很多人在 Mac 上跑本地模型,真正劝退你的不是"跑不起来",而是"能跑,但用起来像钝刀割肉"。oMLX 的出现,让这个问题第一次有了像样的答案。
问题到底出在哪?
最近 GitHub 上有个项目叫 oMLX,值得关注。它不是又一个本地模型启动器,而是目前少数真正把"本地 Agent 后端"当产品来做的项目之一。
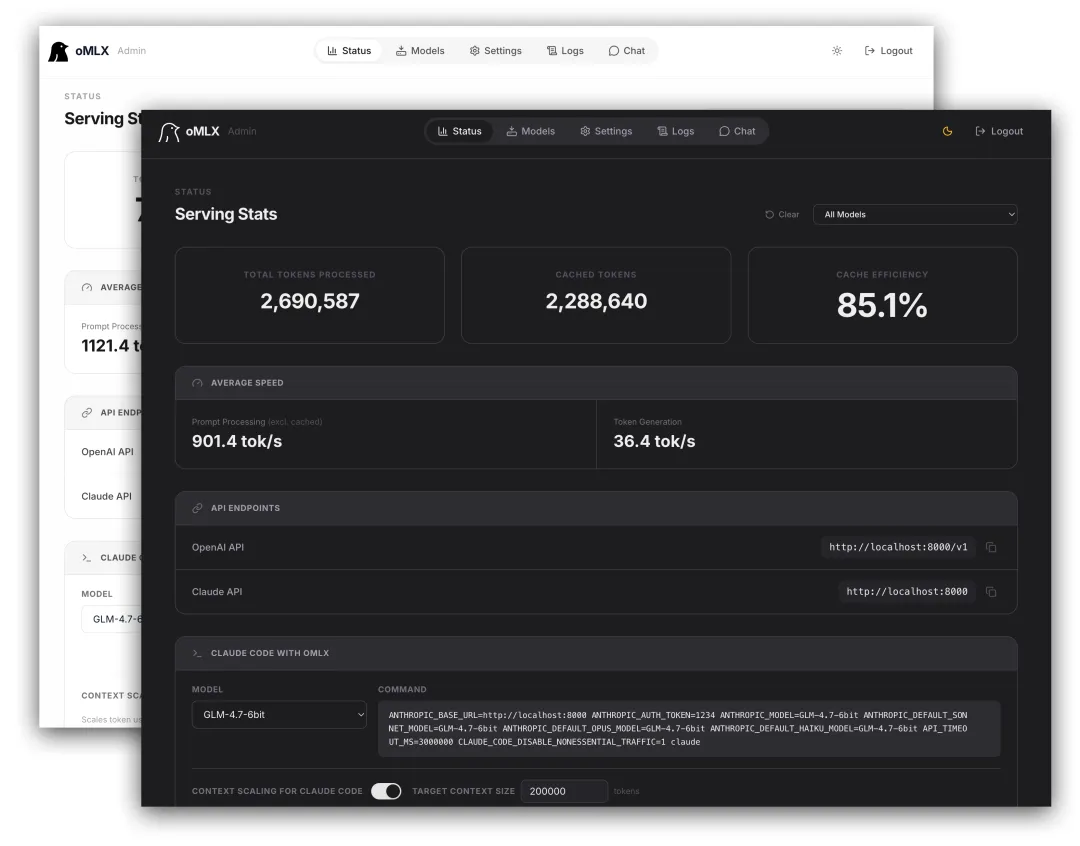
图:oMLX 官方仪表盘截图,来自项目仓库 docs/images/omlx_dashboard.png
一、Mac 本地 Agent 慢,慢在哪里
在 OpenClaw 或 Claude Code 里问一句"1 + 1 等于几",真正送到后端的并不只是这几个字。它前面还带着系统提示词、工具描述、MCP 配置、上下文历史。这个量级通常接近 20K token。
这意味着什么?意味着你每调用一次工具、每开一个新会话、每发一个新问题,这一大段东西都要先被处理一遍。
这也是为什么很多人第一次在 Mac 上跑本地模型时会觉得很怪:模型回起字来似乎不算离谱,但首字前要等很久。尤其一旦接进 Agent 工具链,整个等待就会被无限放大。
传统桌面推理工具更像"单人聊天终端",而不是"多轮、多工具、多并发的 Agent 后端"。这就是瓶颈所在。
二、oMLX 的核心设计亮点
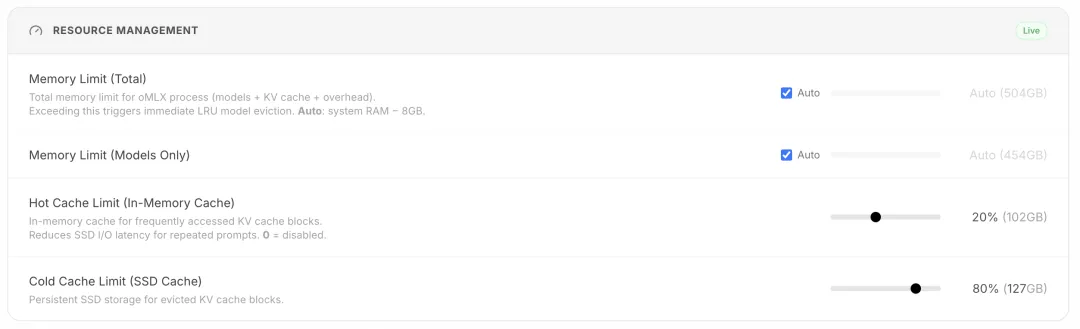
1. 把 KV Cache 做成"热层 + 冷层",而不是只盯着内存
oMLX 的核心卖点之一是 Tiered KV Cache。简单说,它把 KV 缓存分成两层:
- 热层
- 冷层落到 SSD,用 safetensors 形式保存,下一次遇到相同前缀时可以直接恢复,而不是重新计算。
这件事听起来像工程细节,但对 Agent 工作流很关键。因为 Agent 的请求不是简单地"一次问答结束就算了",它会不断复用同一套系统提示、工具清单、结构化输出要求。真正浪费时间的,恰恰是这些重复不变的前缀。
官网给出的目标是把 Agent 场景的 TTFT 从 30 到 90 秒拉到 5 秒以内。这个数字是目标场景下的代表性收益,不是任何模型、任何请求都能稳定达到,但设计方向是合理的,因为它解决的是"反复重算"这个根问题。
图:oMLX 官方说明中的 Hot + Cold KV Cache 架构图,来自项目仓库 docs/images/omlx_hot_cold_cache.png
2. 分页缓存和前缀共享,才是它和普通本地推理工具拉开差距的地方
oMLX 在 README 里明确提到它的块级缓存管理受 vLLM 启发,支持 prefix sharing 和 Copy-on-Write。
这意味着什么?意味着如果你同时开多个 Claude Code 窗口,或者多个 OpenClaw 会话共享大段系统前缀,oMLX 不需要为每个请求都存一整份完整 KV。公共前缀只保留一份,变化部分再增量扩展。这不是"省一点资源"那么简单,而是决定了入门机型能不能把多并发跑起来。
这也是为什么我会说,oMLX 的设计亮点不是"加了缓存",而是终于把缓存理解成了 多会话、长上下文、工具调用密集的生产问题。
3. 连续批处理,让它开始像一个真正的服务端,而不是 GUI 玩具
第二个关键亮点,是 Continuous Batching。项目文档写得很克制,只说它基于 mlx-lm 的 BatchGenerator 处理并发请求,最大并发数可在 CLI 或管理面板中配置。但这件事的意义其实很大。
很多本地推理产品虽然能开多个请求,但本质是"能处理多个窗口",不是"擅长把多个请求压成更有效的吞吐"。如果你的目标是跑 Agent,尤其是工具调用、任务拆分、多个会话并行推进,连续批处理几乎就是必需项。
相同提示词并发时能出现明显加速,这个方向和官方产品定位是吻合的。更重要的是,oMLX 还把这件事做进了可视化 benchmark 界面里,而不是只留给命令行用户自己写脚本测。
三、产品化做得比很多本地推理项目成熟
如果只看底层架构,oMLX 已经挺有辨识度了。但我觉得它更聪明的地方,在于作者没有停在"工程师看得懂"的层面,而是继续把使用门槛压低。
GitHub README 里可以确认的产品化亮点,至少有这几项:
- macOS 菜单栏应用
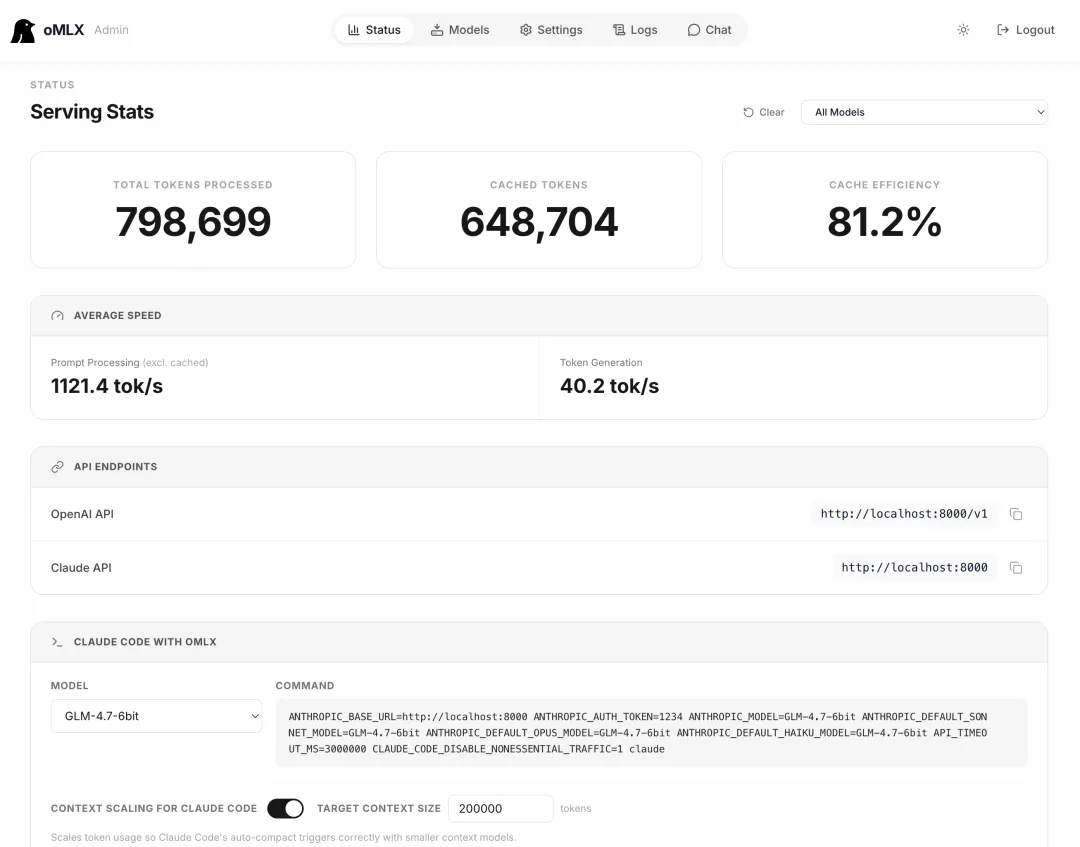
- Admin Dashboard,可以直接做模型管理、监控、聊天、benchmark、单模型参数配置。
- OpenAI / Anthropic 兼容 API,这意味着它不是一个封闭生态,而是可以直接接入现有工具。
- 多模型同服,同一服务里可以管 LLM、VLM、embedding、reranker。
- 按模型独立设置,包括 alias、TTL、采样参数、模型类型覆盖等。
- 面向 Claude Code 的专门优化
这部分其实很说明产品意识。很多本地推理项目喜欢把"能跑"当终点,但你真用起来就会发现,模型怎么自动卸载、怎么限制内存、怎么保持服务不炸、怎么让现有客户端少改代码,这些才是长期使用时最痛的部分。oMLX 目前至少是在认真处理这些问题,而不只是做一个更漂亮的启动器。
管理面板能给 Claude Code 直接生成启动参数。这类动作看似很小,却很有代表性。因为它说明作者不是只在写推理引擎,而是在替用户把"最后一公里接线"也想了。
图:oMLX Admin Dashboard,来自项目仓库 docs/images/Screenshot 2026-02-10 at 00.45.34.png
四、从 GitHub 现状看,oMLX 已经不算"小众新坑"
截至 2026 年 4 月 16 日:jundot/omlx 在 GitHub 上已经来到 10,335 stars、891 forks,最新版本是 v0.3.5,发布时间为 2026 年 4 月 15 日。
这说明什么?说明这个项目不是火了就停,更像是在快速迭代。最新 release 里已经出现了几条很像"下一阶段能力"的更新:
- DFlash speculative decoding
- 多图 VLM 对话的前缀缓存复用,官方给出的真实工作流示例里,缓存效率从 14% 提到 76%。
- Thinking 开关、TTS、更多模型支持、代理和 TLS 配置,说明它正在从"本地推理服务器"向"更完整的 AI 服务底座"扩展。
官网的 Community Benchmarks 页面也给了一个很好的信号。它不是只贴一张作者自己机器上的跑分图,而是在持续收集不同 Apple Silicon 机器的数据。比如页面最新记录里,M4 Max 48 GB 跑 gemma-4-31b-it 4bit,1k 上下文下预填充达到 199.9 tok/s,生成 22.6 tok/s;M4 16 GB 跑 gemma-4-e4b-it 4bit,1k 上下文生成能到 32.9 tok/s。这些数字不能直接替代你的实际体验,但至少说明 oMLX 已经开始形成可对照的性能社区,而不是只有单个 UP 主口述感受。
图:oMLX 内置 Benchmark 工具,来自项目仓库 docs/images/benchmark_omlx.png
五、这篇测评里,我最看重的 4 个设计亮点
第一,问题定义对了。它不是围绕"单轮聊天快一点"设计,而是围绕 Agent 的前缀复用、多会话并发、工具调用链路来设计。
第二,缓存不是点状功能,而是架构级功能。热内存加冷 SSD,再加块级分页和前缀共享,这才是 Apple Silicon 机器真正能被榨出价值的原因。
第三,接口兼容性很务实。OpenAI 和 Anthropic 兼容 API,让它天然适合接入已有工具链,不需要你把整个上层应用重写一遍。
第四,产品化做得早。菜单栏、管理面板、基准测试、模型下载、多语言 UI,这些都在降低普通用户试用和切换成本。一个项目能不能从"技术演示"跨到"日常可用",这一步很关键。
图:oMLX 单模型参数配置界面,来自项目仓库 docs/images/omlx_ChatTemplateKwargs.png
六、但也别把它神化,边界同样要看清
如果你只是偶尔本地聊天,或者只是想随手开一个模型玩玩,oMLX 未必比 LM Studio 这类工具有压倒性优势。它最强的地方,恰恰是当你开始做 Agent、多会话、长上下文、持续调用工具时,那种系统级延迟会被显著拉开。
还有一点要注意,官方首页给出的 TTFT 数字也应该理解成目标场景下的代表性收益,而不是任何模型、任何请求都会稳定达到的承诺。
另外,Apple Silicon 本身仍然有物理边界。入门 16 GB 机器就算被 oMLX 调教得更顺,也不等于它突然拥有高端工作站的上限。你能不能稳定多开、能不能跑更大模型、能不能撑住更长上下文,最后还是受制于内存、带宽、SSD 和模型规模。
七、谁最该现在就去试 oMLX
- 想在 Mac 上跑 OpenClaw、Claude Code、Cursor 本地后端的人。
- 已经被首字延迟、重复 prefill、会话一多就卡住折磨过的人。
- 希望用一台 Apple Silicon 机器承载多个任务流,而不是只做单轮聊天的人。
- 想先用本地模型把工作流跑通,再决定要不要上更贵云端 / token 方案的人。
反过来说,如果你只想找一个图形界面聊聊天,或者你根本不打算碰 Agent 工作流,那 oMLX 的优势你可能感受不到那么明显。
八、最后的判断
oMLX 不是 Apple Silicon 上又一个本地模型启动器,而是目前少数真正把"本地 Agent 后端"当产品来做的项目之一。
它最亮的设计,不是任何一个孤立功能,而是这套组合拳终于开始贴近真实使用场景:前缀缓存、SSD 分层、连续批处理、多模型服务、兼容现有 API,再加上对 Claude Code / OpenClaw 这类工具链的直接照顾。这让它不像一个实验作品,更像一个会继续往"本地 AI 基础设施"方向长的项目。
所以如果你问我,这项目值不值得关注,我的答案是明确的:值得,而且不是因为它火了,而是因为它抓对了问题。接下来真正值得观察的,不是它还能涨多少 star,而是它能不能继续把 Apple Silicon 上的本地 Agent 体验,做成一个真正长期可用的默认选项。
参考资料
1. GitHub:https://github.com/jundot/omlx
2. 官方网站:https://omlx.ai
3. 官方 Benchmarks:https://omlx.ai/benchmarks
4. GitHub Release:v0.3.5,发布时间 2026-04-15