Mac 本地 CSV/Excel 最小工作流:第一版具体步骤。
目标不是一步做到很复杂,而是先把最基本的流程跑通:
不换模型,直接上脚本。
继续保留 mistral做文字,CSV/Excel 交给 Python
Excel/CSV 负责数据,脚本负责校验和计算,mistral 负责写中文总结。
一、第一版要实现什么
先只做这 4 件事:
读取你的 CSV 文件
检查空值和基础格式问题
输出一个清晰的检查结果
再把结果交给 mistral写成中文说明
先不要碰:
自动写回 Excel
多表合并
复杂盈亏模型
图表
OpenClaw
二、你需要准备什么
你现在只需要有这两样:
1. 一个 CSV 文件
2. 你的 Mac 已经能跑终端
三、第一版工作目录
先建一个文件夹,专门放这套本地工作流。
在终端执行:
mkdir -p ~/local_csv_workflowcd ~/local_csv_workflow
四、把 CSV 放进去
把你的 amzn_trades.csv放进这个文件夹。
最后你的目录里至少有:
~/local_csv_workflow/amzn_trades.csv
五、创建第一版检查脚本
在终端里执行:
nano check_csv.py
把下面这整段代码原样粘进去:
import csvfrom pathlib import PathFILE_NAME = "amzn_trades.csv"required_columns = ["Date", "Ticker", "Action", "Quantity", "Price", "Fees", "CashFlow"]file_path = Path(FILE_NAME)if not file_path.exists(): print(f"文件不存在: {FILE_NAME}") raise SystemExit(1)with open(file_path, "r", encoding="utf-8-sig", newline="") as f: reader = csv.DictReader(f) rows = list(reader)print(f"文件名: {FILE_NAME}")print(f"总行数: {len(rows)}")print()# 检查表头print("【表头检查】")actual_columns = reader.fieldnames or []missing_columns = [col for col in required_columns if col not in actual_columns]extra_columns = [col for col in actual_columns if col not in required_columns]print(f"实际列名: {actual_columns}")if missing_columns: print(f"缺少列: {missing_columns}")else: print("缺少列: 无")if extra_columns: print(f"额外列: {extra_columns}")else: print("额外列: 无")print()# 检查空值print("【空值检查】")empty_found = Falsefor idx, row in enumerate(rows, start=2): # CSV 第1行是表头,所以数据从第2行开始 for col in required_columns: value = row.get(col, "") if value is None or str(value).strip() == "": print(f"第 {idx} 行,{col} 列为空") empty_found = Trueif not empty_found: print("未发现空值")print()# 检查数字列格式print("【数字列检查】")numeric_columns = ["Quantity", "Price", "Fees", "CashFlow"]number_error_found = Falsefor idx, row in enumerate(rows, start=2): for col in numeric_columns: value = str(row.get(col, "")).strip() if value == "": continue try: float(value) except ValueError: print(f"第 {idx} 行,{col} 列不是有效数字: {value}") number_error_found = Trueif not number_error_found: print("数字列格式正常")print()# 基础汇总print("【基础汇总】")tickers = sorted(set(str(row.get("Ticker", "")).strip() for row in rows if str(row.get("Ticker", "")).strip()))print(f"Ticker 列包含: {tickers}")actions = sorted(set(str(row.get("Action", "")).strip() for row in rows if str(row.get("Action", "")).strip()))print(f"Action 列包含: {actions}")print()print("检查完成。")
然后:
按 Control + O保存
回车
按 Control + X退出
六、运行第一版脚本
在终端执行:
python3 check_csv.py
七、你会得到什么结果
它会输出几块内容:
这说明两件事:
你的 Mac 本地 CSV 工作流已经能用了
现在的问题不在 Python 环境,而在 CSV 文件内容本身
你这次结果说明了什么
脚本能正确发现:
这正是你原始数据里那条缺日期的记录。
但它还发现了很多额外空值,像:
第 7 行开始大量空值
第 8、9、10 行也有空值
这通常说明你的 amzn_trades.csv里不止 5 条数据,很可能夹了:
所以现在不是脚本错了,而是 CSV 文件需要先看一眼原始内容。
下一步只做一件事
在终端输入这句:
cat -n amzn_trades.csv
它会把文件内容按行号显示出来。
哪些是正常数据行
哪些是空白/脏数据
下一步该清理文件,还是改脚本忽略空行
看清楚了,问题就在文件本身,不在脚本。
你的 amzn_trades.csv里实际是:
第 1 行:表头
第 2–6 行:你这次要的 AMZN 数据
第 7–9 行:脏空行
第 10 行:另一条不完整的旧数据
所以现在最合理的是:
先做一个干净版 CSV,只保留第 1–6 行。
在终端输入这句:
head -n 6 amzn_trades.csv > amzn_trades_clean.csv
这会新建一个干净文件 amzn_trades_clean.csv,只保留前 6 行。
做完后再输入:
cat -n amzn_trades_clean.csv
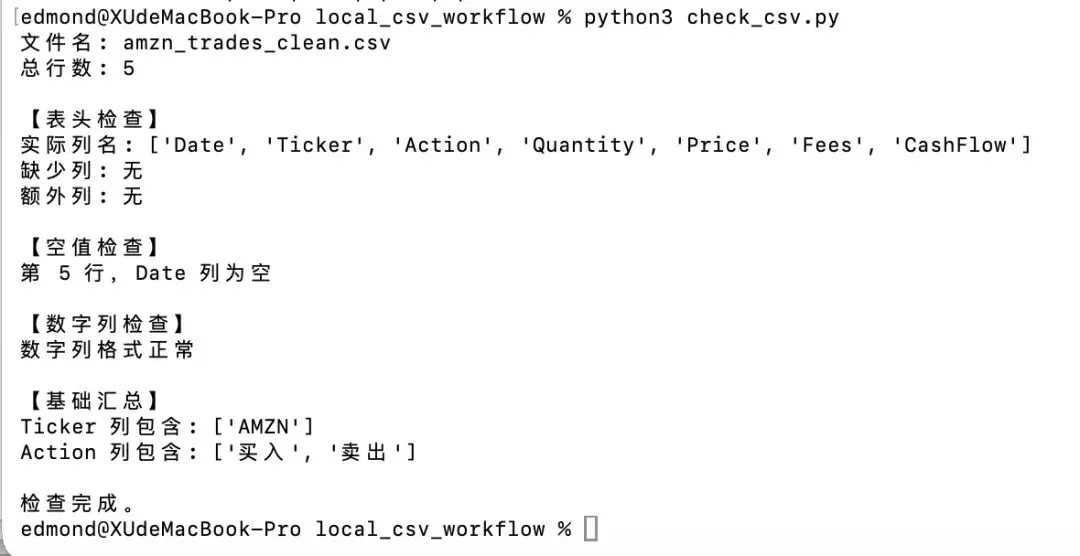
很好,现在这个干净版文件已经对了。
当前 amzn_trades_clean.csv里只剩:
表头
5 条 AMZN 记录
其中第 5 行数据的 Date为空
下一步
把脚本里的文件名从:
FILE_NAME = "amzn_trades.csv"
改成:
FILE_NAME = "amzn_trades_clean.csv"
改完后再运行:
python3 check_csv.py
很好,第一版本地 CSV 工作流已经跑通了。
现在结果完全符合预期:
文件名正确
总行数正确
表头正常
数字列正常
正确识别出:
现在已经有了一个比本地大模型更可靠的 CSV 检查方式:
这就是后面最稳的本地工作流雏形。
下一步把这份脚本输出交给 mistral,让它写成一段简洁中文说明。
Python 脚本:负责准确检查
mistral:负责把检查结果写成中文说明
很好,这一步也跑通了。
现在你已经把 “Python 检查 + mistral 写中文说明”这条最小工作流完整走通了。
而且结果是对的、可用的。
这意味着什么
你现在已经有了一个稳定分工:
Python:负责准确检查 CSV
mistral:负责把检查结果整理成中文说明
这比单独靠本地大模型直接看 CSV 稳得多。
你当前已经完成的最小工作流
准备 CSV
用 Python 检查
找出空值和基础问题
把检查结果交给 mistral
输出可直接写进日志的中文说明
下一步把这个工作流扩成第二版。
第二版最值得加的功能
我建议按这个顺序来:
统计买入/卖出次数
按 Ticker 汇总交易数量
检查日期格式
导出检查结果到一个 txt 或 csv
后面再考虑:
第二版:在现有脚本上增加“基础交易汇总”。
比如让脚本额外输出:
总买入次数
总卖出次数
总记录数
每个 Ticker 出现次数
买入和卖出各多少条
这样你这套本地工作流就会从“能查错”升级到“能做基础分析”。
第一版已经成功了,下一步不是继续测试模型,而是升级脚本,做第二版基础交易汇总。







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
