关注CAIE,国内头部AI人才认证、培训体系,助你在职场升职加薪。咱们做PPT最难的不是写内容,而是调格式。改了一版又一版,字体大小不对、对齐歪了、页码丢了,简直比写内容本身还折磨人。
MiniMax刚把新发布的M2.7开源了,这个模型在专业办公评测GDPval-AA里拿到了1495分的ELO评分,所有开源模型里排第一,分数甚至反超了GPT-5.3。
这个成绩意味着什么呢?就是M2.7干那些日常办公的活,已经比市面上绝大多数闭源模型都要靠谱了。
开源地址:https://huggingface.co/MiniMaxAI/MiniMax-M2.7
具体到PPT和Word这块,M2.7最让人觉得离谱的是它的多轮编辑能力。什么叫多轮编辑?
就是你跟它说帮我把第二页那段话改得更正式一点,它就只动第二页那段话,其他地方的格式、排版、字体全部纹丝不动。
改完之后你拿到的就是一个能直接发出去的原文件,不是那种AI生成完你还得花半小时手动调的半成品。Excel也能处理,读数据、建图表、写公式这些都不在话下。
而且它不是只会从零开始生成文档。你完全可以给它一个已有的模板或者半成品文件,然后告诉它按照你的需求去改。
它支持基于模板生成,也支持针对现有文件做多轮高保真编辑,最终交付的就是一个可以直接用的可编辑文件。这在真实工作场景里太重要了,因为谁也不是每次都从空白页开始写PPT的。
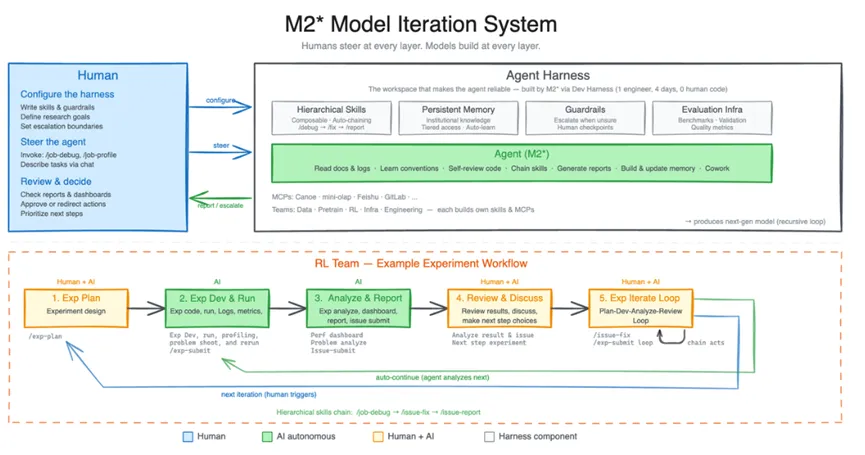
不过说实话,如果你只拿它来写PPT,那就太大材小用了。M2.7真正让我觉得这个团队有点疯的地方,是它竟然参与了自身的进化过程。
他们让早期版本的M2.7自己搭建了一套研究型智能体框架,这个框架能跟不同项目组交互协作,管理数据流水线、训练环境、评估基础设施,甚至维护跨团队的持久化记忆。
研究人员只需要把控大方向和关键决策,剩下那些文献调研、实验配置、代码调试、指标分析之类的脏活累活,模型自己去干。
举个例子吧。MiniMax让M2.7在内部平台上自主优化编程性能,模型自己跑了一个超过100轮的迭代循环。
每一轮都做同样的事情,分析哪里失败了,规划怎么调整,修改代码,跑评估,对比结果,然后决定保留还是回退。
就像一个不知疲倦的工程师,加班加点地调优自己的代码。最终这个自我优化的过程让性能提升了30%。
30%听起来可能不是很震撼,但你想一想,这是模型在没人盯着的情况下自己给自己做手术,做完之后还真的变强了,这事本身就挺震撼的。
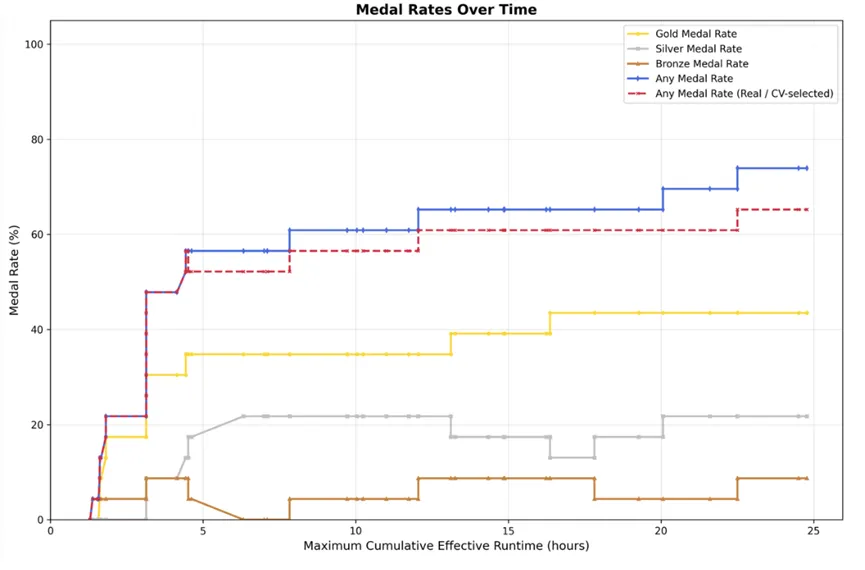
更有意思的是他们做的一组竞赛实验。MiniMax让M2.7参加了OpenAI开源的22场机器学习竞赛,这些竞赛基本上覆盖了机器学习研究的所有阶段。
他们给模型设计了一个包含短期记忆、自我反馈、自我优化三个核心模块的简易框架,让M2.7在每次迭代后自己写总结、自己打分、自己想下一轮怎么改。
三次试验,每次让它自己进化24小时,最后拿到了9金5银1铜的成绩,平均获奖率66.6%,跟Gemini-3.1持平,仅次于Opus-4.6和GPT-5.4。
然后是软件工程这块。M2.7在SWE-Pro基准测试中得分率56.22%,跟GPT-5.3-Codex打了个平手。
在更贴近真实工程场景的SWE多语言测试中拿到76.5分,Multi SWE Bench拿到52.7分,优势就更明显了。
MiniMax的真实案例,现在用M2.7排查线上生产事故,故障恢复时间已经能压缩到3分钟以内。
3分钟啊,干过后端和运维的朋友应该懂这个数字意味着什么。凌晨3点收到告警,M2.7能自己关联监控指标和部署时间线做因果推理,对链路采样做统计分析提出假设,主动连数据库验证根因,定位代码仓库里缺失的索引迁移文件。
甚至知道先用非阻塞索引创建来快速止损,再提交合并请求。这不叫会写代码,这叫真正理解了生产系统是怎么跑的。
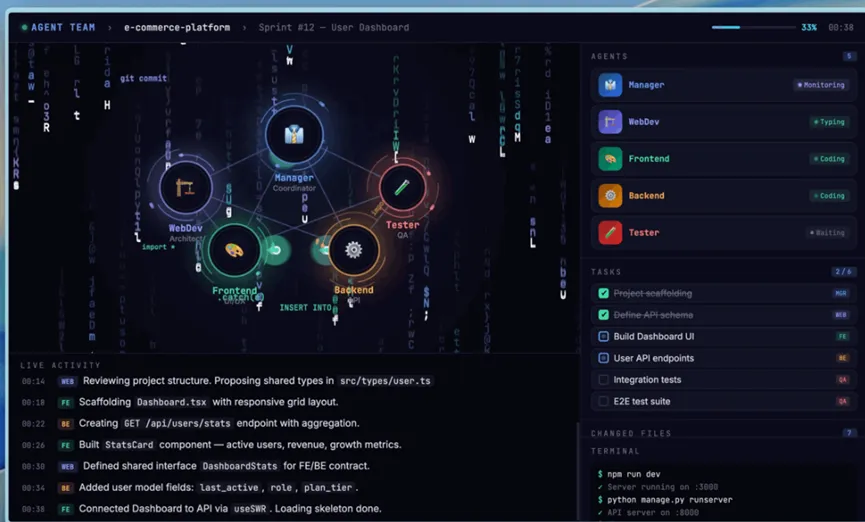
还有一个我很喜欢的能力,原生智能体协作。简单来说就是你可以给M2.7分配多个角色,比如一个负责写代码,一个负责测试,一个负责审阅,它们之间会自己协调任务分工。
这不是靠提示词拼凑出来的效果,而是模型原生具备的能力,需要角色边界意识、对抗推理能力、协议遵守意识这些东西真正内化到模型里面才行。
MiniMax内部已经在用这套多智能体协作来做产品原型开发了,效果据说相当不错。
上面说的这些,其实也只是M2.7能力的一部分,喜欢折腾的小伙伴期待你们更多的玩法。
想系统掌握AI核心技能、获取行业认可资质?
CAIE注册人工智能工程师认证
助你拓宽职业赛道,成为AI领域持证实力派
企业、高校及渠道合作
请联系微信:FYLlaoshi