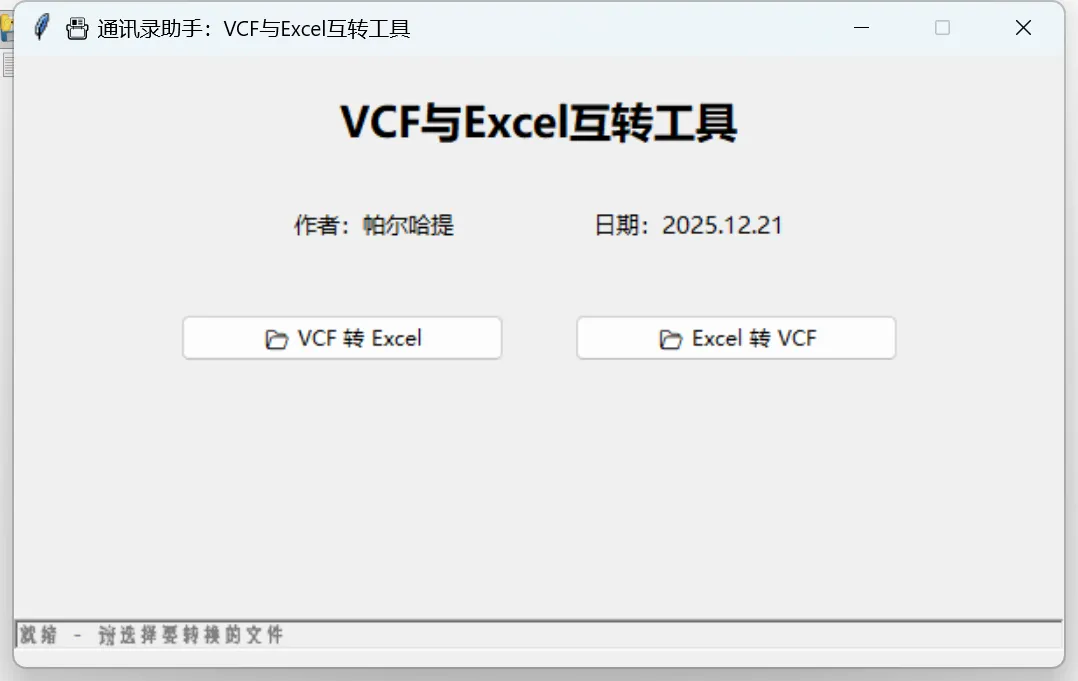
import osimport sysimport pandas as pdimport reimport quopriimport base64from tkinter import *from tkinter import ttk, filedialog, messageboxclass VCFConverterApp: def __init__(self, root): self.root = root self.root.title("📇 通讯录助手:VCF与Excel互转工具") self.root.geometry("600x350") self.root.resizable(False, False) # 标题 title_label = ttk.Label(root, text="VCF与Excel互转工具", font=("微软雅黑", 18, "bold")) title_label.pack(pady=20) # 说明文字 desc_label = ttk.Label(root, text="作者:帕尔哈提 日期:2025.12.21", font=("微软雅黑", 10)) desc_label.pack(pady=10) # 按钮框架 button_frame = ttk.Frame(root) button_frame.pack(pady=30) # VCF 转 Excel 按钮 self.btn_vcf_to_excel = ttk.Button(button_frame, text="📂 VCF 转 Excel", width=25, command=self.run_vcf_to_excel) self.btn_vcf_to_excel.grid(row=0, column=0, padx=20) # Excel 转 VCF 按钮 self.btn_excel_to_vcf = ttk.Button(button_frame, text="📂 Excel 转 VCF", width=25, command=self.run_excel_to_vcf) self.btn_excel_to_vcf.grid(row=0, column=1, padx=20) # 状态栏 self.status_var = StringVar() self.status_var.set("就绪 - 请选择要转换的文件") self.status_bar = ttk.Label(root, textvariable=self.status_var, relief=SUNKEN, font=("Consolas", 9), foreground="gray") self.status_bar.pack(side=BOTTOM, fill=X, pady=10) def show_error(self, message): messagebox.showerror("错误", message) self.status_var.set("状态:出错 - " + message[:50] + "...") def show_info(self, message): messagebox.showinfo("转换成功", message) self.status_var.set("状态:转换完成 - 请查看文件") def run_vcf_to_excel(self): self.status_var.set("状态:正在选择VCF文件...") self.root.update() vcf_path = filedialog.askopenfilename( title="选择VCF联系人文件", filetypes=[("VCF Files", "*.vcf"), ("All Files", "*.*")], initialdir=os.path.expanduser("~") ) if not vcf_path: self.status_var.set("状态:已取消 - 未选择文件") return try: contacts = self.process_vcf_file(vcf_path) if not contacts: self.show_error("未解析到有效联系人数据,请检查VCF文件是否有效") return # 获取保存路径 desktop = os.path.join(os.path.expanduser("~"), "Desktop") default_name = os.path.splitext(os.path.basename(vcf_path))[0] + "_完整联系人信息.xlsx" save_path = filedialog.asksaveasfilename( title="保存Excel联系人文件", initialdir=desktop, initialfile=default_name, defaultextension=".xlsx", filetypes=[("Excel Files", "*.xlsx"), ("All Files", "*.*")] ) if not save_path: self.status_var.set("状态:已取消 - 未保存文件") return # 生成Excel文件,确保包含所有字段(核心:保留所有信息列) df = pd.DataFrame(contacts) # 定义固定列顺序,确保所有信息都显示 columns_order = [ '姓名', '联系电话1', '联系电话2', '工作单位(公司)', '部门', '职位', '详细地址', '电子邮件' ] # 补充存在的列,避免缺失 for col in df.columns: if col not in columns_order: columns_order.append(col) # 重新排序,确保字段完整显示 df = df.reindex(columns=columns_order, fill_value="") # 过滤无效数据(仅姓名为空或电话全空的过滤) df = df[(df['姓名'] != '未知联系人') & (df['姓名'] != '') & ((df['联系电话1'] != '') | (df['联系电话2'] != ''))] # 保存Excel,不保留索引 df.to_excel(save_path, index=False, engine="openpyxl") success_msg = f"转换成功!\n共解析 {len(df)} 个有效联系人\n包含字段:姓名、联系电话1、联系电话2、工作单位、部门、职位、地址、电子邮件\n文件已保存至:\n{save_path}" self.show_info(success_msg) except Exception as e: self.show_error(f"转换失败:{str(e)}\n请检查文件格式或依赖库是否安装完整") def run_excel_to_vcf(self): self.status_var.set("状态:正在选择Excel文件...") self.root.update() excel_path = filedialog.askopenfilename( title="选择Excel联系人文件", filetypes=[("Excel Files", "*.xlsx *.xls"), ("All Files", "*.*")], initialdir=os.path.expanduser("~") ) if not excel_path: self.status_var.set("状态:已取消 - 未选择文件") return try: # 读取Excel文件,支持所有字段 if excel_path.endswith(".xlsx"): df = pd.read_excel(excel_path, engine="openpyxl") else: df = pd.read_excel(excel_path, engine="xlrd") # 检查必要字段 required_cols = ['姓名', '联系电话1'] for col in required_cols: if col not in df.columns: raise ValueError(f"Excel文件缺少必要字段:{col},请确保包含姓名和联系电话1列") # 获取保存路径 desktop = os.path.join(os.path.expanduser("~"), "Desktop") default_name = os.path.splitext(os.path.basename(excel_path))[0] + "_完整联系人.vcf" save_path = filedialog.asksaveasfilename( title="保存VCF联系人文件", initialdir=desktop, initialfile=default_name, defaultextension=".vcf", filetypes=[("VCF Files", "*.vcf"), ("All Files", "*.*")] ) if not save_path: self.status_var.set("状态:已取消 - 未保存文件") return # 生成VCF文件,完整保留所有字段 with open(save_path, 'w', encoding='utf-8') as f: for _, row in df.iterrows(): f.write("BEGIN:VCARD\n") f.write("VERSION:3.0\n") # 处理姓名(保留·间隔符) name = row['姓名'] if pd.notna(row['姓名']) else "" if name == "": continue # 跳过无姓名的联系人 encoded_name = quopri.encodestring(name.encode('utf-8')).decode('utf-8') f.write(f"FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:{encoded_name}\n") f.write(f"N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:{encoded_name};;;\n") # 处理联系电话(修复.0后缀问题,清除无效字符) phone1 = row['联系电话1'] if pd.notna(row['联系电话1']) else "" phone2 = row['联系电话2'] if pd.notna(row['联系电话2']) else "" # 处理电话1 if phone1 != "": # 若为数值类型(int/float),先转为整数再转字符串(去除小数部分) if isinstance(phone1, (int, float)): phone1 = str(int(phone1)) # 清除所有空格和非数字字符(保留+等可能的前缀) phone1 = re.sub(r'\s+', '', str(phone1)).strip() f.write(f"TEL;TYPE=CELL:{phone1}\n") # 处理电话2 if phone2 != "": if isinstance(phone2, (int, float)): phone2 = str(int(phone2)) phone2 = re.sub(r'\s+', '', str(phone2)).strip() f.write(f"TEL;TYPE=CELL:{phone2}\n") # 处理电子邮件(完整保留) email = row['电子邮件'] if '电子邮件' in df.columns and pd.notna(row['电子邮件']) else "" if email != "": encoded_email = quopri.encodestring(email.encode('utf-8')).decode('utf-8') f.write(f"EMAIL;TYPE=WORK;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:{encoded_email}\n") # 处理工作单位(公司,完整保留) company = row['工作单位(公司)'] if '工作单位(公司)' in df.columns and pd.notna(row['工作单位(公司)']) else "" if company != "": encoded_company = quopri.encodestring(company.encode('utf-8')).decode('utf-8') f.write(f"ORG;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:{encoded_company}\n") # 处理部门(完整保留) dept = row['部门'] if '部门' in df.columns and pd.notna(row['部门']) else "" if dept != "": encoded_dept = quopri.encodestring(dept.encode('utf-8')).decode('utf-8') f.write(f"X-DEPARTMENT;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:{encoded_dept}\n") # 处理职位(完整保留) title = row['职位'] if '职位' in df.columns and pd.notna(row['职位']) else "" if title != "": encoded_title = quopri.encodestring(title.encode('utf-8')).decode('utf-8') f.write(f"TITLE;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:{encoded_title}\n") # 处理详细地址(完整保留) address = row['详细地址'] if '详细地址' in df.columns and pd.notna(row['详细地址']) else "" if address != "": encoded_address = quopri.encodestring(address.encode('utf-8')).decode('utf-8') f.write(f"ADR;TYPE=WORK;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;;{encoded_address};;;;\n") f.write("END:VCARD\n") success_msg = f"转换成功!\n共生成 {len(df)} 个有效联系人\n包含字段:姓名、联系电话、工作单位、部门、职位、地址、电子邮件\n文件已保存至:\n{save_path}" self.show_info(success_msg) except Exception as e: self.show_error(f"转换失败:{str(e)}\n请检查文件格式或必要字段是否存在") def decode_quoted_printable_full(self, text): """完整解码QP编码内容,保留·间隔符和特殊字符,无截断""" try: text = re.sub(r'=\r?\n', '', text) # 拼接行续符 text = re.sub(r'=+$', '', text) # 移除末尾多余= decoded_bytes = quopri.decodestring(text.encode('utf-8')) return decoded_bytes.decode('utf-8', errors='replace') except Exception as e: return text def is_invalid_name(self, text): """优化无效姓名过滤,保留·间隔符""" if not re.search(r'[\u4e00-\u9fff\w\s·]', text) or len(text) == 0: return True if re.search(r'CHARSET|ENCODING|QUOTED-PRINTABLE|BASE64|PHOTO|IMAGE', text, re.IGNORECASE): return True return False def extract_name_from_block_full(self, block_text): """完整提取姓名,保留·间隔符""" # 移除干扰字段 block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) # 提取FN字段(优先) fn_pattern = re.compile(r'FN[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE) fn_matches = fn_pattern.findall(block_text) if fn_matches: fn_content = fn_matches[0].strip() decoded_name = self.decode_quoted_printable_full(fn_content) decoded_name = re.sub(r'[^\u4e00-\u9fff\w\s\u3000-\u303f\uff00-\uffef·]', '', decoded_name) decoded_name = re.sub(r'\s+', ' ', decoded_name).strip() if not self.is_invalid_name(decoded_name) and decoded_name: return decoded_name # 提取N字段 n_pattern = re.compile(r'N[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE) n_matches = n_pattern.findall(block_text) if n_matches: n_content = n_matches[0].strip() decoded_name = self.decode_quoted_printable_full(n_content) decoded_name = re.sub(r'[^\u4e00-\u9fff\w\s\u3000-\u303f\uff00-\uffef·]', '', decoded_name) name_parts = [p.strip() for p in decoded_name.split(';') if p.strip()] full_name = ''.join(name_parts) full_name = re.sub(r'\s+', ' ', full_name).strip() if not self.is_invalid_name(full_name) and full_name: return full_name return "" def extract_phones_from_block_full(self, block_text): """提取联系电话(单个不重复、多个正常保留、空电话不填充)""" # 移除干扰字段 block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) clean_block = re.sub(r'CHARSET|ENCODING|QUOTED-PRINTABLE|BASE64', '', block_text, flags=re.IGNORECASE) # 提取所有有效电话(去重,避免重复提取) tel_pattern = re.compile(r'TEL[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE | re.MULTILINE) tel_matches = tel_pattern.findall(clean_block) valid_phones = [] for match in tel_matches: phone = ''.join([c for c in match if c.isdigit() or c in ['+', '-', '(', ')', ' ']]) phone = re.sub(r'\s+', '', phone).strip() if phone and phone not in valid_phones: # 去重,避免单个电话重复 valid_phones.append(phone) # 处理电话数量:最多保留2个,单个则第二个为空 phone1 = valid_phones[0] if len(valid_phones) >= 1 else "" phone2 = valid_phones[1] if len(valid_phones) >= 2 else "" return phone1, phone2 def extract_org_full(self, block_text): """完整提取工作单位/公司信息""" block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) block_text = re.sub(r'=\r?\n', '', block_text) block_text = re.sub(r'=+$', '', block_text) # 匹配ORG字段(工作单位/公司) org_pattern = re.compile(r'ORG[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE | re.MULTILINE) org_matches = org_pattern.findall(block_text) if org_matches: org_content = org_matches[0].strip() decoded_org = self.decode_quoted_printable_full(org_content) decoded_org = re.sub(r'[^\u4e00-\u9fff\d\w\s\+\-\@\.\·]', '', decoded_org) decoded_org = re.sub(r'\s+', ' ', decoded_org).strip() org_parts = [p.strip() for p in decoded_org.split(';') if p.strip()] return ' '.join(org_parts) if org_parts else "" return "" def extract_dept_full(self, block_text): """完整提取部门信息""" block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) block_text = re.sub(r'=\r?\n', '', block_text) block_text = re.sub(r'=+$', '', block_text) # 匹配部门字段(X-DEPARTMENT/DEPT) dept_pattern = re.compile(r'(X-DEPARTMENT|DEPT)[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE | re.MULTILINE) dept_matches = dept_pattern.findall(block_text) if dept_matches: dept_content = dept_matches[0][1].strip() decoded_dept = self.decode_quoted_printable_full(dept_content) decoded_dept = re.sub(r'[^\u4e00-\u9fff\d\w\s\+\-\@\.\·]', '', decoded_dept) decoded_dept = re.sub(r'\s+', ' ', decoded_dept).strip() return decoded_dept if decoded_dept else "" return "" def extract_title_full(self, block_text): """完整提取职位信息""" block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) block_text = re.sub(r'=\r?\n', '', block_text) block_text = re.sub(r'=+$', '', block_text) # 匹配职位字段(TITLE) title_pattern = re.compile(r'TITLE[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE | re.MULTILINE) title_matches = title_pattern.findall(block_text) if title_matches: title_content = title_matches[0].strip() decoded_title = self.decode_quoted_printable_full(title_content) decoded_title = re.sub(r'[^\u4e00-\u9fff\d\w\s\+\-\@\.\·]', '', decoded_title) decoded_title = re.sub(r'\s+', ' ', decoded_title).strip() return decoded_title if decoded_title else "" return "" def extract_adr_full(self, block_text): """完整提取详细地址信息""" block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) block_text = re.sub(r'=\r?\n', '', block_text) block_text = re.sub(r'=+$', '', block_text) # 匹配地址字段(ADR) adr_pattern = re.compile(r'ADR[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE | re.MULTILINE) adr_matches = adr_pattern.findall(block_text) if adr_matches: adr_content = adr_matches[0].strip() decoded_adr = self.decode_quoted_printable_full(adr_content) decoded_adr = re.sub(r'[^\u4e00-\u9fff\d\w\s\+\-\@\.\u3000-\u303f\uff00-\uffef·]', '', decoded_adr) decoded_adr = re.sub(r'\s+', ' ', decoded_adr).strip() adr_parts = [p.strip() for p in decoded_adr.split(';') if p.strip()] return ' '.join(adr_parts) if adr_parts else "" return "" def extract_email_full(self, block_text): """完整提取电子邮件信息""" block_text = re.sub(r'PHOTO[^:]*:.*?(?=\r?\n\w+|END:VCARD)', '', block_text, flags=re.DOTALL | re.IGNORECASE) block_text = re.sub(r'=\r?\n', '', block_text) block_text = re.sub(r'=+$', '', block_text) # 匹配电子邮件字段(EMAIL) email_pattern = re.compile(r'EMAIL[^:]*:(.*?)(?=\r?\n\w+|END:VCARD)', re.DOTALL | re.IGNORECASE | re.MULTILINE) email_matches = email_pattern.findall(block_text) if email_matches: email_content = email_matches[0].strip() decoded_email = self.decode_quoted_printable_full(email_content) decoded_email = re.sub(r'[^\u4e00-\u9fff\d\w\s\+\-\@\.\.]', '', decoded_email) decoded_email = re.sub(r'\s+', ' ', decoded_email).strip() return decoded_email if decoded_email else "" return "" def process_vcf_file(self, vcf_path): """核心流程:完整提取所有信息,处理联系电话不重复""" contacts = [] try: # 读取VCF文件 with open(vcf_path, 'rb') as f: raw_data = f.read() block_text = raw_data.decode('utf-8', errors='replace') block_text = re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]', '', block_text) block_text = re.sub(r'\r\n', '\n', block_text) # 拆分单个联系人块 vcard_blocks = re.split(r'BEGIN:VCARD', block_text, flags=re.IGNORECASE) for block in vcard_blocks[1:]: # 跳过第一个空块 if 'END:VCARD' not in block: continue # 提取核心信息 name = self.extract_name_from_block_full(block) phone1, phone2 = self.extract_phones_from_block_full(block) company = self.extract_org_full(block) dept = self.extract_dept_full(block) title = self.extract_title_full(block) address = self.extract_adr_full(block) email = self.extract_email_full(block) # 构建联系人字典 contact = { '姓名': name if name else '未知联系人', '联系电话1': phone1, '联系电话2': phone2, '工作单位(公司)': company, '部门': dept, '职位': title, '详细地址': address, '电子邮件': email } contacts.append(contact) return contacts except Exception as e: raise Exception(f"解析VCF文件失败:{str(e)}")if __name__ == "__main__": root = Tk() app = VCFConverterApp(root) root.mainloop()