拒绝“PPT工厂”与“数据坟场”:工厂数字化采集实战策略
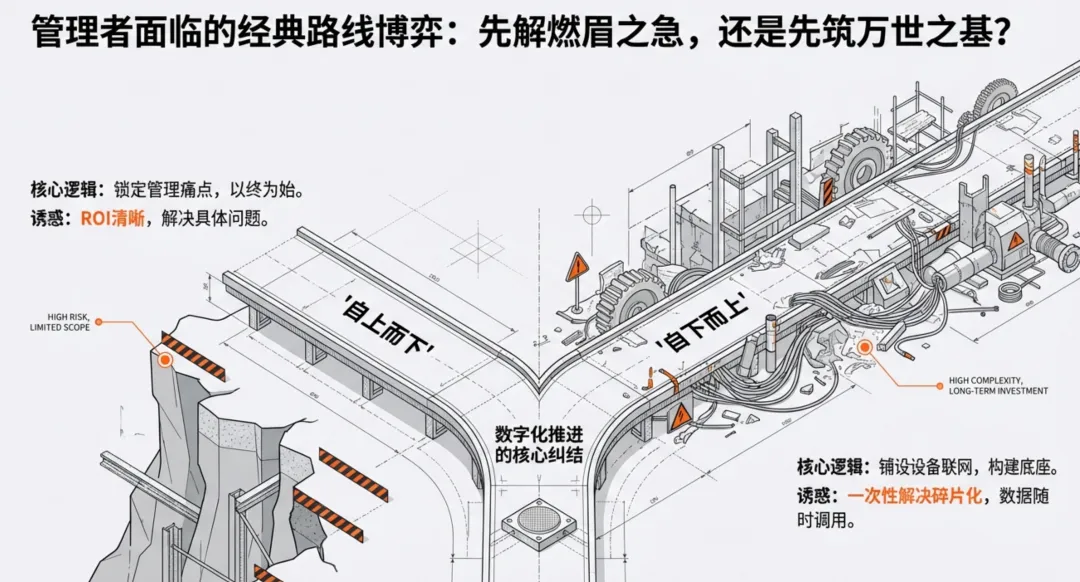
在智能制造的推进过程中,很多管理者都会面临一个经典的“路线纠结”:是先锁定要解决的管理问题(自上而下),还是先铺好设备联网和数据底座(自下而上)?如果选择先看结果,往往会发现现场设备五花八门,数据接不齐、对不上,最后看板做得很漂亮,但数据全靠补录,变成了只能看、不能用的“PPT工厂”。如果选择先打底座,投入大量资源把所有设备都连上网,却发现数据采了一堆,却没人知道怎么用,最终在服务器里静静“吃灰”,变成了耗资巨大的“数据坟场”。自上而下的“管理闭环”:为何总在执行现场折戟?
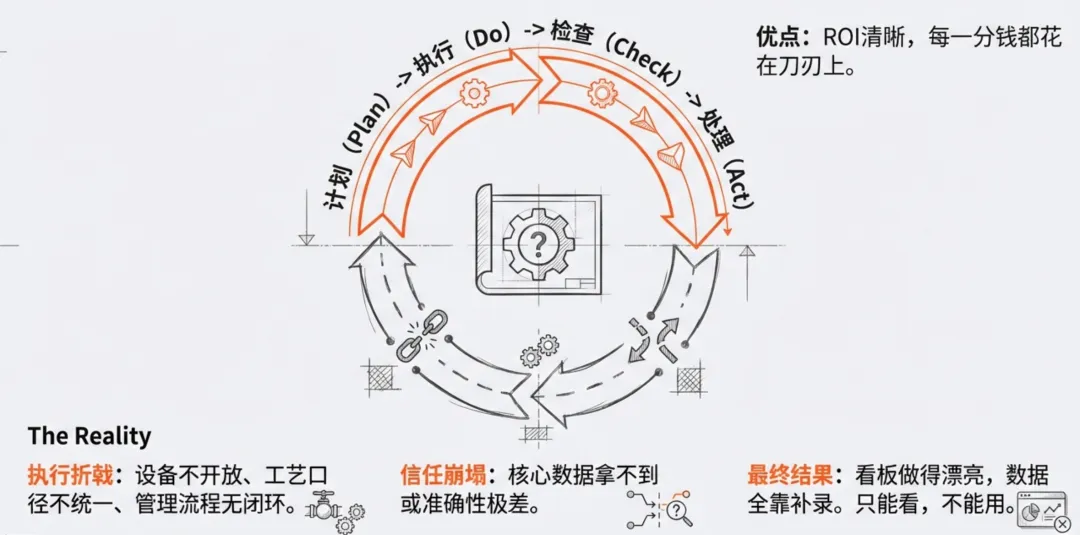
自上而下的策略本质上是“以终为始”。它要求管理者先定义好KPI,比如良率要提升多少、停线时间要减少多少,然后倒推需要采集哪些字段。这种方式的优点是投资回报率(ROI)非常清晰,每一分钱都花在解决具体问题上。对于业务目标明确、需要快速见效的工厂来说,这通常是首选。然而,在实际落地中,这种路线极度依赖现场的标准化程度。如果设备不开放、工艺口径不统一,或者管理流程本身就没有闭环,那么设计的指标再科学,也无法真正落地参与生产决策。我们见过太多案例,顶层设计非常完美,但到了接入阶段才发现,核心数据拿不到或者准确性极差,最终导致管理层对数字化的信任度断崖式下跌。自下而上的“底座逻辑”:为何沦为昂贵的“数据坟场”?
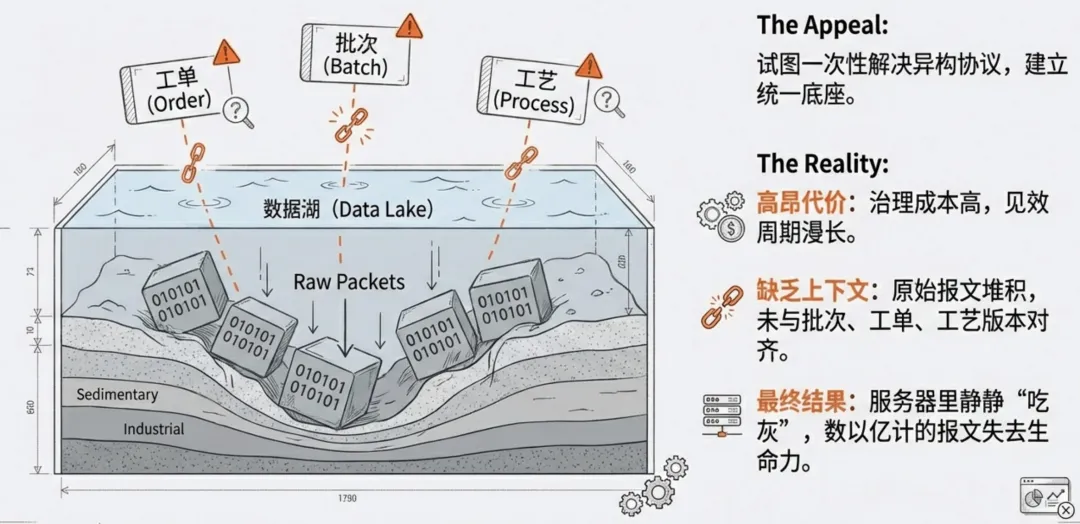
另一种极端是“先铺路、后开车”。即不管现在用不用,先把设备信号标准化,建立一套完整的数据字典和对象模型。这种策略在工厂建设初期非常吸引人,因为它能一次性解决异构协议和数据碎片化的问题。只要底座够稳,未来无论业务怎么变,数据都能随时被调用。但它的代价是高昂的治理成本和漫长的见效周期。管理者往往要面对持续的投入,却看不到直接的业务产出。如果缺乏业务牵引,团队很容易陷入“为了采集而采集”的自我感动中。当数以亿计的原始报文堆积在数据库里,却没有与具体的批次、工单、工艺版本对齐时,这些数据就失去了生命力。等到真正要用时,才发现缺了最关键的上下文。执行层面的“致命盲区”:别在供应商撤离后才想起追数据
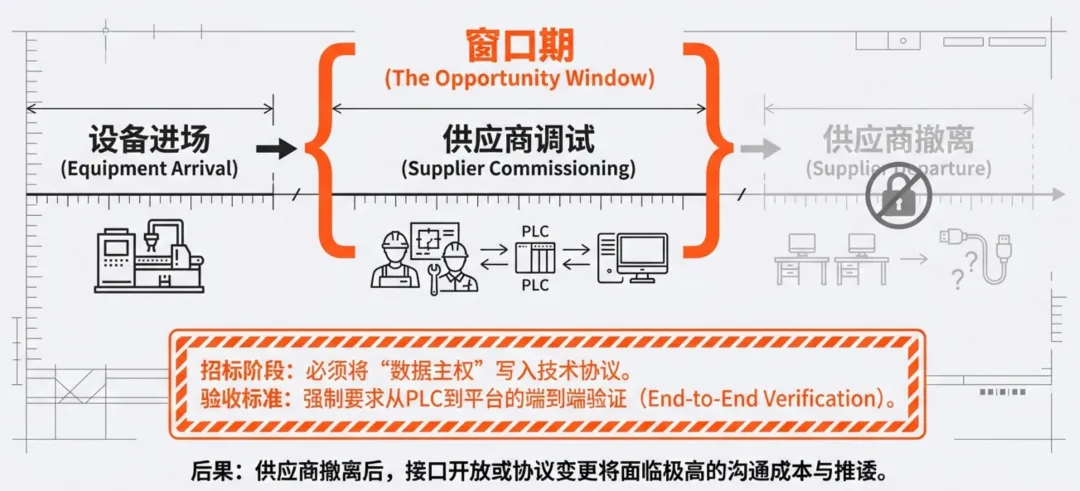
即便路径选对了,很多项目依然会死在最后一步:数据的物理通断。对于管理者而言,项目初期的最大风险往往不在于“怎么采”,而在于“谁来保”。在设备进场、供应商尚未撤离的窗口期,是建立数据链路的最佳、甚至可能是唯一的时机。一旦供应商完成验收并撤离现场,任何后续的数据接口开放或协议变更,都会面临极高的二次沟通成本。甚至可能因为原厂工程师的变动、知识产权的扯皮,而让原本简单的取数需求陷入僵局。因此,无论采取哪种路线,必须在招标阶段就将“数据主权”写入技术协议。这不仅是列出几个字段名,而是要强制要求供应商在交付验收前,必须配合完成从设备PLC到数采平台的端到端验证,确保链路是通的,而不仅仅是“理论上支持”。分层耦合策略:如何实现“轻量化起步”与“标准化沉淀”?
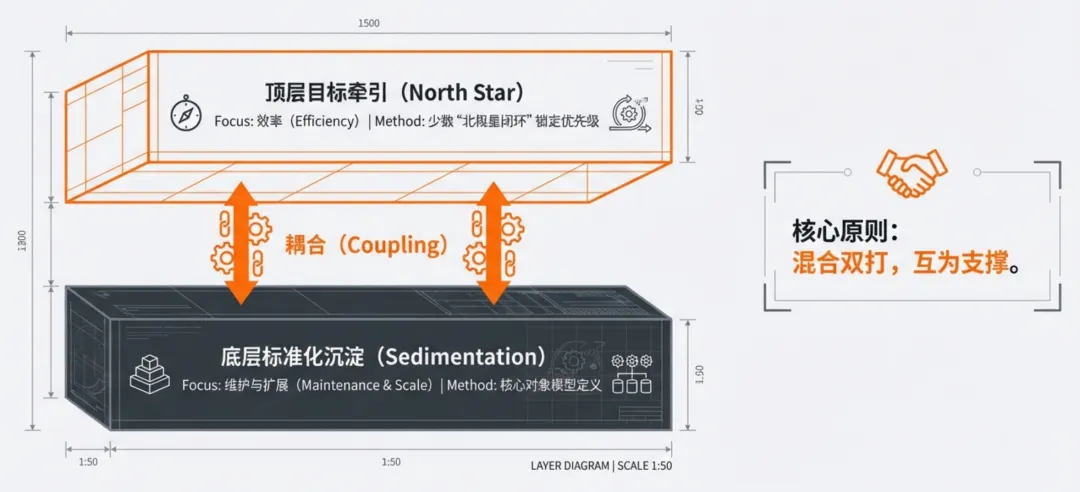
在解决了“能不能采到”的物理前提后,接下来要解决的是“采什么”的效率问题。在真实的工厂环境下,单纯依靠某种路线都是危险的。最稳妥的量产打法是“顶层目标牵引 + 底层标准化沉淀”,即在不同层级采用不同的策略。顶层应当通过少数“北极星闭环”来锁定采集优先级。例如,只选定瓶颈设备的OEE、关键工艺的SPC漂移等3-5个核心场景,确保这些闭环所需的数据必须实时、准确。这能让数字化团队摆脱“漫无目的”的忙碌,将资源投射到最能产生经济效益的环节。中层与底层则需要通过标准化来降低长期的维护成本。无论上层应用如何变,设备状态、工单节拍、物料批次、工艺版本、人员资质这五大核心对象,必须在接入时就完成对象模型定义。同时,遵循“80/20原则”,先覆盖核心闭环涉及的关键瓶颈设备,保证系统能快速产生价值,再根据业务演进逐步扩展到全线。管理者的决策清单:不同阶段的工厂该怎么选?
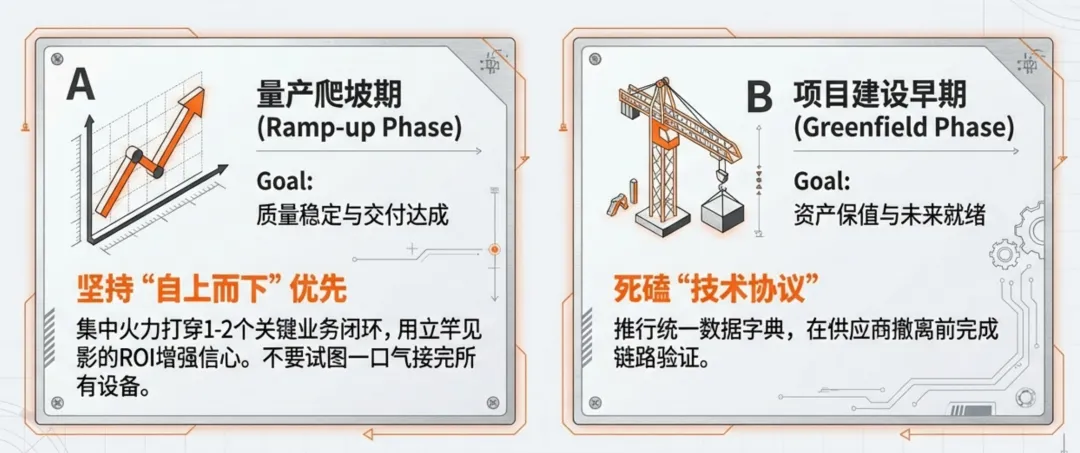
如果你的工厂处于量产爬坡期,且最关心短期内的质量稳定和交付达成,那么请坚持“自上而下”优先。这种情况下,不要试图一口气接完所有设备,而是要集中火力打穿1-2个关键的业务闭环,用立竿见影的ROI来增强团队对数字化的信心。如果你的工厂还在项目初期或建设早期,面对的是大量异构设备进场,那么必须在招标和进场阶段卡住“技术协议”。除了推行统一的数据字典,更要在供应商撤离前完成链路验证,为未来保留真正可用的数据通路。这不仅是技术准备,更是对未来资产的保值。无论采取哪种策略,核心的评判标准只有一个:这些数据是否真正参与了生产管理。如果异常发生后,没有系统触发报警,没有责任人处理,没有验证环节,那么采集再多数据也只是数字游戏。让数据在流动的过程中产生价值,远比把它们存在昂贵的服务器里更重要。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
