影刀RPA如何按10行一组循环读取Excel?以IMA知识库一次导入10条链接为例
- 2026-05-16 22:07:29
"888"即可获得《RPA元素定位实战指南:XPath从入门到精通》电子版,直接送,无任何转发套路
*更多RPA自动化应用解决方案见往期分享,有RPA自动化工具定制需求的老板后台滴滴~
用过腾讯IMA知识库的铁子都知道,我们在导入外部公开访问链接时,系统有个硬限制——一次最多只能输入10个网址,超过不给提交。
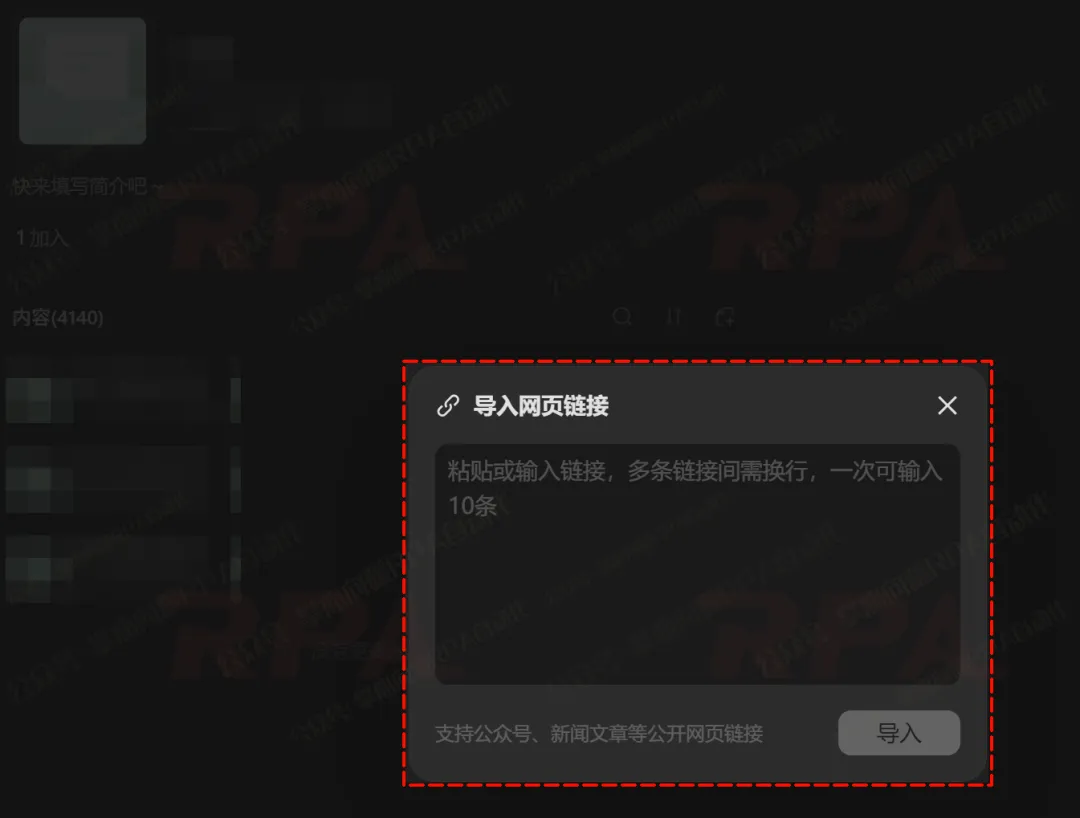
如果你只有七八条链接,手动贴一下几秒钟也就完事了。但现实是:但凡想创建自己知识库的,哪个手里不是攒了百千条链接,
难不成真要:手动复制→ 粘贴 → 提交 → 再复制→ 再粘贴 → 再提交……循环往复几十次?

大概率数到第5轮的时候,你已经不确定自己数到哪了。数到第10轮的时候,你开始怀疑人生。 数到第15轮的时候,你想砸电脑。
说实话,这种活干10分钟人就麻了,纯粹是在拿注意力换体力!
而且不只是IMA。你去看看,批量导入商品一次最多20条、CRM系统导客户单批有上限、API接口每次最多提交50条……这类"系统限制单批数量"的场景,工作中到处都是。
那问题来了:遇到这种限制,怎么用RPA自动化分批循环处理呢?
下面我仍以"ima知识库导入链接"为例,来说说通用的处理逻辑。
一、背景重述
现在我手头已经有了一个存储链接的Excel表格,其中:表格首行是"表头字段",A列是"链接"列,B列为"状态"列。
现在需要:从该Excel表格里,每次读取A列连续10行的数据,在ima中导入,并在表格对应的状态列区域写入"已完成"。再跳到下一组10行,循环往下执行,直到读完整个表。
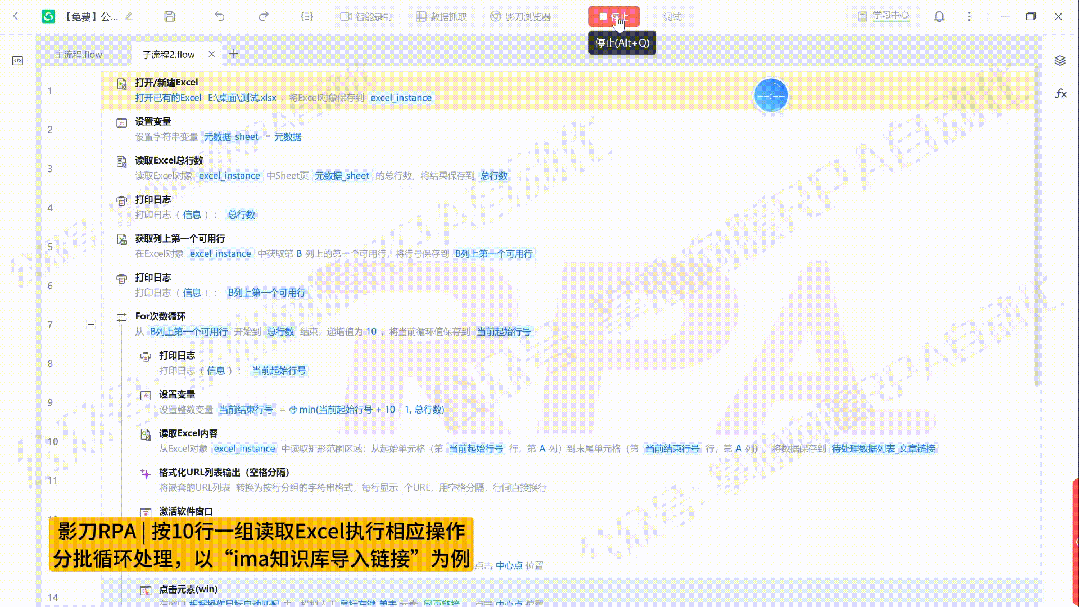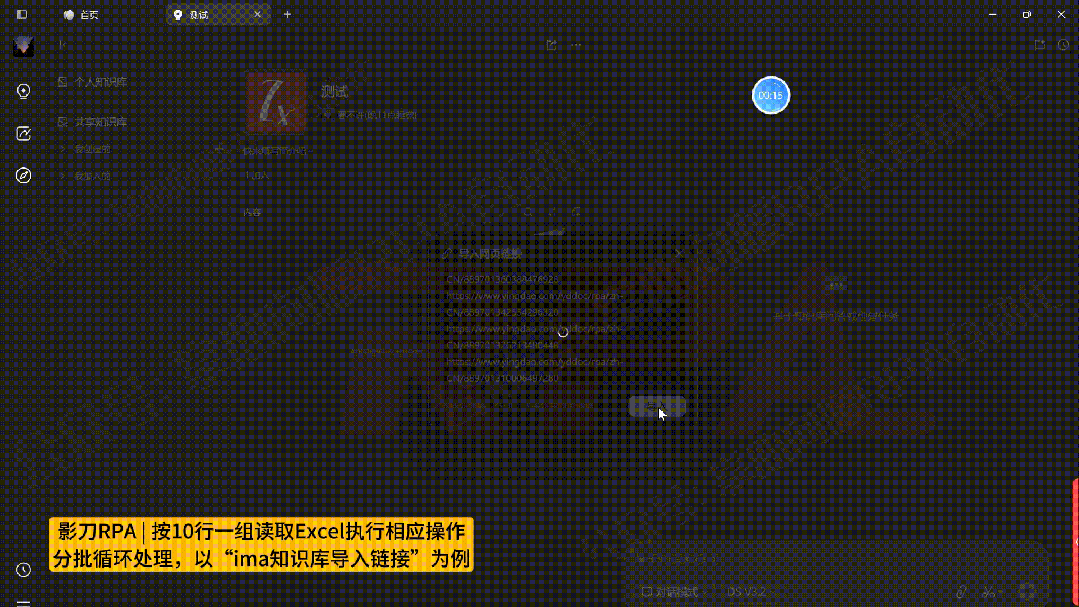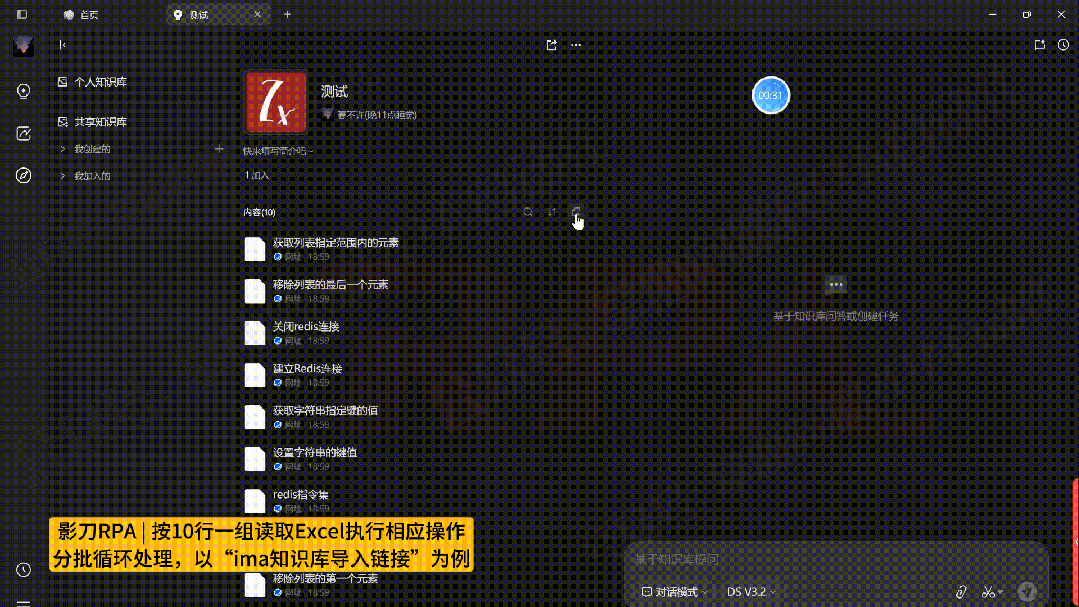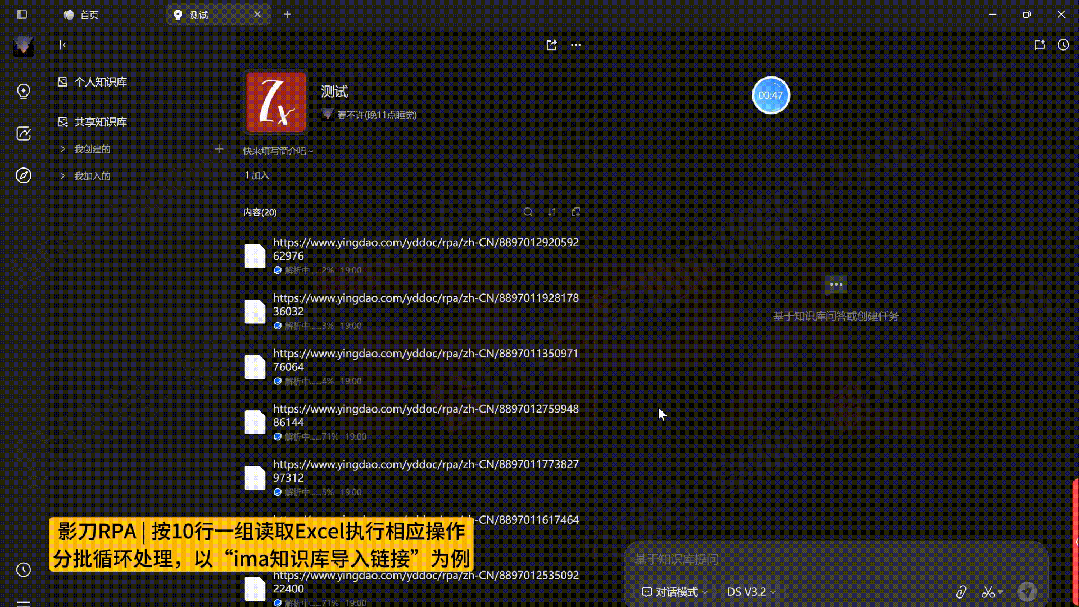
二、流程拆解
1. 指令长图
2. 流程拆解
1)初始化
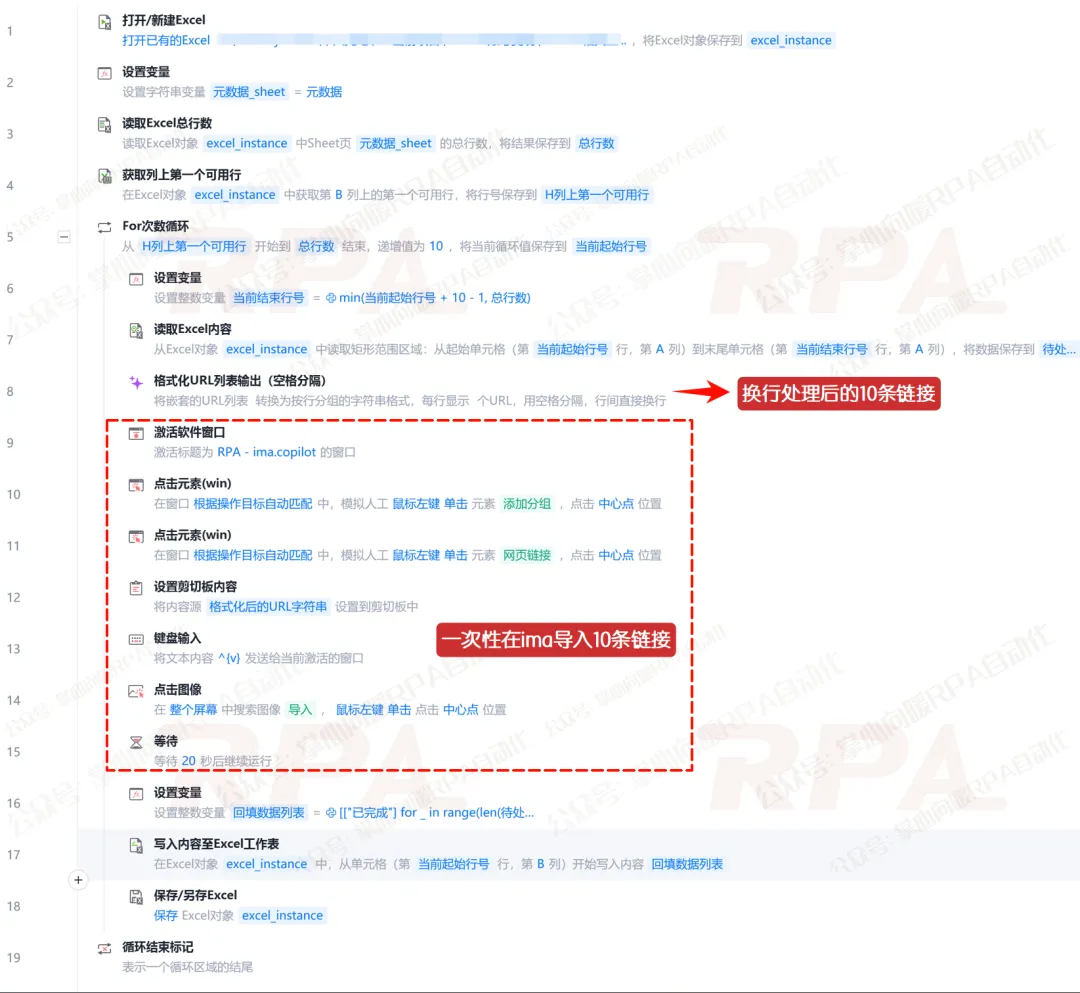
打开表格:首先使用"打开/新建Excel"指令,选择我们要处理的数据源文件。
获取总行数:紧接着用"读取Excel总行数"获取该表的最大数据行数,存入变量【总行数】,这样机器人才知道循环到哪里应该停下。
每轮循环开始行:使用"获取列上第一个可用行"指令,每轮从该行开始往下数。
2)分段循环
这里我们需要设置一个带步长的次数循环,告诉机器人:你要从第X行(即前述"循环开始行")开始,每次跨10行跑一轮。”
对应的,"For次数循环"指令的配置:"起始数"选择第一步获取的【状态列上第一个可用行】,"结束数"选择第一步获取的【总行数】,"递增值(步长)"填入【10】。
这样设置后,假设起始数为2,则:循环每次跑起来时,【当前起始行号】的值就会是 2、12、22、32…… 完美卡准了每一个批次的第一个数据行号。
有了批次的"头",还得算出批次的"尾",后面才能精准读取这一块区域。
这里我们使用"设置变量"指令创建一个【当前结束行号】变量。点亮Python表达式模式,输入:min(当前起始行号 + 步长 - 1, 总行数)。
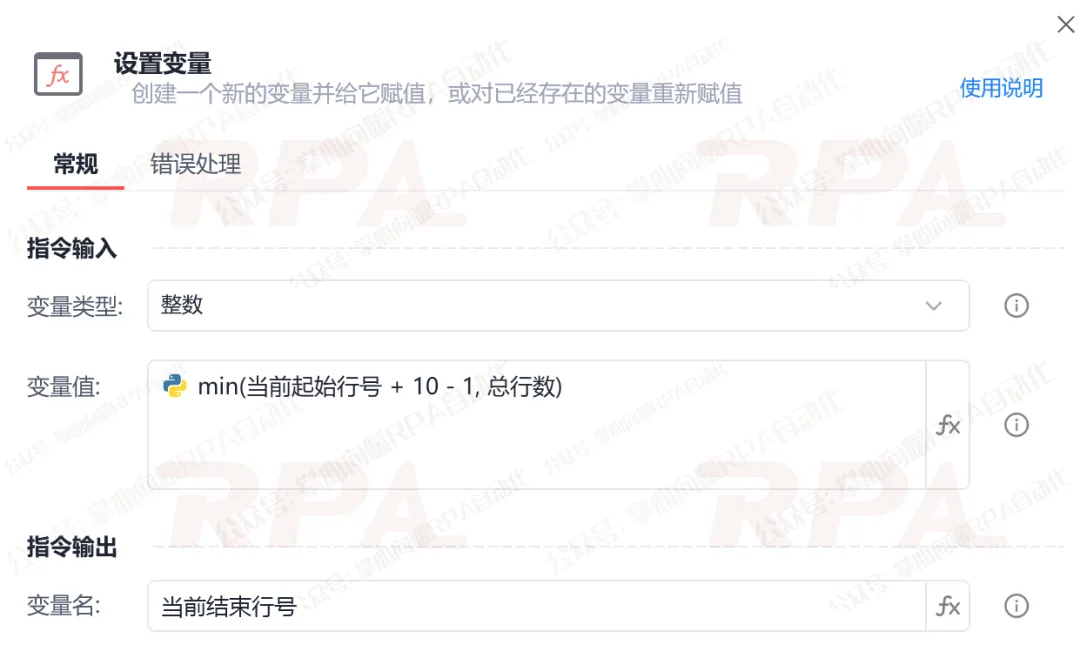
*为什么要加 min 函数? 这是为了防止越界报错。比如表格总共只有 25 行,当循环到第 22 行时,如果没有 min 函数限制,它会去读 22-31 行,此时加上 min 就能确保它最多只读到最后一行(第 25 行)。
3)批量读取
上一步我们已经把当前批次的范围算出来了,紧接着就可以一次性读取出来了。
执行读取:使用"读取Excel内容"指令,选择【区域内容】。起始单元格设为 "A"列 + 当前起始行号,结束单元格设为 "A"列 + 当前结束行号,将这 10 个数据存入【待处理数据列表】。
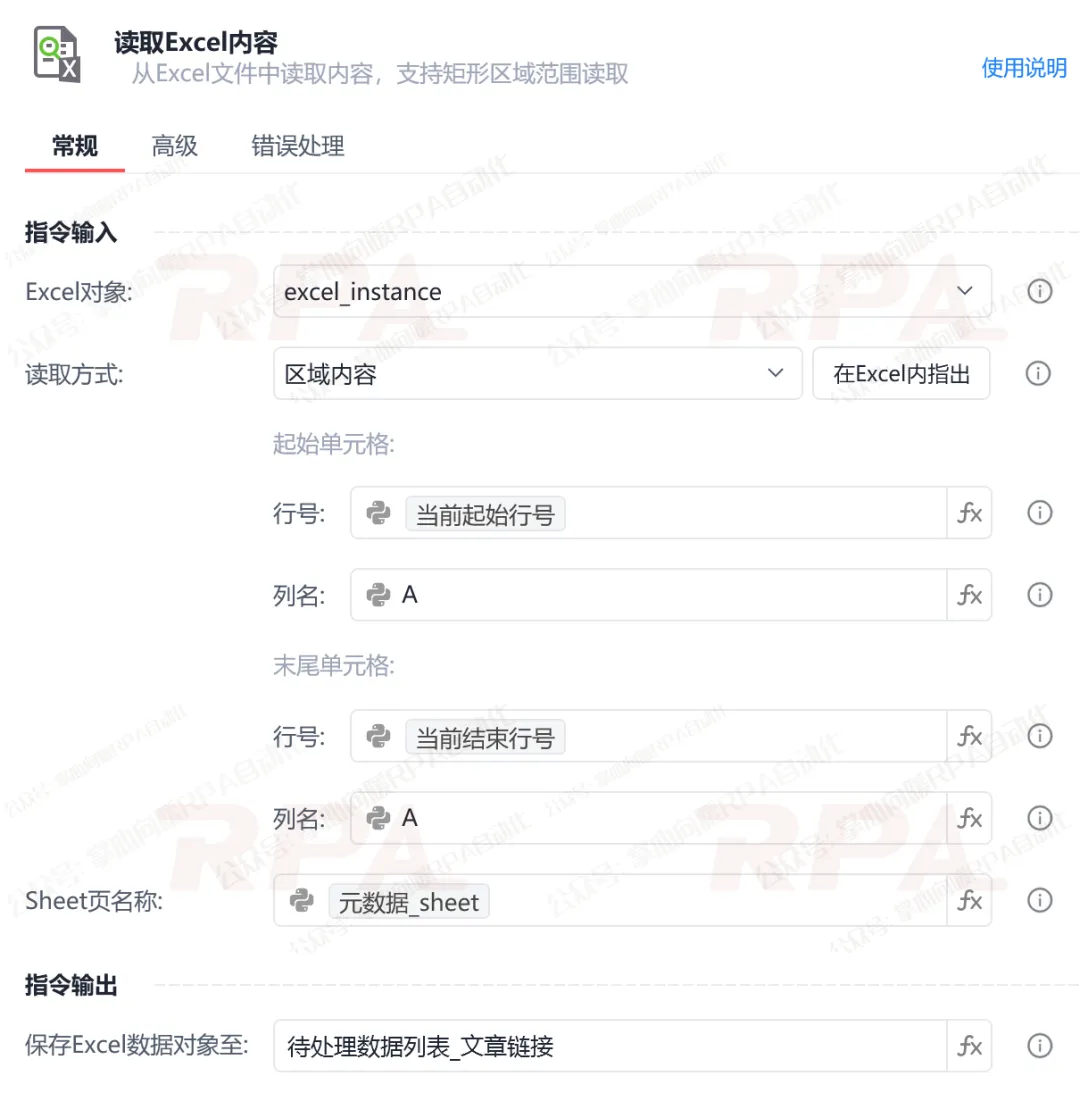
格式处理:现在,RPA机器人已经记住了这10条数据构成的二维列表。由于IMA导入链接要求链接换行,所以这里我们还需要将这10条数据构成的二维列表做格式处理。*推荐使用"魔法指令"一步到位。
from typing import *try:from xbot.app.logging import trace as printexcept:from xbot import printdef format_url_list_with_spaces(url_list, urls_per_line=3):"""title: 格式化URL列表输出(空格分隔)description: 将嵌套的URL列表 % url_list % 转换为按行分组的字符串格式,每行显示 % urls_per_line % 个URL,用空格分隔,行间直接换行。inputs:- url_list (list): 嵌套的URL列表,每个子列表包含一个URL,eg: "[['https://example.com'], ['https://test.com']]"- urls_per_line (int): 每行显示的URL数量,默认为3,eg: "3"outputs:- formatted_output (str): 格式化后的URL字符串,eg: "https://example.com https://test.com""""if not url_list:raise ValueError("URL列表不能为空")def _extract_urls(nested_list):"""提取嵌套列表中的URL"""urls = []for item in nested_list:if isinstance(item, list) and len(item) > 0:urls.append(item[0])else:raise ValueError("输入格式不正确,每个子列表应包含至少一个URL")return urlsdef _format_urls_with_line_breaks(urls, per_line):"""将URL列表按指定数量分行格式化,用空格分隔"""lines = []for i in range(0, len(urls), per_line):line_urls = urls[i:i + per_line]lines.append(" ".join(line_urls))return "\n".join(lines)# 提取URLurls = _extract_urls(url_list)# 格式化输出formatted_output = _format_urls_with_line_breaks(urls, urls_per_line)return formatted_output
4)唤醒IMA客户端,执行导入操作
激活ima软件窗口,在知识库页面,点击"添加"图标,在弹出的下拉选项中再次点击"网页链接"。
然后将之前格式处理后的链接粘贴进去,最后点击"导入"按钮,等待平台自动新增/解析。
5)批量回填"已完成"状态标记
一轮操作执行完了,为了避免中间临时有事需要打断程序运行,这时我们可以在Excel里做个状态标记,这样下次可以接着上次的处理记录继续操作。
生成回填数据:使用“设置变量”创建一个【回填数据列表】,Python 表达式:[["已完成"] for _ in range(len(待处理数据列表))]。
这行代码的意思是:刚才读了几行数据,就生成几个包裹着“已完成”的二维列表。

区域写入:使用"写入内容至Excel工作表"指令,写入范围依然选择【区域】。起始单元格对准状态列(比如 "B" + 当前起始行号),把【回填数据列表】一把填进去。


你有没有算过,每天多少时间浪费在重复操作上?未来,自动化将是职场的基础能力。掌握RPA,你就能把重复的工作交给机器人,把创造力留给自己。


2. 如果你希望及时获取最新推送,请关注本公众号并标星⭐。
3. 扫描下方二维码,无套路领取《XPath元素定位指南简略版及辅助插件》。