导读:游戏公司的 AI 翻译流程搭建,可能 99% 的火力都集中在如何提升机翻质量上了,却往往忽略了最基础的文档工程能力。一旦遇上稍微带点排版的文档格式,就当场歇菜。很多时候,明明机翻质量就能凑合用的文档,只因为全员“没手”(没人愿意干预处理和排版),最后索性外包给乙方,只为了买个“格式整齐”。机翻这头大象并不难装,难的是怎么把冰箱门打开(原文提取),再把冰箱门关上(译文回填)。
缘起:一次睡前冲浪引发的脑洞
昨晚刷手机时,无意间瞥见 Kimi 宣传其办公文档能力的广告,一个“偷懒计划”瞬间在脑海中成型。
今早直接拉 Kimi(云端代码解释器)和 Antigravity(本地强执行 Agent)同步展开两组测试,并得出了最终方案。结果令人大跌眼镜:有时候,更“轻”的工具反而更能打。
解题思路:ETL 工作流
PPT 翻译一直是本地化流程里的“隐形刺客”。直接扔进翻译引擎?排版炸裂。人工复制粘贴?Ctrl+C/V 按到肌腱炎。
最科学的解法是借鉴数据工程的 ETL (Extract-Transform-Load) 思路:
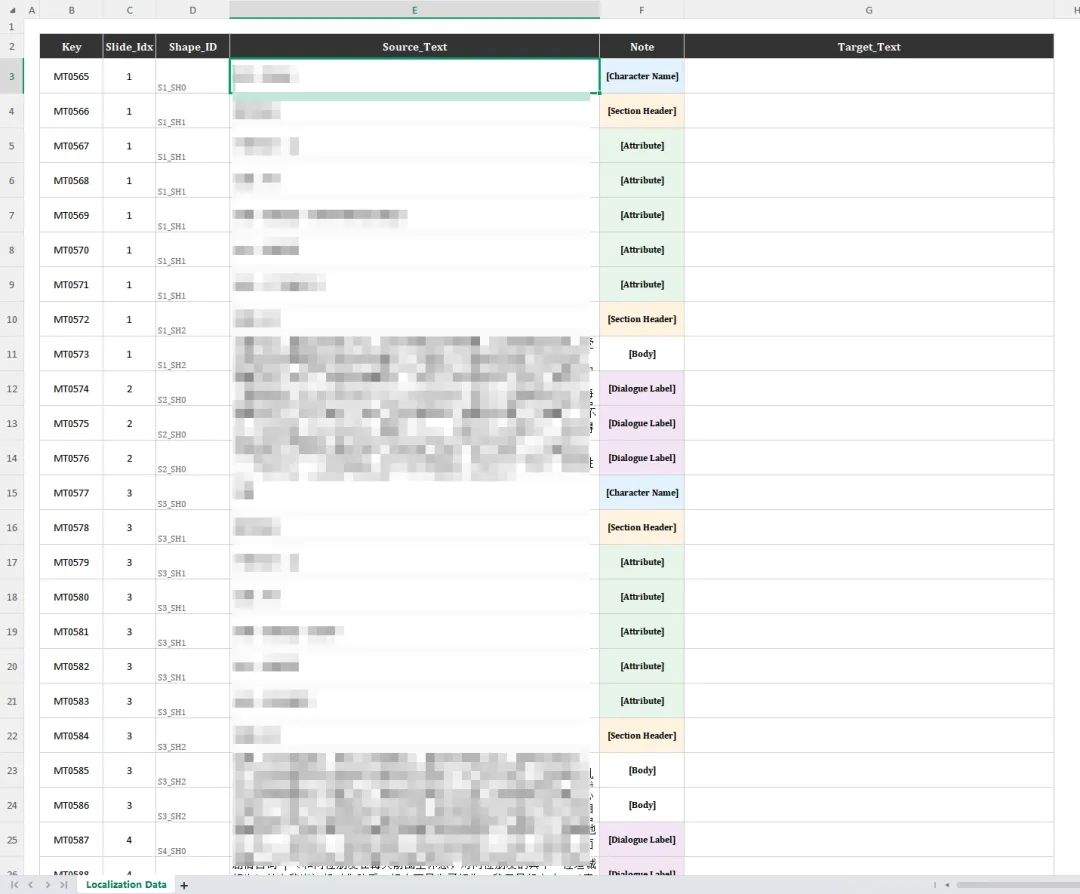
- Extract (提取):把文字精准提取到 Excel,并生成唯一身份证(Key)。
- Transform (转换):用 Excel 格式舒舒服服地衔接原有的 AI 翻译流程。
- Load (回填):带着身份证号,把译文精准填回 PPT 原位,且保留格式。
为了实现这个自动化闭环,我们给两位 AI 选手下达了相似的指令。
🟢 选手一:Kimi (网页版/代码解释器)
战术风格:保姆级微操,逻辑理解满分。
我给 Kimi 投喂了一个包含复杂排版(角色立绘、多文本框组合)的“某游戏角色设定 PPT”,并附带了一段精心设计的 Prompt(文末附赠)。
1. 提取阶段:令人惊艳的“语境侦探”
Kimi 并没有简单地调用 python-pptx 瞎抓一通,而是完美执行了我的核心诉求:
- 视觉排序 (Visual Sorting):它真的听懂了!它没有按 PPT 默认的图层顺序(谁先画谁在前面)提取,而是按“从上到下、从左到右”的人类阅读顺序排列。翻译时,上下文终于连贯了!
- 智能打标 (Context Note):这是最“AI”的地方。Kimi 自动分析了文本特征:
- 只有一两个字的,标记为
[Attribute](属性);
- 颗粒度把控:它将 PPT 拆解成了 71 条 独立的句段(Segment),完美符合 CAT 工具的口味。
2. 回填阶段:完美的“无缝衔接”
当我把翻译好的 Excel 扔回给 Kimi,要求它生成新 PPT 时,它展现了极强的稳定性。下载回来的 PPT,格式几乎未动,字体颜色保留,文字精准归位(内容涉密,不便截图)。
Kimi 表现总结:
🔴 选手二:Antigravity (本地 Agent)
战术风格:直男程序员,推一下动一下。
我对 Antigravity 采用了更开放的“甲方策略”:告诉它意图,让它自己规划路径。结果,它演示了什么叫“过度工程化”和“甚至不如不干”。
1. 提取阶段:灾难现场
Antigravity 在本地目录里生成了一堆中间文件,噼里啪啦跑了一通代码,最后交出来的 Excel 让人两眼一黑:
- 幽灵字符:原文里莫名其妙混入了
[Row 1, Col 1] 这种代码残留,清洗这些比翻译还累。 - 逻辑粗暴:它把一整页甚至一大块文本框的内容“硬拼”在了一个单元格里。71 条细分句段被它压缩成了 22 条大文本块。这对翻译记忆库(TM)来说是毁灭性的打击。
- 视觉脏乱:生成的 Excel 毫无美感,纯粹是数据的堆砌。
2. 交互体验:心累
- 权限狂魔:每一步操作都要问我“允许吗?”,仿佛一个没断奶的实习生。
- 效率低下:写计划 -> 确认 -> 报错 -> 修正 -> 再确认。虽然它很严谨,但在这个轻量级任务上显得极其笨重。
Antigravity 表现总结:
- 结论:在流程没跑通前,就被我“快刀斩乱麻”终止了测试。
⚔️ 赛后复盘:为什么 Kimi 赢了?
这次对比揭示了一个深刻的道理:在办公自动化领域,"懂业务" 比 "懂代码" 更重要。
Prompt 的胜利: Kimi 的成功,很大程度上归功于我们那段“保姆级 Prompt”。提示词明确定义了“视觉排序”、“Key 生成规则”和“语境判断逻辑”。Kimi 的长文本理解能力让它完美消化了这些需求,并转化为了 Python 代码。
- 启示:把 AI 当成高级工程师,而不是许愿池。你给的逻辑越细,它干活越漂亮。
云端一体化的优势: 对于 PPT 处理这种不需要极高算力、但需要环境配置(Python 库)的任务,Kimi 这种“开箱即用”的 Sandbox 环境,比需要在本地配置环境、确认权限的 Agent 要丝滑太多。
颗粒度的艺术: Antigravity 输在“太像程序员”。程序员看到 PPT,想到的是 Object 和 Container;而 Kimi(在我们的引导下)看到了 Segment 和 Context。前者是数据搬运,后者是本地化工程。
🎁 附赠:价值百万的“Kimi 炼金咒语”
想复刻 Kimi 的完美表现吗?这是本次测试我采用的 Prompt,拿走不谢:
第一步:智能提取(Extract)
(上传 PPT 后发送)我需要你对上传的 PPT 进行“智能本地化提取”。核心任务:解析 PPT,提取所有文本,并生成 Excel。关键逻辑(请严格执行):
- 视觉排序:请务必按文本框的物理位置(先 Top 后 Left)排序,模拟人类阅读顺序,不要按图层顺序。
- 智能 Key:新增 Key 列,从 MT056 (按需调整) 开始自增,作为唯一身份证。
- 语境侦探:新增 Note 列。根据字数和位置推测功能(如 [Title], [Body], [UI])。
- 输出列:Key, Slide_Idx, Shape_ID (用于回填), Source_Text, Note, Target_Text (留空)。
第二步:精准回填(Load)
(上传翻译好的 Excel 后发送)请读取 Excel,根据 Slide_Idx 和 Shape_ID 将 Target_Text 的内容填回原 PPT。要求:保留原文本框的字体、颜色和排版格式。

