以下是《Artificial Intelligence for Molecular Biology》中第一章:词嵌入方法(Word Embedding Methods) 的精华总结,涵盖完整知识点:
引言
在人工智能与分子生物学的交汇处,一场静默的革命正在发生。要让机器理解生命的语言——DNA、RNA和蛋白质,首先需要解决的是“语言障碍”。
正如书中 Foreword 所言,“应用AI方法进行基因组和蛋白质组序列分析的主要障碍在于AI专家与生物学家之间的鸿沟。” 第一章《Word Embedding Methods》正是为了架起这座桥梁而存在。它不讲枯燥的代码,而是深入浅出地解析了如何将生物学的“字母”转化为AI能理解的“向量”。
本文将带你精读本书第一章,揭开词嵌入(Word Embedding)技术在生物信息学中的核心应用。
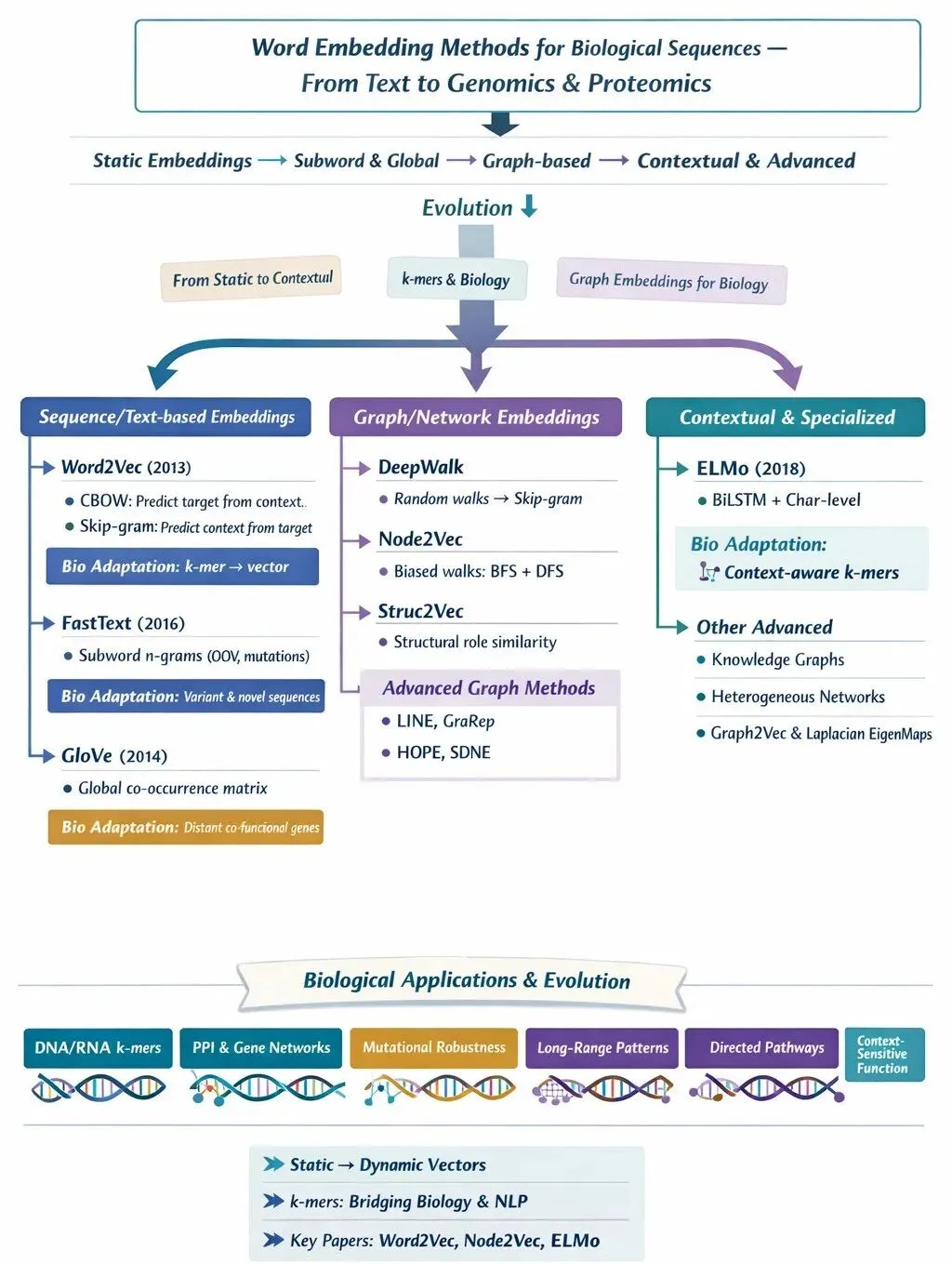
1. Word2Vec:从统计到语义
核心概念: Word2Vec 是词嵌入时代的开端(2013年)。它打破了传统“词袋模型”和“TF-IDF”的局限,不再将词语视为独立的符号,而是通过上下文捕捉词语的语义和句法关系。
书中详细拆解了其两种架构:
- • CBOW(连续词袋模型): 像填空题一样,利用上下文预测目标词。它通过滑动窗口提取上下文,利用负采样(Negative Sampling)优化计算效率,适合处理高频词。
- • Skip-gram: 与CBOW相反,利用目标词预测上下文。它更擅长处理低频词,能挖掘出更深层次的语义联系。
生物学启示: 在生物序列中,我们可以将 DNA/RNA 视为文本,将 k-mers(长度为k的子序列)视为单词。Word2Vec 让AI学会了“一沙一世界”,通过局部的k-mer特征去推断整个基因序列的功能。
2. FastText:打破“未登录词”魔咒
核心概念: Word2Vec 遇到了一个大麻烦:如果遇到训练中从未见过的词(Out-Of-Vocabulary, OOV),模型就失效了。
FastText(2016年)的出现解决了这个问题。它的核心洞察是:词语的内部结构(子词)包含重要信息。
- • 机制: FastText 将词拆解为字符级的 n-gram(如 拆解为 等)。
- • 优势: 即使遇到生僻词,只要它的词根或词缀在训练集中出现过,模型就能为其生成合理的向量表示。
生物学启示: 在基因突变研究中,FastText 的“子词”思想极其重要。它允许模型通过已知的基因片段(subwords)组合,去推测未知或突变后的蛋白质序列特性,极大地增强了模型的泛化能力。
3. Global Vector (GloVe):全局统计与局部上下文的结合
核心概念: Word2Vec 侧重于局部上下文,而 GloVe(2014年)则试图融合全局统计信息。
- • 机制: GloVe 构建了一个巨大的“词共现矩阵”(Co-occurrence Matrix),记录每个词在其他词周围出现的频率和距离。
- • 数学之美: 它通过矩阵分解技术,将复杂的全局统计关系压缩到低维向量空间中。它不仅关注“谁和谁一起出现”,还关注“出现的频率有多高”。
生物学启示: 在复杂的生物网络中,某些基因或蛋白质可能相距甚远,但具有高度的协同作用。GloVe 的全局视角有助于捕捉这种长距离的生物关联。
4 - 6. 基于图的嵌入:DeepWalk, Node2Vec 与 Struc2Vec
当数据不再是线性的文本,而是复杂的网络(Graph)时,传统的 NLP 方法就显得力不从心了。生物学中的蛋白质互作网络(PPI)、基因调控网络本质上都是图结构。
1.4 基础:图论与编码 章节首先介绍了图的基本概念:节点(Node)和边(Edge)。图嵌入的目标是将节点映射到向量空间,同时保留网络的拓扑结构。
1.5 DeepWalk:随机游走的先驱 DeepWalk 的灵感非常巧妙:将图上的随机游走路径视为“句子”。
- • 然后将这些序列喂给 Skip-gram 模型进行训练。
1.6 Node2Vec:有偏好的探索 Node2Vec 是 DeepWalk 的升级版。它引入了 BFS(广度优先)和 DFS(深度优先)的混合策略。
- • BFS: 捕捉节点的“局部社区”特征(类似“我和我的邻居”)。
- • DFS: 捕捉节点的“全局角色”特征(类似“我和远方的亲戚”)。 通过调节参数,Node2Vec 可以灵活地在同质性(Homophily)和结构性(Structural equivalence)之间权衡。
1.7 Struc2Vec:结构的守望者 Struc2Vec 关注的是节点在图中的“结构角色”,而不在乎它们是否直接相连。
- • 它构建了一个多层图,计算不同层级节点的结构相似度。
- • 即使两个节点相隔千里,只要它们在网络中扮演的角色相似(例如都是“枢纽”或都是“桥梁”),Struc2Vec 就会赋予它们相似的向量。
8 - 10. 高级图嵌入方法
为了更精准地捕捉复杂网络的特性,研究者们提出了更高级的算法:
- • LINE (Large Scale Information Network Embedding): 专注于保留网络的“一阶 proximities”(直接连接)和“二阶 proximities”(共享邻居)。这对于构建生物分子的邻接关系图至关重要。
- • GraRep: 引入了全局结构信息,通过考虑 k-step(k步)的邻居信息,捕捉更远距离的节点依赖关系。
- • HOPE (High Order Proximity Preserved Embedding): 专门处理有向图(Directed Graph)。在生物学中,信号通路往往是有方向的(A调控B),HOPE 通过分解非对称的相似性矩阵,完美解决了这一问题。
11. ELMo:上下文感知的时代
核心概念: 传统的词嵌入(如 Word2Vec)为每个词只生成一个固定的向量,但这无法解决“一词多义”的问题(例如 "bank" 可以是河岸也可以是银行)。
ELMo(Embeddings from Language Models, 2018)引入了**上下文感知(Contextualized)**的概念。
- • 机制: 它使用双向 LSTM(BiLSTM)在字符级别上进行预训练。
- • 原理: 同一个词,在不同的句子语境下,会有完全不同的向量表示。
- • 意义: 这标志着从“静态嵌入”向“动态嵌入”的跨越。对于生物学而言,这意味着同一个基因片段在不同的序列上下文中,其功能含义可以被动态地解析。
12. 其他嵌入方法概览
章节最后对剩余的嵌入方法进行了分类综述,构建了一个完整的工具箱:
- 1. 深度学习方法(如 SDNE): 利用自编码器捕捉网络的非线性结构。
- 2. 知识图谱距离评分(如 TransE, DistMult): 将实体和关系映射到向量空间,用于处理复杂的生物知识图谱(如 Drug-Gene-Disease 关系)。
- 3. Walk Based 方法(如 TripleWalk): 基于随机游走的变体,适合处理异构网络。
- 4. MetaPath 方法(如 HIN2Vec): 专门针对包含多种节点和边类型的复杂生物网络。
- 5. 数学方法(如 Laplacian EigenMaps): 基于图论的数学原理进行降维。
- 6. 全图嵌入(如 Graph2Vec): 不再关注单个节点,而是将整个图(如一个完整的蛋白质分子)编码为一个向量。
总结:第一章不仅是技术的罗列,更是一场思维的进化
从最初的 Word2Vec 将生物学序列数字化,到 FastText 处理变异与新词,再到 Graph Embedding 处理复杂的生物网络关系,最后到 ELMo 引入动态上下文,我们看到了 AI 理解生命语言的能力在指数级提升。
对于分子生物学家而言,这些方法不再是遥不可及的数学公式,而是解读遗传密码的新显微镜。掌握这些工具,意味着我们能更早地预见疾病机制,更精准地设计药物。
推荐阅读与延伸
- • 原著章节: 《Artificial Intelligence for Molecular Biology》Chapter 1 (Muhammad Nabeel Asim et al.)
- • 经典论文: Mikolov 的 Word2Vec 论文, Grover 的 Node2Vec 论文, Peters 的 ELMo 论文。
- • 工具库: Gensim (Python), PyTorch-Geometric (图神经网络库)。
- • 在你的研究领域(如蛋白质折叠或基因预测)中,哪种嵌入方法最适合处理你的数据类型?
- • 随着 Transformer 和 BERT 的兴起(书中后续章节将涉及),传统的词嵌入方法在生物信息学中将扮演什么角色?

