两秒奇迹:把 300 个 Excel 的“查找替换苦工”直接送走
我是小李。如果说日常办公是“打怪升级”,那么企业 ERP 系统上线绝对是“地狱级副本”。你会发现,过去十年里同事们随手填写的 Excel 表格,全是雷:同一个“研发部”,有人填“研发中心”,有人填“技术部”,还有人填“R&D”。同一个供应商“A公司”,表格里有“A公司”、“A 公司”、“A-公司”十几种写法。ERP 系统很冷酷:“数据不标准,我就不让你上线。”这时候,最痛苦的人就是负责清洗数据的你。几百个 Excel + 上百条替换规则 + 每个表都要改 + 还不能改错。你以为 Excel 的“查找替换”能救你?抱歉,Excel 的查找替换擅长的是“单个文件、单次操作”。当你的任务变成“300 个文件 × 100 条规则 × 多个工作表 × 指定列/指定格式”时,它就变成了一个需要人肉驱动的按钮。这一节给你一个真实案例:用 Python 把传统 9 万分钟的苦工压缩到几秒钟,并且可复跑、可审计。办公场景:300个表格 × 100条规则的“绝望乘法”
任务量:有300 多个Excel 文件(各部门提交的)。规则量:有100 多条替换规则(比如把“旧编码A”换成“新编码B”,把“旧部门名”换成“标准名”)。操作:打开一个表 -> Ctrl+H 查找替换 -> 输入规则 1 -> 全部替换 -> 输入规则 2 -> 全部替换 …… 循环 100 次 -> 保存 -> 打开下一个表。算一笔账:假设手动处理一个表的一条规则需要 2 秒(这已经是手速极限了),那么:300 个表 × 100 条规则 × 2 秒 = 60000 秒 ≈ 16.7 小时。这还是机器人的速度,人类还要休息、还要核对、还会眼花填错。实际算下来,没个把月根本干不完。这就是 Python 的**“降维打击”**时刻。🤖 我给 AI 的指令
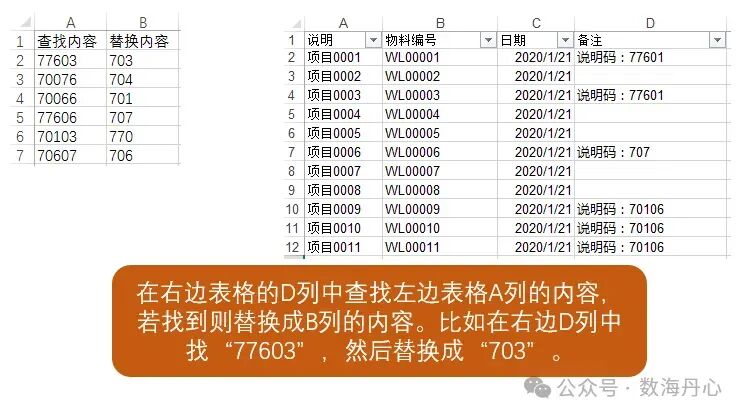
“有一个 Excel:查找替换.xlsx,A列是旧值,B列是新值。还有一个文件夹里有很多 Excel,要在每个文件的所有 sheet 中,对 D 列从第2行开始做替换:单元格格式是‘前缀:编码’,只替换冒号后的编码部分,前缀保留。批量处理并另存为新文件,打印耗时和每个文件替换数量。”
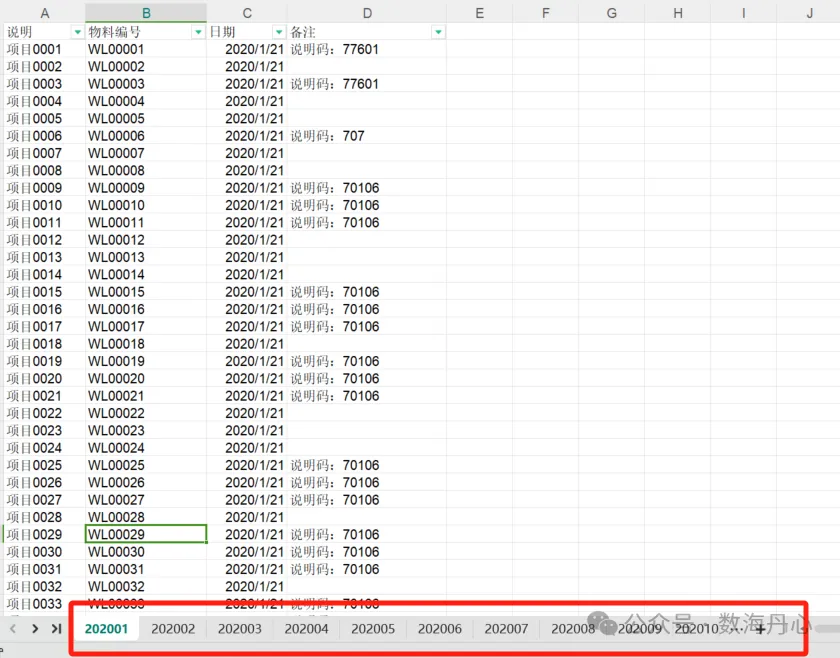
上百条查找替换规则,需要在300多个表中找到下图中A列的数据并将A列的数据替换成B列中的数据
待清理的300多个表格
import timeimport osfrom openpyxl import load_workbookdef batch_replace_data(): s_t = time.time() # 1. 读取“替换规则字典” # 就像你脑子里记住了所有的“暗号本” print("📖 正在读取查找替换规则...") try: wb_rule = load_workbook('查找替换.xlsx') ws_rule = wb_rule.active replace_dict = {} for row in range(2, ws_rule.max_row + 1): old_val = str(ws_rule['A' + str(row)].value).strip() # 转换字符串防报错 new_val = str(ws_rule['B' + str(row)].value).strip() if old_val != 'None': # 排除空行 replace_dict[old_val] = new_val except Exception as e: print(f"❌ 规则表读取失败:{e}") return # 2. 遍历待处理文件 # 假设所有文件都在 '待处理表格' 文件夹下 target_folder = './待处理表格' if not os.path.exists(target_folder): print(f"❌ 找不到文件夹:{target_folder}") return file_list = [f for f in os.listdir(target_folder) if f.endswith('.xlsx')] print(f"📂 发现 {len(file_list)} 个文件,开始批量手术...") processed_count = 0 for file_name in file_list: file_path = os.path.join(target_folder, file_name) try: wb = load_workbook(file_path) # 遍历该文件里的每一个 Sheet for sheet_name in wb.sheetnames: ws = wb[sheet_name] # 3. 核心替换逻辑(以操作 D 列为例) # 注意:这里是按你的业务场景:数据格式类似 "前缀:旧值" for row in range(2, ws.max_row + 1): cell = ws.cell(row=row, column=4) # 第4列就是D列 original_value = cell.value if original_value: str_val = str(original_value) # 业务逻辑:按中文冒号分割,取后面那段去匹配 # 例如 "ID:A部门" -> 分割出 "A部门" parts = str_val.split(":") if len(parts) > 1: key_part = parts[-1] # 取冒号后面部分 if key_part in replace_dict: # 找到了!执行替换 new_content = parts[0] + ":" + replace_dict[key_part] cell.value = new_content # print(f" - 修改:{str_val} -> {new_content}") # 保存修改后的文件(建议另存,别覆盖原文件,给自己留条后路) output_path = os.path.join('./处理完成', f"已清洗_{file_name}") # 确保输出目录存在 if not os.path.exists('./处理完成'): os.makedirs('./处理完成') wb.save(output_path) processed_count += 1 print(f"✅ 完成文件:{file_name}") except Exception as e: print(f"⚠️ 文件 {file_name} 处理出错:{e}") e_t = time.time() print(f"\n🎉 全部完成!共处理 {processed_count} 个文件,耗时 {e_t - s_t:.2f} 秒")if __name__ == "__main__": batch_replace_data()
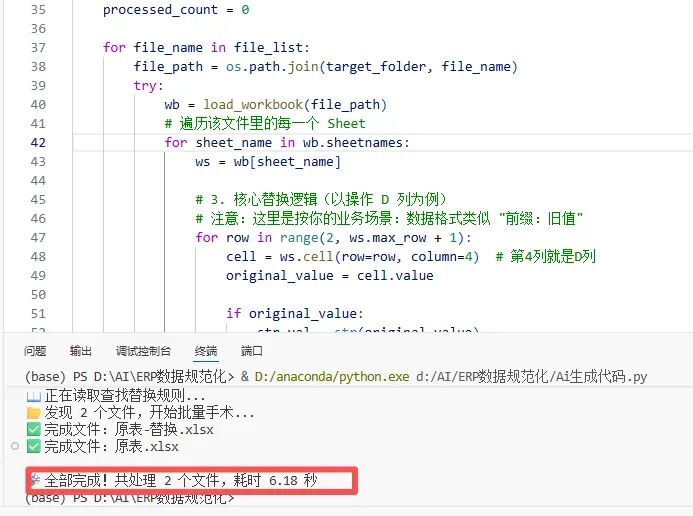
速度惊人:300 个文件,如果数据量不是几百万行那种,通常几秒到几分钟就能跑完零失误:机器不会看花眼,只要字典里有,它就一定换;字典里没有,它绝对不乱动。【小李的避坑笔记】
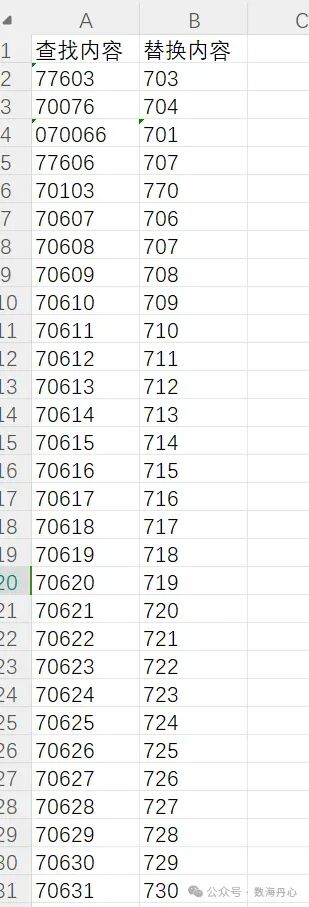
数据类型陷阱:读取 Excel 时,数字 123 和字符串 '123' 是不等的。代码里用了 str() 强转,就是为了防止“看着一样却匹配不上”的尴尬。if key_part in replace_dict 是完全匹配(精准)。如果你想把“研发中心一部”、“研发中心二部”里的“研发中心”都换掉,那就需要用 replace 字符串函数做包含匹配。AI 指令要说清楚:“请做包含查找替换”。备份!备份!备份!:批量修改文件前,千万把源文件复制一份到移动硬盘里。代码跑起来很快,删数据也很快(别问我怎么知道的)。小李的总结
Excel 的查找替换像“手持螺丝刀”:偶尔修修家电没问题。但 ERP 上线的数据规范化,是“工厂装配线”:你需要的是批处理、可复跑、可审计。剩下的交给 AI 写初稿,Python 稳定执行。从此你不再是“查找替换工”,你是数据清洗的流程设计师。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
