当需要进行数据处理时,需要将Excel的多个Sheet合并在一个Sheet中,便于查询、操作Excel表格。然而Excel内容十分多,Ctrl+C/V,会导致系统卡顿和闪退的情况。
如何使用Excel自带的合并工具实现多Sheet的合并呢?这里我们介绍Excel自带的Power Query工具来实现多个Sheet合并以及使用代码实现批量数据合并。
Excel Power Query工具:
情况1:合并一个Excel文件中的所有Sheet
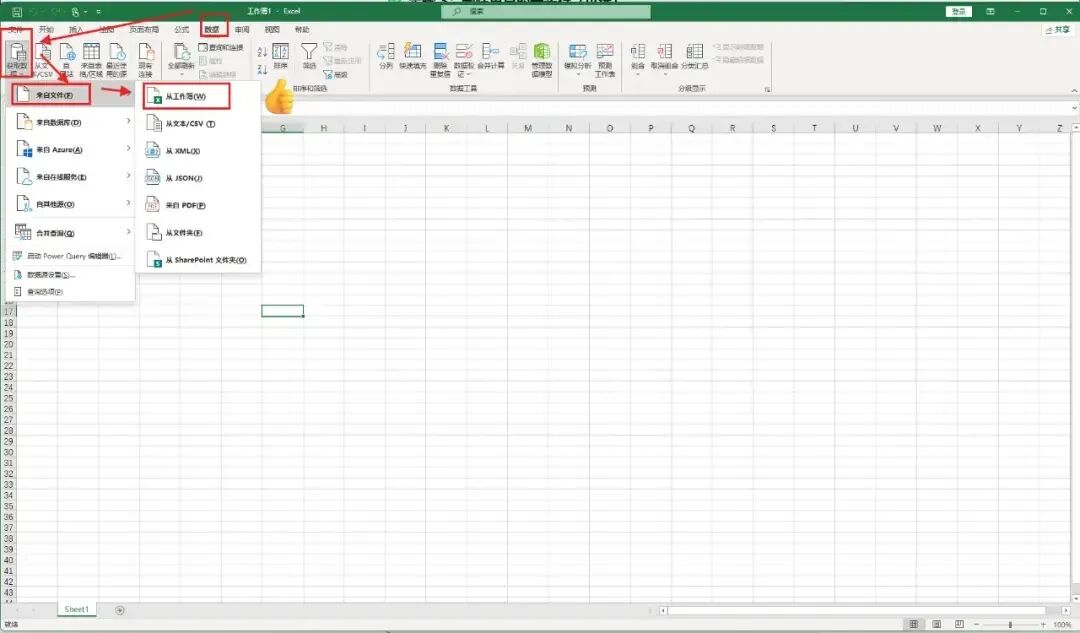
1、打开Excel,点击【数据】-【获取数据】-【来自文件】-【从Excel工作簿】
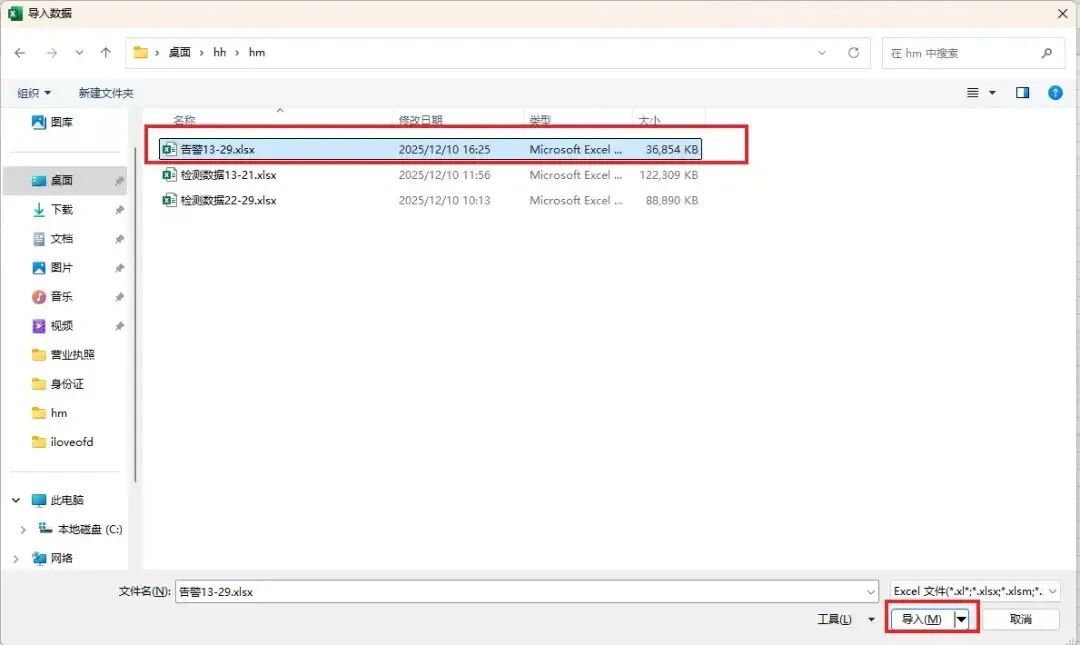
2、找到自己的工作簿文件,点击【导入】
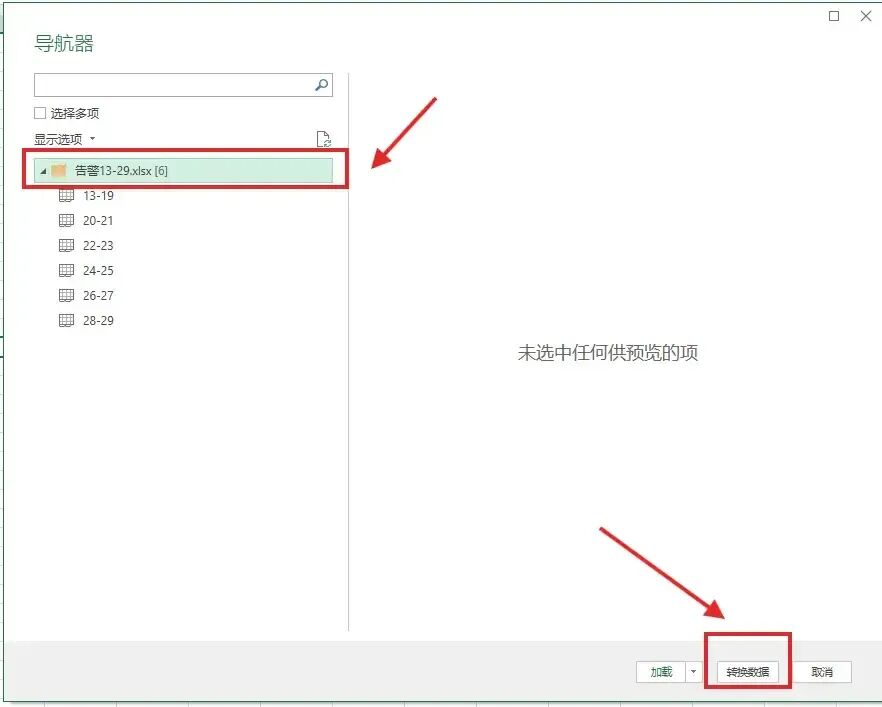
3、点击【工作簿】,也就是你的文件名,点击【转换数据】
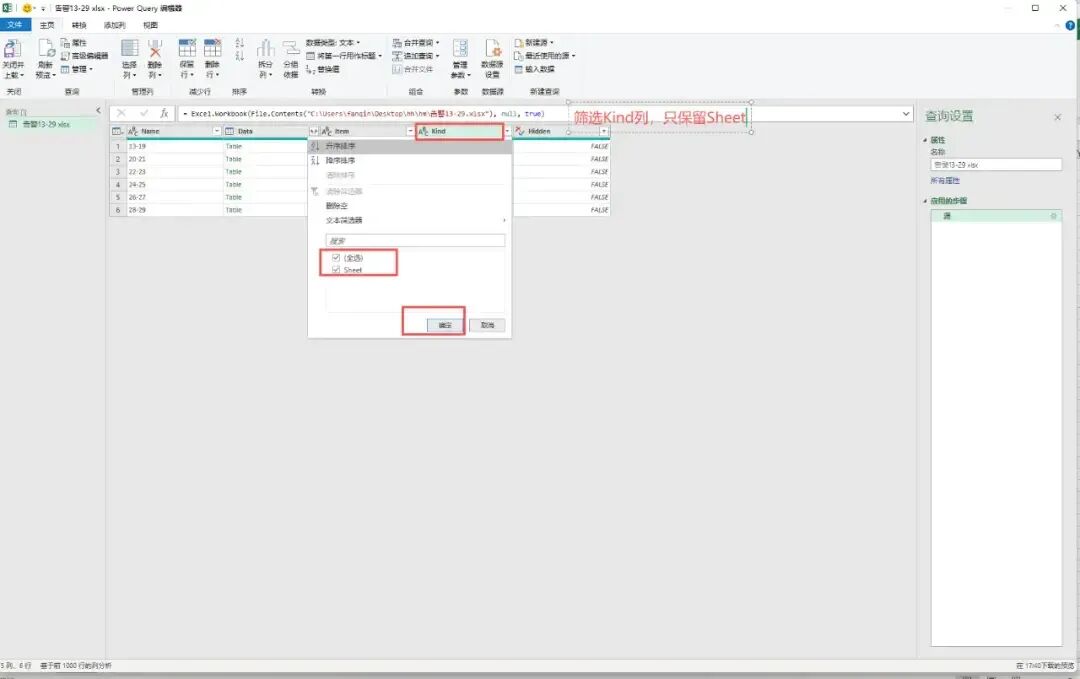
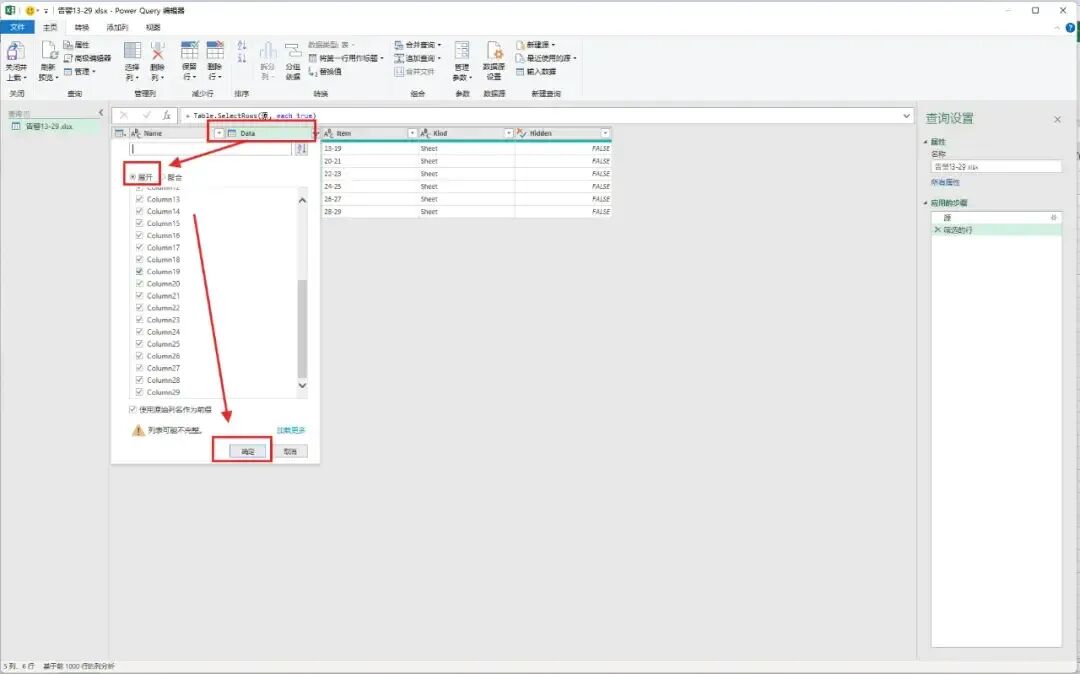
注意:必须是工作簿,如果点击sheet,后面的页面不会出来4、筛选【Kind】,去掉不是Sheet行,点击【Data -|-】,展开所有列数据,点击【确认】(删掉不要的列和行数数据就行)
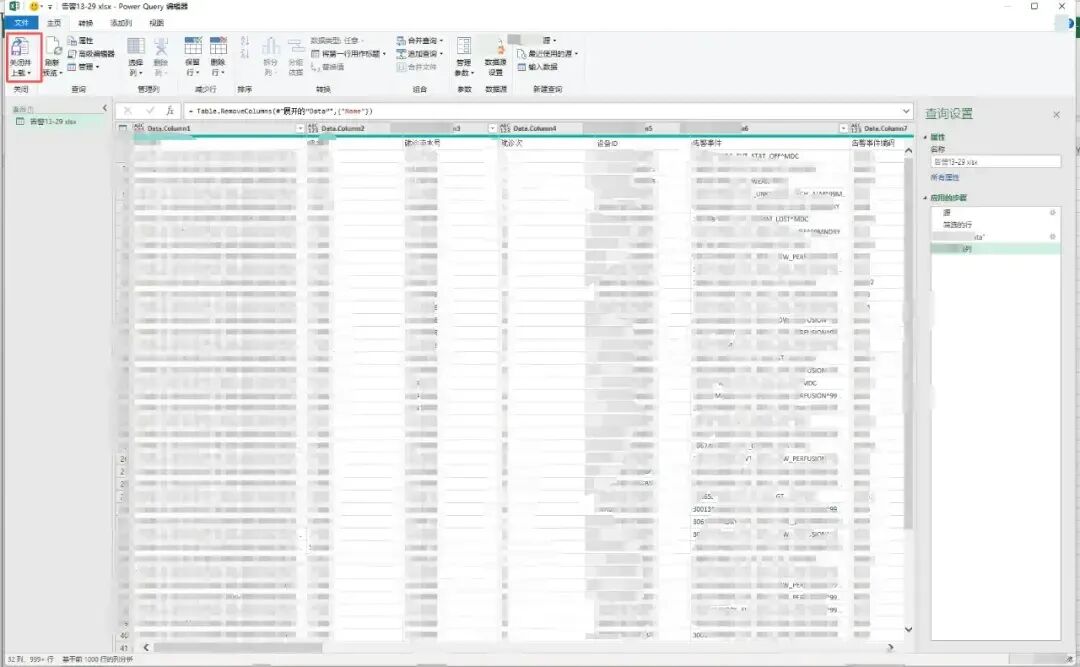
5、点击【关闭或上载】,即可看到合并的整个数据。
情况2:合并多个Excel文件中的所有Sheet
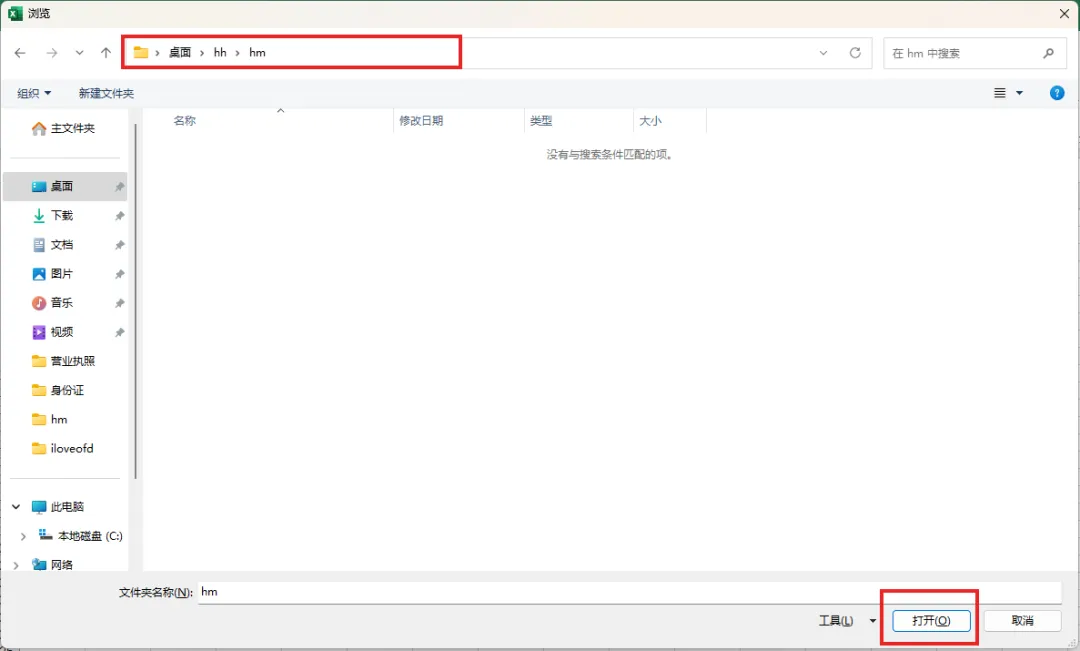
1、把所有的文件都放在同一个文件夹下,示例:文件放在桌面的hh\hm文件夹下
C:\Users\XX\Desktop\hh\hm
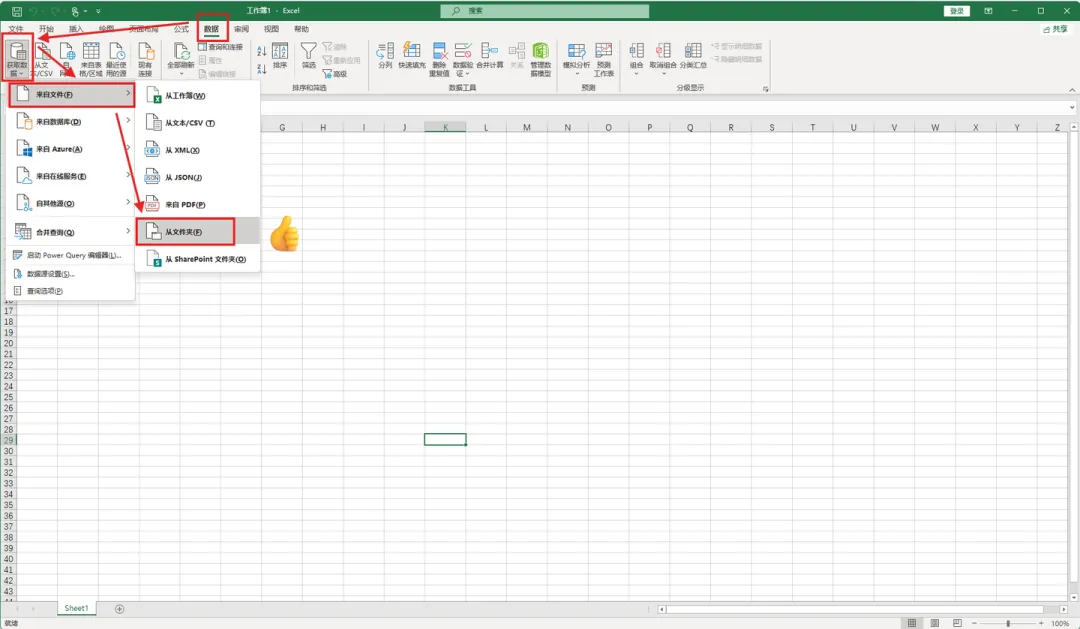
2、打开Excel,点击【数据】-【获取数据】-【来自文件】-【从文件夹】
3、找到自己的文件夹,点击【打开】
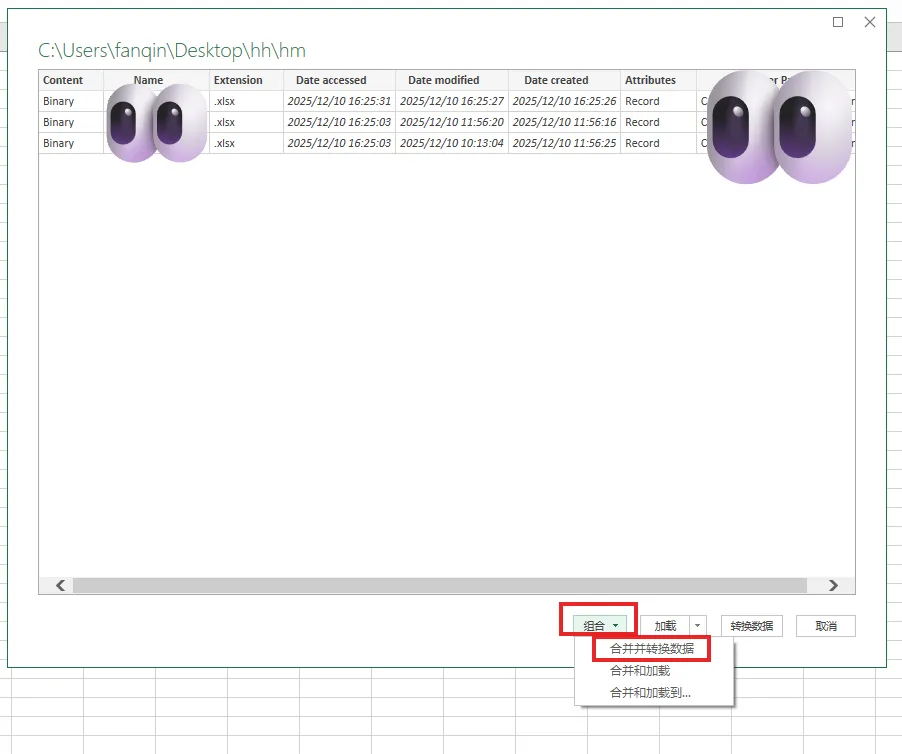
4、点击【组合】,选择【合并并转换数据】
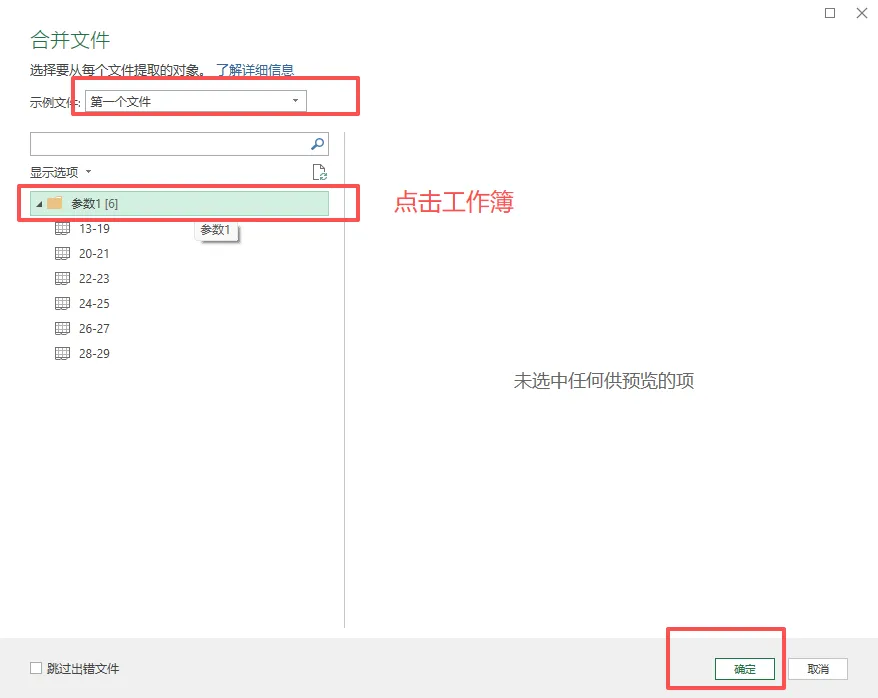
5、点击【第一个文件】,点击【工作簿】。注意不要点击下面的Sheet文件
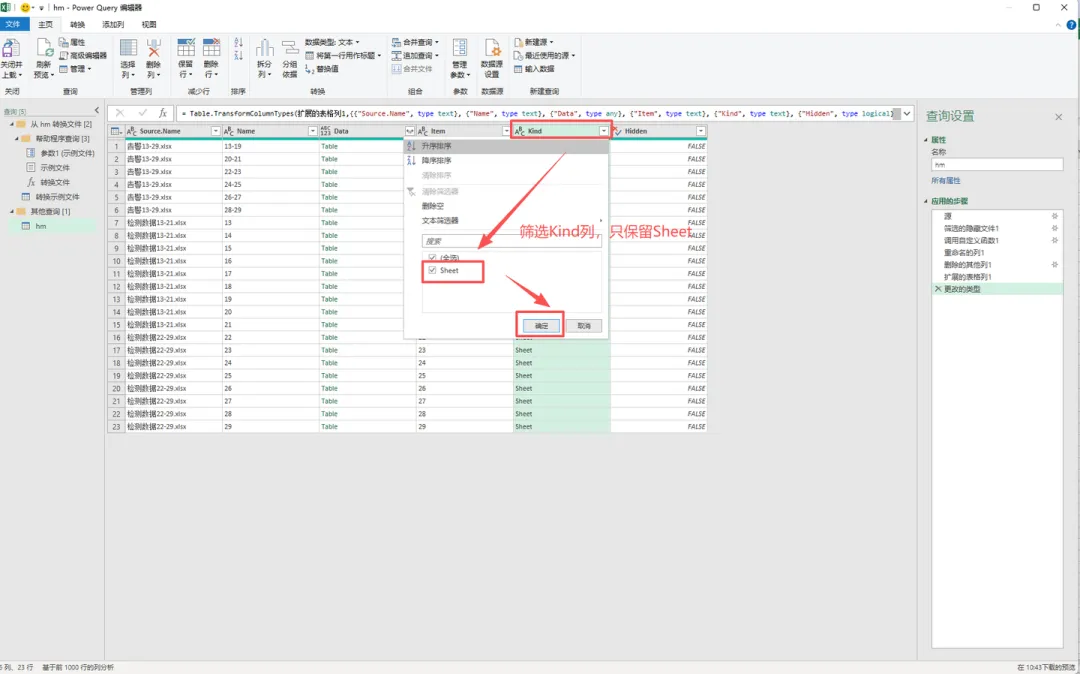
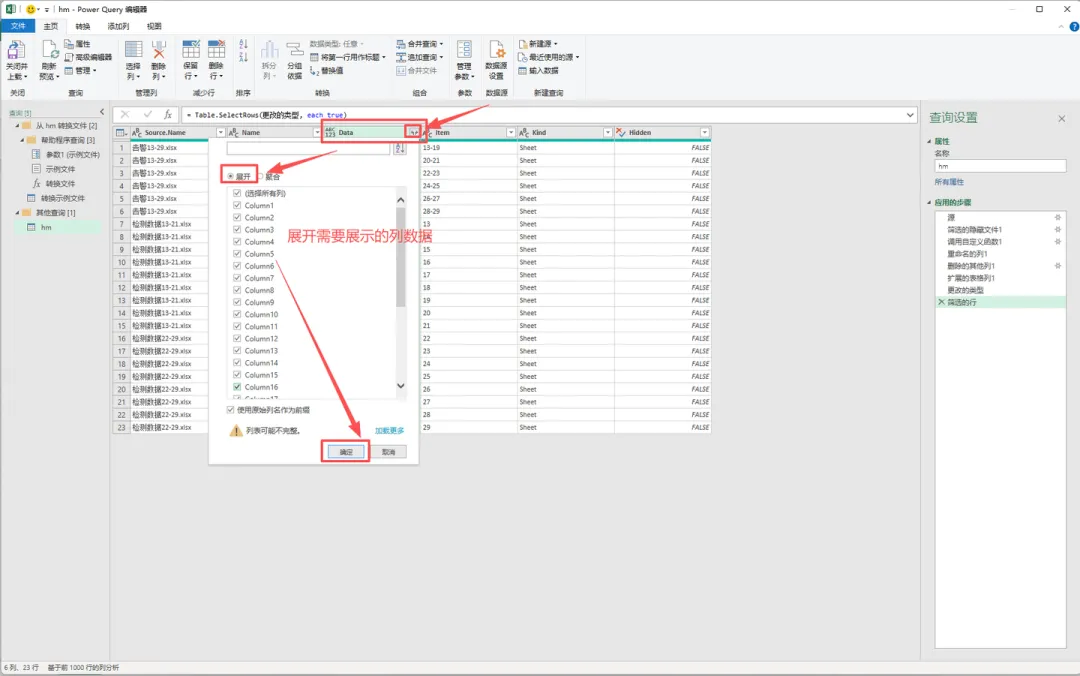
6、筛选【Kind】,去掉不是Sheet行,只保留Sheet。点击【Data -|-】,展开需要展开的数据,点击【确认】(删掉不要的列和行数数据就行)
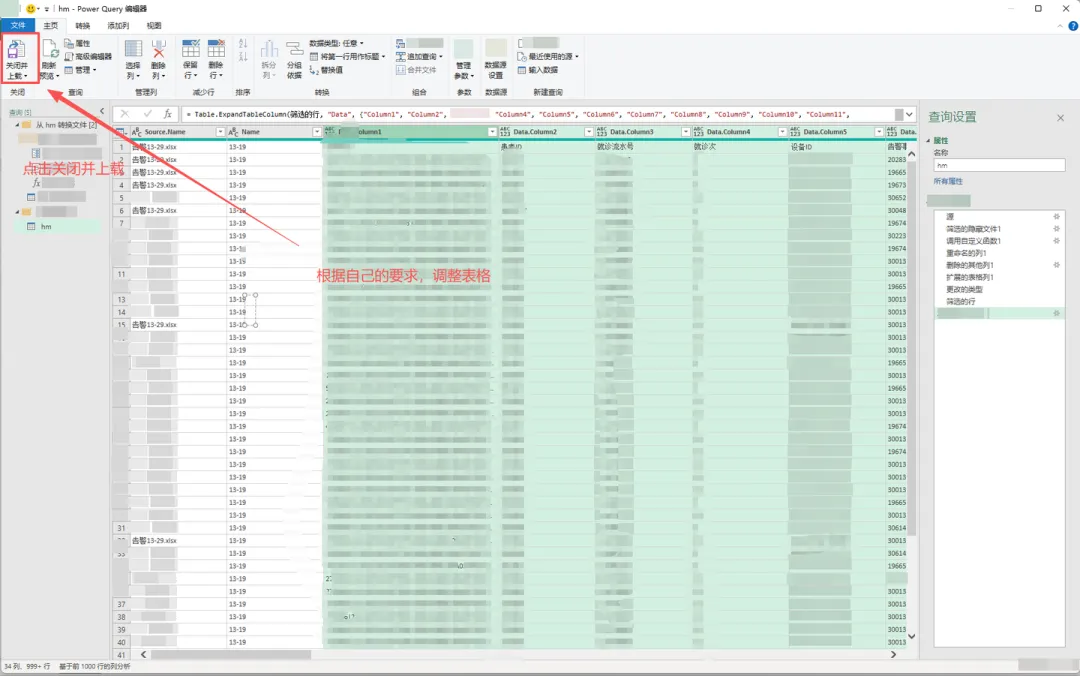
7、根据自己的要求调整表格,点击【关闭或上载】,即可看到合并的整个数据。
Python代码实现
适合文件内容多,且Sheet数量多的情形,支持批量操作和验证文件行数。
前提:需要安装运行Python的环境
安装依赖包
pip install pandaspip install openpyxl
Excel一个Sheet最多支持1048576行,若没有超过最大行数则输出Excel格式,否则输出CSV格式。import pandas as pdimport os# Excel 文件所在文件夹路径folder_path = "./excels/" # 修改为你的路径all_data = []header_saved = None# 统计信息file_row_count = {} # 每个文件的总行数skip_header_count = 0 # 被跳过的重复表头数量for file in os.listdir(folder_path): if file.endswith(".xlsx") or file.endswith(".xls"): file_path = os.path.join(folder_path, file) print(f"读取文件: {file}") total_rows_this_file = 0 # 当前文件所有 sheet 的行数之和 sheets = pd.read_excel(file_path, sheet_name=None) for sheet_name, df in sheets.items(): rows = len(df) total_rows_this_file += rows print(f" - 读取 sheet: {sheet_name}, 行数: {rows}") if header_saved is None: header_saved = list(df.columns) all_data.append(df) else: df = df[header_saved] # 判断是否为重复表头 if list(df.iloc[0]) == header_saved: skip_header_count += 1 df = df.iloc[1:] # 去掉表头行 all_data.append(df) # 保存文件总行数 file_row_count[file] = total_rows_this_file# 合并所有 sheet 内容merged_df = pd.concat(all_data, ignore_index=True)# 输出 CSVoutput_file = "merged_output.csv"merged_df.to_csv(output_file, index=False, encoding="utf-8-sig")# ========== 输出统计信息 ==========print("\n================= 统计信息 =================")print("1️⃣ 每个 Excel 文件的总行数:")for file, rows in file_row_count.items(): print(f" - {file}: {rows} 行")print(f"\n2️⃣ 被跳过的重复表头数量: {skip_header_count} 次")print(f"\n3️⃣ 最终合并后的 CSV 总行数: {len(merged_df)} 行")print("=============================================\n")print(f"合并完成!输出文件: {output_file}")