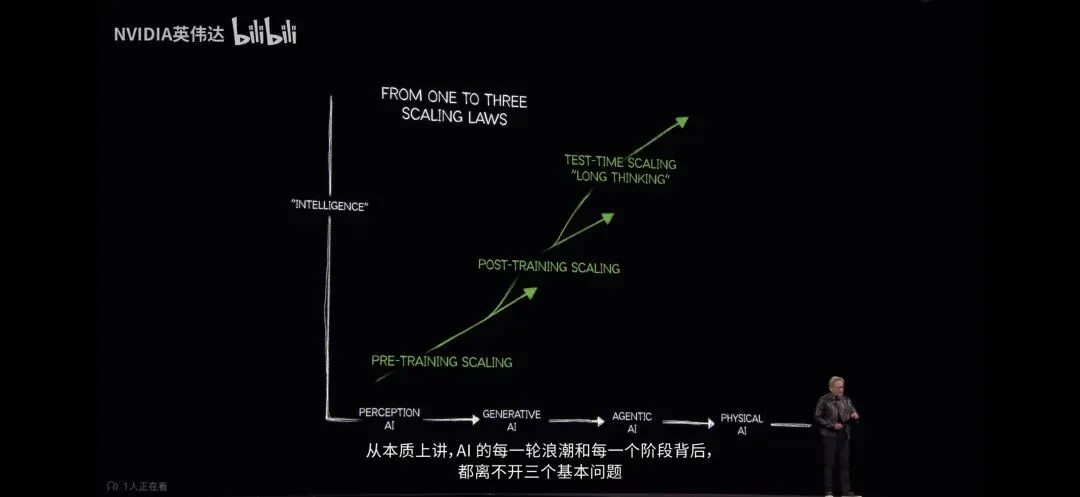
这页 PPT 的核心意思是:AI 的能力提升,已经不只靠“训练更大的模型”这一条路,而是变成了三条增长曲线叠加:预训练、后训练、推理时思考。
黄仁勋是在解释:为什么 AI 未来还会继续消耗大量算力,甚至算力需求会比过去更大。
一、这张图先看两个坐标
横轴是 AI 发展的阶段:
Perception AI → Generative AI → Agentic AI → Physical AI
也就是:
从“看懂世界”,到“生成内容”,到“自主完成任务”,再到“进入物理世界”。
纵轴是 Intelligence,也就是智能水平。
所以整张图在说:
AI 每往前走一代,智能都需要继续往上提升,而提升智能的方法已经从一条路变成三条路。
二、第一条曲线:Pre-training Scaling,预训练扩展
这是过去几年大家最熟悉的逻辑。
问题是:为什么 GPT、Claude、Gemini 会越来越聪明?
答案是:因为它们吃了更多数据,用了更大模型,花了更多 GPU 训练。
例如:
早期 AI 只能识别猫狗、车牌、人脸,这是 Perception AI。
后来大模型通过海量文本、图片、代码预训练,开始能写文章、写代码、画图、做翻译,这就是 Generative AI。
这条曲线的逻辑是:
数据越多,参数越大,训练算力越强,模型基础能力越强。
但问题也来了:
互联网上高质量数据不是无限的,单纯靠“更大预训练”会越来越贵,边际收益也可能下降。
所以 AI 进入第二条曲线。
三、第二条曲线:Post-training Scaling,后训练扩展
这条曲线的意思是:模型预训练完以后,还要继续“调教”。
比如:
一个大模型预训练后,知道很多知识,但它未必会按照人的方式回答问题,也未必会遵守指令,更未必会像专家一样推理。
所以要做:
指令微调、RLHF、人类反馈强化学习、偏好训练、代码训练、数学训练、工具调用训练、安全训练。
简单说:
预训练让模型“有知识”;
后训练让模型“会做事”。
举例:
一个孩子读了很多书,这是预训练。
但他要成为医生、律师、设计师、CEO,还需要大量专业训练,这是后训练。
AI 也是一样。
比如一个基础模型可以写普通文案,但经过后训练之后,它可以变成:
电商客服 AI、设计审稿 AI、投研分析 AI、代码工程师 AI、法律合同 AI、门店运营 AI。
这就是为什么现在不仅训练基础模型要算力,后训练也会成为巨大的算力需求来源。
四、第三条曲线:Test-time Scaling,“推理时扩展”或者“长思考”
这是这页 PPT 最重要的新东西。
过去大家以为:模型训练完以后,回答一次问题就是一次简单推理。
但现在发现:
AI 在回答问题的时候,如果允许它“多想一会儿”,它的能力会明显提升。
这就是图上写的:
Test-time Scaling / Long Thinking
也就是推理阶段的算力扩展。
你可以把它理解成:
普通 AI 是“马上回答”;
高级 AI 是“先思考、分解、验证、反思,再回答”。
例如:
你问 AI:
“2+2 等于几?”
它不需要长思考。
但你问:
“英伟达未来三年是不是还值得投资?请结合资本开支、竞争格局、估值、现金流、ASIC 替代风险、数据中心电力瓶颈分析。”
这个问题就需要长思考。
模型如果只花 1 秒回答,可能是泛泛而谈;
如果花 30 秒、2 分钟、10 分钟,调取工具、拆解变量、比较数据、做情景推演,答案质量会明显不同。
这就是为什么未来 AI 算力需求不只是来自“训练模型”,还来自“每一次高质量回答”。
五、黄仁勋真正想表达的投资逻辑
这页 PPT 背后其实是在回应一个核心问题:
AI 算力需求会不会见顶?
他的答案是:不会那么快见顶。
因为过去大家只看到了第一层需求:
训练大模型需要 GPU。
但现在有三层需求:
第一层是 预训练算力:训练更大的基础模型。
第二层是 后训练算力:把基础模型训练成专家模型、行业模型、Agent 模型。
第三层是 推理算力:AI 每次认真思考、规划、执行,都要消耗大量算力。
而第三层可能是未来最大的一层。
因为训练是阶段性的,但推理是每天、每个人、每家公司、每个机器人都在发生的。
六、几个容易理解的例子
例子一:写一篇普通文案
普通生成式 AI:
你输入:“帮我写一段糖力朋友圈文案。”
它直接生成一段。
这主要是 Generative AI。
但如果升级到 Agentic AI,它会这样做:
先理解糖力品牌定位;
再分析目标客群;
再判断发布场景;
再生成 10 个版本;
再根据小红书/朋友圈/视频号分别优化;
最后还给你推荐关键词和发布时间。
这时候,它不只是生成,而是在“执行一个任务”。
这就需要更多推理算力。
例子二:投研分析
普通 AI:
“英伟达是 AI 龙头,长期看好。”
高级 AI:
它会问:
英伟达未来三年收入增长来自哪里?
Blackwell、Rubin 的迭代节奏如何?
云厂商资本开支是否可持续?
ASIC 会不会替代 GPU?
毛利率是否会下降?
推理算力是否能接棒训练算力?
估值是否已经反映未来三年增长?
这种分析不是简单生成文字,而是多步骤推理。
所以越接近“高质量投研”,越需要 test-time scaling。
例子三:机器人
Physical AI 是最远的一层。
比如未来一个家用机器人,要帮你整理衣柜。
它不是简单识别衣服,而是要:
看懂衣服材质;
判断哪些是羊毛、哪些是羽绒、哪些不能机洗;
理解你的衣柜分类习惯;
规划动作路径;
避开小孩和宠物;
完成折叠、挂放、收纳。
这背后需要视觉模型、语言模型、动作模型、规划模型一起工作。
所以 Physical AI 的算力需求,可能比今天的 ChatGPT 推理还大很多。
七、你可以用这些问题理解这张 PPT
1. 为什么 AI 从一条 scaling law 变成三条 scaling law?
因为过去智能主要靠“训练更大模型”;
现在智能还可以靠“后训练”和“推理时多思考”继续提升。
2. 为什么这对英伟达重要?
因为这意味着 GPU 不只是卖给模型训练,还会卖给:
后训练、推理、Agent、机器人、自动驾驶、工业仿真、数字孪生。
英伟达想证明:
AI 算力需求不是一次性建设,而是长期基础设施。
3. 为什么 test-time scaling 很关键?
因为它把 AI 的算力消耗从“训练阶段”变成“使用阶段”。
训练一个模型可能几个月一次;
但用户每天使用 AI,企业每天调用 AI,机器人每秒都在推理。
所以推理可能成为更持续、更庞大的市场。
4. Agentic AI 为什么比 Generative AI 更耗算力?
因为生成式 AI 只是回答问题;
Agentic AI 要拆任务、做计划、调用工具、执行、检查结果、修正错误。
比如你让 AI “帮我管理一家服装公司的电商视觉转化率”,它不能只写建议,而要分析数据、识别图片、生成方案、测试 A/B、反馈优化。
这比写一段文字复杂得多。
5. Physical AI 为什么是更大的终局?
因为 AI 一旦进入物理世界,就不是“说对”就行,而是要“做对”。
机器人、自动驾驶、无人仓、工厂自动化,都需要实时感知、实时决策、实时动作。
这会带来巨大的边缘算力、数据中心算力和仿真训练需求。
八、对你的投资理解,最关键的一句话
这页 PPT 不是单纯讲技术,而是在讲:
AI 的算力需求,正在从“训练大模型”扩展到“训练后优化、推理时思考、Agent 执行、机器人行动”。
所以如果这个逻辑成立,未来 AI 算力不是短周期景气,而是类似电力、互联网、云计算一样的长期基础设施。
但你也要继续追问一个关键问题:
这些新增算力需求,最后到底会变成云厂商的真实收入和利润,还是只变成英伟达和硬件公司的资本开支?
这个问题,才是判断英伟达、AMD、云计算公司、PCB/CCL/电力设备是否值得投资的核心。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
