前两周跟一个地铁公司的信息中心主任聊天,他说了一句话我印象特别深:
"我看了八家厂商的PPT,每家都说自己第一,看完我更迷糊了。"
这哥们叫老周,管着集团公司十几个系统的数据治理项目。三个月前立项,预算两百多万,现在工具还没定下来。
不是老周不会选,是厂商的PPT太会讲。
今天就聊聊:选数据治理工具,怎么才能不被PPT带跑。
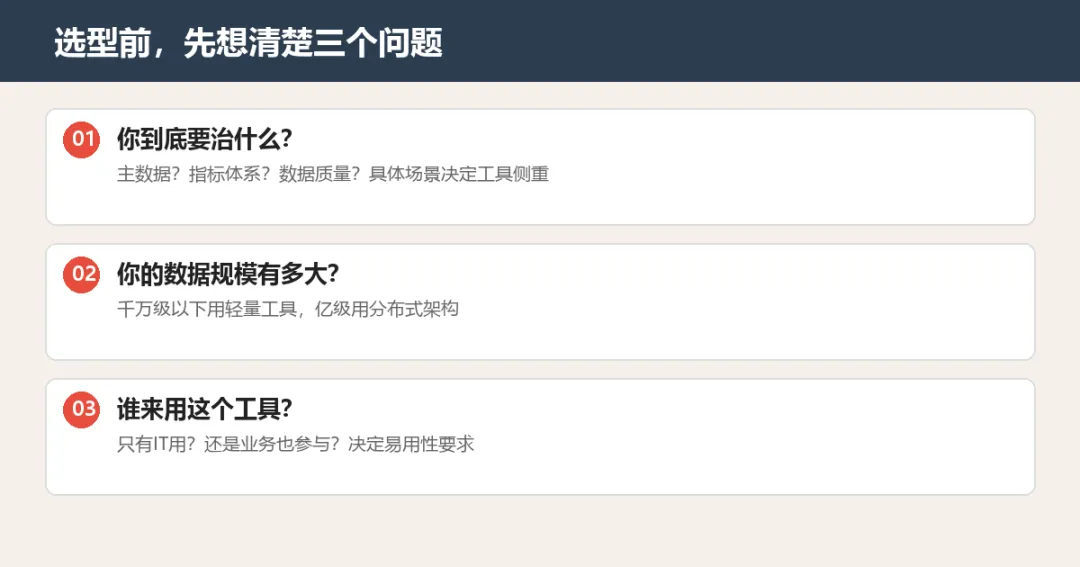
先想清楚三个问题,再去看PPT
很多人选工具的第一步,是让厂商来汇报。
这步就错了。
你去买车,得先想清楚:市区代步还是长途自驾?五座还是七座?预算二十万还是五十万?想不清楚,销售带你试驾一万圈,你还是不知道买啥。
选数据治理工具一样,先内部对齐三个问题:
第一个问题:你到底要治什么?
别回答"我要做全面数据治理",这跟说"我要做个好人"一样,正确的废话。
具体到场景:是主数据混乱导致财务对账出错?还是指标体系不统一导致管理层看报表各看各的?还是数据质量太差,AI应用跑不起来?
不同的痛点,对应不同的工具能力侧重。主数据问题优先看MDM模块,指标混乱优先看指标平台,数据质量优先看质量规则引擎。
老周他们最后想清楚了:最核心的痛点是集团合并报表时,十几个子公司的科目编码不统一,导致财务数据对不上。所以选型时重点看主数据管理和数据标准这两个模块。
第二个问题:你的数据规模有多大?
几百万条数据跟几十亿条数据,对工具的要求完全不一样。
小数据量(千万级以下),轻量工具就能搞定,别上重型平台,杀鸡用牛刀,后期维护成本压死你。
大数据量(亿级、十亿级),就得看工具的分布式架构、并行处理能力,还有跟你们现有大数据平台的兼容性。
第三个问题:谁来用这个工具?
这点是大多数人忽略的。
如果只有IT部门用,那技术能力强不强是核心。如果业务部门也要参与(比如数据标准制定、质量问题反馈),那易用性、低代码能力就是硬指标。
老周他们最后定的原则是:业务人员也要能上手,不能全是SQL和配置页。
厂商PPT里最会忽悠的五个说法
想清楚上面三个问题之后,再去看厂商的PPT,你就能识别哪些话是忽悠了。
我挑五个最常见的:
忽悠一:"我们支持所有数据源"
听着很厉害,实际上没啥用。
主流数据源(MySQL、Oracle、Hadoop、Kafka)大家基本都支持。关键是你们用的那些小众系统——比如你们集团用的那个老掉牙的ERP,或者城市轨道交通专用的调度系统——厂商是不是真的能接。
怎么验证?别听PPT,让厂商现场连你们真实的数据源,跑一遍。这叫POC(概念验证),是选型必经环节。
忽悠二:"我们内置AI能力"
2026年,不说自己有AI能力的工具,都不好意思出来见人。
但AI能力分三六九等:
- 最基础的:用AI生成数据质量规则描述,或者用AI做自然语言查询——这个门槛很低,基本是大模型API套壳;
- 中等的:用垂类大模型做数据标准推荐、字段语义识别——这个需要真正的数据治理语料训练,不是随便接个API能搞定的;
- 真正有价值的:AI能自动发现数据质量问题、推荐修复方案、做血缘影响分析——这个目前市面上能做到的产品不多,基本是头部厂商才有的能力。
怎么判断?让厂商演示一个具体场景:给你们一张真实的、有点脏的数据表,看AI能不能找出问题并给出修复建议。光看PPT上的"AI赋能"四个字,啥也说明不了。
忽悠三:"我们有完整的DAMA/DCMM落地方法论"
DAMA和DCMM是数据治理的两大理论体系,确实重要。
但"有方法论"跟"能落地"之间,差了一个太平洋。
我见过太多案例:厂商的方法论文档厚得像字典,实施的时候却发现——这套方法论是通用模板,根本不考虑你们行业的特殊性。地铁公司和银行的数据治理需求能一样吗?一个侧重运营调度数据,一个侧重交易合规数据,方法论的重点完全不同。
怎么判断?问厂商要同行业的落地案例,最好是能联系上的客户,直接问他们实施过程中的真实体验。
忽悠四:"我们开箱即用,一个月上线"
数据治理工具,不存在真正的"开箱即用"。
数据是你们自己的,标准是你们业务自己的,流程是你们组织自己的。这些东西不理清,工具再强大也只能是个摆设。
老周后来跟我说,有一家厂商说他们平台"预置了轨道交通行业数据模型",听起来很诱惑。结果POC的时候发现,那个"行业模型"就是国标里的基础字段,跟他们集团的实际业务场景差了十万八千里。
真正靠谱的厂商会告诉你:上线只是开始,数据治理是持续运营的过程。那些承诺"一个月搞定"的,大概率是卖了工具就跑,后续实施和支持跟不上。
忽悠五:"我们是Gartner/IDC报告里的领导者"
第三方报告有参考价值,但不能当唯一依据。
报告评估的是厂商的综合能力,不是针对你们具体需求的匹配度。就好比米其林指南给餐厅打分,但你的需求是"带三岁小孩吃一顿不贵的午餐",三星餐厅反而可能不合适。
真正有用的参考是:报告里对这个厂商短板的评价。正面话都是公关过的,负面评价反而更真实。
选型实战:老周他们最后怎么定的
老周的公司最后选了一家中型厂商,不是PPT最漂亮的,也不是名气最大的。
他们做对了三件事:
第一,先POC,再谈价格。
让三家入围厂商,各自在他们的真实环境里跑两周。数据源用他们真实的财务系统,数据量用他们真实的集团公司数据,场景用他们最痛的科目编码不统一问题。
两周下来,哪家真的能解决问题,一目了然。
第二,不只看功能,看实施团队。
工具再好,实施的人不行,项目照样黄。
老周他们专门问了每家厂商的实施顾问:你们做过几个轨道交通行业的项目?实施周期一般多长?万一我们中途想调整需求,怎么处理?
有一家厂商,销售吹得天花乱坠,结果实施顾问一问三不知,明显是临时拼凑的团队。直接淘汰。
第三,算总账,不算首购账。
有些工具首购便宜,但license按用户数收费,后期扩展成本高得离谱。有些工具首购贵,但后续维护费用低,还能私有化部署,长远看反而划算。
老周他们算了一笔账:三年总拥有成本(TCO),包括采购、实施、培训、运维。最后选的那家,首购不是最便宜的,但三年下来总成本最低。
选型避坑清单
总结一下,选数据治理工具,记住这"三要三不要":
三要:
1. 要先想清楚自己的需求,再去看厂商的PPT
2. 要做POC,用真实场景验证,别光听演示
3. 要算总账(TCO),别只看首购价格
三不要:
1. 不要被"AI赋能""开箱即用"这些词忽悠,要看到真实的演示效果
2. 不要只看大厂商,有些垂直领域的中型厂商,行业理解反而更深
3. 不要忘了后续运营,工具上线只是开始,持续的数据治理运营能力才是关键
说到底,选工具跟找对象差不多——PPT再漂亮,过日子得看实际。
你的数据治理工具选型踩过什么坑?欢迎留言分享,帮更多人避雷。
下期预告:《数据治理运营怎么做——工具上线了,然后呢》——选对工具只是第一步,持续运营才是真正的考验
转发给需要的朋友 🚀
作者:数据管理学习笔记 | 专注数据治理、数据管理知识分享