前两篇关于 AI PPT 的文章,我反复讨论了两个问题:为什么 PPT 必须可编辑,以及为什么稳定交付不能只依赖模型的一次发挥。
这次不再重复论证这些判断,而是往前走一步:用一份 20 页左右的真实技术分享,试着把它们完整落地。
我没有直接让 Codex”帮我做一份 PPT”,而是借用了 SlideMind 拆解工作流的思路,把整件事拆成几步:先统一视觉规范,再逐页规划内容和表达方式,然后生成可编辑 PPTX,渲染出来检查,发现问题就改,改完再检查。每一轮跑下来学到的经验,写回 Skill,下次复用。
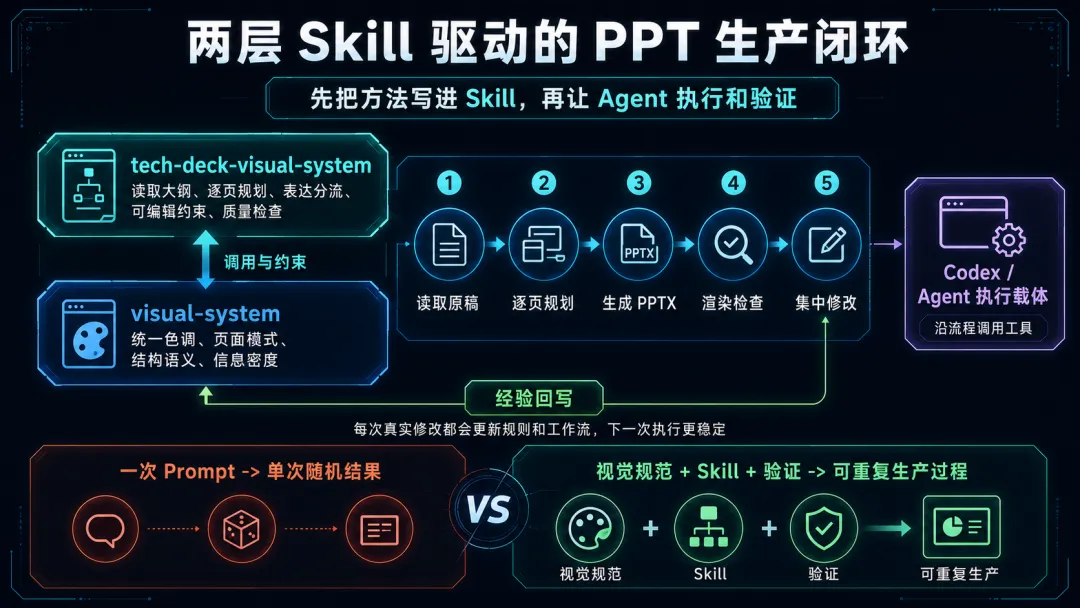
这些判断不是模型天然具备的能力。它们是在一次次试跑、讨论和修改中逐渐形成,再被写进两层 Skill:底层的 visual-system 负责视觉规范和结构语义,上层的 tech-deck-visual-system 负责技术类 PPT 的生产与检查流程。
Codex 在这里是执行载体。它读取原稿、遵循 Skill、调用工具、生成 PPTX,再根据渲染结果继续返工。换成其他具备文件操作和工具调用能力的 Agent,这套方法原则上仍然成立。
所以这次真正想验证的,不是 Codex 能不能做 PPT,而是:
能不能通过视觉体系、工作流拆解和 Skill 沉淀,把大模型不稳定的单次生成,变成尽可能稳定、可检查、可持续改进的生产过程。
一、先统一视觉,再决定每一页怎么做
这份技术分享的正文已经比较完整。进入 PPT 阶段后,我们没有立即逐页生成,而是先确定整套 Deck 的视觉方向。
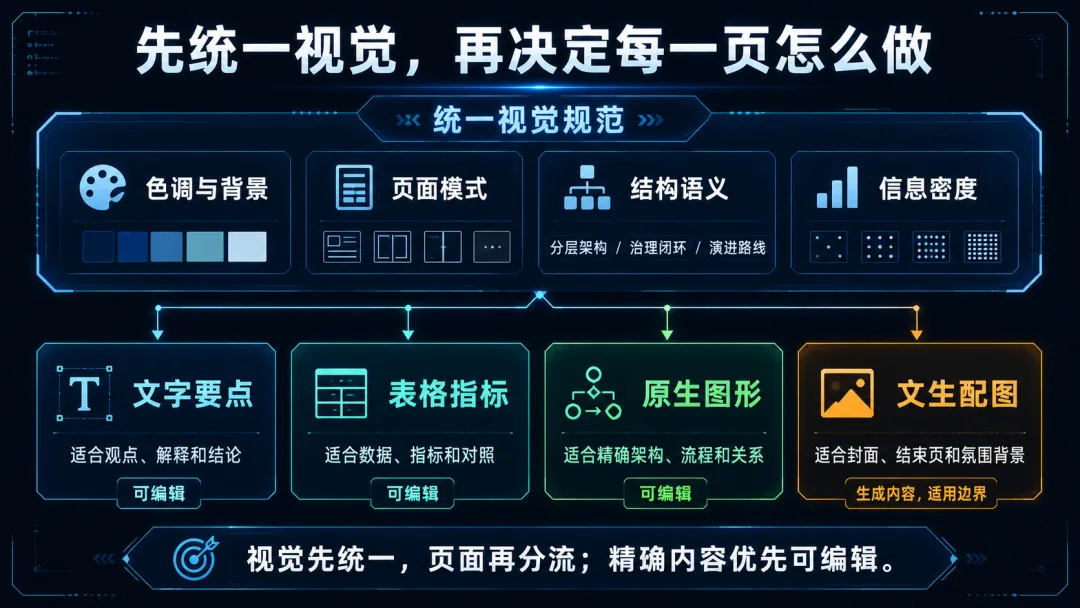
这一步不只是选一种颜色或找一张背景图,而是统一一套表达规则:封面、内容页和结束页使用什么色调;阅读型页面和重点展示页怎样区分;分层架构、治理闭环和演进路线分别采用什么结构;文字、表格、原生图形和文生图各自适合什么页面。
底层的 visual-system 负责把这些判断整理成可以复用的视觉规范,tech-deck-visual-system 再据此判断每一页适合使用文字、表格、PowerPoint 原生图形,还是文生图。
图片单独看很细腻,但放回真实修改过程,问题马上出现:架构层级需要调整、一个能力需要拆成两个子部分、场景名称也需要替换。如果这些信息都已经画进图片,每次修改都要重新生成。
因此,架构页、闭环页和指标页最终改用 PowerPoint 原生元素,文生图只保留给封面、结束页和共享背景。
关于“为什么坚持可编辑”,前两篇已经讲得比较多。这次更重要的变化是:视觉不再依赖每一页临场发挥,而是先形成统一规范,再进入逐页分流、生成和检查流程。
二、先把方法写进 Skill,再交给 Codex 执行
确定视觉体系和页面分工后,我们没有继续开发一个新的 PPT 生成器,而是把方法写进 Skill,让 Codex 按流程执行。
它先读取完整原稿,再整理逐页内容和视觉分工。生成初稿后,它会回头对照原文,检查是不是为了页面简洁,把业务影响、目标口径和建设机制删得太多。
这点对我很重要。很多 PPT 的问题不是字多,而是压缩之后只剩几个名词,支撑结论的逻辑不见了。
确认内容后,Codex 调用 PPTX 生成工具输出可编辑文件。标题、正文、卡片、表格、架构层和箭头都是 PowerPoint 原生对象,可以直接在文件里继续修改。
生成之后,它还会把每一页渲染成图片,生成整套缩略图,再放大检查重点页并运行布局检测。
有一次检查发现,两个紧凑卡片沿用了普通卡片组件,说明文字被压缩成省略号。缩略图里并不明显,放大渲染后才发现。修正、重新导出,再检查一次。
这很像软件开发里的构建和测试,只不过对象变成了 PPT。
工作过程中还有一个小改动很典型:内容页最初是深色背景,后来决定统一换成浅色。如果每页手工放一张背景图,就要逐页修改。最后我们把目录和所有内容页统一引用同一个背景文件,通过公共函数加载。
以后再换背景,只需要替换一张图片并重新导出。
这些事情单独看都不复杂,但串在一起之后,Codex 的角色就清楚了:它是一个能读文件、按规则制稿、检查结果并继续返工的执行者,而不是方法本身,也不是一个只负责输出文件的按钮。
三、为什么要把经验写回 Skill
这次做 PPT 的过程不是一次性写一段长 Prompt。
随着不断试跑,我们逐渐得到了一些稳定判断:整套 Deck 先统一色调和页面模式;架构图等技术图示遵循固定的结构语义;精确架构和指标优先使用原生图形;内容背景只维护一个共享资产;先生成完整初稿,再集中收集反馈;修改时先改公共规范,再改单页;每轮交付前都要看整套缩略图和重点页渲染结果。
这些经验最后被写回了 Skill。
这里实际分成两层。
底层的 visual-system 负责通用视觉规则,包括色调、背景、页面模式、信息密度,以及分层架构、闭环和演进路线等结构语义。它不负责生成某一份具体 PPT,也可以同时服务 PPT 和公众号配图。
上层的 tech-deck-visual-system 负责把这些视觉规范接入技术 Deck 的生产流程:如何读取大纲、怎么划分页面、每页采用哪种表达方式、哪些内容必须可编辑、共享背景如何管理,以及生成后怎样检查。
这样做的好处是,下一次再处理技术总结或架构汇报时,不用从头讨论同一批问题。
Prompt 解决的是一次任务,Skill 沉淀的是一类任务的做法。
四、两条路线,各走各的
前两篇提到了 SlideMind,这里需要交代一下它和这次 Codex 实践的关系。
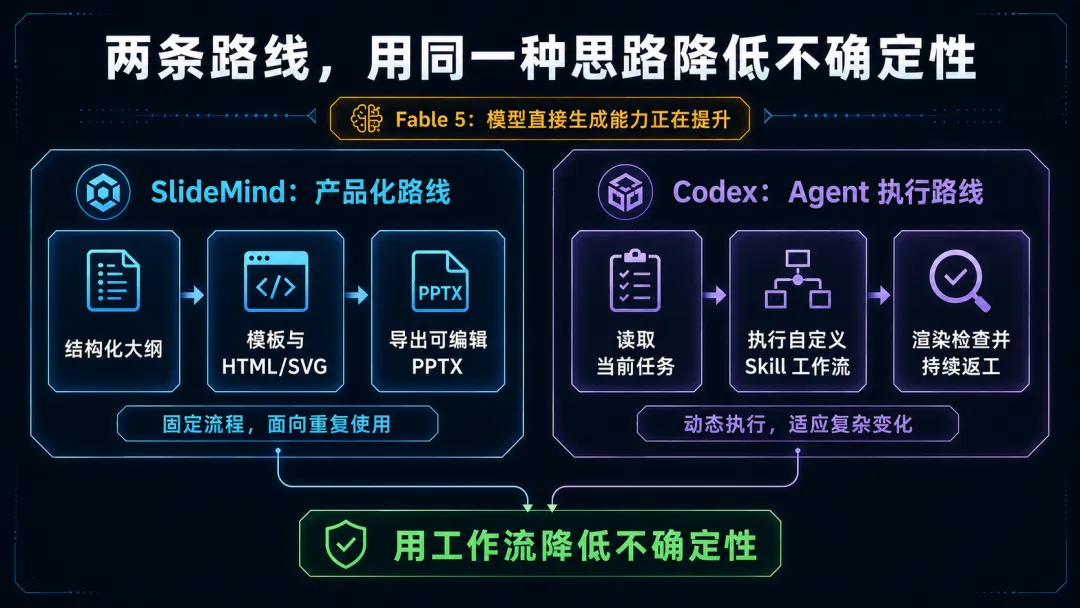
SlideMind 是一条产品化路线:把内容分析、模板体系、HTML/SVG 生成和 PPTX 导出固化成产品流程,目标是让更多人可以重复使用。它还在继续迭代,对应的 Skill 也在打磨。
这次 Codex 实践是另一条路线。它借用了 SlideMind 对 PPT 工作流进行拆解和约束的思路,但不依赖 SlideMind 的具体生成链路,而是让 Agent 根据当前任务读取文件、调用工具、管理资产、生成页面并检查结果。这条路线更灵活,适合复杂、变化多的任务,围绕它沉淀了 visual-system 和 tech-deck-visual-system 两个 Skill。
两条路线解决的问题不同,会继续各自迭代。
值得一提的是,同期我也用 Claude 提供的最新模型 Fable 5 直接生成过一版可编辑 PPTX。模型的直接生成能力确实在快速提升。但模型能生成 PPTX,不代表问题已经解决——它是否读了完整原稿?页面类型是否合理?核心内容是否可编辑?生成后有没有检查?用户反馈能不能进入下一版?
这些问题仍然需要工作流来回答。
所以不管是产品化的 SlideMind,还是 Agent 动态执行的 Codex 路线,还是模型能力本身的提升,指向的都不是”谁替代谁”,而是同一个目标:
不把质量押在模型一次发挥上,而是把任务拆成可检查、可接管、可重复的步骤。
五、用工作流换确定性
回过头看,这次真正留下来的不只是一份可编辑 PPTX,还包括一套统一的视觉规范,以及能够执行这套规范的两层 Skill 工作流。
以后再做同类 Deck,流程大致会是:读取原文,梳理页面,确定可编辑边界,生成完整初稿,渲染检查,集中修改,再把新的经验写回 Skill。
它不保证每一页第一次生成就是最漂亮的,但每一步都能被看见和修改,第二版也更容易比第一版稳定。
以前我更关注最终用什么格式生成——图片、HTML/SVG、原生 PPTX,还是模板系统。这次做完之后觉得,格式只是最后一环,更值得关注的是:视觉判断有没有形成统一体系,整个过程是不是可执行、可验证、可继续积累。
模型会持续升级,生成能力也会越来越强。但内容怎样进入、页面怎样分流、结果怎样检查、反馈怎样回到下一版,这些事情不会自动消失。
我接下来会继续迭代 SlideMind,也会继续用 Codex 和新的模型能力跑真实任务,再把稳定的方法沉淀下来。
模型负责生成,Agent 负责执行,Skill 负责约束,产品负责规模化。
作为技术人,整理逻辑从来不是最难的部分。真正费劲的是把一套技术架构变成别人一眼能看懂的视觉表达——这恰恰是我们最不擅长的事。既然 AI 有机会把这块短板补上,那就继续折腾。
之前有位读者留言说"把生图当辅助,不要想一步到位",这句话给了我一些启发,直接影响了这次实践中文生图和原生元素的分工方式。所以不管是建议还是槽点,都欢迎留言,一起把这条路走得更明白。