为什么 AI 做的 PPT,总差那么一截?
- 2026-06-30 11:43:00
这个系列都在讲同一件事——怎么用 AI 把 PPT 做得更好。第一篇《做了一个 PPT 生成工具 Skill:验证 spec → test → lessons 的 SDD 全流程》讲的是 AI PPT 项目怎么用 SDD 工作流启动,从 spec 到 test 到复盘,跑通一个可迭代的节奏。第二篇《AI 做 PPT 不难,难的是生成后还能改得动》讲的是 HTML+SVG 这条技术路线的设计取舍——为什么放弃图片生成、为什么用约束替代自由发挥、为什么先试跑再批量。
两篇把"怎么做"和"为什么这么做"讲得差不多了,但很快又撞上一个更具体的问题:
为什么很多 AI 生成的 PPT,内容已经八九不离十,却还是总差那么一截?
最近这段时间,我基本就在围着这个问题反复试。不是单纯换模型,也不是一直补 prompt,而是把整条生成链路往回拆,看看到底是哪一层在制造这种"AI 味"。
慢慢发现:这类问题看起来像"模型能力问题",但真做下来,很多时候不是模型不够强,而是系统分工太粗。
这几条线一直在同时跑,不是坐着想出来的,是跑出来的——
主链路已经闭环:从内容分析到逐页生成到导出 PPTX,整条 pipeline 能跑通,系统有了可分析、可替换、可分阶段收紧的骨架。视觉问题被当成系统问题处理:标准页模板化、复杂图示页单独处理、先跑代表页锁定风格再批量展开。单页修改的能力正在建起来:后续重点不是"一次性全量生成",而是"哪页有问题就修哪页"。
先说结论:生成不是问题,稳定才是
大模型已经能完成这些事:拆大纲、生成标题和要点、输出结构完整的 HTML、甚至直接出一张不错的视觉稿。
所以"能不能生成",不是最关键的问题。
真正的问题是:同样的输入,能不能持续得到一套可交付的结果。
对技术分享场景来说,要求尤其高。用户要的不是"一张截图式的好看页面",而是一套逻辑清楚的 deck、前后一致的视觉语言、以及后面还能继续修改的交付物。
这也是我们的取舍:不追求"自由排版能力",而是解决另一件事——
技术内容从文档到演示稿,怎样更稳定地生成初稿,再更低成本地修问题页。
目标一旦变成"稳定交付",系统设计就会跟着变。下面这几步,就是这段时间最重要的认知收敛。
第一步:不要把所有页面都交给模型
最开始做 AI PPT,很容易默认一个前提:既然是 AI 生成,那每一页都应该交给 AI 去写、去排、去画。
但跑几轮就会发现这条路成本很高。因为一套技术分享里,并不是每一页都需要高自由度生成。很多页面其实是标准页:要点页、双栏对比页、指标卡片页、常规图表页。
这些页面真正需要的,不是"创意",而是:信息密度稳定、字体和间距统一、颜色使用克制、同类型页面风格一致。
如果继续交给 LLM 自由生成,带来的往往不是价值,而是波动——字号忽大忽小、间距忽松忽紧、同样是要点页但布局每次都不同。
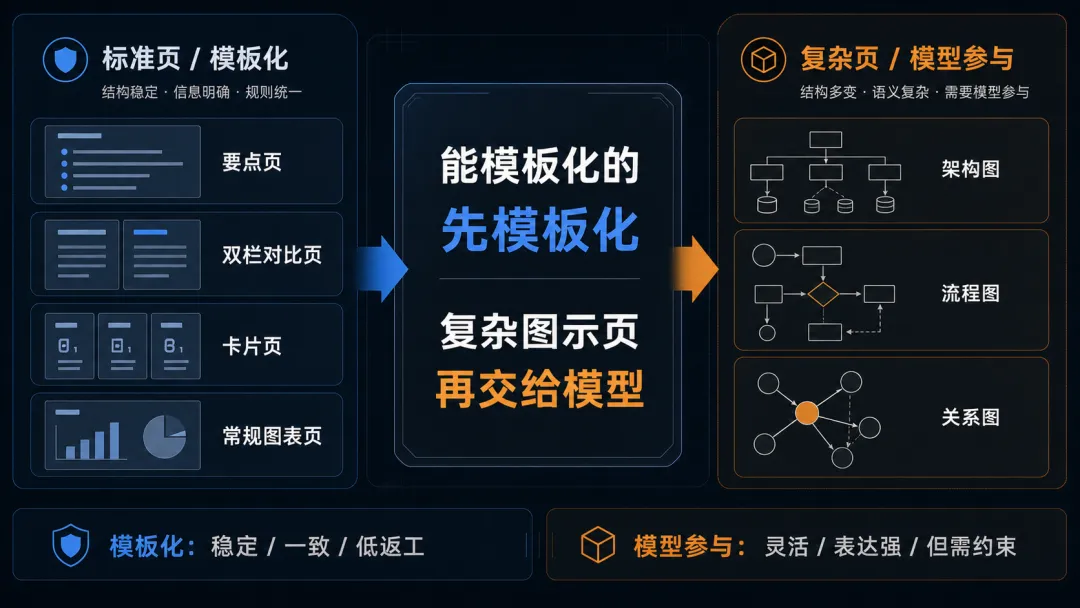
所以后来做了一个很明确的调整:标准页尽量模板化,复杂页再交给模型。
更准确地说,是把页面分成两类:
- 确定性页面
:内容结构明确,合理布局有限,优先用模板引擎处理 - 非确定性页面
:需要图示表达、关系建模、视觉隐喻,才交给模型参与
这一步的收益非常直接:标准页稳定性明显提升,deck 内部一致性更强,生成时间和返工成本下降,模型的注意力被留给真正复杂的页面。
背后的判断其实很简单:
能用确定性系统完成的事,不要交给概率系统。
第二步:复杂页的问题,不只是 prompt 不够,而是缺少约束
标准页模板化之后,剩下最难的是哪些页?通常是:架构图、流程图、时间线、飞轮图、双圆关系图。
这类页面有一个共同点:内容不是简单罗列,而是需要"视觉表达"。也正因为如此,它们最容易出现一种情况:语义对了,图不对。
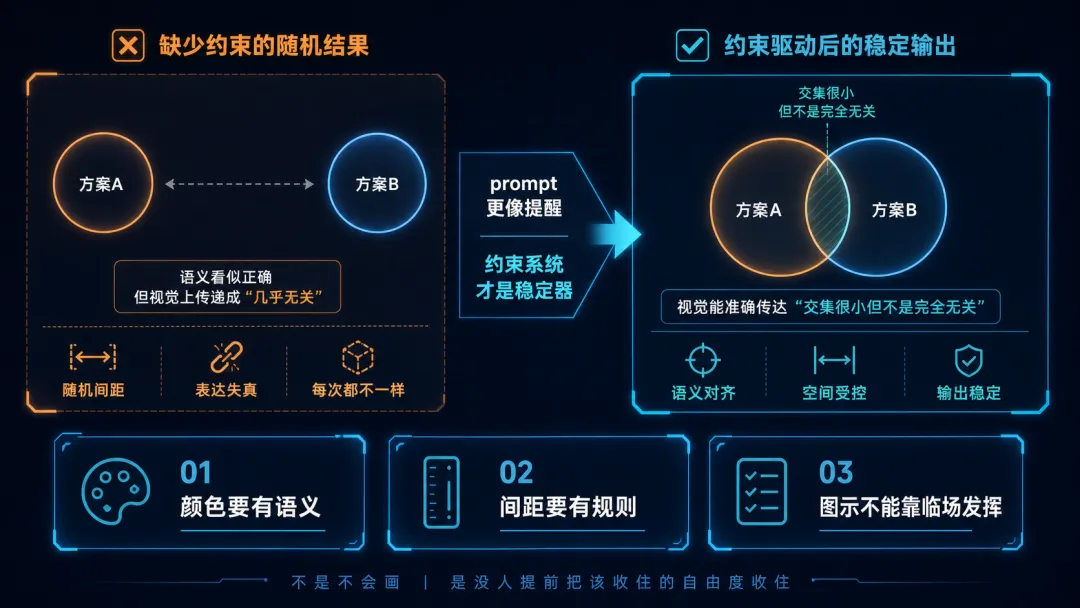
比如最近碰到的一页双圆关系图,想表达的是"AI 的通用知识"和"团队内部知识"只有很小交集。结果模型给出的图形里,两个圆离得很远,视觉上传递成了"几乎无关"。
标题对,文案对,元素也齐。问题在于,图示表达没有被约束到正确的区间。
一开始遇到这种情况,直觉往往是继续调 prompt。但调得越多,越会碰到一个事实:
prompt 更像提醒,不像约束。
它能提高概率,但很难保证一致性。尤其是复杂图示页,本质上是在让模型同时做几件事:理解内容关系、选择视觉隐喻、安排空间布局、输出可渲染结构。把这些都压在一次生成里,本身就很不稳。
所以后来对这个问题的理解变了:复杂页的核心矛盾,不是 prompt 不够长,而是缺少一层明确的视觉约束系统。
这层约束至少应该回答:哪类组件使用哪类颜色、图形和文字的最小间距、哪些布局允许出现、哪类关系图应该控制在什么信息密度。当这些规则只是散落在临时 prompt 里,结果通常是局部修得动,但系统收不住。
这段时间也专门看了几类相关项目——三顿 PPT Agent、以及一些 PPT Skill和一些架构图生成项目。它们具体路线不一样,但有一个共同点:越是想把结果做稳,越不会把视觉判断完全留给模型临场决定。
这个观察说明了一件事:当前技术类 AI PPT 的问题,不是只有我们遇到;而"约束前置、生成分层、结果可修"这条路,也不是孤立判断。
第三步:质量不是单页好看,而是整套结果能进入交付链路
如果只看第一眼效果,今天已经有一些路线可以把视觉冲击力做得很强。尤其是直接用图像模型生成整页视觉稿,确实很容易出"哇"的效果。
但对技术分享场景来说,这条路线有个明显短板:它更接近最终成品,不接近协作中间态。
而大部分真实 PPT,并不是一次生成就结束。一套 deck 生成之后,通常还会:调整某一页标题表达、改掉某个不准确的图示、补一页上下文说明、把一页拆成两页、按听众重新控制密度。
如果系统只擅长"整页直接生成",却不擅长"后续继续精修",那它解决的是演示效果问题,不是交付效率问题。
这也是一直坚持"HTML 中间态 + PPTX 导出"的原因。HTML 中间态的价值,不只是"浏览器里能预览",而是它天然适合承接下一步工作流:可审阅、可逐页查看、可逐页重生成、可继续导出为 PPTX。
换句话说,目标不是一次性生成"最像成品"的结果,而是生成"最适合继续修"的初稿。
所以更愿意把视觉质量理解成一个系统指标,而不是一个页面指标。更关键的不是"某一页有没有高光",而是:deck 内部是否一致、问题页是否容易定位、弱页面是否容易单独修、最终结果是否方便继续交付。
第四步:要把约束往前提,而不是把修正放在最后
很多系统的默认做法是:先让模型尽量自由生成 → 生成完再人工挑问题 → 出问题了再补 prompt → 继续重跑。
这条路能跑,但很难规模化。因为它的本质,是把质量控制放在输出之后。
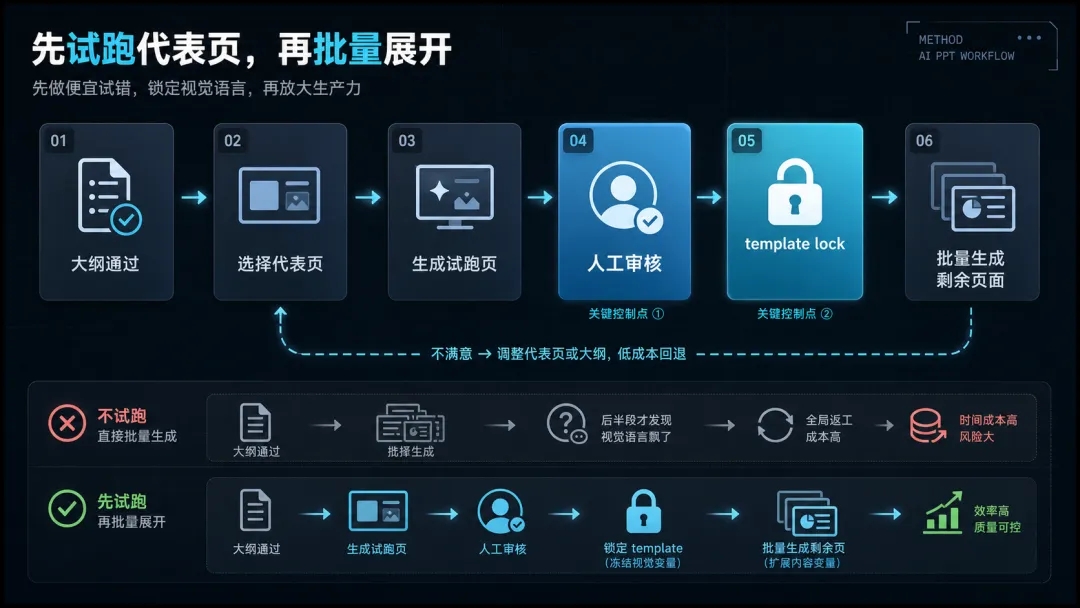
更合理的方式,是把约束前置到生成之前,甚至拆进不同阶段:
- 大纲阶段
:先约束信息结构 - 试跑阶段
:先锁定风格和版式方向 - 渲染阶段
:标准页走模板,复杂页才走生成 - 导出阶段
:尽量保留文字层,降低后续修改成本
从工程视角看,这不是在"增加流程",而是在减少随机性。
尤其是"先试跑"这一步,现在觉得很重要。因为很多质量问题,不是内容错,而是风格没锁住。如果不先跑代表页、直接批量生成,往往要到后半段才看出整套视觉语言已经飘了,返工成本很高。
所以比起"直接全量生成",更认同:先验证代表页,再批量展开。 它更像工程里的灰度发布,而不是一次性上线。
这也是为什么最近的精力,已经不再只放在"把整套生成跑快一点",而是开始转向:单页更新和单页重生成、当前页预览和局部重渲染、页面状态追踪。
回过头看,这是一个典型的系统分层问题
AI PPT 的视觉质量,不能再被理解为"模型一次生成得好不好",而应该拆成四个层次:
第一层:内容结构是否稳定。 逐页大纲是不是清楚,信息密度是不是合适,叙事节奏是不是合理。
第二层:页面类型是否分流。 哪些页应该模板化,哪些页必须交给模型,边界有没有划清楚。
第三层:视觉规则是否明确。 颜色、间距、布局、图示语义有没有沉淀成可复用约束。
第四层:结果是否便于修正。 问题页能不能单独修,输出是不是还方便继续交付。
这几个层次里,模型只负责其中一部分。剩下的大量工作,其实属于系统设计。
这段时间比较明确的一个变化:AI 负责生成,系统负责收敛。
如果只有前者、没有后者,效果可能偶尔很好,但很难稳定;如果后者做得足够扎实,即使模型能力没有明显升级,整体结果也会改善很多。
下一步
后面最值得继续做的,不是再把"一次性整套生成"推得更激进,而是把几件事补扎实。
统一视觉系统。 主题、色调、页面密度、色板、组件语义这些东西,尽量先在系统层锁住,而不是在每一页里重复提醒模型。简单说,就是先把"整套 deck 应该长什么样"管起来。
把逐页精修工作流做出来。 方向已经很明确:用户可以只改当前页的标题、要点、布局类型,只重生成当前页,而不是每次整套重跑。
把文字层和视觉层分得更清楚。 不是所有页面都要同一种生成策略。背景和版式由模板系统控制,关键信息保留在可编辑的文字层里,复杂视觉块才考虑用图片能力补上。

当然,也有些问题还没彻底解决。复杂图示页的稳定性还不够,很多约束还停在规范层、没完全进入程序校验层。但和前一阶段相比,至少现在问题已经拆得比较清楚了。
上一篇提到的 Skill 还没放出来。不是忘了——平时要工作,周末也常有事情处理,能投入的时间确实不多。目前的约束系统质量还不太稳,直接放出来怕别人踩坑。继续打磨,稳了再分享。
最后一句
真正决定质量上限的,往往不是模型能发挥到什么程度,而是系统能把哪些自由度提前收住。
对 demo 来说,偶尔惊艳就够了。对产品来说,稳定可用更重要。技术类 AI PPT 要想真正进入交付链路,下一步比拼的不会只是模型,而是约束系统。
这个系列还在继续。后面 SlideMind 每推进一个阶段,有值得记录的判断和实践,我会继续写出来。如果你也在做类似的事,欢迎关注,一起把这条路走清楚。
如果觉得这篇有启发,欢迎收藏、转发,下次遇到问题页的时候可能用得上。

