我们可以将现有查询中的数据处理流程转换成自定义的 M 函数,以达到多次复用及自动化的效果。将查询转换成自定义函数的过程可以形象地理解为 “打包” 数据处理步骤。合并不规范文件时,需要对每一个文件都执行一些固定操作,比如提升标题、删除空行和空列、替换值等,这些清洗流程都可以封装成可重复使用的函数,方便后续调用。
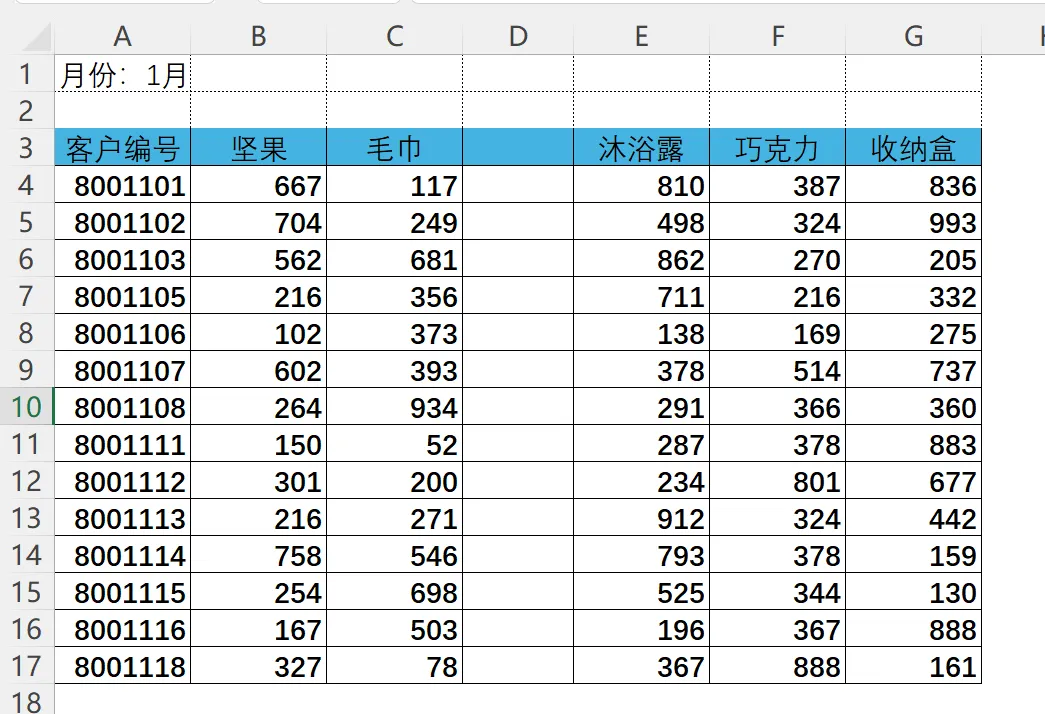
示例数据一共有 4 个月的销售数据,现在需要将它们合并进行汇总分析。1月数据内容如下:
观察 1 月数据,如上图所示。第 1、2 行是空行,加载到 Power Query 后将会显示成 null,因此需要删除前两行。另外,由于系统原因,D 列是空列,需要删除。同时为了更好地分析各产品情况,我们需要将数据进行逆透视处理。每个月的数据都符合以上特点,都需要删除前两行、删除 D 列、进行逆透视处理。
既然数据处理步骤都是标准化的,那么在 Power Query 中就可以通过自定义函数实现自动化,具体操作如下。
(1)选择一个月的数据作为查询样本进行处理,这里我们选择 1 月的数据作为样本。以 “从 Excel 工作簿” 的形式导入 1 月的销售数据,如下图所示。
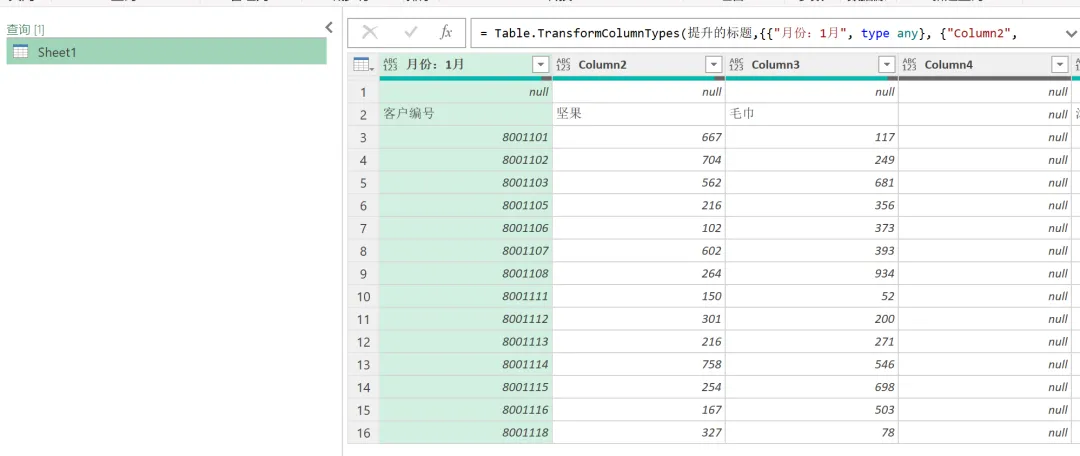
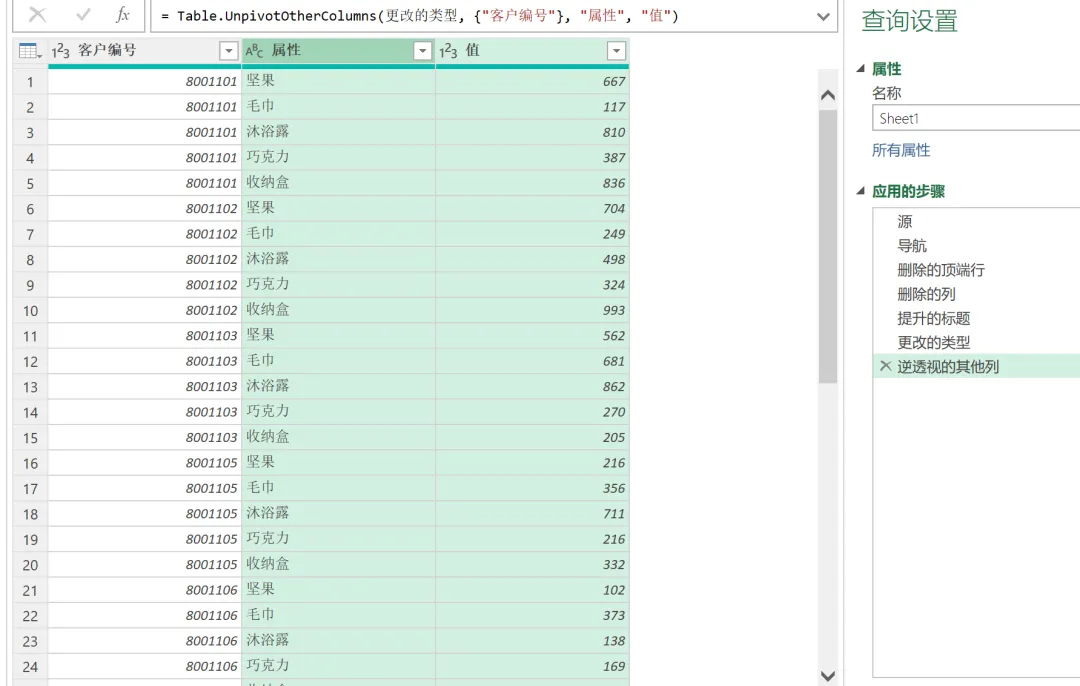
2)对 1 月的数据进行清洗,删除前两行、删除第 4 列、提升标题,逆透视客户编号以外的其他列。以上步骤操作完,1月的数据存在的问题就处理完了,得到的数据就是我们可以用来进一步分析的数据,如下图所示。
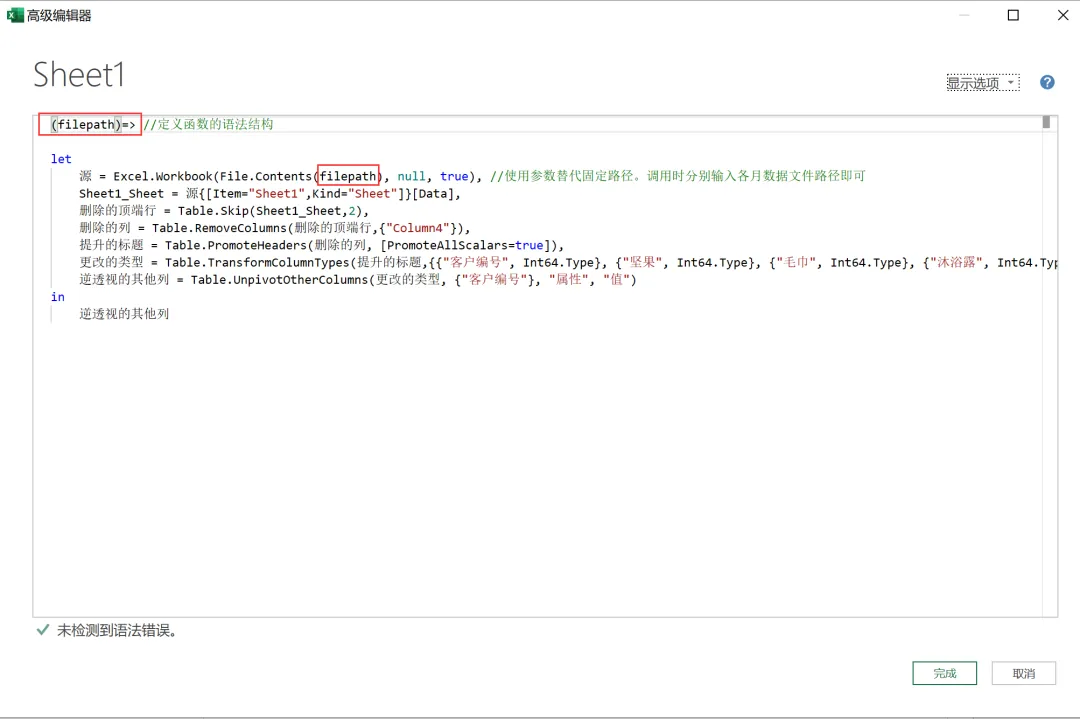
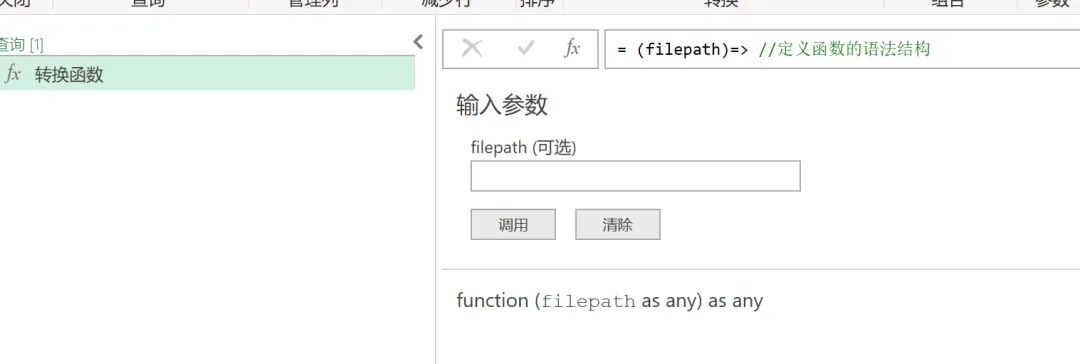
3)对1月数据执行的所有数据处理步骤都需要应用在个月的数据中。所以我们封装的的 M 函数就以 1 月数据处理流程为基础。打开 “高级编辑器”,按照自定义函数的语法要求修改查询。首先在 let 语句上方输入定义参数的语句:(filepath)=>。找出查询中的文件路径,将其替代为参数 filepath,如下图所示。
4)单击 “完成” 以后,可以看到 1 月数据处理流程已经被转变成了函数,修改函数名称为 “转换函数”,如下图所示。在输入参数中输入数据所在文件路径,就可以调用之前的处理流程对数据进行一系列的转换了。
(5)获取所有文件的文件路径。批量获取文件路径信息可以通过从文件夹功能实现,文件信息列表的众多列中就有文件路径,如下图所示。
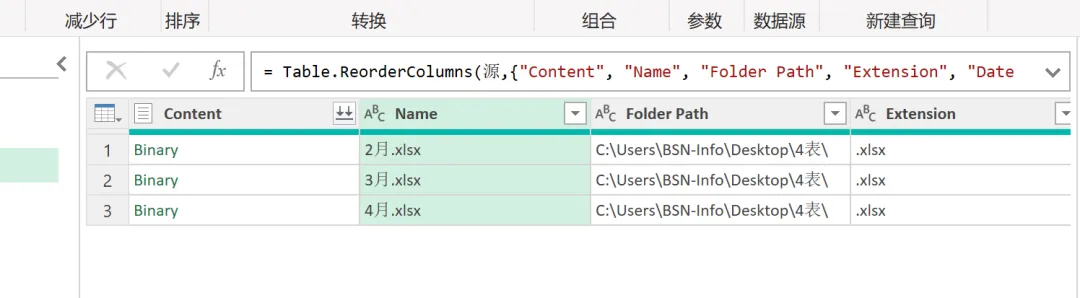
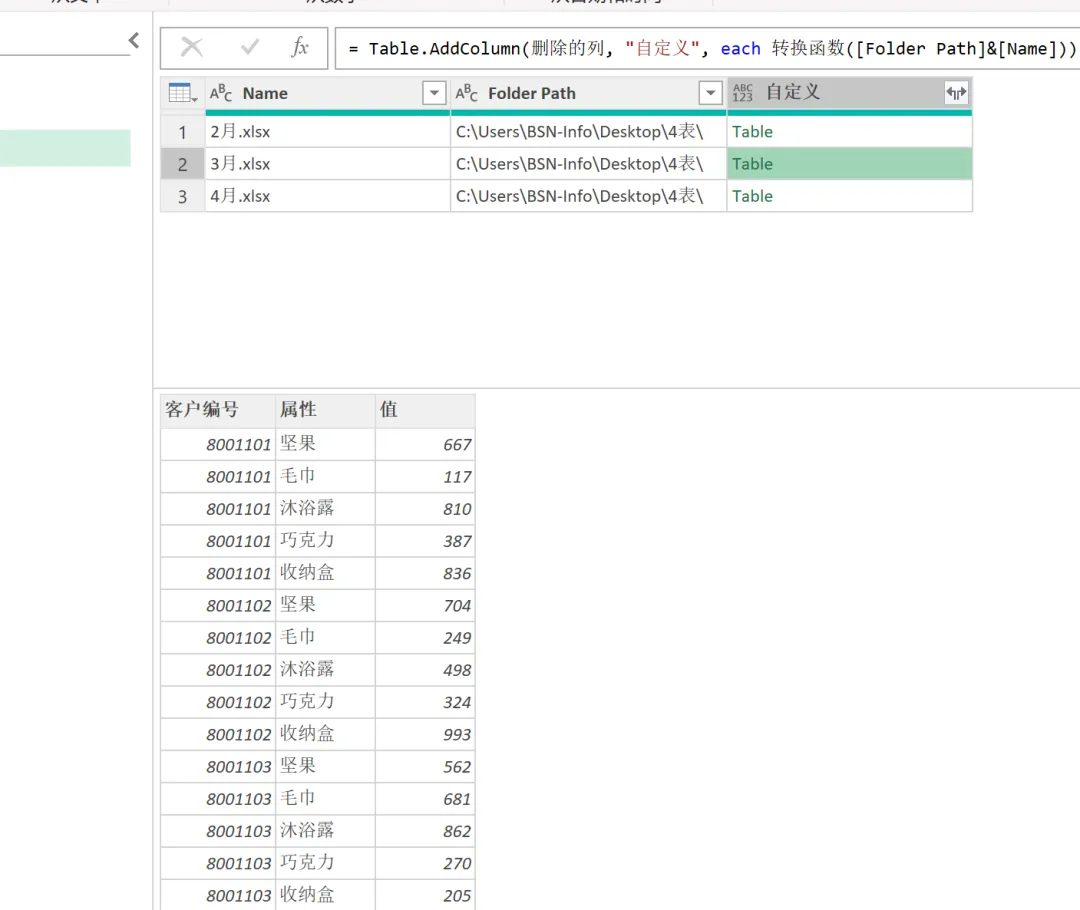
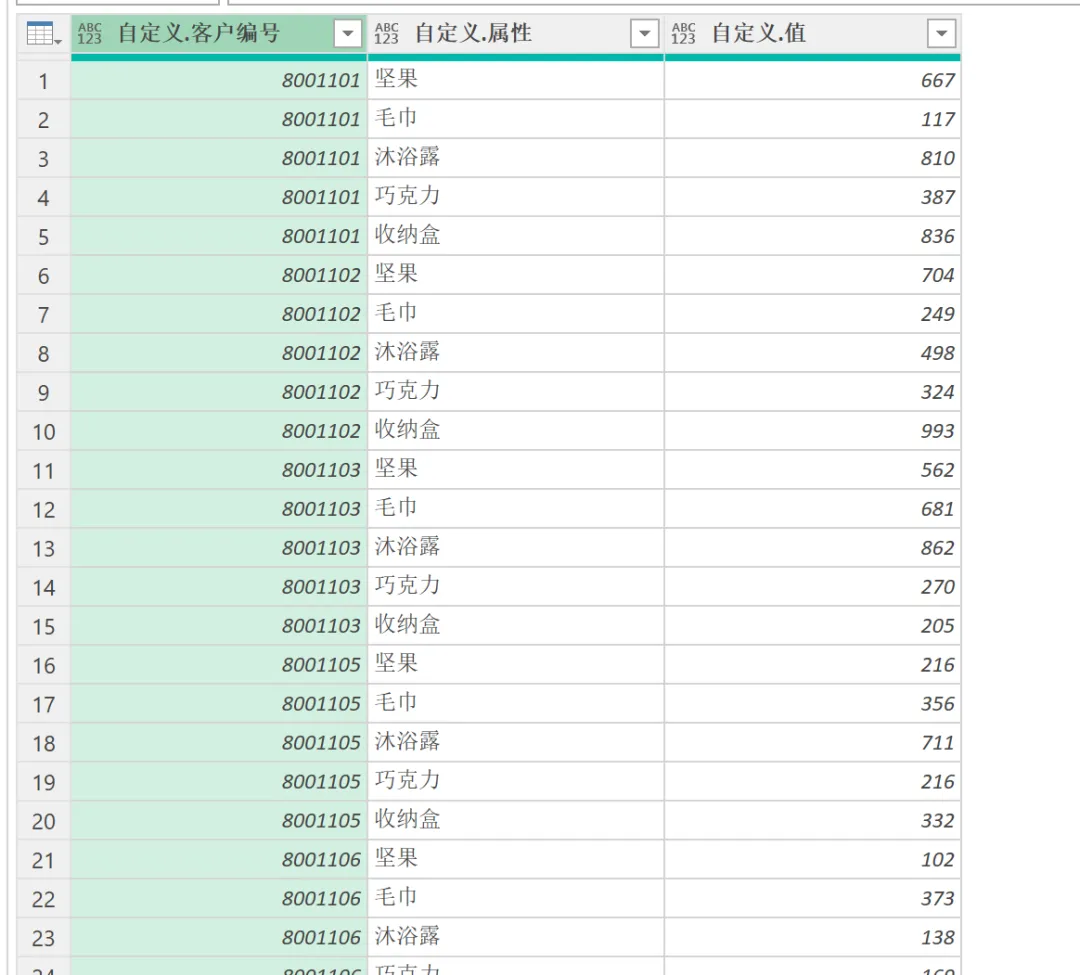
(6)仅保留 Name 列和 Folder Path 列,新建自定义列调用自定义函数,输入以下自定义列公式:= 转换函数([Folder Path]&[Name])。单击 “确定” 以后,可以看到在自定义列中,各月的数据已经按要求转换成功,所有表格都从二维表变成了一维表,如下图所示。
(7)使用 Table.Combine() 函数合并自定义列中的表,如下图所示。
基于现有查询定义自定义函数的关键是找到可以用参数替代的部分。我们可以在查询的任意阶段定义参数,这取决于我们想要封装的具体步骤包含哪些部分。自定义函数的参数可以有多个。在查询中重复出现的操作对象,我们都可以将其设置为参数。
今天内容就这些。