企业知识库最容易被低估的地方,是中间过程。
用户看到的只是最后一步:在飞书或企业微信群里问一句话,机器人给出答案。但在这次回答出现之前,一份业务资料已经经历了很多环节:部署环境要能跑起来,PPT 要被解析成可检索的结构,页面关系不能丢,文档要带上项目和部门等元数据,权限要跟组织层级走,检索结果要能重排和解释,最后答案还要在 IM 里及时返回。
KnowFlow v2.3.9-v2.4.0 新增和强化的能力,正是围绕这条链路展开:
- • MinerU 支持 3.1.1,使用最新 MinerU 模型,PPT 可直接转 Markdown
这不是 7 个互不相干的功能点。更准确地说,它们让一份企业资料从“上传进系统”,走到“在组织工作流里被正确使用”。
 PPT 问答
PPT 问答第一步:客户现场先要跑得起来
很多产品文章喜欢从功能开始讲,但企业软件落地时,第一关往往不是功能,而是环境。
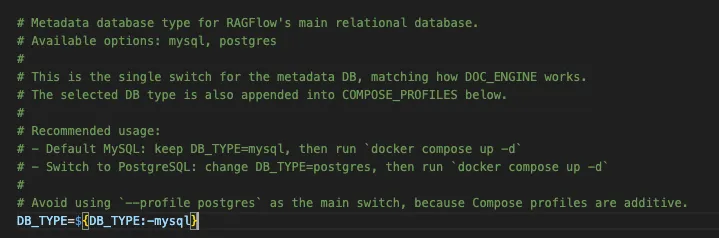
客户现场可能已经有标准数据库规范。有人用 MySQL,也有人要求所有新系统统一接 PostgreSQL。过去,如果一个知识库系统强绑定某一种数据库,项目还没进入业务验证,就会先卡在 IT 规范和运维体系上。
v2.4.0 新增 PostgreSQL 数据库兼容能力,解决的是这个准入问题。
这次不是简单把连接串换成 PostgreSQL,而是把数据库兼容做进了服务端的基础结构里。组织、协作组、租户、用户、RBAC、知识库这些核心模块,都要能在不同数据库环境下保持一致行为。
这样做的业务价值很直接:业务逻辑不用到处关心 MySQL 和 PostgreSQL 的方言差异。客户现场选择 PostgreSQL 时,组织管理、权限管理、知识库授权这些核心能力仍然可以沿同一套服务结构运行。
对企业客户来说,数据库兼容不是“多一个选项”这么轻。它意味着 KnowFlow 更容易进入已有基础设施,而不是要求客户为了知识库单独迁就一套技术栈。
 MySQL 和 PostgreSQL 动态切换
MySQL 和 PostgreSQL 动态切换第二步:PPT 不能只抽文字,要变成可检索的结构
企业知识里有大量 PPT。
售前方案、产品培训、项目汇报、解决方案、客户交流材料,很多关键知识都沉在 PPT 里。问题是,PPT 并不是一篇线性文章。它有页、标题、表格、截图、图示、流程箭头和备注。如果只是把文字抽出来,RAG 拿到的往往是一堆失去上下文的句子。
v2.3.9-v2.4.0 中,KnowFlow 对 MinerU 链路继续增强,支持 MinerU 3.1.1,使用最新 MinerU 模型的 Task 异步解析模式,并支持 PPT 直接转 Markdown,而无需像之前一样先转成 PDF 再进行识别。

这一步的意义,是把 PPT 从“文件”变成“知识结构”。Markdown 不是为了好看,而是为了让标题层级、列表、表格、图片引用这些结构能进入后续分块和检索流程。
这次增强后的解析链路,不只是把 PPT 里的文字抽出来,而是尽量保留标题、列表、表格、图片位置和页面关系,再转成后续检索更容易理解的 Markdown 结构。
这对业务的影响很明显:
- • 售前 PPT 可以直接进入知识库,不必先人工整理成 Word
对企业来说,PPT 解析质量决定了大量非正式知识能不能真正进入知识库。KnowFlow 这次增强 MinerU 和 PPT Markdown,就是在扩大企业知识的可接入范围。
第三步:有些内容必须按页理解
PPT 转成 Markdown 之后,还有一个问题:怎么切。
很多文档适合按标题或语义段落分块,但 PPT、扫描件、视觉报告、图表密集材料不一样。对这类资料来说,“一页”本身就是一个完整表达。标题、配图、说明文字和布局关系共同构成语义。如果强行拆碎,检索命中的可能只是页面上的几个词,而不是这一页真正要表达的内容。
所以 v2.3.9-v2.4.0 新增了 Page 解析方法。
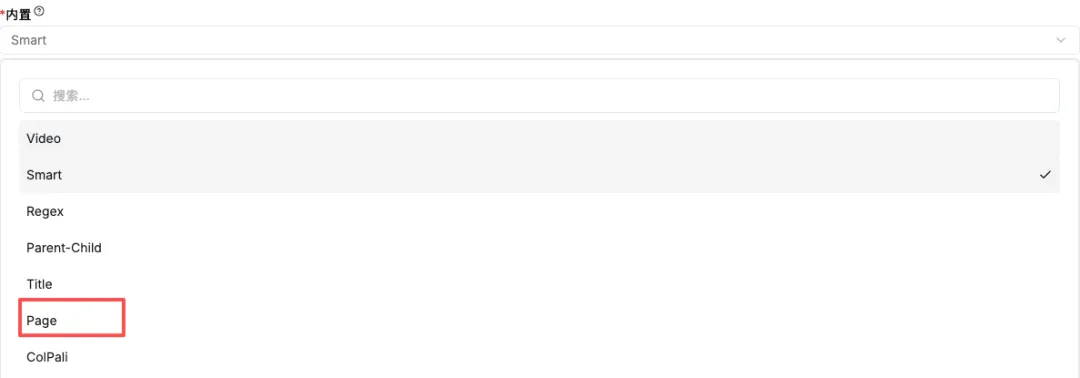
Page 解析会尽量按页面组织内容,而不是把所有材料都拆成普通段落。它也会处理图片在不同页面或分块中的重复问题,让图文页进入知识库后更接近原来的阅读体验。
这不是换一个分块名字,而是在承认一种现实:页面本身就是知识边界。
例如一页客户行业方案,左边是行业痛点,右边是解决方案架构,下面还有流程图。用户问“这个方案适合什么场景”,答案很可能需要整页信息。如果只拿其中一小段文字,模型可能答得片面;如果按页保留上下文,系统更容易给出完整解释。
Page 解析让 KnowFlow 对 PPT、图文页、报告页这类资料更友好。它补上的不是“解析格式”,而是对企业文档表达方式的尊重。
第四步:文档要有业务身份,元数据要参与检索
一份 PPT 进入知识库后,光有正文还不够。
企业里的同名文档太多了。《项目方案》《客户汇报》《验收材料》《售后政策》这些名字可能在不同部门、不同客户、不同年份重复出现。真正决定它是否应该被检索出来的,往往是元数据:客户、项目、部门、版本、状态、文档类型、有效期。
v2.4.0 强化了元数据管理和检索过程,让元数据不只是文档旁边的备注,而是可以进入检索筛选。
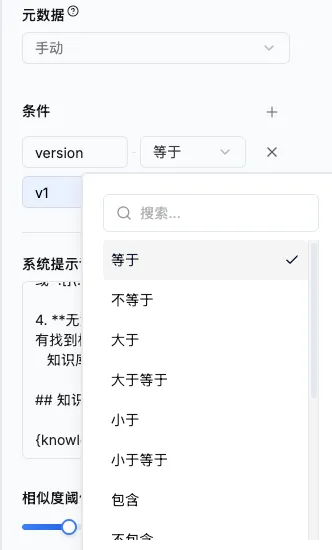
这次增强后,元数据可以在检索前发挥作用。系统能够先根据客户、项目、文档类型、版本、状态等条件缩小候选文档范围,再进入语义检索和排序。 这样做不是为了多一个筛选框,而是为了让检索更贴近真实业务条件。
这个设计比较关键。它没有把所有复杂条件都粗暴塞进搜索引擎,而是区分“能安全预筛”和“需要回退处理”的场景。
业务价值也很清楚:
- • 同一个知识库里,不同版本、状态、部门的材料可以被区分
- • 企业可以把文档管理规则带进 RAG,而不是只靠模型猜
举个例子,员工在飞书里问:“华东制造客户这次方案里的数据安全怎么讲?”系统如果能先用元数据过滤到“华东制造客户 + 售前方案 + 已生效版本”,再做语义检索,答案稳定性会比直接全文搜索高得多。
元数据让知识库从“文本仓库”更接近“业务资料库”。
第五步:不是每个人都能问到这份 PPT
现在,这份 PPT 已经被解析、按页分块、带上元数据。下一步是权限。
企业知识库不能只回答“有没有这份资料”,还要回答“这个人有没有资格看到这份资料”。
v2.3.9-v2.4.0 中,KnowFlow 的 RBAC 支持组织多层级继承,可以快速把知识库授权给不同层级的组织。对企业来说,这比逐个用户授权重要得多。
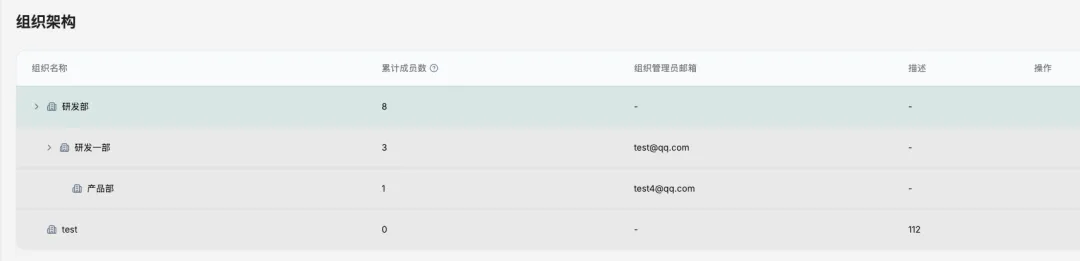 创建多层级组织
创建多层级组织这次的组织继承能力,让权限可以沿着企业组织层级自然下发。管理员不需要把知识库逐个授权给每个用户,而是可以按事业部、部门、项目组这样的层级进行授权。 组织结构变化后,权限也更容易跟着人员归属一起调整。
这意味着,如果给“华东事业部”授权某个知识库,下面的部门和项目组成员可以按组织继承获得权限,而不是管理员手动给每个人加权限。
业务价值是非常实际的:
- • 总部、区域、部门、项目组可以按层级配置访问范围
- • 管理员不必在“全局超级权限”和“逐人授权”之间二选一
对于销售资料、客户项目文档、内部制度、研发知识库来说,这类继承权限是上线前必须解决的问题。否则知识库越大,权限维护越容易失控。
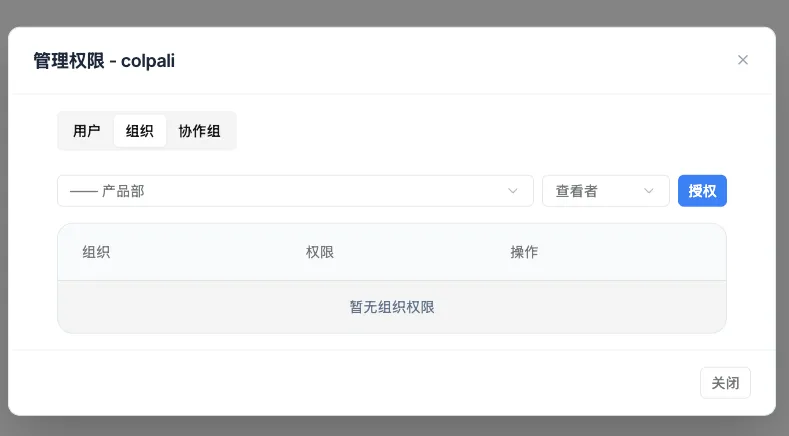 知识库按组织授权
知识库按组织授权第六步:检索结果要能重排,也要能解释
用户终于开始提问了。
系统先根据权限和元数据缩小范围,再进入检索。但对企业 RAG 来说,召回只是第一步。真正影响答案质量的,是哪些内容排在前面。
v2.4.0 让 Milvus 支持客户端重排和检索调试。这个功能的价值,在复杂知识库里会非常明显。
Milvus 擅长向量召回,但企业文档检索不能只看向量相似度。一个片段是否应该排在前面,可能还取决于关键词命中、问题特征、标签信号、PageRank、服务端初始分数等。客户端重排会把这些信号综合起来,让排序结果更贴近业务语义。
同时,检索调试可以把关键过程展示出来:到底是向量分高,还是关键词命中强,还是标签和权重影响了排序。也就是说,检索不再是一个黑箱。
这对业务团队很重要。过去用户说“为什么没有搜到那份资料”,工程团队只能猜:是向量召回问题,还是关键词没命中,还是元数据过滤太窄,还是重排权重不合适。现在调试面板能把过程拆开看,定位问题会快很多。
更重要的是,客户验收时也更容易建立信任。
企业客户不只是要一个答案,还会问这个答案从哪里来、为什么是这些引用、为什么这个片段排第一。Milvus 客户端重排和检索调试,给 KnowFlow 补上了“解释检索过程”的能力。
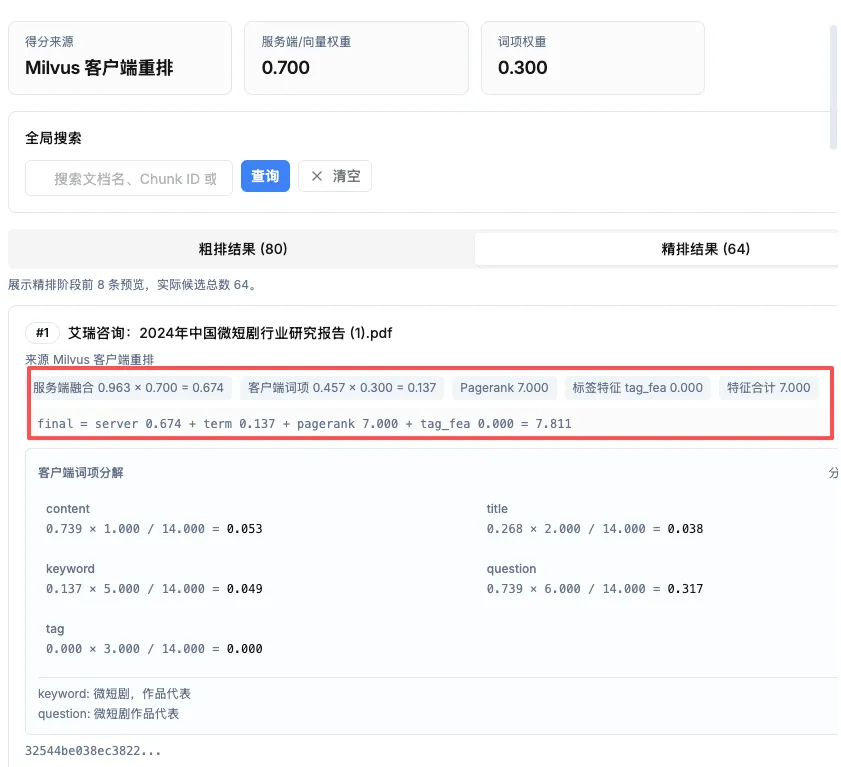
第七步:答案要回到员工工作的地方,而且不能让人等太久
最后一步,答案要回到飞书或企业微信。
很多知识库项目的问题,是答案只停留在 Web 页面里。员工真正工作的地方却是 IM:项目群、售前群、客服群、研发群。让员工为了查一句话打开另一个系统,本身就是阻力。
v2.3.9-v2.4.0 增强了企业微信和飞书接入,支持流式输出。
这背后不是简单“分段发消息”,而是让机器人在生成答案的过程中持续把中间内容推送到会话里。用户不用等完整答案生成完,第一时间就能看到系统已经开始处理。
飞书里可以通过流式卡片持续更新内容,企业微信里可以通过流式消息逐步返回答案。最后系统再补齐完整内容、引用和图片信息,让过程反馈和最终结果都完整。
这个体验差异很大。
没有流式输出时,用户在群里问一个复杂问题,机器人可能沉默十几秒。哪怕最后答对了,用户也会觉得系统卡住了。流式输出让用户第一时间看到系统正在处理,长答案也能边生成边阅读。
对业务价值来说,这不是一个交互动效,而是在降低知识库被使用的心理成本。
企业知识库只有出现在员工日常工作的地方,才有机会变成真正的工作流工具。飞书、企业微信流式输出,让 KnowFlow 的回答不再停留在后台,而是进入组织沟通现场。
这两个版本补上的,是一条完整链路
回到最开始那份 PPT。
它先在客户现场的 PostgreSQL 环境里被系统接收;通过 MinerU 3.1.1 转成 Markdown;用 Page 解析保留页面语义;通过元数据标记客户、项目、版本和状态;再由 RBAC 组织继承控制谁能访问;用户提问时,Milvus 客户端重排和调试信息让检索过程更可信;最后答案以流式方式回到飞书或企业微信。
这就是 KnowFlow v2.3.9-v2.4.0 这两个版本新增能力串起来之后的意义。
它们不是为了把功能列表写长,而是在补企业知识库从“资料导入”到“可信回答”的中间链路。企业 RAG 真正难的地方,往往就藏在这些中间环节里。
一个能演示的知识库,只需要上传、检索、回答。一个能生产使用的知识库,还必须处理部署环境、文档结构、业务元数据、组织权限、检索解释和 IM 工作流。
KnowFlow 这两版做的,就是把这些生产级能力继续往前推进。
了解更多:
- • 官网:https://www.knowflowchat.cn
- • 文档:https://www.knowflowchat.cn/docs
- • GitHub:https://github.com/knowflow-ai/KnowFlow

