导读
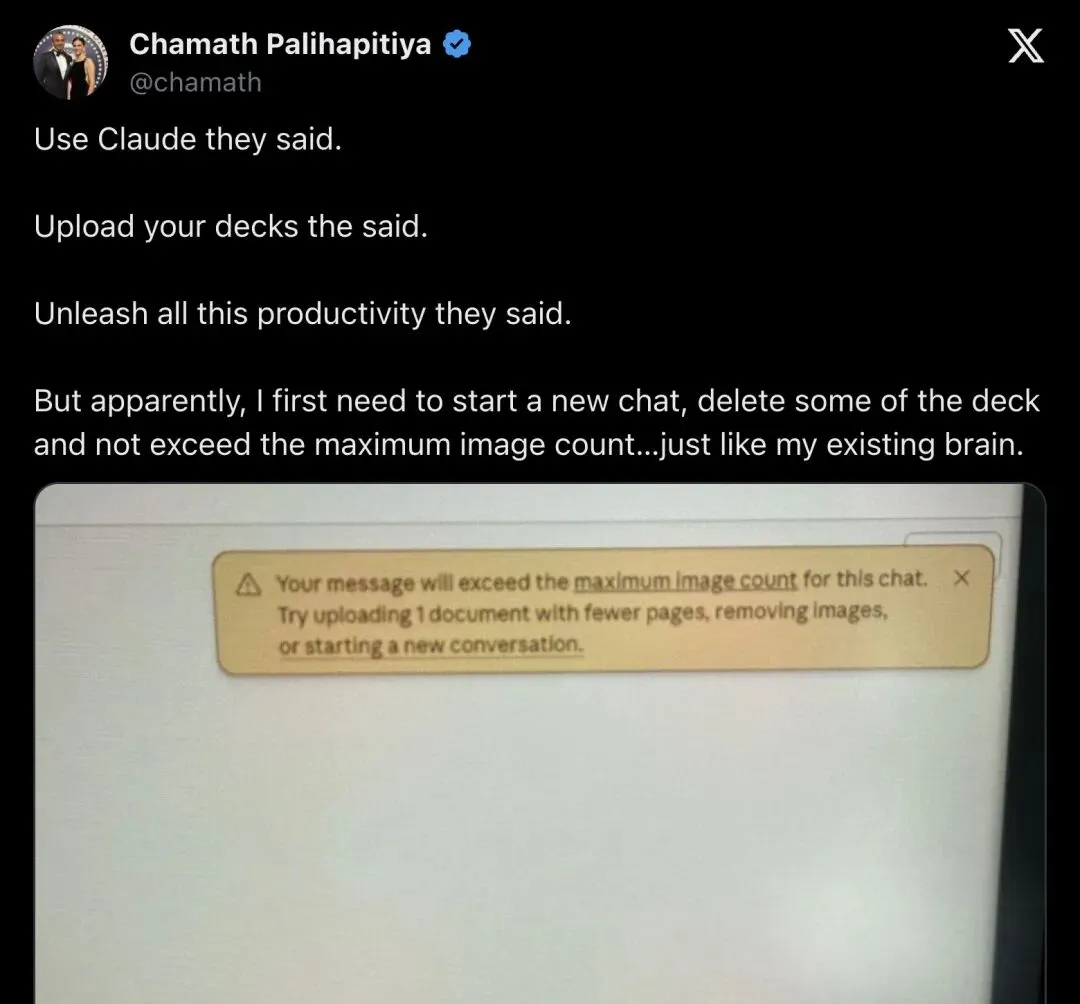
Chamath Palihapitiya 在 X 上发了一条吐槽,配图是 Claude 的报错弹窗:「你的消息超出了最大图片数量。」30 万人围观、2200 人点赞——它精准命中了大模型产品的一个核心反差:厂商宣传能吞下整套代码库,但用户拿一份真实 PPT 进去,却被系统拦在门口。「跟我自己那个脑子一模一样」
5 月 15 日,Social Capital 创始人、硅谷最活跃的科技投资人之一 Chamath Palihapitiya 在 X 上发帖:
"Use Claude they said. Upload your decks they said. Unleash all this productivity they said. But apparently, I first need to start a new chat, delete some of the deck and not exceed the maximum image count…just like my existing brain."
「他们说用 Claude。他们说上传你的 deck。他们说释放生产力。但实际上,我得先开一个新聊天,删掉一部分 deck,还不能超过最大图片数量……跟我自己那个脑子一模一样。」
▲ Chamath 发帖吐槽,配图就是 Claude 弹出的 maximum image count 报错
最后那半句 "just like my existing brain" 才是杀伤力最大的部分:你花了钱,买了一个号称远超人脑的 AI 助手,结果它跟你的大脑有同一个毛病——容量不够用,得先清理才能装新东西。
百万 token,宣传有多高调
要理解这条吐槽为什么戳中这么多人,得先看 Anthropic 过去一年在"上下文长度"上的营销力度。
TechCrunch 报道,Anthropic 把 Claude Sonnet 4 的 context window 拉到了100 万 token——大约等于 75 万个英文单词,比《指环王》三部曲加起来还长,或者 7.5 万行代码。这个数字是之前 20 万 token 限制的5 倍,也是 OpenAI GPT-5 的 40 万 token context window 的 2.5 倍。
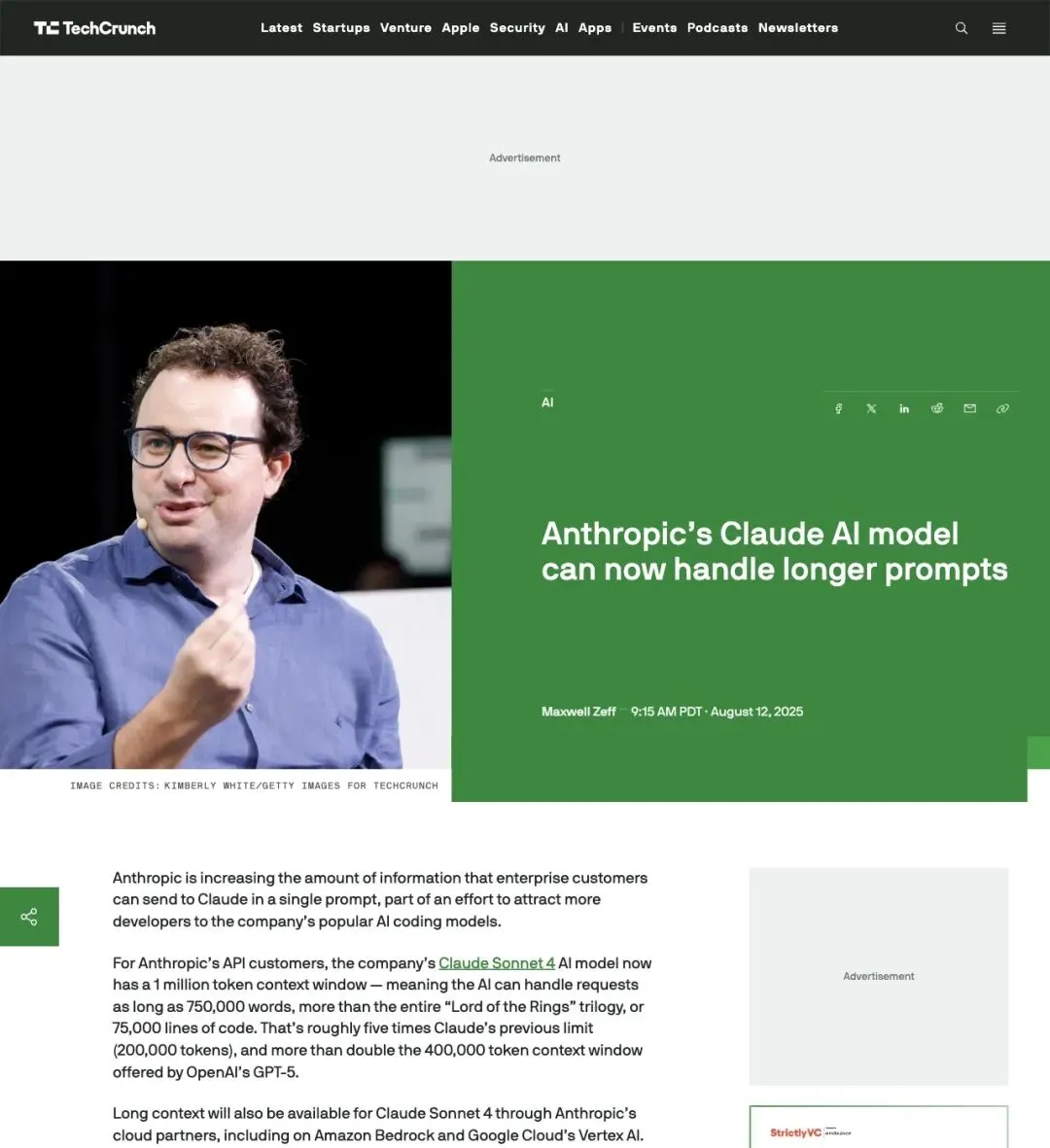
▲ TechCrunch: "Anthropic's Claude AI model can now handle longer prompts"
VentureBeat 也跟进报道:这意味着开发者可以一次性分析整个软件项目,或者同时喂入数十篇研究论文。
从数字上看,确实够震撼。但 Chamath 遇到的问题,跟 token 数量根本不在同一个维度。
一份投资 deck,凭什么卡住百万 token
PPT 和投资 deck 看起来就是几十页 slides,为什么会比 7.5 万行代码更难处理?因为它在 AI 眼里根本不是"文本"。
每一页 slide 都可能变成一张图。大量 deck 里塞满了图表、截图、logo、表格和嵌入式图片,文字只是配角。当你把这种 PDF 上传到 Claude,系统会把每一页都当成图片来处理——于是一份 40 页的 deck,就变成了 40 张图片请求。
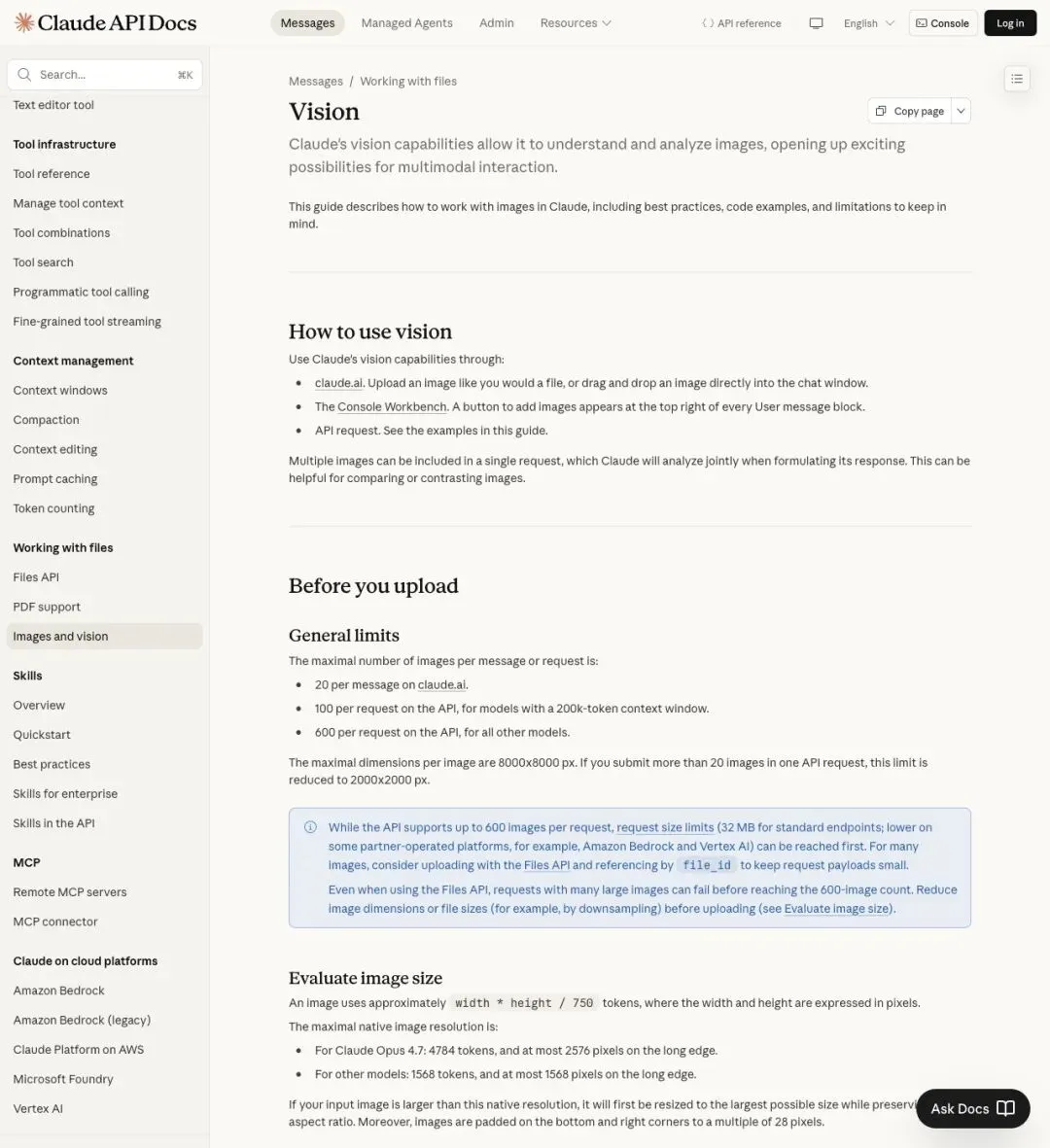
▲ Anthropic API 文档显示,图片请求有单次数量上限,大量图片会快速消耗 token 预算
而 Anthropic 的文档明确写了:每次请求的图片数量有上限。API 层面,如果你一次提交超过 20 张图片,系统会限制为 100 张。普通用户在 Claude 网页端遇到的限制更紧。
PDF 的处理路径也分两条。Claude 拿到一份 PDF 后,可能走文本抽取,也可能走视觉理解——取决于页面内容。如果页面上大部分是图表、截图和视觉排版,系统就会用 vision 模式处理,每一页都要吃掉大量 token 预算。
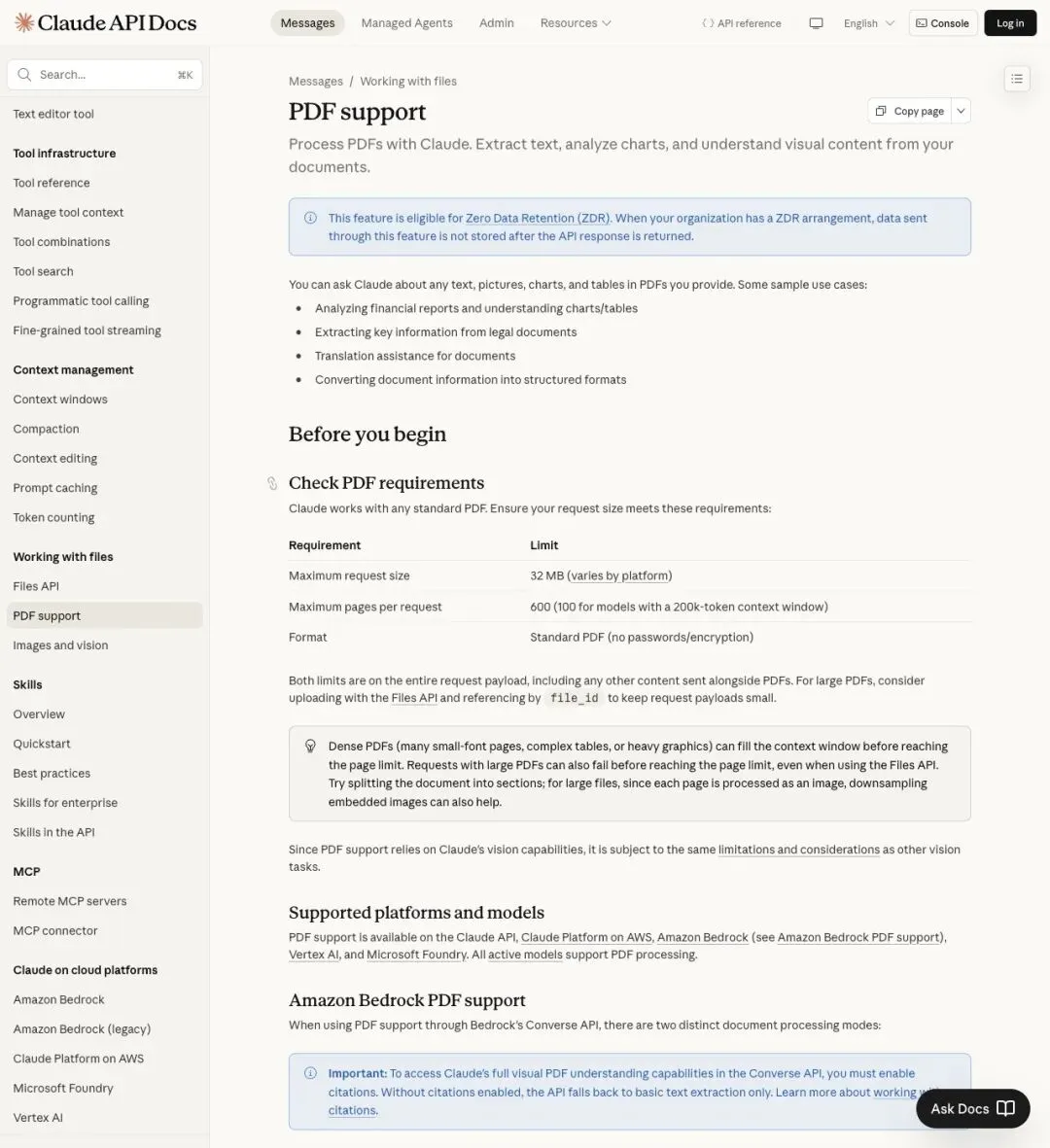
▲ Anthropic 文档:PDF 处理涉及页数上限、文件大小和内容类型判断
会话历史也在抢预算。如果你在同一个聊天里已经讨论了上一版 deck、几封邮件和一份数据表,那留给新文档的空间就所剩无几。这正是系统让 Chamath "start a new chat" 的原因——前面的对话已经占满了上下文容量。
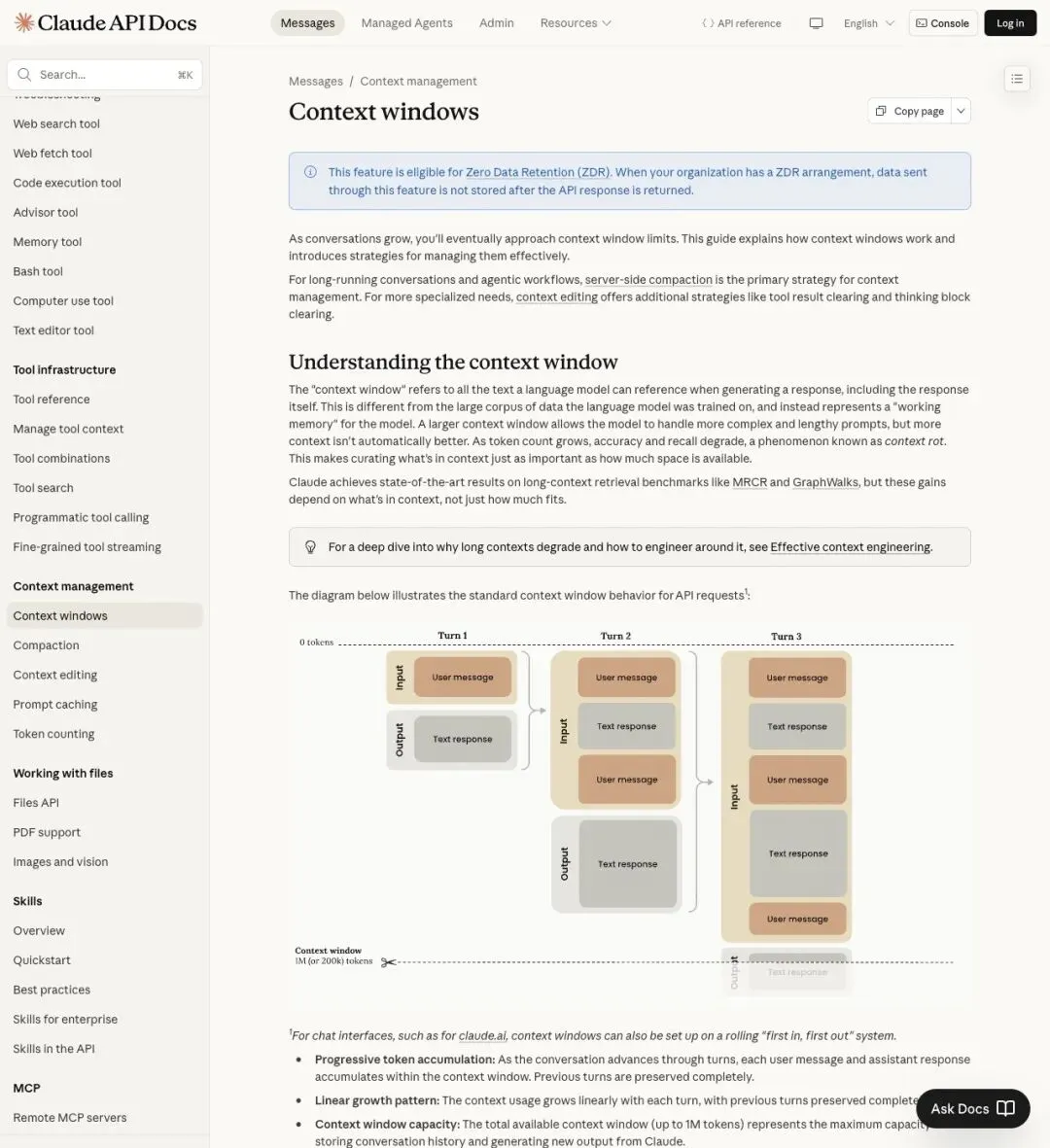
▲ Anthropic 文档解释 context window 的工作机制——所有输入和输出共享一个总预算
token 多 ≠ 什么都能塞
把上面这些限制叠在一起看,问题就清楚了:
100 万 token 的 context window 解决的是长文本场景——让你能把整个代码库、一本书、几十篇论文塞进同一个对话。这个能力主要面向 API 客户和企业合作伙伴。
但一份 deck 带来的压力完全不同。它混合了文本、图片、布局、图表和视觉信息,每个维度都有独立的限制:图片数量上限、单张图片的 token 消耗、PDF 处理路径、文件大小天花板、会话状态管理。
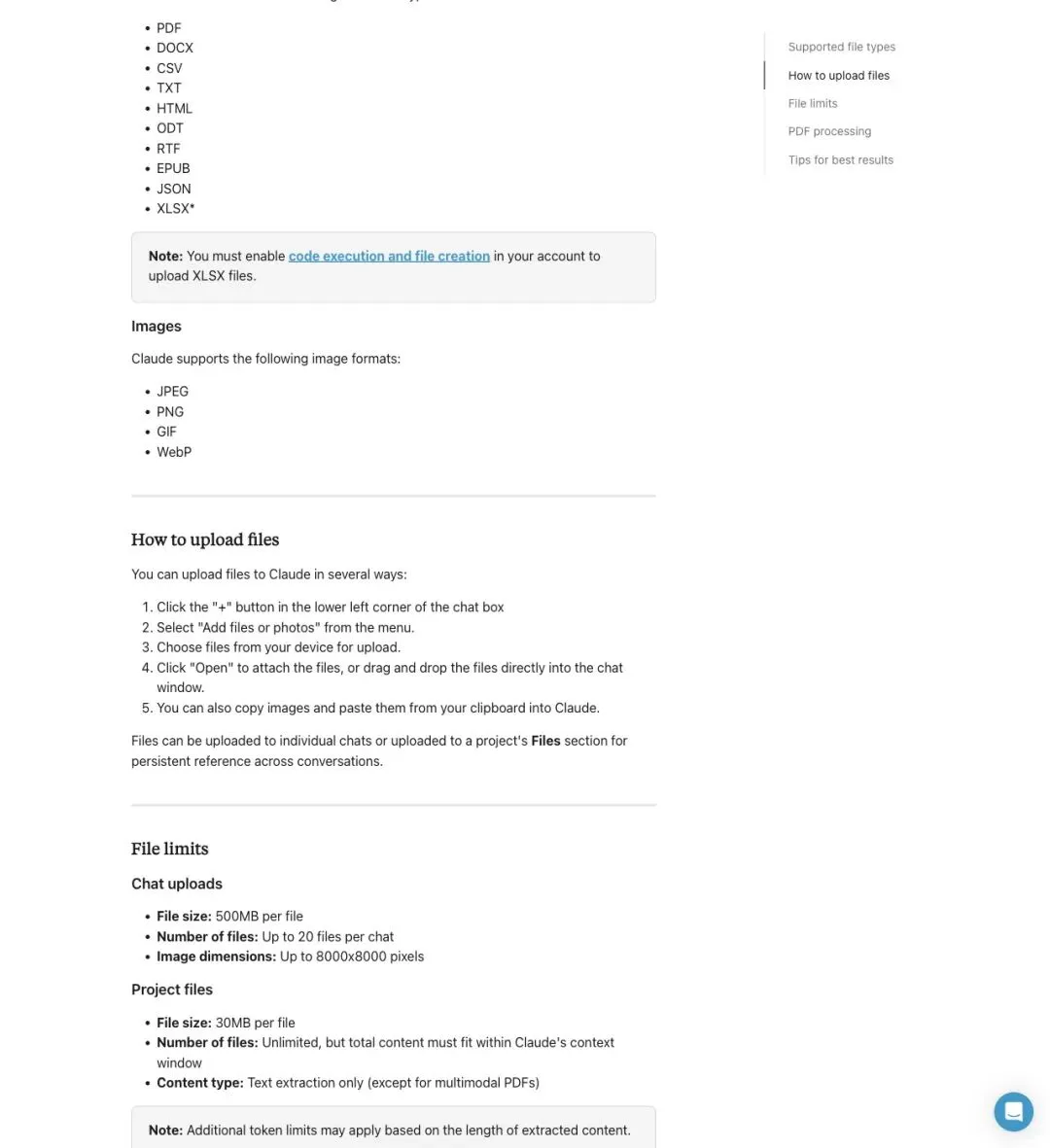
▲ Claude 帮助中心列出了支持的文件类型、大小限制和上传方式
说白了:「处理 7.5 万行代码」和「顺手读完一份投资 deck」需要的能力完全不一样。代码是纯文本结构,token 效率极高;deck 是多模态文档包,每一页都可能吃掉几千个 token 的图片预算。
用户看到"百万 token",直觉是"什么都能放进去"。但实际产品里,token 容量只是其中一道门槛,文件格式、图片数量、视觉解析和会话状态分别还有各自的门。
用户真正想要的,比加 token 难得多
评论区有人给了一个变通方案:用 Claude 桌面端,把资料放在本地文件夹里,让模型持续访问。
这个建议背后藏着一个更大的需求:用户不想每次手动上传文件、清理上下文、开新聊天。他们要的是一个项目级的工作区——模型像同事一样,长期看同一批资料,不需要每次从头开始。
对 Anthropic、OpenAI、Google 来说,下一阶段的竞争焦点可能正在发生转移。比拼谁的 context window 更长只是基础;真正决定企业用户留存的,是谁能把长上下文、文件系统访问、多模态解析、权限管理和会话状态打通成一个无缝体验。
Chamath 那条吐槽之所以引发这么大反应,是因为它说出了许多人在日常工作中反复碰到的摩擦:AI 的理论能力和实际产品体验之间,还隔着一段不小的距离。
百万 token 是一个了不起的工程成就。但对拿着一份 deck、想让 AI 帮忙过一遍的普通用户来说,他们卡住的地方,从来都不在 token 数量上。
— END —