📍 文 / 老Z
把一行 prompt 丢给图像模型,让它画一只玻璃质感的猫,今天已经不稀奇。真正麻烦的是另一种需求:做一页中文发布会 PPT,标题要对,副标题不能漏字,右边有产品结构图,左下角放品牌口号,整体还要像设计师排过版。很多模型一开始看着挺会画,字一多就开始抖,横排竖排混在一起,甚至把标语写成半熟乱码。
Qwen-Image-2.0 这份技术报告抓住的正是这个尴尬点。它不是只追一张漂亮图,而是把文生图、图像编辑、长文本排版、多语言文字、2K 级写实细节和更快推理放到同一个模型里。我觉得这比单纯刷一张榜更有意思,因为它瞄准的是创作工作流里最烦人的地方:图能不能继续改,字能不能相信,等待时间能不能接受。
漂亮图不难,难的是别把字画坏
图像模型最容易给人错觉的地方,是 demo 太会讨好眼睛。光影、皮肤、毛发、构图,只要样例挑得好,很容易让人觉得模型已经够用。可一到电商海报、课程封面、活动长图,问题就变细了:一个价格写错,整张图不能用;一行中文挤歪,设计感直接掉下去;品牌名少一个字,后面再真实的材质都救不回来。
Qwen-Image-2.0 把长文本渲染放在很前面讲,支持最长 1K token 的提示,目标场景包括 slides、posters、infographics 和 comics。这里的重点不是“能写很多字”这么简单,而是字要和画面一起成立。比如一页产品介绍页,标题、注释、图标、人物和背景要同时对齐,任何一处乱了,读者看到的就不是 AI 能力,而是返工成本。

这张 slide 展示图值得看,不是因为它证明模型已经能替代设计师,而是它暴露了 Qwen 团队想攻的任务类型:文字密集、结构密集、审美密集。我个人判断,未来图像模型在办公室场景里能不能普及,很大程度就看这种页能不能稳定生成。只会画氛围图,离真实交付还差一截。
中文文本对比更直接。论文里拿 Qwen-Image-2.0 和 GPT-Image-2、NanoBanana Pro、Seedream 5.0 Lite 等模型比较,问题不只是谁错字更少,还包括文字有没有贴在正确物体上、字号是否自然、店招和衣服上的字会不会像后期贴纸。
我看到这里的反应是:文字渲染其实是一个综合能力测试。它同时考模型的视觉定位、语言记忆、排版习惯和物理融合。能把“文字渲染”四个字写对,只是最低要求;能让它像真的刻在牌匾上、印在衣服上,才接近可用。
再换一个更贴近运营的场景。便利店要做一张夜间促销图,门牌、冰爽一夏、营业时间、品牌小字都得在正确位置上。模型如果只把便利店画得很有氛围,却把促销海报写成乱码,这张图在社媒上还能当氛围图,在真实投放里就是废稿。我觉得 Qwen-Image-2.0 把文字场景单独拎出来训练和比较,是一个很现实的选择:它承认生成图片不是给人看一眼就结束,很多图片最终要承载可读信息。
一套模型吃下生图和修图,野心在工作流
这篇报告的另一个重点,是不把生图和修图拆成两套系统。T2I 可以理解为只给文本生成图,TI2I 是给文本和图片,让模型按指令改图。真实使用里这两件事经常连在一起:先生成一张海报,再把主色调改掉,把人物换成另一张参考图,把标题改成活动名,还要保持整体风格不塌。
Qwen-Image-2.0 的架构由三块撑起来。Qwen3-VL 负责理解文本和参考图,VAE 负责把图像压到更适合生成模型处理的空间,MMDiT 负责把文字和图像条件放在一起生成目标图。这里不用记名词。看这张图时,我建议只盯一个问题:用户的 prompt、输入图和目标图,是不是在同一套通道里被处理。

这个设计的野心在工作流。以前很多系统像接力赛,理解归理解,生成归生成,编辑又换一套。接力棒传得越多,信息越容易丢。统一框架至少给了一个更干净的入口:文字、参考图、局部编辑需求,都可以被同一个模型主干一起消化。
编辑任务里的猫例子很能说明问题:把第二张图里的帽子戴到第一张猫头上,再在猫前面放胡萝卜和纸巾,同时保持猫的表情、姿势和毛色。这个需求听起来像小修图,实际很难。模型要知道哪些地方该动,哪些地方不该动。我的判断是,图像编辑最怕的不是改不了,而是改对一个东西顺手毁掉三个东西。
再比如人像物料。品牌方让模型把同一个代言人放进瑞士河岸、地铁站台、便利店门口,衣服可以换,姿势可以换,脸和气质不能跑。这里考的不是“像不像某张参考图”的单点相似,而是跨场景保持身份。Qwen-Image-2.0 把单图编辑和多图编辑放在一起做,我觉得方向是对的,因为真实工作很少只有一次操作,通常是一张主视觉一路改出横版、竖版、封面和详情页。
我更在意数据管线,不是那张架构图
如果只看架构,Qwen-Image-2.0 不会显得特别神秘。真正让我停下来看的,是它的数据策略。报告把 caption 分成通用描述、文本描述、知识描述和结构化描述,还把训练分成从低分辨率到高分辨率的多阶段过程。这个选择很朴素:模型不要一上来就啃最难的图,先学干净样本和基本语义,再逐步进入编辑、高分辨率和复杂排版。
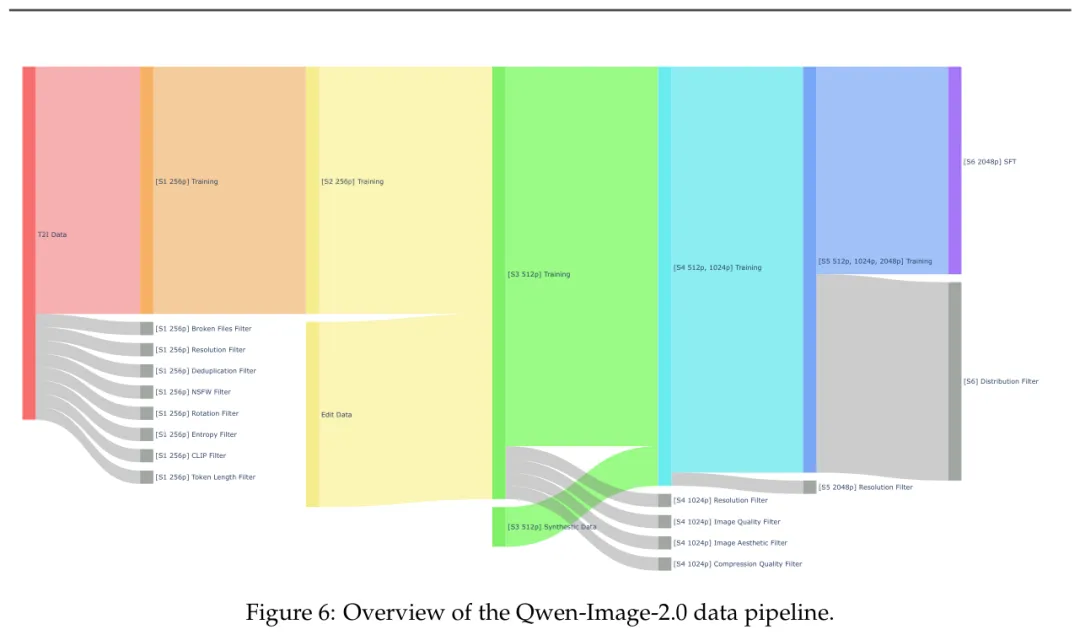
这张数据管线图里,256p、512p、1024p、2048p 不是几个冷冰冰的分辨率标签,而是一条加难度的路线。早期过滤坏文件、低质图和对不上的图文对,后面再加入编辑数据、合成数据和更严的高分辨率样本。我觉得这类工作常被低估,因为它不像新模块那样好讲故事,但模型能不能稳定,很多时候就卡在这里。
更有工程味的是失败样本处理。Qwen-Image-2.0 没有把所有 bad case 都当成同一种问题,而是分成几类:有的需要 RL 去调偏好,有的是预训练数据缺口,有的是用户 prompt 写得太粗,需要 Prompt Enhancer 帮忙补全。这个分流很关键。海报字错了和猫的身份变了,可能根因完全不同,硬塞回一个池子里训练,效率未必高。
Prompt Enhancer 也值得单独说。真实用户不会写设计 brief,很多需求只有“做一张高级感海报”“把这张图变清晰”这种短句。PE 做的事,是把这些短句扩成更细的布局、材质、光照和风格描述,再让生成结果反过来给它反馈。我喜欢这个方向,因为它承认了一个现实:用户不会为了模型去学咒语,模型得学会把人话补成可执行的视觉指令。
榜单很亮,但真正要追的是失效边界
结果部分最抓眼的数字来自 LMArena。报告写到,Qwen-Image-2.0 在 2026 年 4 月 22 日访问时,文生图榜单全球第 9,中国模型第 1,ELO 1168,并超过 Nano Banana。LMArena 是盲评偏好榜,用户不知道图来自哪个模型,这比自选样例更有参考价值。
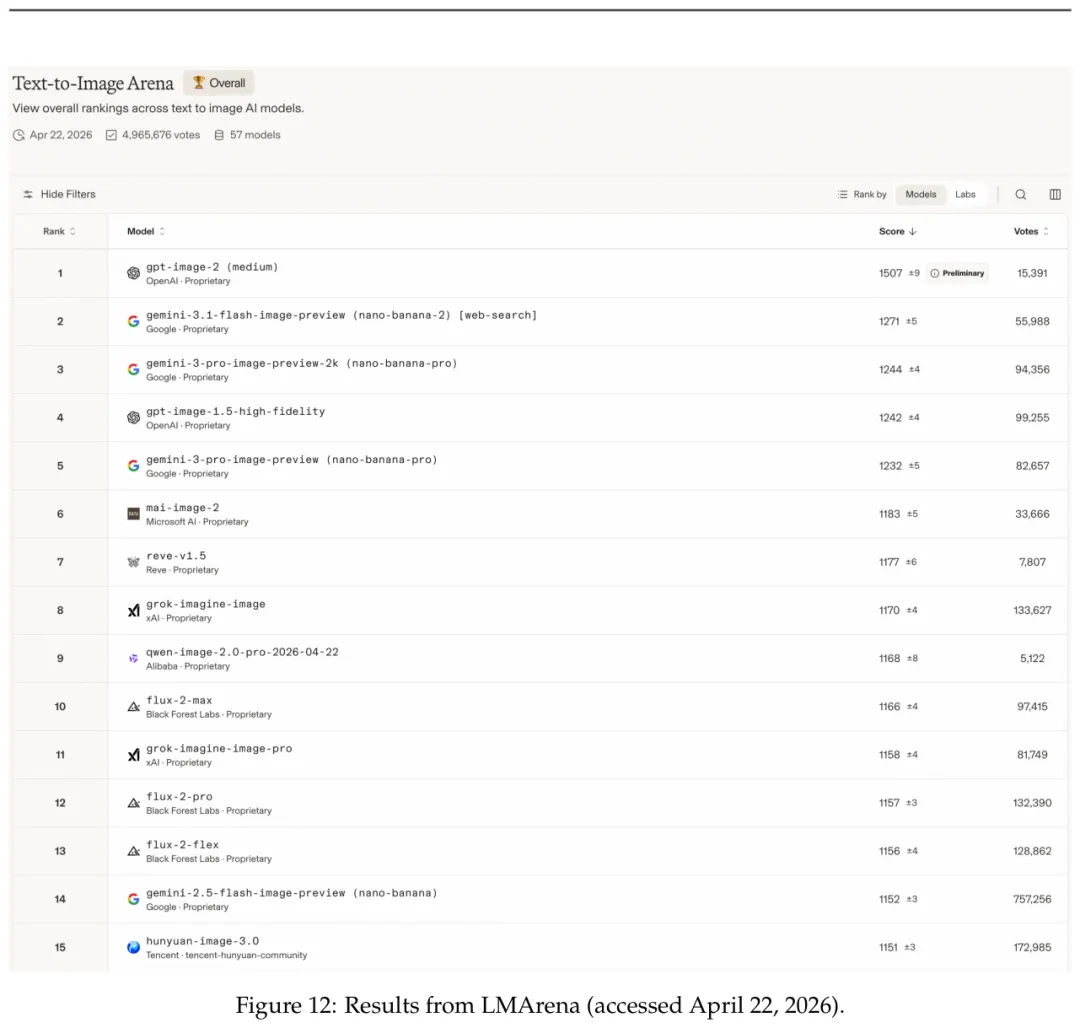
但我不会只看榜单。偏好榜能说明整体观感强,却很难回答一个更细的问题:同一套品牌规范下连续改十轮,模型会不会越来越偏?一页 30 行文字的课程海报,错字率到底多少?多语言混排时,哪些脚本最容易出事?这些才是生产系统最关心的边界。
少步蒸馏给了另一个重要信号。报告展示 4 步学生模型接近 40 步 teacher 的视觉效果。这个数字听起来像推理优化,落到使用场景里很具体:设计师反复试标题位置,运营临时换促销文案,商品图要批量出 20 个版本,等待时间会直接决定大家愿不愿意继续用。

我这里也有一个存疑点。Prompt Enhancer 会把短 prompt 补得更完整,但“更完整”不一定永远等于“更忠实”。如果用户只想要极简白底商品图,PE 会不会自动加上它觉得更好看的光影、背景和装饰?报告里有生成质量提升的样例,但我还想看到更系统的约束评测,尤其是低改动编辑和品牌规范场景。
还有一个边界,是多语言文字的真实覆盖。报告展示了多语言渲染,但不同文字系统的难度并不一样。阿拉伯文的连写、泰文的上下标、日文混排里的假名和汉字,都会让布局更复杂。我不怀疑方向,只是觉得公开报告还没把这些关键压力测试完整摊开。
如果把它放进更具体的团队流程,我会特别看两个指标:同一套版式连续生成二十张,文字错误会不会累积;同一张主视觉反复编辑五次,主体身份和布局会不会漂移。报告已经给了不少好看的样例,但生产环境不奖励单张惊艳,奖励的是少返工、可追责、能复用。这也是我觉得它下一步最该公开的部分。
所以我对 Qwen-Image-2.0 的评价比较明确:它不是一次单点炫技,更像阿里把图像模型往真实工作台上推了一步。画一页 PPT、改一张海报、保住一只猫的身份、把等待压下来,这些问题放在一起,才是图像生成接下来要面对的硬仗。能画好一张图很重要,能陪人稳定改完一套物料,才更接近真正可用。
✍️ 老Z ·
欢迎转发,谢绝洗稿

