最近又被Excel教育了一次。
手里有一份车载项目的接口规格书,MOST协议相关的
_リプログラム車載機間-IF仕様書_01_Sequence.xlsx
里面不是普通表格,而是一堆Sequence时序图。
如果只是几行数据,直接让Codex读xlsx,问题不大。可这种规格书真正有价值的信息,经常不在单元格文本里,而在箭头方向、泳道位置、分支条件、注释框和页面排版里。
所以这类Excel不要急着丢给Codex。
要先把它变成Codex更容易看的样子。
我一开始走的是Windows方案。
用PowerShell调ExcelCOM,把每个Sheet导出成PDF。这个思路很自然,因为MicrosoftExcel自己渲染,理论上最接近你肉眼看到的效果。
命令大概是这样:
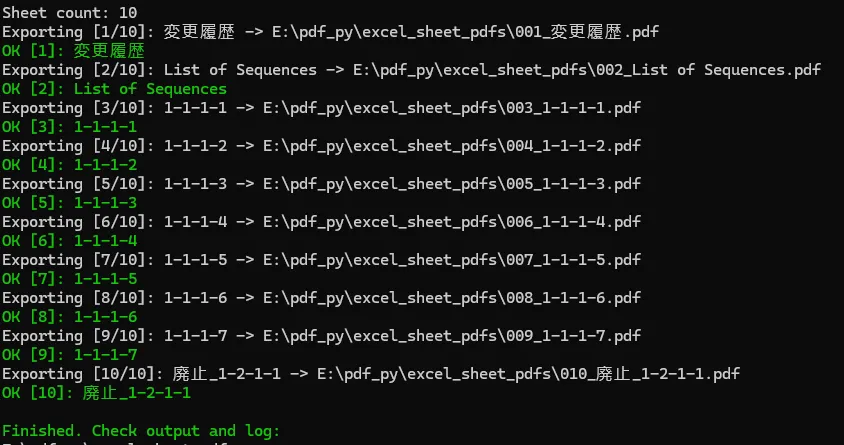
powershell -NoProfile-ExecutionPolicy Bypass `-File .\export_excel_sheets_to_pdf.ps1 `-InputExcel"E:\pdf_py\_リプログラム車載機間-IF仕様書_01_Sequence.xlsx" `-OutputDir"E:\pdf_py\excel_sheet_pdfs"
跑完以后,窗口里全是OK。
每个Sheet也确实导出了PDF。
当时我以为这一步已经过了。
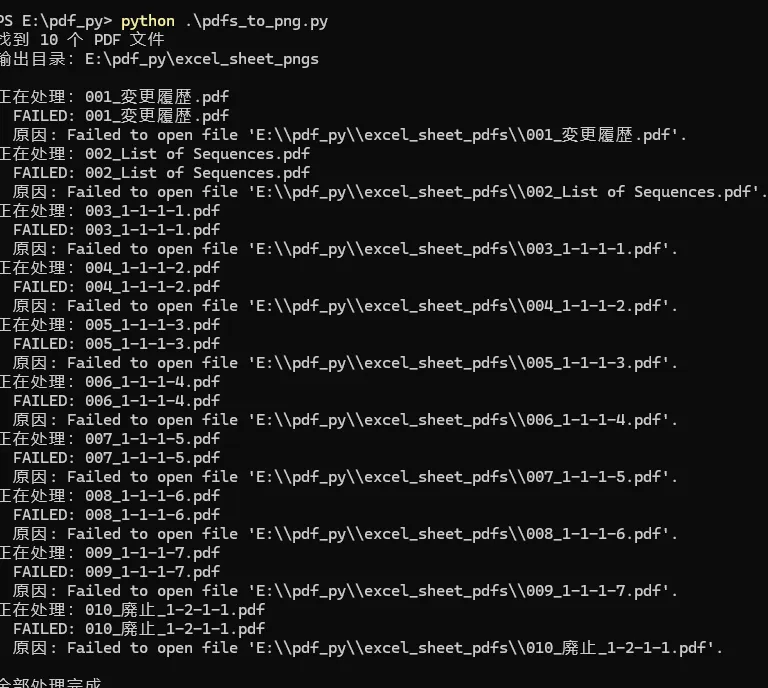
结果下一步转PNG,直接翻车。
pdftoppm报错:
Syntax Warning: May not be a PDF fileSyntax Error: Couldn't find trailer dictionarySyntax Error: Couldn't read xref table
我又换了Python+PyMuPDF,还是打不开。
于是我就查了一下文件头。
WindowsPowerShell5.1里可以这样看前16个字节:
$path = "E:\pdf_py\excel_sheet_pdfs\003_1-1-1-1.pdf"$bytes = [System.IO.File]::ReadAllBytes($path)[0..15]$bytes | ForEach-Object { "{0:X2}"-f$_ }
正常PDF应该以这个开头:
也就是%PDF。
但我看到的是:
E0 A8 91 E7 D8 F2 05 AC ...
这就说明,这些文件虽然后缀.pdf,但不是标准PDF。
后来确认,问题出在系统加密上。ExcelCOM日志显示OK,文件大小也不是0KB,但导出来的PDF其实是坏的。
这个坑很恶心,因为它不是那种一眼能看出来的失败。
你看到的是OK,工具却打不开。
所以我现在多了一个习惯:
只要PDF转图片失败,第一步不是换工具,而是先检查文件头是不是%PDF。
PDF这条路走不通,那就换路。
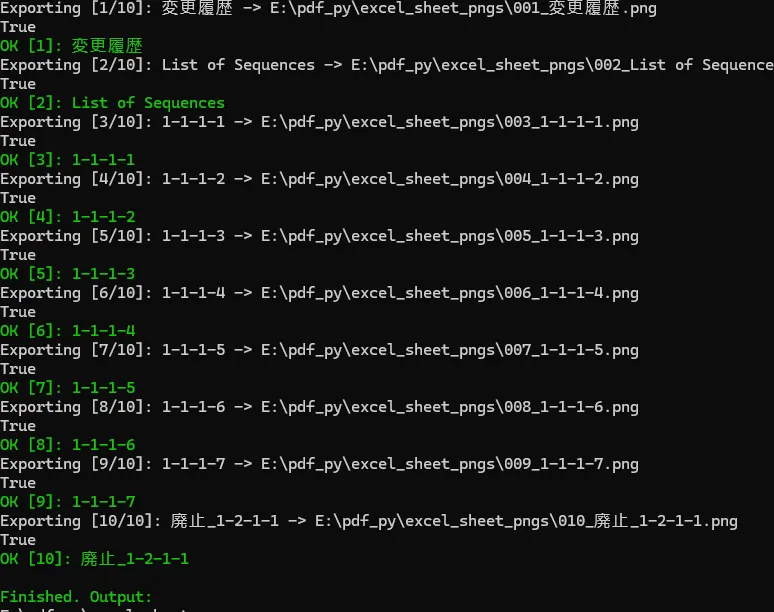
直接把ExcelSheet导成PNG。
思路是:
Excel Sheet ↓CopyPicture ↓临时Chart ↓导出PNG
这条路绕开PDF,反而更适合这种时序图规格书。
因为Codex真正要看的,是画面本身。
命令类似这样:
powershell -NoProfile-ExecutionPolicy Bypass `-File .\export_excel_sheets_to_png.ps1 `-InputExcel"E:\pdf_py\リプログラム車載機間-IF仕様書_01_Sequence.xlsx" `-OutputDir"E:\pdf_py\excel_sheet_pngs"
这次就顺了。
10个Sheet全部导成PNG。
这个方案特别适合车载项目里这些东西:
接口规格书时序图规格书ECU间通信流程由箭头、文本框、合并单元格组成的说明图
如果只是普通表格,没必要这么折腾,转CSV或Markdown就行。
但只要是时序图,图片一定要导出来。
因为箭头方向、模块位置、分支说明,这些信息不是简单读单元格就能还原的。
后来我又把文件放到了WSLUbuntu里。
这时就不能用ExcelCOM了,因为WSL里没有MicrosoftExcel。
WSL里可以用LibreOffice:
sudo apt updatesudo apt install -y libreoffice poppler-utils fonts-noto-cjk
我的文件目录是:
/home/ll/code/App22/src/doc/vpu
我会先整理一个给Codex用的目录:
cd /home/ll/code/App22/src/doc/vpumkdir -p excel_for_codex/raw excel_for_codex/pdfs excel_for_codex/pngscp"リプログラム車載機間-IF仕様書_01_Sequence.xlsx" excel_for_codex/raw/
然后用LibreOffice转PDF:
libreoffice --headless \ --convert-to pdf \ --outdir excel_for_codex/pdfs \"excel_for_codex/raw/リプログラム車載機間-IF仕様書_01_Sequence.xlsx"
看到这句,基本说明PDF生成了:
using filter : calc_pdf_Export
但我还是建议查一下:
file excel_for_codex/pdfs/*.pdfxxd -l 16 excel_for_codex/pdfs/*.pdf
正常应该能看到PDF document,文件头里有:
也就是%PDF。
再转图片:
for pdf in excel_for_codex/pdfs/*.pdf; do base="$(basename "$pdf" .pdf)" pdftoppm -png -r 200 "$pdf""excel_for_codex/pngs/$base"done
如果字太小,就把200改成300。
不过WSL这条路有一个问题要提前说。
LibreOffice渲染Excel,不一定和MicrosoftExcel完全一致。
普通表格还好,复杂时序图、日文规格书、形状对象多的时候,可能会有错位。
所以我的实际选择是:
版式要求高:优先WindowsExcel原生导PNG快速预览:WSLLibreOffice转PDF/PNG普通数据表:CSV/Markdown
最后给Codex的目录,我一般会整理成这样:
excel_for_codex/ raw/ 原始xlsx pdfs/ 转出的PDF pngs/ 每页图片 merged/ 跨页Sequence合并长图,可选 README_FOR_CODEX.md
README_FOR_CODEX.md很重要。
比如时序图被拆成多张图片时,Codex很容易把每张图当成独立流程。所以要提前告诉它:
# Excel Sequence图说明raw/是原始Excel。pdfs/是从Excel转出的PDF。pngs/是由PDF按页导出的图片。注意:- 同一个sequence可能被拆成多张连续图片。- 请按文件名页码顺序阅读。- 如果某页缺少参与方名称,请参考前一页、后一页或List of Sequences。- 输出时按sequence编号归纳,不要按图片页码碎片化总结。
提示词也要写清楚。
不要只写:
我会这样写:
请分析/home/ll/code/App22/src/doc/vpu/excel_for_codex。请按MOST、车载多媒体网络、ECU间接口、重编程流程、状态迁移、消息交互来理解。请先根据List of Sequences建立sequence清单。然后按sequence编号逐个分析。如果一个sequence被拆成多张图片,请按页码顺序合并理解。每个sequence输出:- sequence编号- sequence名称/用途- 对应图片文件- 参与ECU/节点/模块- 触发条件- 主流程时间线- 消息方向- MOST相关消息/命令/状态- ECU间IF/信号/参数- 条件分支/异常分支- 超时/重试/失败处理- 结束条件- 工程理解总结- 需要结合代码或日志确认的点
这里有个细节很关键。
要先把资料拆成模型能读懂的形态,再把上下文边界讲清楚。
Excel尤其如此。
它不是一个文件。
它是一组信息源:
原始文件+ 表格数据+ 页面截图+ 文件索引+ 分析提示词
这套流程不高级,但很救命。
尤其是车载项目里那些Excel规格书、接口表、Sequence图,别急着让Codex分析。
先把它变成Codex能看懂的样子。
这一步做好了,后面再让它整理流程、对照代码、生成问题单,才不容易跑偏。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
