飞书 API多维表格自动化数据同步
你有没有过这样的经历:每天要把 Excel 里的生产数据手动填进飞书多维表格,日复一日,枯燥又容易出错。
今天分享一个我在工厂里实际运行的方案——文件监控自动导入脚本。只要 Excel 文件一更新,60 秒内数据就自动同步到飞书,全自动、零手动。
一、整体架构:四步完成数据流转
二、核心原理:文件变化监控 + 批量 API 写入
脚本的核心逻辑分三层:
1. 文件变化检测(MD5 哈希)
通过比对文件 MD5 哈希值判断文件是否发生变化——这是业界最常用的变更检测方式,精确且性能开销极低。
2. 飞书认证(Tenant Access Token)
通过 App ID + App Secret 获取访问令牌,这是调用所有飞书 Open API 的前提。
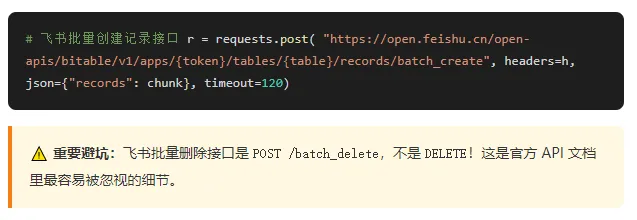
3. 批量写入(并发 500 线程)
每次最多 500 条记录为一组,启用 500 个线程并发写入,是冲量场景下的最优配置。
三、完整源码(含详细注释)
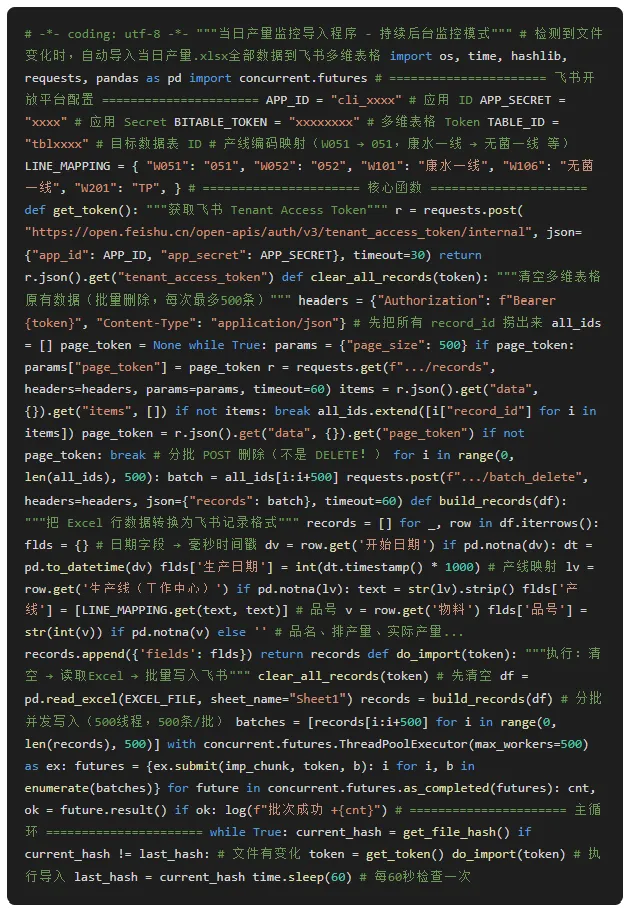
# -*- coding: utf-8 -*-"""当日产量监控导入程序 - 持续后台监控模式"""# 检测到文件变化时,自动导入当日产量.xlsx全部数据到飞书多维表格importos, time, hashlib, requests, pandasaspdimportconcurrent.futures# ====================== 飞书开放平台配置 ======================APP_ID ="cli_xxxx"# 应用 IDAPP_SECRET ="xxxx"# 应用 SecretBITABLE_TOKEN ="xxxxxxxx"# 多维表格 TokenTABLE_ID ="tblxxxx"# 目标数据表 ID# 产线编码映射(W051 → 051,康水一线 → 无菌一线 等)LINE_MAPPING = {"W051":"051","W052":"052","W101":"康水一线","W106":"无菌一线","W201":"TP", }# ====================== 核心函数 ======================defget_token():"""获取飞书 Tenant Access Token"""r = requests.post("https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal", json={"app_id": APP_ID,"app_secret": APP_SECRET}, timeout=30)returnr.json().get("tenant_access_token")defclear_all_records(token):"""清空多维表格原有数据(批量删除,每次最多500条)"""headers = {"Authorization":f"Bearer {token}","Content-Type":"application/json"}# 先把所有 record_id 捞出来all_ids = [] page_token =Nonewhile True: params = {"page_size":500}ifpage_token: params["page_token"] = page_token r = requests.get(f".../records", headers=headers, params=params, timeout=60) items = r.json().get("data", {}).get("items", [])if notitems:breakall_ids.extend([i["record_id"]foriinitems]) page_token = r.json().get("data", {}).get("page_token")if notpage_token:break# 分批 POST 删除(不是 DELETE!)foriinrange(0,len(all_ids),500): batch = all_ids[i:i+500] requests.post(f".../batch_delete", headers=headers, json={"records": batch}, timeout=60)defbuild_records(df):"""把 Excel 行数据转换为飞书记录格式"""records = []for_, rowindf.iterrows(): flds = {}# 日期字段 → 毫秒时间戳dv = row.get('开始日期')ifpd.notna(dv): dt = pd.to_datetime(dv) flds['生产日期'] =int(dt.timestamp() *1000)# 产线映射lv = row.get('生产线(工作中心)')ifpd.notna(lv): text =str(lv).strip() flds['产线'] = [LINE_MAPPING.get(text, text)]# 品号v = row.get('物料') flds['品号'] =str(int(v))ifpd.notna(v)else''# 品名、排产量、实际产量...records.append({'fields': flds})returnrecordsdefdo_import(token):"""执行:清空 → 读取Excel → 批量写入飞书"""clear_all_records(token)# 先清空df = pd.read_excel(EXCEL_FILE, sheet_name="Sheet1") records =build_records(df)# 分批并发写入(500线程,500条/批)batches = [records[i:i+500]foriinrange(0,len(records),500)]withconcurrent.futures.ThreadPoolExecutor(max_workers=500)asex: futures = {ex.submit(imp_chunk, token, b): ifori, binenumerate(batches)}forfutureinconcurrent.futures.as_completed(futures): cnt, ok = future.result()ifok: log(f"批次成功 +{cnt}")# ====================== 主循环 ======================while True: current_hash =get_file_hash()ifcurrent_hash != last_hash:# 文件有变化token =get_token()do_import(token)# 执行导入last_hash = current_hash time.sleep(60) # 每60秒检查一次
四、字段映射关系详解
Excel 列名与飞书多维表格字段不是简单的一一对应,需要做类型转换和数据清洗:
| | |
|---|
| | |
| | → 根据 LINE_MAPPING 字典映射(W051→051) |
| | |
| | |
| | |
| | |
| | |
💡 产线映射的必要性:ERP 系统里的产线编码(W101)和业务口语(康水一线)不同。通过 LINE_MAPPING 做一次标准化,保证飞书里的数据干净统一。
五、飞书开放平台应用创建步骤
1
创建企业自建应用
进入 飞书开放平台 → 开发者后台 → 创建应用 → 选择「企业自建应用」→ 填写应用名称和描述
2
获取 App ID 和 App Secret
在应用详情页 → 凭证与基础信息 → 复制 App ID 和 App Secret(妥善保管,不要泄露)
3
开通多维表格权限
权限管理 → 搜索「bitable」→ 开通以下权限:
bitable:app:readonlybitable:appbitable:table
4
发布应用版本
应用发布 → 创建版本 → 申请发布(管理员审批后生效)
5
获取多维表格 Token 和 Table ID
打开目标多维表格 → 地址栏 URL 中提取:
https://xxx.feishu.cn/base/{BITABLE_TOKEN}?table={TABLE_ID}
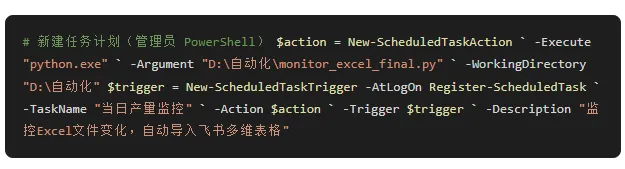
六、定时任务配置(开机自启动)
有了脚本,还需要让它开机自动跑。用 Windows 任务计划程序一键搞定:
七、性能对比:优化前后
八、常见报错与解决方案
写在最后
这套方案最初是为了解决每天手动录入生产数据的痛点。核心价值不是「技术多厉害」,而是把人的精力从重复劳动中解放出来。
代码本身不长,但涵盖了企业级数据同步的几个关键点:文件变化检测、API 认证管理、批量并发写入、错误重试机制。改一改 Excel 路径和字段映射,这套方案可以直接套用到其他类似的场景里。
如果你也在飞书生态里做数据治理,欢迎评论区交流你的做法。觉得有用的话,转发给你身边需要的人 🙂