截至目前,绝大多数用于HTA的药物经济学模型都是使用Microsoft Excel搭建的,然而这种使用电子表格构建模型的方法在近几十年来没有实质性更新,许多经济学模型仍使用Briggs et al.在2006年出版的建模手册中的方法。近年来,得益于R语言强大的向量,矩阵等功能,基于其构建的药物经济学模型被验证具有相比于传统Excel模型执行速度更快且更容易验证等优势。 自2020年起,Excel和Google Sheets等表格工具进行了多次更新,增加了对动态数组函数(Dynamic array function)功能的支持,这些函数不仅允许将R语言建模中的许多技术应用在电子表格中,同时也避免了使用复杂的VBA(Visual Basic for Applications)代码进行概率分析和其他复杂计算的需要,大幅简化了电子表格模型的构建并减少了开发、验证和执行所需的时间。 本两篇推送将基于发表在PharmacoEconomics的文章《A Modern Approach for Constructing Decision Analytic Models in Microsoft Excel》(在Microsoft Excel中构建决策分析模型的现代方法)一文,讲解如何使用新版Excel的动态数组函数功能构建高效马尔可夫队列模型,包括如何使用单个公式实现从构建马尔可夫轨迹到计算总成本与产出完整的流程,以及如何不使用VBA代码进行抽样、蒙特卡洛模拟及绘制CEAC等。相关文章推荐:不使用VBA在Excel进行患者层面离散事件模拟(Patient-level DES)建模方法Blissett, Rob, Will Sullivan, Inola Subban, and Adam Igloi-Nagy. ‘Patient-Level Health Economic Modeling in Excel Without VBA: A Tutorial’. PharmacoEconomics, ahead of print, 8 October 2025. https://doi.org/10.1007/s40273-025-01543-7.)
本节将使用动态数组函数进行概率性马尔可夫队列模型的构建,旨在通过在Excel的单一单元格中输入单个公式实现从分布中抽取随机样本、进行蒙特卡洛模拟、计算增量结果及ICER,并通过例如绘制成本效益可接受性曲线(CEAC)、成本效果可接受性边界(CEAF)等方式展示分析结果。这种方法可以避免在建模过程中使用任何组件、插件、软件包及VBA宏代码。构建概率性模型的第一步是为具有不确定性的参数分配一个合适的概率分布,并在这些分布中进行随机抽样。在传统Excel建模的方法中,每次抽样只从每种分布中随机抽取一个样本,这些样本被用于计算马尔可夫轨迹和每种治疗方案的总成本和健康产出,然后使用VBA宏存储这些结果,并在蒙特卡洛模拟的每次迭代中重复抽样和计算的过程。 在本案例中将概述使用动态数组函数不借助VBA进行两种蒙特卡洛模拟抽样的方法,即传统的单个抽样方法,和从每个分布中预先抽取多个样本,每个样本对应蒙特卡洛模拟的一次迭代的多个抽样方法。下文的单个抽样公式模板可用于从同一组参数的一种或多种分布中进行单个样本的抽取,并在表格中以每行一种分布的形式输出。该公式还添加了额外一列表格用于总结每种分布的属性和每次随机抽样的随机概率。 转换概率和健康效用等参数常用到Beta分布,该分布使用均值(μ)和标准差(σ)进行参数化计算alpha(α)和beta(β);也可以使用从试验数据中获取的alpha和beta反向计算μ和σ。 首先,假设对两个由均值和标准差参数化的Beta分布进行建模:μ = 0.85,σ = 0.10;以及μ = 0.75,σ = 0.05。此时的随机抽样函数为:= LET(μ, {0.85; 0.75}, σ, {0.10; 0.05}, α, μ * ((μ * (1 - μ) / σ ^ 2) - 1), β, α * (1 / μ - 1), p, RANDARRAY(COUNT(μ)), x, BETA.INV(p, α, β), HSTACK(μ, σ, p, α, β, x)) 通过修改(μ, {μ1; μ2; ...}, σ, {σ1; σ2; ...})中μ和σ的数组,该函数可用于任何模型中任意数量的Beta分布。 本公式中的LET函数用于定义每个分布的μ和σ,从而更加清晰的编写α和β的表达式;RANDARRAY和COUNT函数的作用是为每个分布精确抽取一个随机数。这些随机数(p)和计算出的α和β将被存储为列向量,并由BETA.INV函数为每组分布创建一个从该组beta分布中随机抽取的样本(x)的列向量。最后一行的HSTACK函数会创建一个六列的表格,从左至右输出每组分布的均值(μ)、标准差(σ)、随机概率(p)、alpha(α)和 beta(β)参数以及随机beta抽样(x)。 接下来,假设alpha(α)和beta(β)可以直接从试验数据中获取,我们可以使用类似的公式逆向获得均值(μ)、标准差(σ)和从该Beta分布中随机抽取的样本,并和上表一样的形式输出。本案例中假设两组分布:α = 48,β = 2;以及α = 60,β = 90:= LET(α, {48; 60}, β, {2; 90}, μ, α / (α + β), σ, SQRT((α * β) / ((α + β)^2 * (α + β + 1))), p, RANDARRAY(COUNT(α)), x, BETA.INV(p, α, β), HSTACK(μ, σ, p, α, β, x))同样仅需修改α和β的数组即可用于任何模型中任意数量的Beta分布。1.2 Normal、log-normal、gamma、Dirichlet分布= LET(μ, {0.50; 2.50}, σ, {0.10; 1.00}, p, RANDARRAY(COUNT(μ)), x, NORM.INV(p, μ, σ), HSTACK(μ, σ, p, x))- Log-normal分布(μ_log和σ_log)
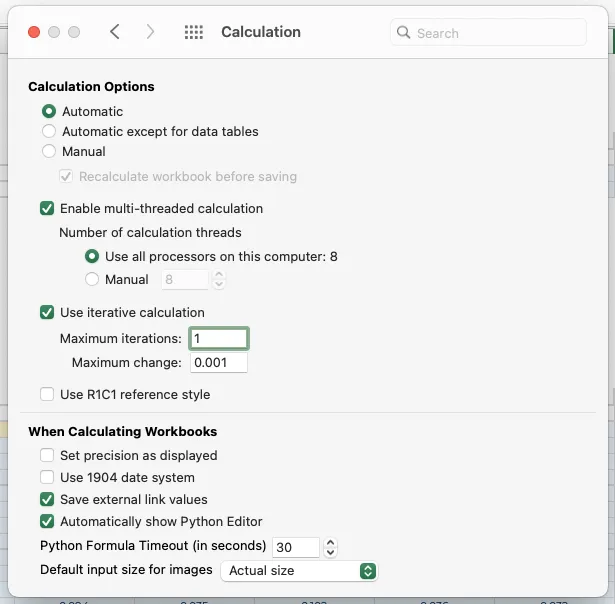
= LET(μ_log, {-0.5; -0.3}, σ_log, {0.1; 0.1}, μ, EXP(μ_log + σ_log ^ 2 / 2), σ, μ * (EXP(σ_log ^ 2) - 1) ^ 0.5, p, RANDARRAY(COUNT(μ_log)), x, LOGNORM.INV(p, μ_log, σ_log), HSTACK(μ, σ, p, μ_log, σ_log, x))= LET(μ, {800; 1000; 2700}, σ, {200; 500; 900}, k, μ ^ 2 / σ ^ 2, θ, σ ^ 2 / μ, p, RANDARRAY(COUNT(μ)), x, GAMMA.INV(p, k, θ), HSTACK(μ, σ, p, k, θ, x))= LET(α, {91; 5; 3; 1}, Σα, SUM(α), μ, α / Σα, σ, SQRT(α * (Σα - α) / (Σα ^ 2 * (Σα + 1))), p, RANDARRAY(COUNT(α)), γ, GAMMA.INV(p, α, 1), Σγ, SUM(γ), x, γ / Σγ, HSTACK(μ, σ, p, α, γ, x))另一种方法是使用单一公式从每种分布中抽取多个样本,以表格的形式储存,每行代表一个分布,每列代表一次迭代。这种方法允许我们在下一节中实现不使用VBA宏进行蒙特卡洛模拟。 首先将蒙特卡洛迭代次数(例如1000)赋名“iterations”以便更改迭代次数: 为了避免不必要的重新抽样拖慢计算速度和干扰结果的复现性,需要关闭随机抽样的重复抽样功能(并在必要时重新打开)以允许使用同一组随机抽样进行重复分析。首先在单元格中新建一个名为“switch1”的布尔变量(TRUE/FALSE)作为在禁用和启用重新采样之间进行切换的开关: 随后在Excel的Preference(偏好设置)> Calculation(计算)> Calculation Options(计算选项)功能中将Maximum iterations(最大迭代次数)设为1: 为存储随机样本的范围赋名(在本案例中命名为m_beta)后,便可以使用以下公式为每个Beta分布和每次迭代创建随机抽样矩阵,并通过将switch1更改为FALSE以禁用重新采样:= IF(switch1, LET(μ, {0.85; 0.75}, σ, {0.10; 0.05}, α, μ * ((μ * (1 - μ) / σ ^ 2) - 1), β, α * (1 / μ - 1), p, RANDARRAY(COUNT(μ), iterations), x, BETA.INV(p, α, β), x), m_beta) 在本函数式中,RANDARRY函数包含了迭代次数从而生成一个随机数矩阵(而非列向量),并将此矩阵与α和β的列向量一起传递给BETA.INV函数。BETA.INV函数生成一个每个分布(每行)和每次迭代(每列)的抽样均不重复的随机Beta分布抽样矩阵。以下为其他分布类型的多个抽样函数式:= IF(switch1, LET(μ, {0.50; 2.50}, σ, {0.10; 1.00}, p, RANDARRAY(COUNT(μ), iterations), x, NORM.INV(p, μ, σ), x), m_norm)- Log-normal分布(μ_log和σ_log)
= IF(switch1, LET(μ_log, {-0.5; -0.3}, σ_log, {0.1; 0.1}, μ, EXP(μ_log + σ_log ^ 2 / 2), σ, μ * (EXP(σ_log ^ 2) - 1) ^ 0.5, p, RANDARRAY(COUNT(μ_log), iterations), x, LOGNORM.INV(p, μ_log, σ_log), x), m_lognorm)= IF(switch1, LET(μ, {800; 1000; 2700}, σ, {200; 500; 900}, k, μ ^ 2 / σ ^ 2, θ, σ ^ 2 / μ, p, RANDARRAY(COUNT(μ), iterations), x, GAMMA.INV(p, k, θ), x), m_gamma)= IF(switch1, LET(α, {91; 5; 3; 1}, Σα, SUM(α), μ, α / Σα, σ, SQRT(α * (Σα - α) / (Σα ^ 2 * (Σα + 1))), p, RANDARRAY(COUNT(α), iterations), γ, GAMMA.INV(p, α, 1), Σγ, SUM(γ), x, γ / Σγ, x), m_dirichlet)通过以上方法获得随机抽样样本后,便可以使用动态数组函数进行蒙特卡洛模拟。此节将介绍两种方法:第一种使用多个公式计算治疗方案和迭代组合(例如治疗A,迭代1)的总成本和结果,此方法需要将公式复制给每次迭代,因此每种治疗方案会产生大量独立公式;第二种使用单一公式一次性计算特定治疗方案在所有迭代中的总成本和结果,只需要为每种治疗方案复制一次公式,这种方法所需的公式更少更简单,但在复杂模型中的运行速度更慢。 本方法将构建一个用于计算治疗方案A在单次迭代中的总成本、QALY和生命年的函数式,然后将此公式复制到所有迭代中。首先在表格中使用SEQUENCE函数创建一个次数列代表每一次迭代:= SEQUENCE(iterations)
本案例包含1000次迭代,所以创建一个从1到1000的列,然后在该列右侧的每个单元格中输入一个LET函数,用于计算治疗方案A在对应迭代次数下的总成本、QALY和生命年。在此函数式中,OFFSET和INDIRECT函数用于从左侧单元格读取迭代次数:OFFSET(INDIRECT(“RC”, FALSE), 0, −1)
为了能启用或禁用概率性结果的计算,还需创建一个名为“switch2”的开关,使重新随机抽样(switch1)和重新计算概率性结果(switch2)可根据需要分别进行。为避免不必要的重新计算,建议在不需要时禁用这两个开关,且每次只启用一个开关。 为确保每次迭代中抽样的独特性,在此方法中将转移概率的列向量(v_p_A和v_p_B)扩展为矩阵,其中每一列代表一次迭代。若采用概率性的转移概率,使用此前多个抽样的公式为每次迭代抽取一个独特的随机样本,并将其输入到矩阵对应的行中;若采用确定性的转移概率,可以使用SEQUENCE或MAKEARRAY函数将相同的值输入到每一列中。例如,在每个周期中保持在“死亡”状态的概率固定为1;可以通过使用以下公式创建由1组成的行向量,每个迭代一个:= SEQUENCE(1, iterations, 1, 0)
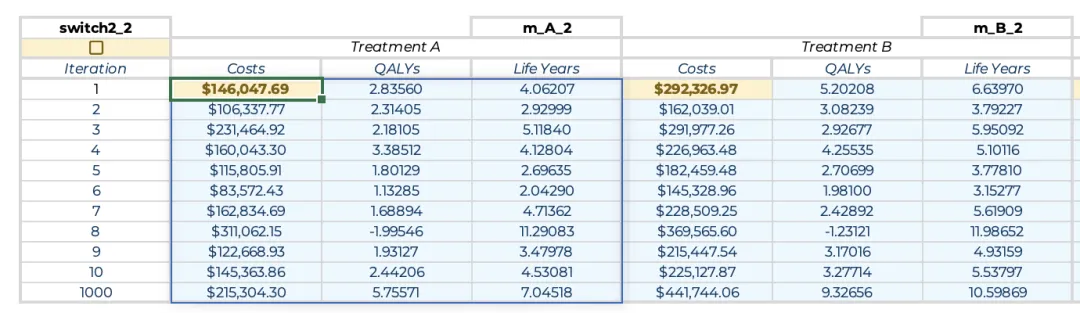
处理完转移概率后,每周期的输入成本(v_c_inp_A和v_c_inp_B)和每周期QALY产出(v_q_inp)的行向量也需要转换为矩阵。为此,每个向量都被转置为列向量,然后扩展为矩阵,每个迭代对应一列。在蒙特卡罗模拟的每次迭代中,相应的列将被读入内存并转置为所需的行向量。这些矩阵可以包含固定成本或健康结果(例如,与死亡相关的健康效用,固定为0)和不确定成本或健康结果的组合,可以使用此前多个抽样的公式抽取随机样本。 这些新矩阵的命名方式应与现有列向量相同,但将“v”替换为“m”。例如,治疗A的转移概率矩阵将命名为“m_p_A”。最后,为存储每个治疗方案的概率结果的新范围分配名称。对于治疗方案A命名为“m_A”;此范围有表示迭代次数的一行和存储每次迭代的总成本、QALY和生命年的三列。将以下公式复制到迭代次数列右侧的单元格中,以计算蒙特卡罗模拟相应迭代中治疗方案A的总成本、QALY和生命年:= LET(i, OFFSET(INDIRECT("RC", FALSE), 0, -1), IF(ISNUMBER(i), IF(switch2, LET(m_tm, WRAPROWS(INDEX(m_p_A, , i), 4), m_mt, REDUCE(v_init, SEQUENCE(cycles), LAMBDA(dist,cycle, VSTACK(dist, MMULT(INDEX(dist, cycle,), m_tm)))), v_c_inp, TRANSPOSE(INDEX(m_c_inp_A, , i)), v_q_inp, TRANSPOSE(INDEX(m_q_inp, , i)), c, SUM(m_mt * v_c_inp * v_cw_c_#), q, SUM(m_mt * v_q_inp * v_cw_h_#), ly, SUM(m_mt * v_ly_inp * v_cw_h_#), HSTACK(c, q, ly)), INDEX(m_A, i, )), HSTACK("", "", "")))
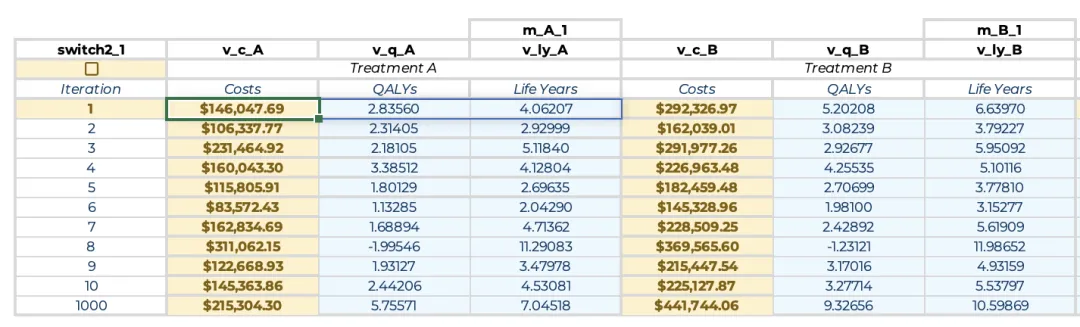
从左侧相邻的单元格中读取迭代次数(i, OFFSET(INDIRECT("RC", FALSE), 0, -1)),若左侧单元格是数字格式,则继续计算下一步;若不是,则跳过后续步骤,输出空值(IF(ISNUMBER(i), ..., HSTACK("", "", "")));
若switch2已启用(TRUE),则重新计算概率性结果并继续计算下一步(IF(switch2, ..., INDEX(m_A, i, )));若未启用(FALSE),则跳过后续步骤,并从范围m_A的第i行中读取现有结果并直接返回至表格;
若上一步中需要重新计算,首先构建此迭代的转移概率矩阵(m_tm)。从m_p_A中读取与迭代i对应的转移概率列,然后构建一个4x4的转移概率矩阵(m_tm, WRAPROWS(INDEX(m_p_A, , i), 4));
然后使用上篇推送的REDUCE函数计算马尔可夫轨迹(m_mt)(m_mt, REDUCE(v_init, SEQUENCE(cycles), LAMBDA(dist,cycle, VSTACK(dist, MMULT(INDEX(dist, cycle,), m_tm)))));
接下来从每周期输入成本列(m_c_inp_A)中读取与迭代次数i对应的成本,并将其转置为名为v_c_inp的行向量(v_c_inp, TRANSPOSE(INDEX(m_c_inp_A, , i)));使用相同方法处理每周期QALY,生成名为v_q_inp的行向量(v_q_inp, TRANSPOSE(INDEX(m_q_inp, , i)))。
最后,使用上篇推送中整合函数式的方法计算本次迭代的总折现成本(c)、QALYS(q)和生命年(ly),并使用HSTACK函数将这些以三列行向量的形式输出(c, SUM(m_mt * v_c_inp * v_cw_c_#), q, SUM(m_mt * v_q_inp * v_cw_h_#), ly, SUM(m_mt * v_ly_inp * v_cw_h_#), HSTACK(c, q, ly))。
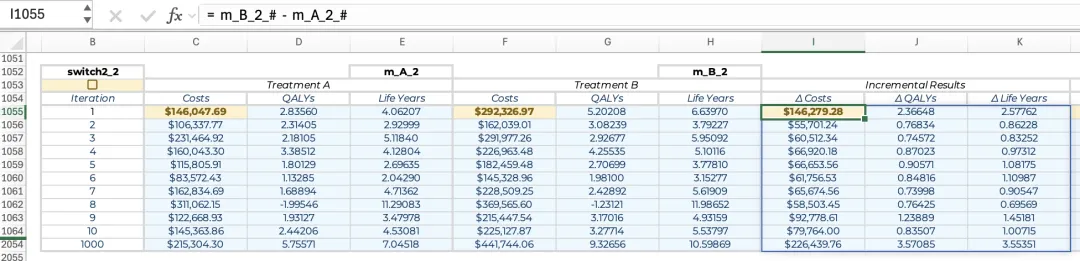
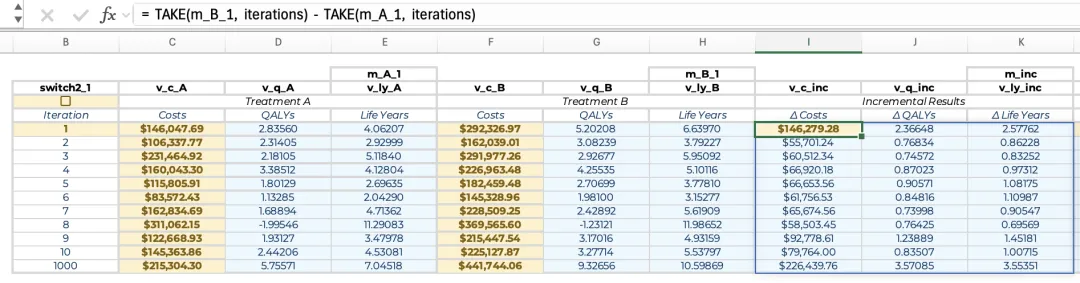
对于治疗方案组B,仅需将公式中的_A更新为_B,和更新读取迭代次数列的偏移量(将读取迭代次数公式中的-1更新为-4)。 在较复杂模型中,该计算过程可能耗时数秒,且计算结束后第一步应先关闭switch2。 另一种方法是使用单一公式一次性计算特定治疗方案在所有迭代中的总成本和结果。将以下公式复制到每组治疗方案的单个单元格中,可以用于在所有迭代中执行完整的蒙特卡洛模拟过程。其输出与多公式方法完全一致,唯一区别是仅需将公式输入指各治疗方案的左上角单元格中,而无需在整列中将公式向下复制填充:= IF(switch2, MAKEARRAY(iterations, 3, LAMBDA(i, column, LET(m_tm, WRAPROWS(INDEX(m_p_A, , i), 4), m_mt, REDUCE(v_init, SEQUENCE(cycles), LAMBDA(dist,cycle, VSTACK(dist, MMULT(INDEX(dist, cycle,), m_tm)))), v_c_inp, TRANSPOSE(INDEX(m_c_inp_A, , i)), v_q_inp, TRANSPOSE(INDEX(m_q_inp, , i)), c, SUM(m_mt * v_c_inp * v_cw_c_#), q, SUM(m_mt * v_q_inp * v_cw_h_#), ly, SUM(m_mt * v_ly_inp * v_cw_h_#), SWITCH(column, 1, c, 2, q, 3, ly)))), TAKE(m_A, iterations)) 该公式通过在MAKEARRAY函数中嵌套LAMBDA来实现迭代循环,从而替代了此前为每次迭代单独设置公式的做法。其中,用于生成马尔可夫轨迹以及计算单次迭代总成本与产出的核心函数与多公式方法一致;不同之处在于,本方法的公式中引入了SWITCH函数,以按预定顺序将各项结果填入表格列中。 此外,若关闭重新计算功能(即设置“switch2 = FALSE”),公式将启用TAKE函数,一次性从命名区域“m_A”中读取现有的全部迭代结果并返回至表格。该方法通过TAKE函数将“m_A”限定在当前指定的迭代次数行内,因此即使在敏感性分析中减少了迭代次数的情况下也能保证模型的兼容性。 与多个公式方法类似,该计算过程可能耗时数秒,期间电子表格可能会出现短暂的未响应状态。因此对于复杂模型,最好先使用较少的迭代次数进行初步测试,此时计算几乎可以瞬时完成,便于快速验证模型逻辑。在完成蒙特卡洛模拟后,即可计算每次迭代治疗方案B相对于治疗方案A的增量成本与产出。最直观的方法是将治疗方案B组结果(m_B)中的各项数值减去治疗方案A组结果(m_A)的对应值,从而生成一张与迭代次数相同规模的增量结果表。然而,若在敏感性分析中减少迭代次数,m_A和m_B底部的部分单元格将成为空白格,导致增量结果表末尾出现多余的0值行。为避免此现象,应将计算范围严格限定在m_A与m_B的第一行(迭代次数)内。 若模拟过程使用的是单公式方法,计算迭代次数行的增量结果的方法非常简便:首先将名称m_A_与m_B_分别定义为m_A与m_B区域的左上角单元格;随后利用带有#溢出引用的公式即可生成相应的增量结果表:= m_B_# − m_A_#
但若模拟过程使用的是多公式法,由于其结果并非动态溢出区域,带有#号的引用在此方法中无效。此时可改用TAKE函数仅从m_A与m_B中读取迭代次数行的数据,同样能生成完全一致的增量结果表:= TAKE(m_B_1, iterations) − TAKE(m_A_1, iterations)
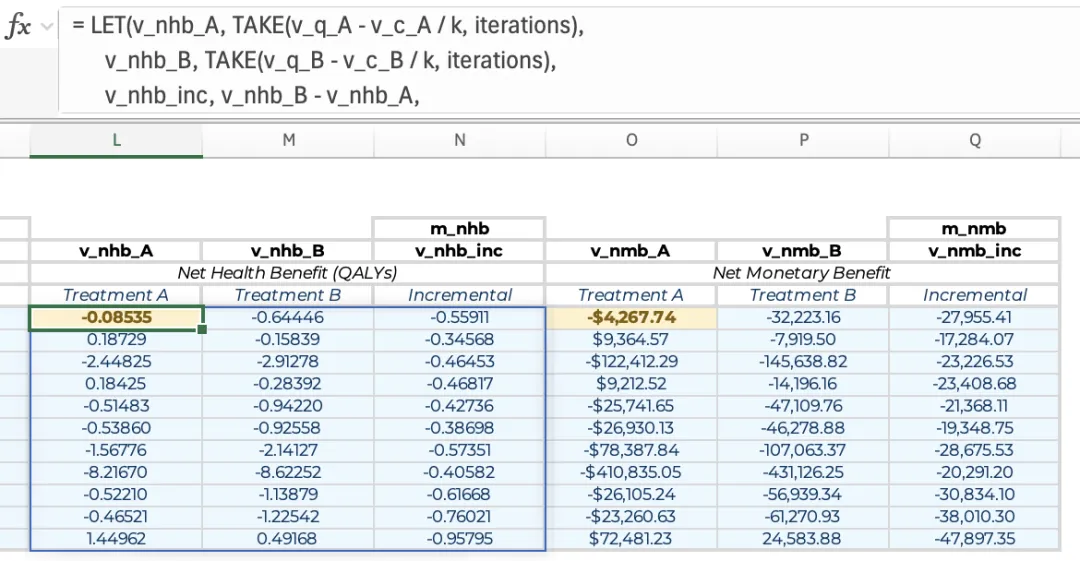
在每次迭代中,不仅可以计算出各治疗方案组的净健康获益(NHB)与净货币获益(NMB),还可以计算出对应的增量NHB与增量NMB。 首先需设定成本效果阈值。在本案例中将50000(每QALY50000美元的支付意愿)输入单元格并赋名“k”。接下来将m_A表中代表治疗方案A成本和QALY的列向量分别赋名为“v_c_A”与“v_q_A”;同理为治疗方案组B的相应列定义类似名称。此时输入以下公式即可生成治疗方案A的NHB列向量,每一行对应一次迭代的结果:= TAKE(v_q_A − v_c_A ∕ k, iterations)
在此公式的基础上,可以使用单个LET函数创建一个三列的结果表,分别对应两组治疗方案的NHB和增量NHB(若计算NMB,则将成本向量除以k更改为QALY向量乘以k):= LET(v_nhb_A, TAKE(v_q_A - v_c_A / k, iterations), v_nhb_B, TAKE(v_q_B - v_c_B / k, iterations), v_nhb_inc, v_nhb_B - v_nhb_A, HSTACK(v_nhb_A, v_nhb_B, v_nhb_inc))
此外,若需同时呈现NHB和NMB,建议先创建NHB表格,并将该公式所在的单元格命名为m_nhb_,随后即可使用以下公式便捷的生成NMB:= m_nhb_# ∗ k
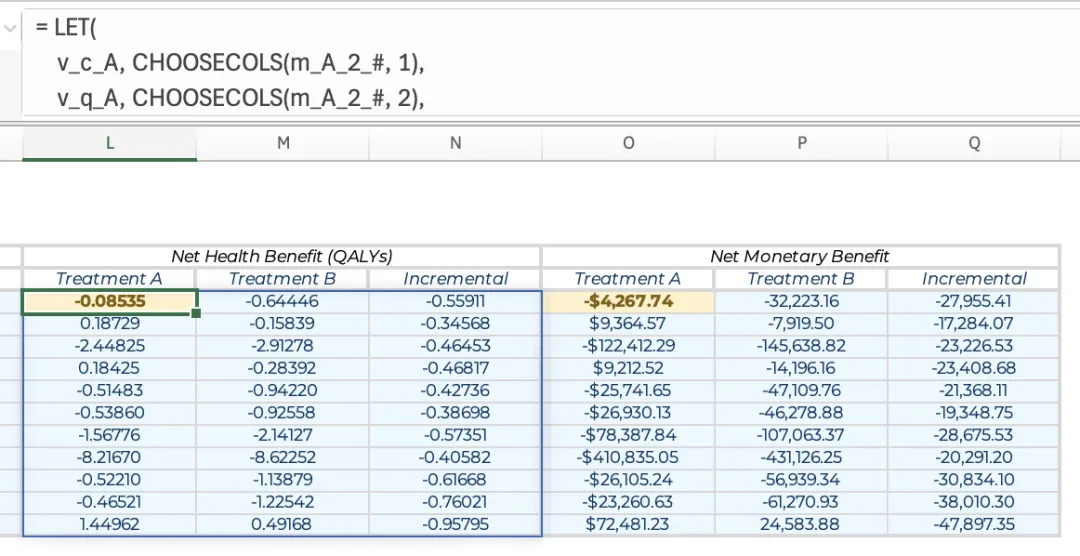
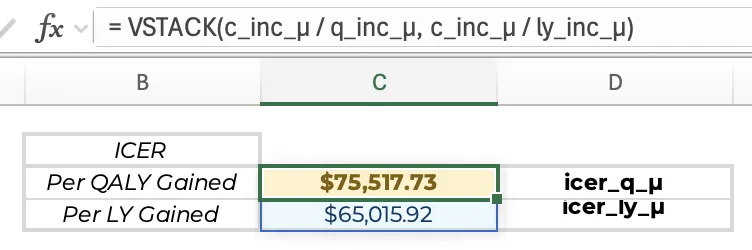
需要注意的是,若蒙特卡洛模拟使用的是单公式法,则可以直接通过#溢出引用从m_A与m_B中提取成本与QALY的列向量,无需再为这些向量单独定义名称:= LET(v_c_A, CHOOSECOLS(m_A_#, 1), v_q_A, CHOOSECOLS(m_A_#, 2), v_c_B, CHOOSECOLS(m_B_#, 1), v_q_B, CHOOSECOLS(m_B_#, 2), v_nhb_A, v_q_A - v_c_A / k, v_nhb_B, v_q_B - v_c_B / k, v_nhb_inc, v_nhb_B - v_nhb_A, HSTACK(v_nhb_A, v_nhb_B, v_nhb_inc))概率分析的核心环节在于估算各干预策略的期望成本与产出(即所有迭代次数的平均值)、期望增量结果,以及NHB和NMB的期望值。这些期望增量成本和产出随后可被用于计算增量成本效果比(ICER)。 基于上一节公式创建的五张结果表(每张表包含三列,行数与迭代次数一致,分别记录了治疗方案组A(m_A)、治疗方案组B(m_B)、增量结果(m_inc)、NHB结果(m_nhb)与NMB结果(m_nmb),将这些表格在行上对齐且横向相邻处理后,则可以使用单个公式计算这五张表的平均值。 将以下公式输入到表格上方或下方空白行首个单元格内,即可生成一个15列的期望结果行向量:= BYCOL(HSTACK(m_A, m_B, m_inc, m_nhb, m_nmb), AVERAGE) 该公式使用了BYCOL函数(与BYROW函数用法类似),通过HSTACK将五张表在内存中进行水平堆叠,进而计算堆叠表中每一列的平均值。 随后,将该行向量中分别对应期望增量成本、期望增量QALY与期望增量生命年的单元格赋名为“c_incμ”、“q_incμ”和“ly_inc_μ”,即可使用以下公式计算出ICER:= c_inc_μ ∕ q_inc_μ
同理,若需计算每一个生命年LY的ICER,只需将公式中的“q_inc_μ”替换为“ly_inc_μ”即可。在概率分析中,成本效益可接受曲线(Cost-Effectiveness Acceptability Curves,CEAC)是一种常见的产出形式,反映各干预策略在不同成本效果阈值下具有成本效益概率的曲线图。同时,通常还会绘制“成本效果可接受边界”(Cost-Effectiveness Acceptability Frontier,CEAF),展示了在每一阈值水平下,具有最高期望NHB或NMB的治疗方案组所对应的概率。传统生成CEAC和CEAF所需的概率表的方法通常繁琐且冗长,部分模型甚至需借助VBA宏来辅助完成。然而,通过现代Excel的动态数组函数,在此类双方案的模型中,仅需在单个单元格输入一个公式即可生成完整的概率表:= LET(v_λ, SEQUENCE(41, 1, 0, 5000), n, ROWS(v_λ), IF(switch3, LET(c_inc_μ, AVERAGE(v_c_inc), q_inc_μ, AVERAGE(v_q_inc), v_ceac_A, MAP(v_λ, LAMBDA(λ, SUM(--(v_q_inc * λ < v_c_inc)) / iterations)), v_ceac_B, 1 - v_ceac_A, v_ceaf, IF(q_inc_μ * v_λ - c_inc_μ < 0, v_ceac_A, v_ceac_B), HSTACK(v_λ, v_ceac_A, v_ceac_B, v_ceaf)), TAKE(m_ceac, n)))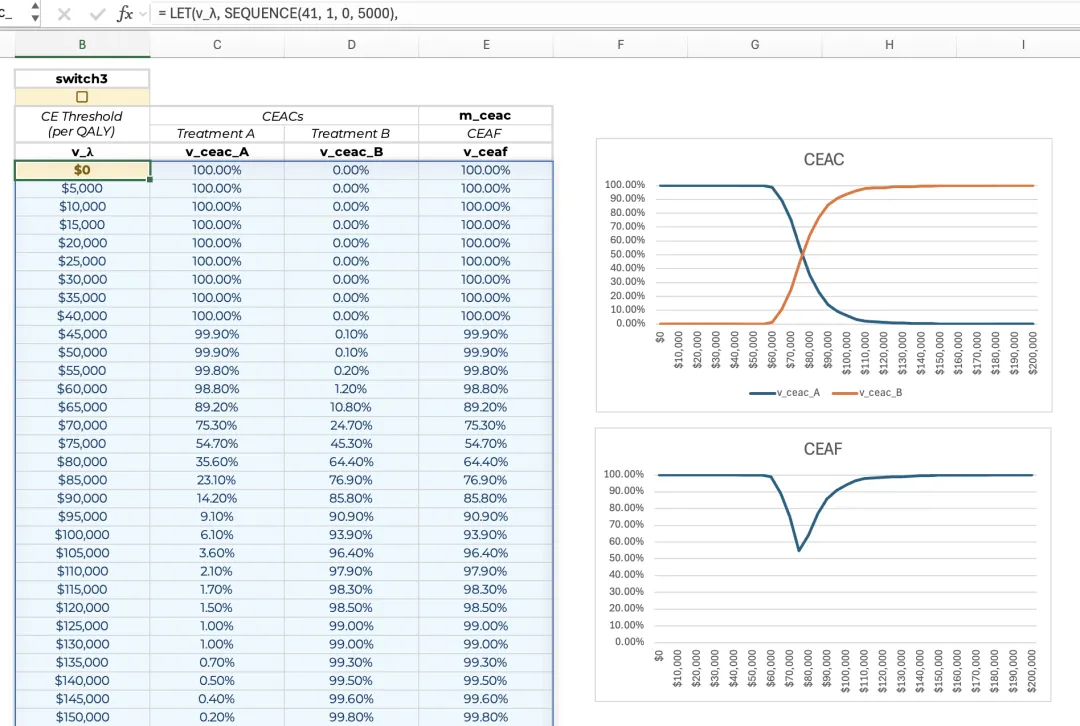
- 生成阈值向量: 首先,利用SEQUENCE函数创建阈值向量(v_λ),范围从$0到$200,000/QALY,步长为$5,000/QALY(v_λ, SEQUENCE(41, 1, 0, 5000))。
- 计数:随后,将v_λ中的阈值总数(本案例中为41个)存储在变量n中(n, ROWS(v_λ))。
- 计算开关: 引入新开关(“switch3”)以控制CEAC和CEAF的计算。这有助于避免不必要的重复计算:当开关关闭时不执行计算,而是直接从工作表中读取现有的结果表(“m_ceac”)(IF(switch3, ..., TAKE(m_ceac, n)))。
- 定义期望变量: 若开关开启则启动计算。首先定义所有迭代的平均增量成本(“c_inc_μ”)和平均增量QALY(“q_inc_μ”),即分别对“v_c_inc”和“v_q_inc”(增量成本和增量QALY的列向量)取平均值(c_inc_μ, AVERAGE(v_c_inc), q_inc_μ, AVERAGE(v_q_inc))。
- 计算治疗方案组A的CEAC概率: 利用MAP函数依次遍历v_λ中的每个值。对于内存中的当前阈值(“λ”),公式会判断每次迭代的增量NHB是否为负(若为负,则代表治疗方案组A在该次迭代中具有成本效益)。具体逻辑为:当v_q_inc * λ < v_c_inc成立时返回TRUE,否则返回FALSE。通过“--”算子将布尔值转换为1和0,再将其总和除以迭代次数,即可得到在当前阈值“λ”下治疗方案组A具有成本效益的概率向量(“v_ceac_A”)(v_ceac_A, MAP(v_λ, LAMBDA(λ, SUM(--(v_q_inc * λ < v_c_inc)) / iterations)))。
- 计算治疗方案组B的CEAC概率: 在双方案模型中,若治疗方案组A不具成本效益,则处理组B必然具有成本效益。因此,治疗方案组B的概率向量(“v_ceac_B”)可直接通过1 - v_ceac_A计算得出(v_ceac_B, 1 - v_ceac_A)。
- 计算CEAF概率: 接着计算CEAF的概率向量(“v_ceaf”)。表达式 q_incμ * vλ − c_inc_μ 利用所有迭代的平均增量值计算出各阈值下的期望增量NHB,返回一个41行的列向量。对于期望增量NHB为负的阈值点,CEAF取治疗方案组A对应的概率(“v_ceac_A”),否则取治疗方案组B的概率(“v_ceac_B”)(v_ceaf, IF(q_inc_μ * v_λ - c_inc_μ < 0, v_ceac_A, v_ceac_B))。
- 结果汇总: 最后,利用HSTACK函数将阈值、各组CEAC概率以及CEAF概率横向合并为最终结果表(HSTACK(v_λ, v_ceac_A, v_ceac_B, v_ceaf))。
此公式具有较强的通用性,可复用于任何双方案模型,且阈值序列可根据需求更新。若模型涉及两个以上的处理方案,则需采用不同的公式逻辑,此时需将各方案的NHB或NMB与所有方案的最大值进行比较来计算CEAC概率,并使用更复杂的函数替换IF逻辑以处理多方案间的比对。
Paulden, Mike. ‘A Modern Approach for Constructing Decision Analytic Models in Microsoft Excel’. PharmacoEconomics, ahead of print, 18 March 2026.