在最近的项目中,我们团队负责孵化一个”PPT生成智能体”。坦白讲,这可以说是我们整个系统里最复杂的一个 Agent。
为什么复杂?因为”一句话生成一份高质量 PPT”并不是调用一次大模型 API 就能搞定的。它是一个典型的长耗时、多阶段的复杂业务流。这个过程涉及到用户意图识别、需求澄清、联网检索、大纲生成、内容填充乃至配图和最终的渲染。通常来说,完整生成一份极具干货的 PPT 需要几分钟之久。
在项目初期,我们面临着两个极其棘手的灵魂拷问:
- 代码怎么写才不会变成”屎山”?多个阶段的逻辑完全不同,有的要查库,有的要调搜索,有的要调用文生图 API,如果全塞在一个 Service 里,代码将变得无法维护。
- 生成的过程中,用户把网页关了怎么办?网络断了怎么办?几分钟的等待期内,用户的任何中断行为都会导致前功尽弃,这对于一款商业级产品来说,体验是灾难性的。
为了解决这两个问题,我们最终采用了一套”状态机 + 策略模式 + 状态持久化”的架构方案。
一、整体架构
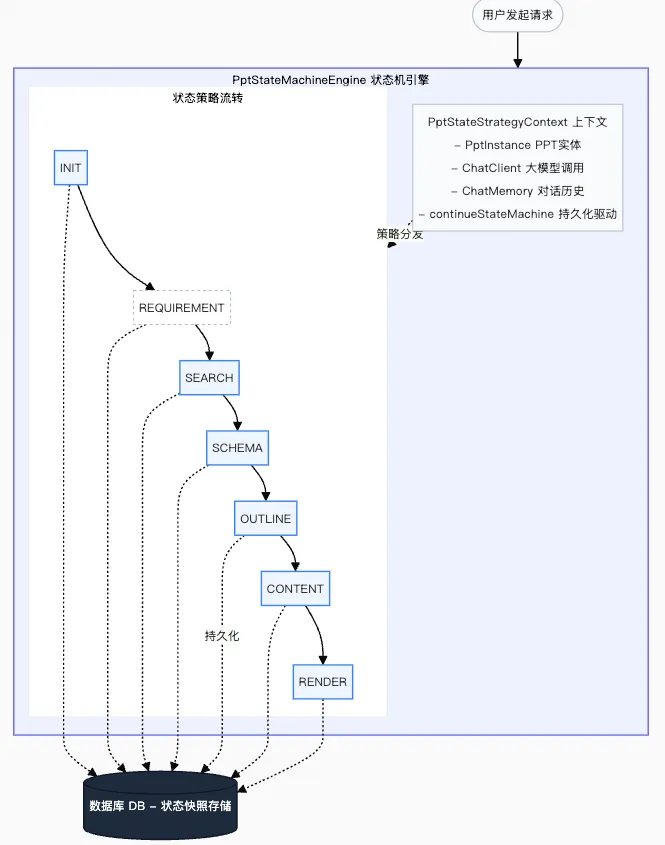
在动手写代码之前,先看整体架构。下图是这套系统的核心数据流:
每一个阶段(State)对应一个独立的 Strategy 类。状态机引擎负责加载上下文、分发任务、并在每个状态边界触发持久化。整个系统的核心设计哲学是:状态是唯一真相(Single Source of Truth),只要状态能恢复,任务就能恢复。
二、状态定义
首先,我们将整个 PPT 生成过程的各个阶段严格地抽象为若干个状态(State):
public enum PptState { INIT, // 初始状态:接收并解析用户初步意图 REQUIREMENT, // 需求澄清:信息不足时主动向用户追问 SEARCH, // 信息收集:联网检索,获取最新资料 SCHEMA, // 结构生成:搭建 PPT 整体章节骨架 OUTLINE, // 大纲生成:为每个章节生成详细大纲 CONTENT, // 内容填充:为每页生成文案,调用文生图配插图 RENDER, // 渲染生成:结构化数据转为真实 PPT 文件 SUCCESS, // 终态(成功) FAILED // 终态(失败)}
几个值得注意的设计决策:
- REQUIREMENT 是可选的:只有当 INIT 阶段判断用户输入信息不足时,才会流转到 REQUIREMENT。否则直接跳到 SEARCH。这意味着状态转换不是严格的线性序列,而是由每个 Strategy 自主决定”下一步去哪”。
- FAILED 是唯一的异常出口:任何阶段抛出的、不可重试的业务异常,都统一流转到 FAILED 状态,并在那里记录错误原因,方便前端展示和人工排查。
- SUCCESS/FAILED 是幂等终态:一旦进入终态,后续所有重复请求都应直接返回结果,不再重新执行。
三、策略模式实现
3.1 策略接口定义
我们为每一个状态都编写了一个独立的 Strategy 类。所有策略类统一实现同一个接口:
public interface PptStateStrategy { // 处理当前状态的核心逻辑,完成后调用 context.continueStateMachine(nextState) 推进 void process(PptStateStrategyContext context); // 声明本策略负责处理哪个状态,引擎据此自动路由 PptState getHandleState();}
3.2 策略的自动注册:让引擎与策略完全解耦
我们利用 Spring 的 IoC 容器,实现策略的自动注册,完全消除引擎对具体策略类的感知:
@Componentpublic class PptStateMachineEngine { private final Map<PptState, PptStateStrategy> strategyMap = new HashMap<>(); // Spring 启动时自动注入所有 Strategy Bean,按 getHandleState() 注册到 Map @Autowired public PptStateMachineEngine(List<PptStateStrategy> strategies) { for (PptStateStrategy strategy : strategies) { strategyMap.put(strategy.getHandleState(), strategy); } } public void dispatch(PptStateStrategyContext context) { PptState currentState = context.getPptInstance().getState(); PptStateStrategy strategy = strategyMap.get(currentState); if (strategy == null) { throw new IllegalStateException(“No strategy found for state: “ + currentState); } strategy.process(context); }}
这样的好处是:新增一个状态,只需新增一个 Strategy 类并打上 @Component 注解,引擎完全不需要改动。 完全符合开闭原则(OCP)。
3.3 一个具体策略的实现:以 RequirementStrategy 为例
下面是需求澄清阶段的策略实现,可以完整看到一个 Strategy 的标准写法:
@Componentpublic class RequirementStrategy implements PptStateStrategy { @Override public PptState getHandleState() { return PptState.REQUIREMENT; } @Override public void process(PptStateStrategyContext context) { PptInstance ppt = context.getPptInstance(); ChatClient chatClient = context.getChatClient(); ChatMemory chatMemory = context.getChatMemory(); // 1. 构建提示词:基于已有信息,询问大模型是否信息充足 String prompt = buildRequirementPrompt(ppt.getUserInput()); // 2. 调用大模型,获取结构化判断结果 RequirementCheckResult result = chatClient .prompt(prompt) .advisors(new MessageChatMemoryAdvisor(chatMemory)) .call() .entity(RequirementCheckResult.class); if (result.isInfoSufficient()) { // 3a. 信息充足 → 将补全后的需求写回 PPT 实例,直接推进到 SEARCH ppt.setRefinedRequirement(result.getRefinedRequirement()); context.continueStateMachine(PptState.SEARCH); } else { // 3b. 信息不足 → 将追问内容回传给用户,状态停留在 REQUIREMENT,等待用户答复 context.replyToUser(result.getFollowUpQuestion()); // 注意:此时不调用 continueStateMachine,状态机”暂停”,等待下一轮用户输入 } }}
注意这里的关键设计:Strategy 对”下一步去哪”有完全的自主权。当信息不足时,流程可以暂停并等待用户输入,这是普通线性流程无法实现的。
3.4 上下文对象:各阶段数据流转的”大脑”
各个阶段独立了,但上下文(Context)是连贯的。PptStateStrategyContext 承担了所有共享资源的托管:
@Datapublic class PptStateStrategyContext { private PptInstance pptInstance; // PPT 实体(含当前状态) private ChatClient chatClient; // 大模型调用入口 private ChatMemory chatMemory; // 对话历史(状态边界时序列化到 DB) private SseEmitter sseEmitter; // 向前端推送进度的通道 // 推动状态机向前:先持久化快照,再调用下一个 Strategy public void continueStateMachine(PptState nextState) { this.pptInstance.setState(nextState); PptStatePersistenceService.persist(this); StateMachineEngine.getInstance().dispatch(this); } // 向前端推送一条消息(追问、进度通知等) public void replyToUser(String message) { SseUtils.send(this.sseEmitter, message); }}
四、断点续传实现
4.1 核心思路:在状态边界打快照
断点续传的实现,水到渠成地建立在状态机设计之上。核心思路:在每个状态转换的边界,将完整快照(包括 PPT 数据 + 对话历史 + 当前状态标识)持久化到数据库。
这样,无论任务在哪个阶段中断,我们都能从数据库中精确恢复到上一个完成的状态节点,并从那里继续执行,不会重复消耗 Token。
4.2 保存什么,怎么保存?
在 continueStateMachine() 内部,持久化逻辑如下:
// PptStatePersistenceService.javapublic static void persist(PptStateStrategyContext context) { PptInstance ppt = context.getPptInstance(); // 1. 序列化对话历史 // ChatMemory 本身是内存对象,需要手动序列化为 JSON 存库 List<Message> messages = context.getChatMemory().get(ppt.getConversationId(), Integer.MAX_VALUE); String chatHistoryJson = JSON.toJSONString(messages); // 2. 构建持久化实体 PptTaskSnapshot snapshot = PptTaskSnapshot.builder() .conversationId(ppt.getConversationId()) .currentState(ppt.getState().name()) // 关键!记录当前状态 .pptData(JSON.toJSONString(ppt)) // 完整 PPT 数据 .chatHistory(chatHistoryJson) // 对话历史 .updatedAt(LocalDateTime.now()) .build(); // 3. 落库(upsert,有则更新,无则插入) pptTaskSnapshotRepository.upsert(snapshot);}
对应的数据库表设计(精简版):
CREATE TABLE ppt_task_snapshot ( conversation_id VARCHAR(64) PRIMARY KEY COMMENT '会话ID,业务唯一标识', current_state VARCHAR(32) NOT NULL COMMENT '当前状态枚举值', ppt_data LONGTEXT COMMENT 'PPT实例数据(JSON)', chat_history LONGTEXT COMMENT '对话历史(JSON)', updated_at DATETIME COMMENT '最后更新时间');
4.3 恢复流程
下面是完整的断点续传恢复逻辑:
// PptAgentService.java - 用户发起请求的入口public void handleUserRequest(String conversationId, String userMessage, SseEmitter emitter) { // 第一步:查询是否存在未完成的任务快照 Optional<PptTaskSnapshot> snapshot = pptTaskSnapshotRepository.findByConversationId(conversationId); PptStateStrategyContext context; if (snapshot.isPresent() && !isTerminal(snapshot.get().getCurrentState())) { // ====== 断点续传分支 ====== PptTaskSnapshot snap = snapshot.get(); // 1. 反序列化 PPT 实例 PptInstance ppt = JSON.parseObject(snap.getPptData(), PptInstance.class); // 2. 恢复对话历史(关键!大模型需要历史上下文才能”记起”之前的对话) List<Message> messages = JSON.parseArray(snap.getChatHistory(), Message.class); ChatMemory chatMemory = new InMemoryChatMemory(); chatMemory.add(conversationId, messages); // 3. 如果用户此次带着新消息进来(比如回答了追问),追加到历史 if (StringUtils.isNotBlank(userMessage)) { chatMemory.add(conversationId, new UserMessage(userMessage)); } // 4. 重新拼装 Context context = new PptStateStrategyContext(ppt, chatClient, chatMemory, emitter); log.info(“断点续传恢复成功,conversationId={}, 继续状态={}”, conversationId, ppt.getState()); } else { // ====== 全新任务分支 ====== PptInstance newPpt = PptInstance.create(conversationId, userMessage); ChatMemory chatMemory = new InMemoryChatMemory(); context = new PptStateStrategyContext(newPpt, chatClient, chatMemory, emitter); } // 第二步:启动状态机(异步执行,避免阻塞 HTTP 线程) asyncExecutor.execute(() -> stateMachineEngine.dispatch(context));}
4.4 前端如何配合后端
前端的核心逻辑非常简单,只需要做两件事:
- 使用 SSE(Server-Sent Events)接收流式进度:每个状态完成后,后端通过 SSE 推送一条进度消息,前端据此更新进度条(”正在搜索资料...” / “正在生成大纲...”)。
- 页面重新打开时,携带 conversationId 重新发起请求:前端将 conversationId 存储在 localStorage 中。用户下次进入时,直接用这个 ID 请求后端,后端会自动识别并执行断点续传。
// 前端伪代码async function startOrResumePptGeneration(userInput) { const conversationId = localStorage.getItem('pptConversationId') || generateUUID(); localStorage.setItem('pptConversationId', conversationId); const eventSource = new EventSource(`/api/ppt/generate?conversationId=${conversationId}&input=${userInput}`); eventSource.onmessage = (event) => { const data = JSON.parse(event.data); if (data.type === 'PROGRESS') { updateProgressBar(data.state, data.message); } else if (data.type === 'DONE') { showPptPreview(data.pptUrl); eventSource.close(); } else if (data.type === 'QUESTION') { // 需求澄清:展示追问弹窗,等待用户输入 showFollowUpDialog(data.question); } };}
五、踩坑记录
坑1:ChatMemory 序列化问题
Spring AI 的 Message 对象是接口,包含 UserMessage、AssistantMessage、SystemMessage 等多个子类型。直接 JSON.toJSONString(messages) 序列化没问题,但反序列化时 JSON.parseArray(json, Message.class) 会因为多态丢失子类型信息而失败。
💡 优雅解法序列化时在每条消息里带上类型标识,反序列化时手动按类型还原,或者使用 Jackson 的 @JsonTypeInfo 注解配置多态序列化策略。
坑2:并发重入问题
用户在任务进行中反复刷页面时,可能同时触发多个恢复请求,导致同一任务被并发执行两遍,产生重复的 Token 消耗和数据错乱。
💡 优雅解法在数据库层面对 conversation_id 加分布式锁(Redis SETNX 或数据库乐观锁),任务开始前先获取锁,任务完成或终止后释放锁。如果加锁失败,说明已有执行中的实例,直接返回”任务进行中”即可。
坑3:CONTENT 阶段耗时极长
CONTENT 阶段需要为每一页 PPT 分别调用大模型生成内容,如果是 20 页 PPT,就是 20 次串行 LLM 调用。这使得整体耗时急剧上升。
💡 优雅解法将 CONTENT 阶段内部改为并发执行(使用 CompletableFuture 或虚拟线程),多页内容同时生成。同时在 CONTENT 阶段内部也做细粒度的持久化(每完成一页就存库),避免中途中断导致已完成页面的 Token 浪费。
坑4:极端条件导致状态机”跑飞”
在测试中,曾出现状态机进入死循环的情况:某个 Strategy 在异常条件下既没有调用 continueStateMachine(),也没有流转到 FAILED,导致任务永久挂起。
💡 优雅解法在引擎的 dispatch() 方法中用整体 try-catch 兜底,所有未捕获的未卜异常都强制流转到 FAILED 状态。同时辅助加入超时检测的后台 Job,定期扫描 updated_at 超过阈值的未完成任务,主动标记为 FAILED 并触发告警。
六、为什么选自研而不是工作流引擎?
不少同学会问:为什么不用 Flowable、Camunda 这类成熟的工作流引擎?
| | |
|---|
| | |
| | 原生支持(Context 直接持有 ChatMemory) |
| | |
| | |
| | |
结论:工作流引擎是重型武器,为复杂的人工审批流而生。对于 AI Agent 这类以大模型调用为核心、需要动态分支、高度感知上下文的场景,自研轻量状态机更灵活、更易调试。
七、总结一下
把这套方案提炼成可以复用的工程经验,核心有以下几条:
- 复杂 AI 任务 = 状态机 + 策略模式,而非线性脚本。每个阶段独立成类,彼此不感知,通过 Context 传递数据。新增阶段只需新增类,完全符合 OCP。
- 状态边界是持久化的天然切点。不需要在业务逻辑中间插入持久化代码。状态转换就是快照时机,持久化逻辑集中在
continueStateMachine() 中,对各 Strategy 完全透明。 - ChatMemory 的序列化是 AI Agent 持久化的核心难点。不处理好对话历史的序列化/反序列化,模型恢复后就会”失忆”,上下文断裂,生成质量直线下降。
- 异步 + SSE 是长耗时 AI 任务的标配前后端交互模型。后端异步执行状态机,通过 SSE 流式推送进度,前端保存 conversationId 支持随时恢复。这套模式几乎适用于所有复杂 AI 生成任务。
- 最长阶段的内部并发化是性能优化的关键。
识别出耗时最长的阶段(如多页内容填充),将其内部改为并发执行,往往可以将整体耗时降低 50% 以上。AI Agent 的工程化,本质上就是”如何让不可控的大模型嵌入可控的工程系统”。