AI做PPT总翻车?这套带6道质检的开源框架,彻底终结排版灾难
- 2026-04-04 19:19:00
今天安装实测了一个流水线生产PPT的skill,通过6个独立阶段的严格校验,它可以生成一整套产物,包括PPT文件、HTML总体文件、html分页文件、截图文件。

PPT Agent skills,GitHub 搜索
sunbigfly/ppt-agent-skills即可找到。
AI 生成PPT的老问题
用过 AI 生成 PPT 的人,大概率遇到过这几类情况:
- 内容幻觉:
生成的数据、案例、引言看着像模像样,但仔细一查根本不存在 - 排版溢出:
文字跑到页面外面去了,或者图片和文字叠在一起 - 风格割裂:
第一页和第十页看起来像两个不同的人做的 - 无法编辑:
生成完发现某个细节要改,结果发现文件里的元素是合并的图片,改不了
根本原因在于,大多数 AI PPT 工具走的是"输入主题 → 一次性生成"的单步路线。速度快,但缺少质量把关环节——生成出来什么样,就是什么样了。
PPT Agent换了一种思路
PPT Agent V4 把"生成一份 PPT"拆成了 6 个独立阶段,每个阶段由专门的子代理(Subagent)执行,产物必须通过校验才能流转到下一阶段。
这套设计直接借鉴了软件工程中的 CI/CD 流水线——让每一页 PPT 的诞生,都经历一次"代码级"的质量把关。
先快速了解这个框架的全貌:
这篇文章适合谁
6 阶段流水线
P0 采访 → P1 分支确认 → P2A 联网检索 / P2B 本地资料压缩→ P3 叙事大纲 → P3.5 全局风格锁定→ P4 逐页并行生产 → P5 导出交付每个阶段的产物落盘后都经过 Gate 校验,只有校验通过才会进入下一阶段。某个步骤失败只回退当前步骤,不会影响其他已经完成的页面。
五大技术特点
1. Subagent 阶段隔离 — 每个环节专人专责
大多数 AI PPT 工具让一个大模型一口气完成所有工作:搜索素材、写内容、做排版、导出文件。问题是,模型在处理排版细节时,可能已经"忘"了前面搜索到的关键数据。
PPT Agent V4 把流程拆成 4 个独立子代理:Research(搜索)、Outline(大纲)、Style(风格)、Planning(规划)。每个子代理只做自己那部分,上下文严格隔离,互不污染。每个子代理创建时强制绑定指定模型,禁止走默认回退——避免模型降级导致内容质量滑坡。
2. 像素级 Visual QA 闭环 — 生成后自动质检
前面提到的"排版溢出"问题,大多数 AI PPT 工具的应对方式是调一下间距。但下一页可能又出同样的问题,治标不治本。
PPT Agent V4 的做法是:每页 HTML 生成后自动截图,交给大模型做视觉审计。发现布局溢出,子代理会直接重写 DOM 和 CSS 结构来消除根本原因。每页至少跑 2 轮检查,P0 和 P1 级缺陷全部清零后才放行。
3. 数据层与渲染层隔离 — 写入前拦截结构错误
PPT Agent V4 的每一页不会直接从素材跳到 HTML。中间多了一步:先生成一个 JSON 格式的结构化规划(类似"合同"),由 planning_validator.py 校验通过后,才进入 HTML 渲染。
这意味着内容结构上的错误(字段缺失、类型错误、资源引用不存在)在渲染之前就被拦截了,不会出现在最终成品里。
4. 无状态断点恢复 — 中断了不用从头来
生成一份 15 页的 PPT,中间如果对话超时了怎么办?
大多数 AI 工具的回答是:重新来。
PPT Agent V4 的回答是:从断点继续。
整个流程不依赖任何进度状态文件。运行中断后,系统通过扫描磁盘上已存在的产物文件自动推断恢复点:
扫描 delivery-manifest.json → 已完成 Step 5,直接交付扫描 slide-N.png → Step 4 部分完成,只重跑缺失页扫描 style.json → Step 3.5 完成,从 Step 4 继续扫描 outline.txt → Step 3 完成,从 Step 3.5 继续完全基于文件系统的事实判断,即使对话上下文丢失也不影响任务续跑。
5. 双引擎 PPTX 导出 — 兼顾视觉效果和可编辑性
导出阶段提供两套管线并行运行:
- PNG 光栅流:
将每页 HTML 截图为高清图片后嵌入 PPTX,保证在任何平台上打开视觉效果 100% 一致,所见即所得 - SVG 矢量流:
保留字体和矢量信息,生成的 PPTX 中元素可以独立编辑、替换文字、调整颜色
需要直接演示就用 PNG 版,需要后续微调就用 SVG 版。
完整产物链
interview-qa.txt → requirements-interview.txt → search-brief.txt | source-brief.txt → outline.txt → style.json → planningN.json → slide-N.html → slide-N.png → preview.html → presentation-{png,svg}.pptx从需求采集到最终交付,每一步都有可追溯的中间产物。
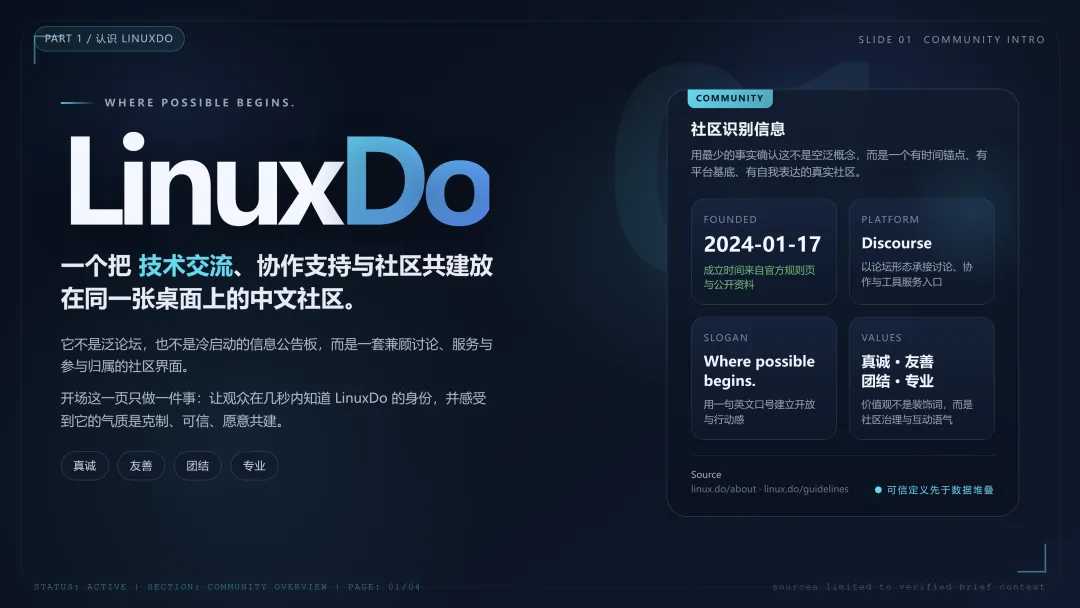
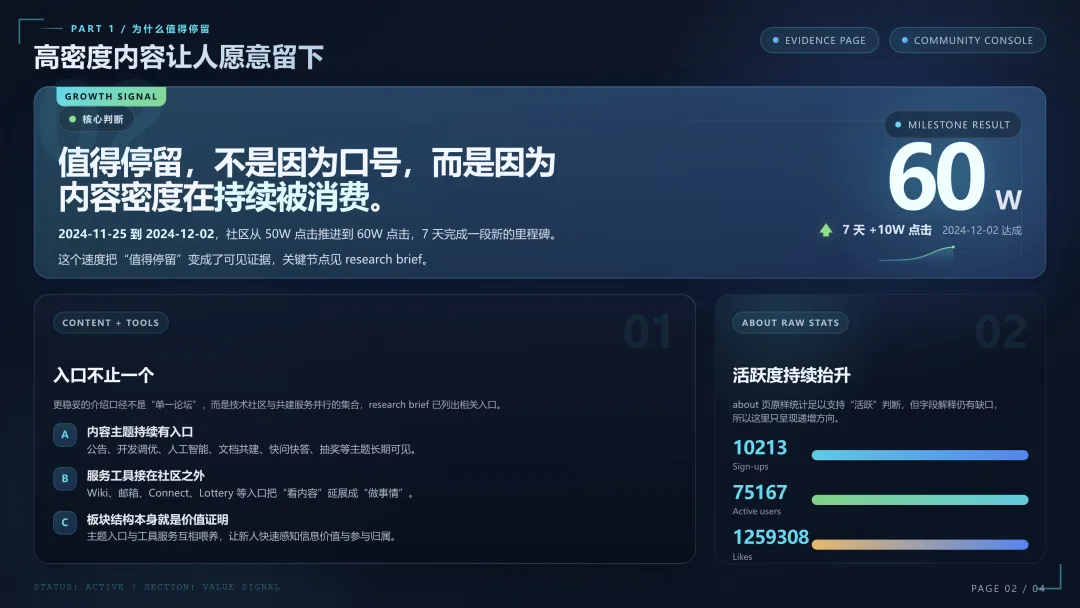
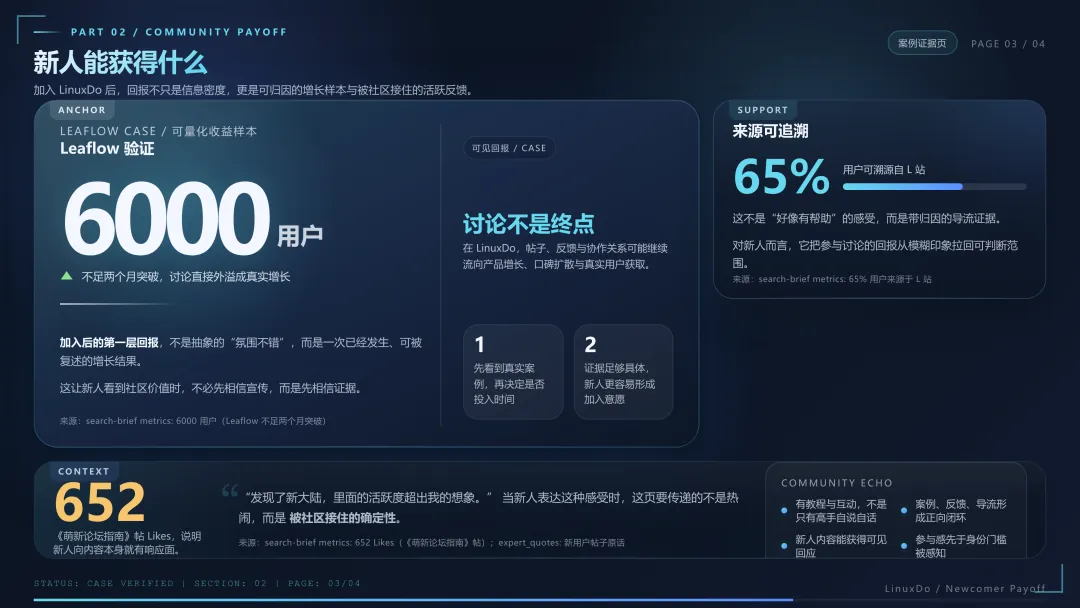
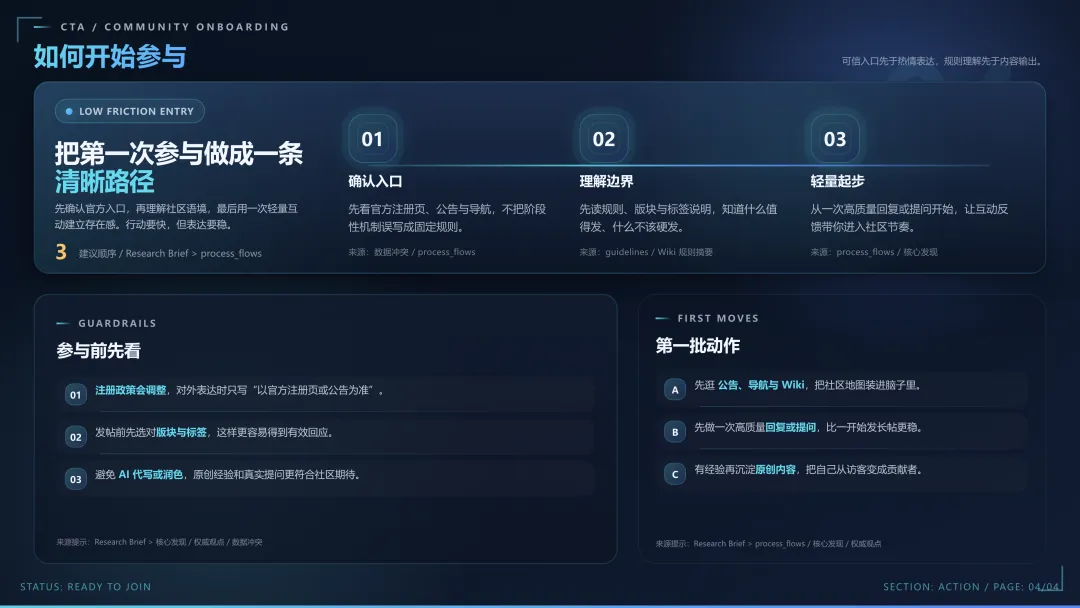


项目资源
资源文件按需挂载——每个阶段的子代理只加载当前步骤需要的知识源,不会一次性灌入过多信息导致注意力分散。
安装方式
PPT Agent V4 以 Agent Skill 形式运行,无需独立部署服务器。在支持 Skill 的代理环境(如 Claude Code、WorkBuddy 等)中执行:
npx skills add sunbigfly/ppt-agent-skills环境依赖
- Python 3:
运行校验和导出脚本 - Node.js:
用于 npx skills add安装 - puppeteer:
HTML 截图(PNG 流)所需的 Chromium 内核 - python-pptx + lxml + Pillow:
PPTX 导出所需的 Python 库
所有依赖在首次运行时按需安装即可。
实际使用体验
安装完成后,直接用自然语言告诉它你要做什么:
"帮我生成一份关于 2026 年具身智能发展趋势的 15 页路演 Deck,暗色科技风格。"
接下来你会经历以下流程:
Step 0 — 需求采访
系统会通过结构化问答跟你确认几个关键信息:演示场景(路演 / 汇报 / 培训)、目标受众、期望页数和风格倾向、是否有品牌规范需要遵循、配图策略(AI 生成 / 素材库 / 手动补充)。回答完毕后,所有信息归一化为一份结构化需求文档,作为后续所有阶段的统一输入。
Step 1 — 分支确认
系统会问你一个关键问题:内容从哪来?
- 联网检索:
系统自动搜索最新资料,适合行业报告、趋势分析类主题。根据主题复杂度执行 2-4 轮搜索,每轮搜索后自评覆盖率,素材充裕则提前终止 - 本地资料:
直接丢你的文档或 PPT 进去,系统自动压缩提炼,适合产品介绍、方案汇报类主题。甚至可以直接丢一个已有的 .pptx文件,系统会先问你期望的处理模式(仅美化排版 / 彻底重构 / 美化并重构)
Step 2 — 素材准备
选择联网检索的话,系统自动执行多轮搜索并输出结构化的素材简报(search-brief.txt),包含专为 PPT 设计的独立数据包(指标、对标、时间线等至少 3 种数据类型)。
选择本地资料的话,系统将你提供的文档/数据降维整合为统一的素材简报(source-brief.txt)。
Step 3 — 大纲构建
独立的 Outline 子代理基于素材生成叙事大纲。这个子代理内部自带"编写 → 自审 → 修复"的闭环——它在内部反复打磨,只有通过自审的大纲才会输出给主流程。
Step 3.5 — 风格锁定
独立的 Style 子代理根据需求和大纲确定全局视觉风格,输出一份精确的 style.json:配色、字体、间距、装饰元素等所有视觉参数全部锁定。后续所有页面统一按这份风格文件执行。
Step 4 — 逐页生产
这是核心环节。每页幻灯片由独立的 PageAgent 处理,各页并行推进,互不阻塞。每个 PageAgent 内部分三个阶段渐进式推进:
- Planning:
生成该页的结构化规划 JSON(必须通过 planning_validator.py校验) - HTML:
根据规划生成完整的 HTML 页面 - Visual QA:
截图 → 视觉审计 → 发现问题则重写 DOM/CSS → 再截图验证(保底 2 轮,P0+P1 清零才放行)
Step 5 — 导出交付
生成网页预览(preview.html),同时导出两版 PPTX:
presentation-png.pptx:光栅版,跨平台视觉一致 presentation-svg.pptx:矢量版,元素可编辑
所有产物统一输出到 ppt-output/runs/<RUN_ID>/ 目录。
往期文章:
把一段话变成一张白板信息图:这个AI Skill让我告别了PPT
AI做PPT的真正门槛,不是模型,是提示词(附skill+教程)
我用NotebookLM生成PPT后,才发现之前全都白做了(附提示词)
这个开源项目把"做PPT"拆成了10步,每一步都能停下来确认
我用了一个开源PPT技能后,决定再也不打开PowerPoint了
(这些是目前最火爆的PPT热门skill)
项目地址
- GitHub:
https://github.com/sunbigfly/ppt-agent-skills - 协议:
MIT(可自由使用、修改、分发) - 安装:
npx skills add sunbigfly/ppt-agent-skills

