Excel函数实战系列 第11期
Excel函数实战系列 第11期
Excel函数实战系列 第11期
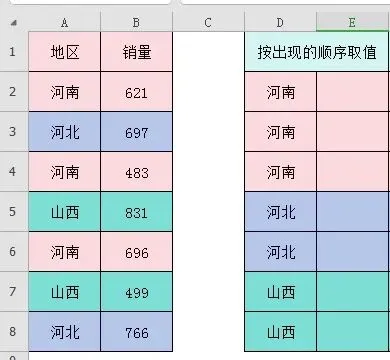
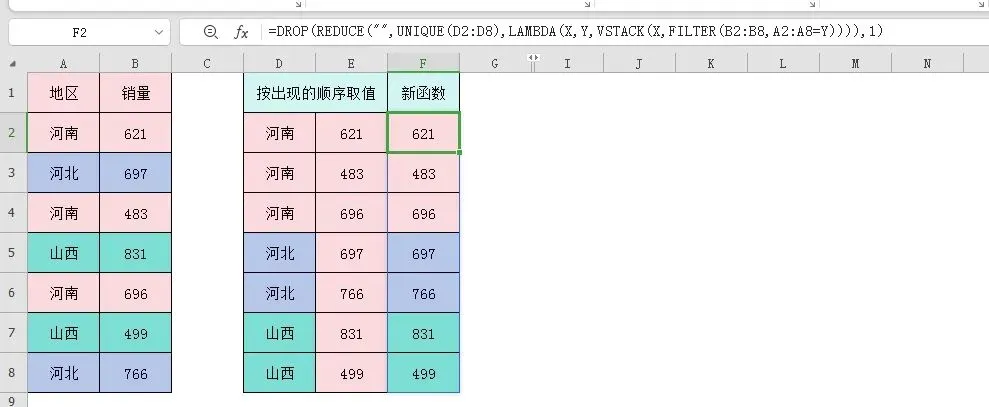
小伙伴们,今天继续我们的函数实战系列,今天我们更新到第11期。上次我们分享了一对多查找IF+SMALL+INDEX这个经典查找套路。有小伙伴又遇到工作中的实际问题,问题描述如下:猛一看,这不就是我们刚说过的一对多查找吗!但是用我们上次说过的IF+SMALL+INDEX套路写好公式后,下拉,前3个还正常运行,但是到第4个单元格就出现问题了。问题出现了,我们要分析问题产生的原因,找出问题的症结所在,然后解决他。今天我们就来具体看看为什么会出错,然后提供2个解决这个问题的办法。第一种还是一对多查找IF+SMALL+INDEX。这个套路在这里还是可以运用的,错误出现在SMALL的第2个参数K上面。我们在下拉的时候,前3个河南是没有问题的,就是找到河南的第1,2,3个所在的行号,但是第4个就有问题了。到第4个是河北,这时候我们需要的就不是4了,是河北第1次出现的行号,直接拉是4,所以就会出现问题。解决问题的办法也很简单,就是随着公式的下拉,第一次出现得到1,第二次出现得到2...=INDEX(B:B,SMALL(IF($A$2:$A$8=D2,ROW($2:$8),4^8),COUNTIF($D$2:D2,D2)))关键就是COUNTIF($D$2:D2,D2),COUNTIF的第1个参数条件区域$D$2:D2,第一个D2单元格的地址是绝对引用,第2个单元格地址是相对引用,随着公式的下拉,条件区域不断的变化,从而得到第一次出现得到1,第二次出现得到2...,就可以完美解决这个问题。第二种是用到365新函数,我是真的很喜欢新函数,解决问题太方便了。=DROP(REDUCE("",UNIQUE(D2:D8),LAMBDA(X,Y,VSTACK(X,FILTER(B2:B8,A2:A8=Y)))),1)UNIQUE(D2:D8)得出条件的不重复值{"河南";"河北";"山西"}。用REDUCE函数循环得到的不重复值,用FILTER函数筛选不重复值里面的每一个地区,然后用VSTACK函数纵向拼接。得到的结果,第一行是空值,最后用DROP函数把第1行删除,完美解决问题。好了,这2个公式嵌套都不算复杂,很简单,希望小伙伴们能熟练掌握函数的嵌套运用,具体运用到工作中来解决实际的工作需要!
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。