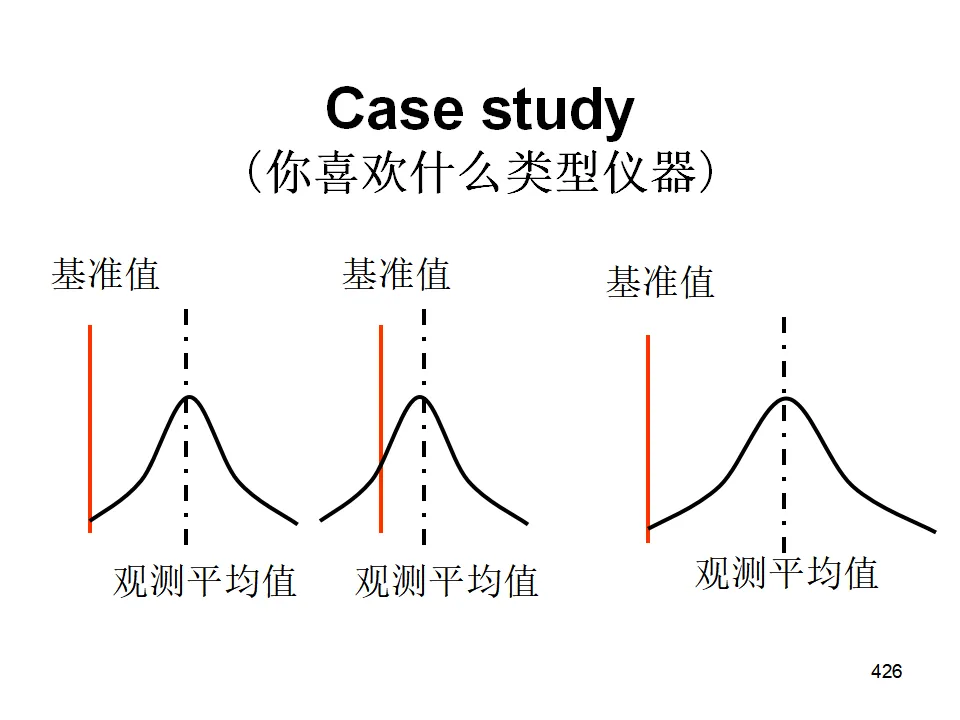
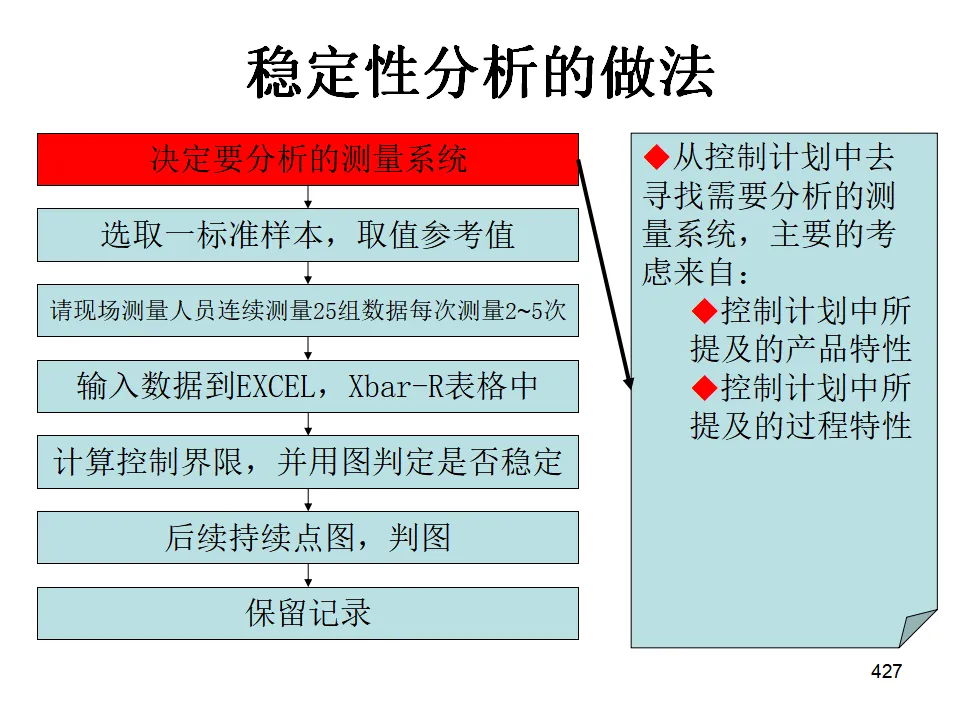
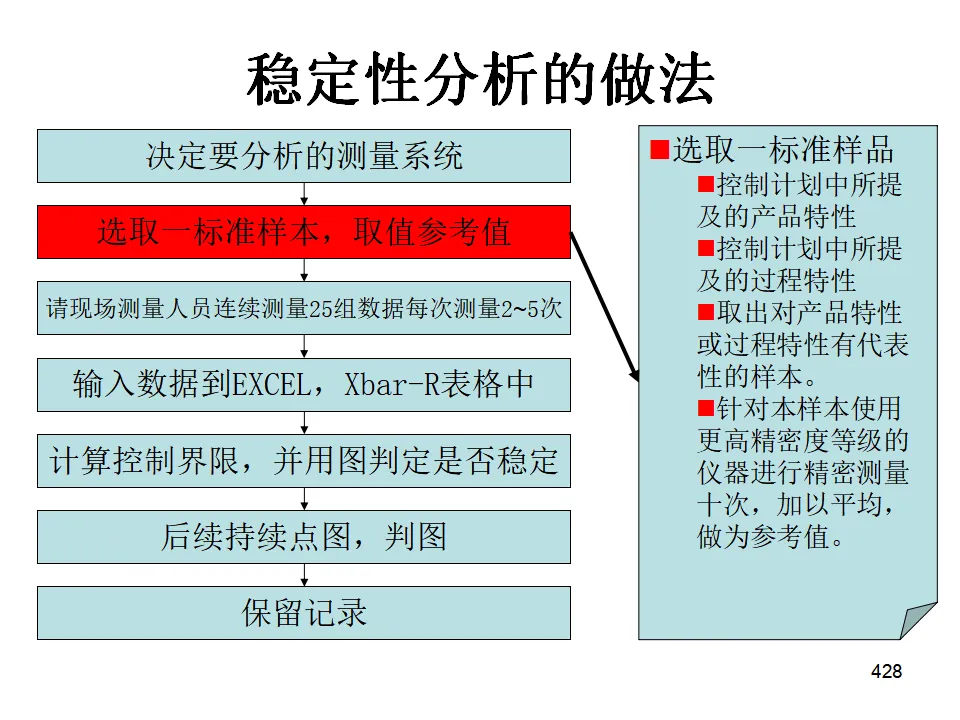
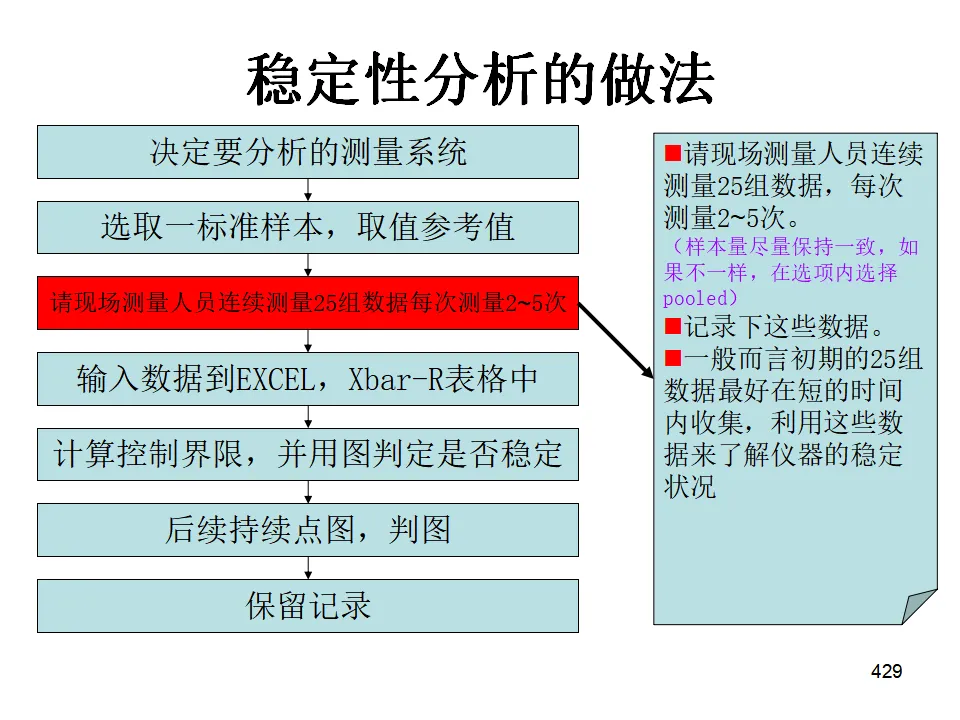
Minitab全面培训教程500多页ppt
Minitab全面培训教程500多页ppt
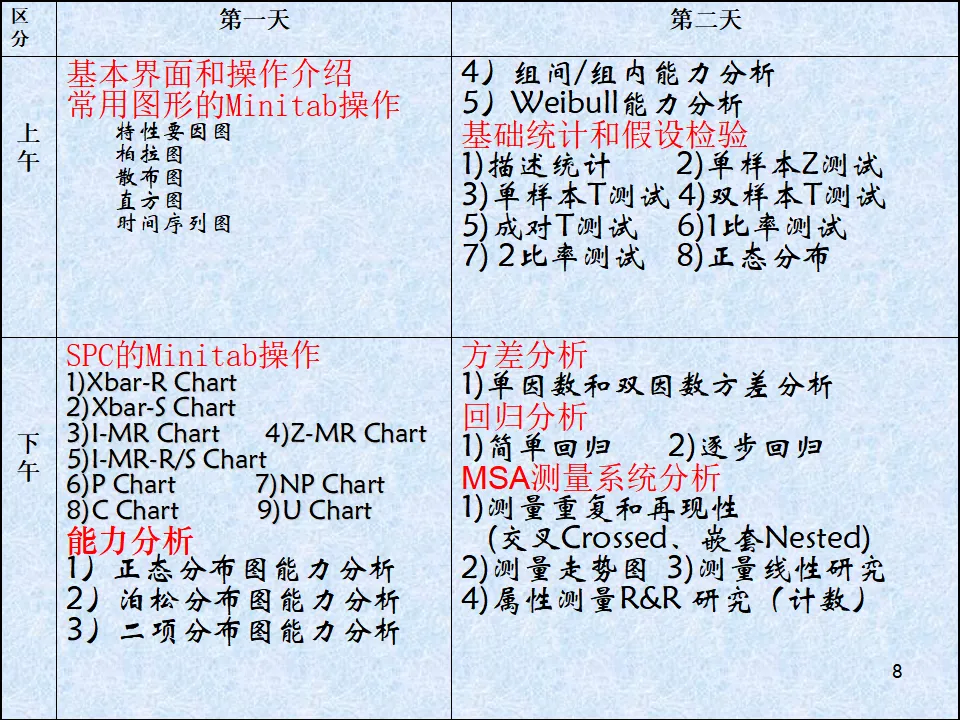
Minitab是一款在质量管理领域广受认可的统计分析软件。它的核心价值在于将复杂的统计方法简化为直观的操作界面,让不具备深厚统计学背景的管理人员和质量工程师也能轻松运用先进的统计工具解决实际问题。相比其他统计软件如SPSS或SAS,Minitab的优势在于其简洁易懂的操作逻辑。软件的设计理念是让用户专注于分析结果的质量意义,而非陷入繁琐的编程或数学推导。在质量管理实践中,我们经常需要快速响应产线问题、分析质量数据、验证改善效果,Minitab正是为满足这种高效率、高质量的分析需求而生。Minitab与六西格玛管理的渊源可以追溯到上世纪80年代。当时Motorola公司在推行六西格玛变革时,发现需要一个强大的统计工具来支撑MAIC(测量-分析-改善-控制)各阶段的分析工作。Minitab凭借其强大的计算能力和友好的界面,成为了六西格玛实施的首选工具。在六西格玛项目的各个阶段,Minitab都发挥着关键作用:- 测量阶段(Measure):通过描述性统计、正态性检验、过程能力分析,帮助我们准确测量当前过程的表现基线。
- 分析阶段(Analyze):运用假设检验、方差分析、回归分析等工具,识别关键影响因素,验证根因假设。
- 改善阶段(Improve):通过试验设计(DOE)优化工艺参数组合,找到最佳设定点。
- 控制阶段(Control):建立控制图监控体系,确保改善成果得以维持。
即使您不熟悉复杂的统计公式,只要掌握了Minitab的操作逻辑,同样能够完成专业的六西格玛分析工作。这大大降低了统计分析的门槛,让更多业务人员能够基于数据做出科学决策。Minitab的功能体系可以分为三大支柱:计算功能、数据分析功能和图形分析功能。- 计算器功能:提供基础的数学运算和统计函数计算,支持自定义公式运算。
- 生成数据功能:可以基于特定分布(如正态分布、泊松分布等)生成随机数据,用于模拟分析或教学演示。
- 概率分布功能:涵盖各种离散型和连续型概率分布的计算,包括概率密度函数、累积分布函数和逆累积分布函数。
- 矩阵运算:支持矩阵的加法、乘法、转置、求逆等线性代数运算,为高级统计分析提供基础。
- 基础统计:描述性统计、正态性检验、假设检验(Z检验、t检验、比例检验、方差检验等)。
- 回归分析:简单线性回归、多元线性回归、逐步回归、非线性回归等,用于建立变量间的预测模型。
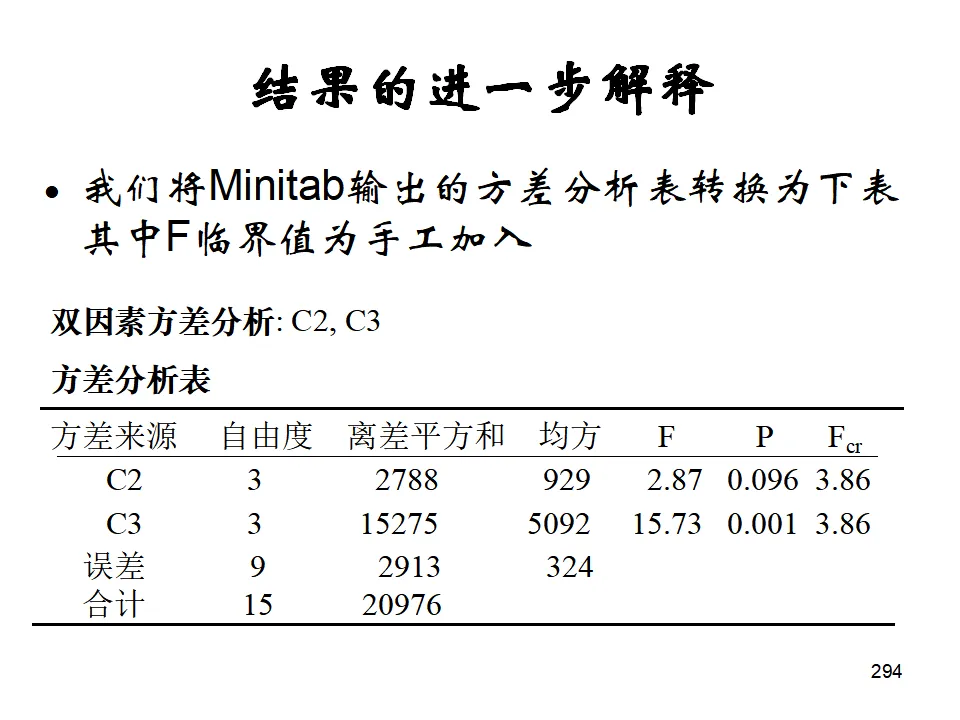
- 方差分析(ANOVA):单因素、双因素、多因素方差分析,用于比较多个总体均值差异。
- 实验设计分析(DOE):全因子设计、部分因子设计、响应曲面设计等,用于工艺优化。
- 控制图:计量型控制图(Xbar-R、Xbar-S、I-MR等)和计数型控制图(P图、NP图、C图、U图等)。
- 质量工具:柏拉图、特性要因图(鱼骨图)、散布图等QC七大手法工具。
- 时间序列分析:趋势分析、季节分解、ARIMA模型等。
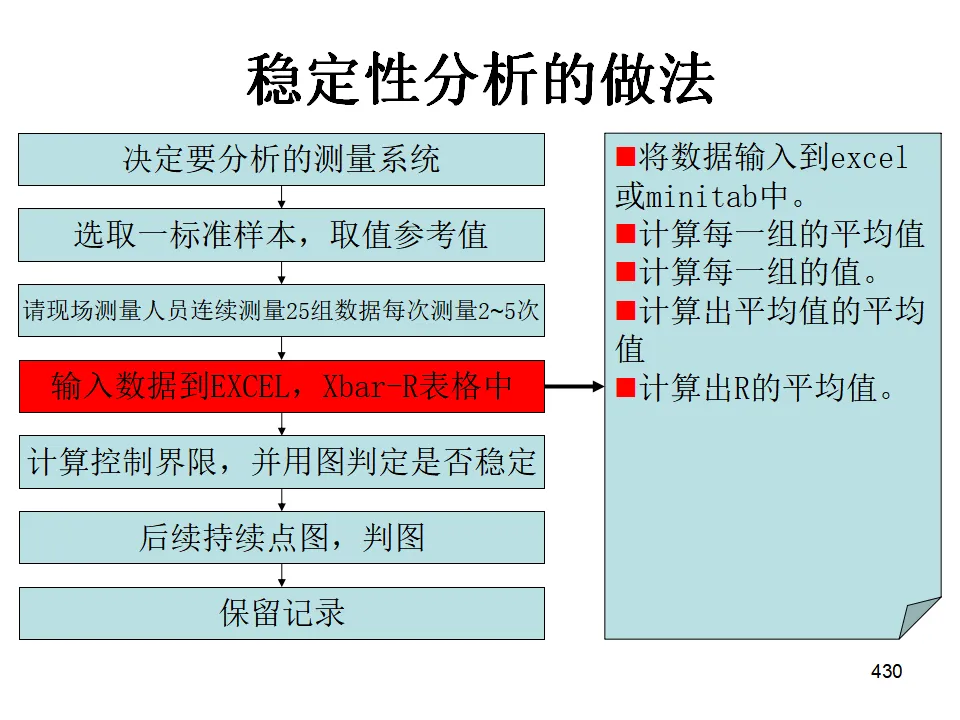
- 测量系统分析(MSA):Gage R&R研究、偏倚分析、线性分析、属性一致性分析等。
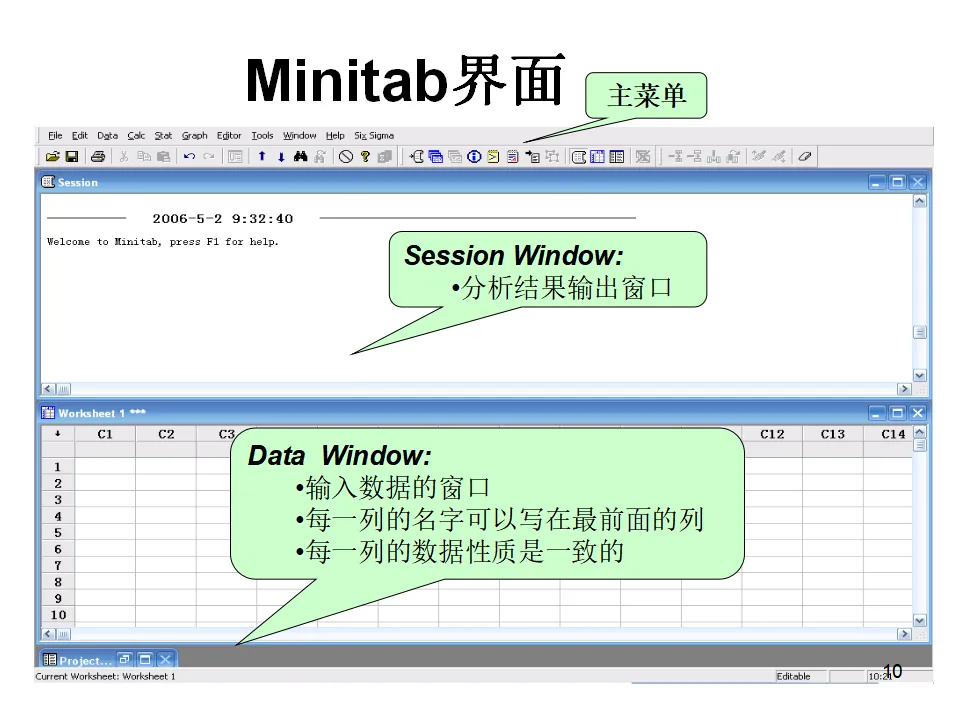
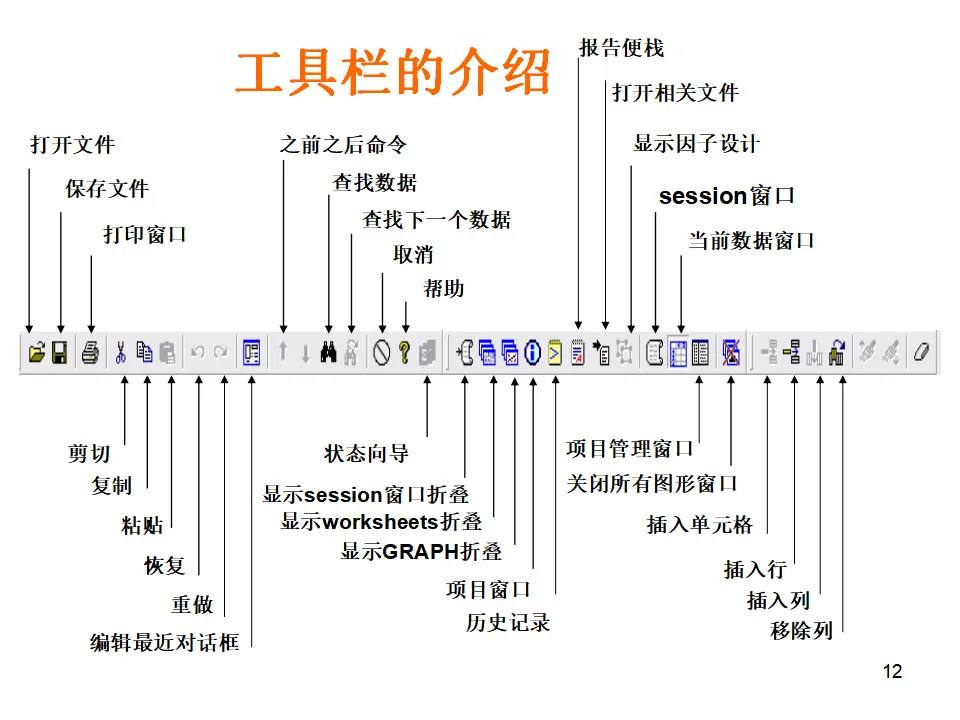
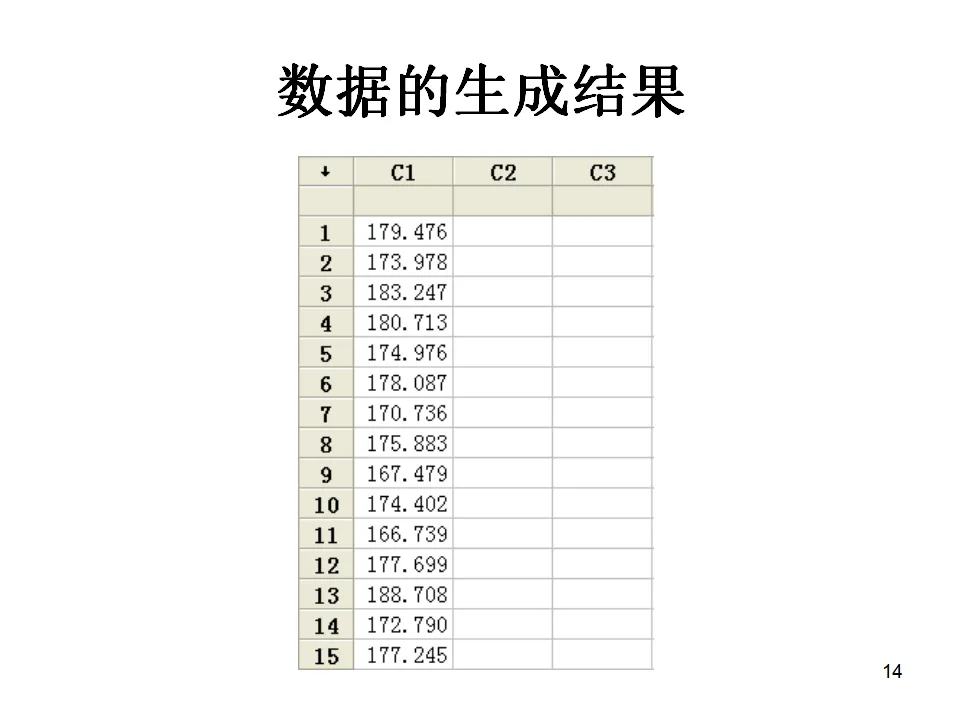
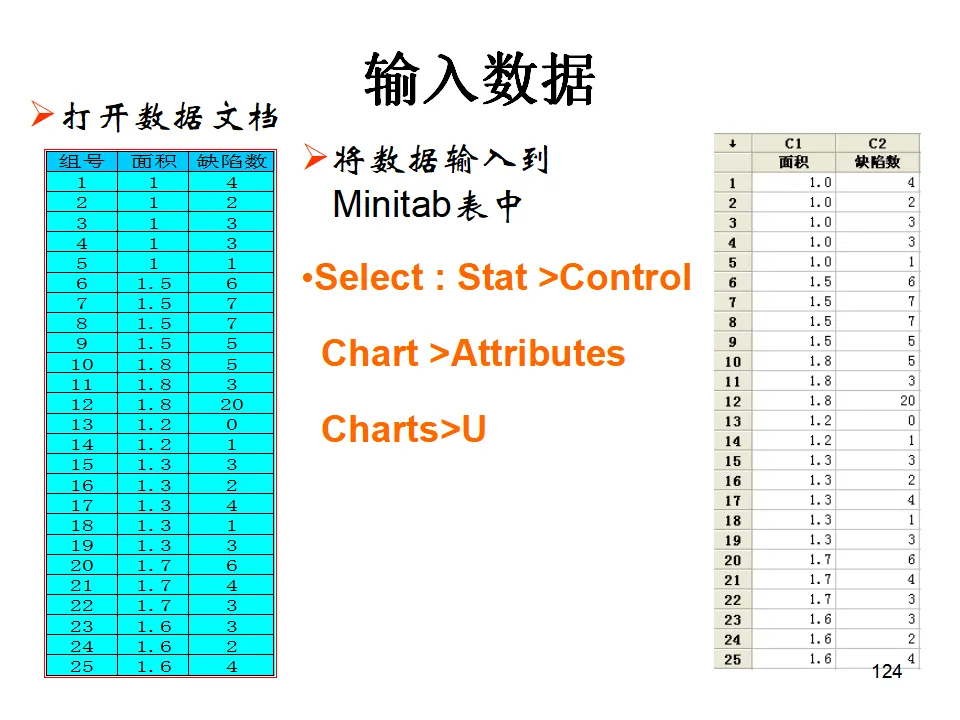
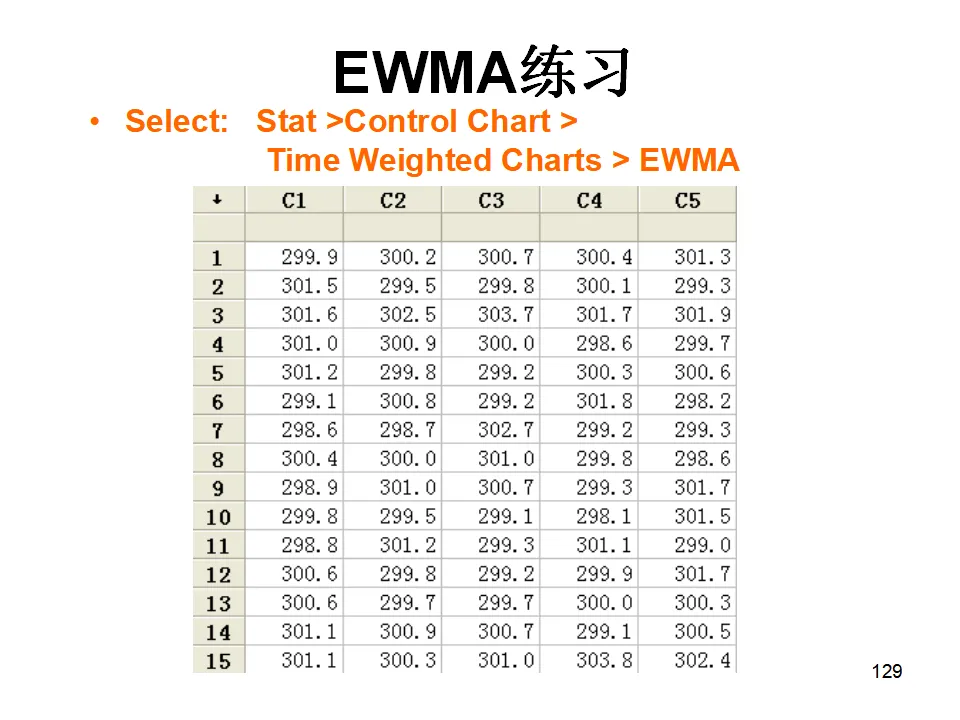
Minitab提供了丰富的图形工具,包括直方图、散布图、时间序列图、条形图、箱线图、矩阵图、轮廓图、三维图、点图、饼图、边际图、概率图、茎叶图、特征图等。这些图形不仅美观,更重要的是与统计分析深度集成,能够自动根据分析结果生成相应的诊断图形。当您第一次打开Minitab,会看到几个核心窗口:Session窗口(会话窗口):这是分析结果的输出窗口。所有的统计输出、检验结果、模型摘要都会在这里以文本形式呈现。您可以将Session窗口的内容保存为报告,或者复制到Word中进行进一步编辑。Data窗口(数据窗口):这是输入和编辑数据的电子表格界面。每一列代表一个变量,列名写在最上方的单元格。Minitab要求每一列的数据性质必须一致——要么全是数值型,要么全是文本型,要么全是日期型。这种结构化的数据组织方式是确保分析准确性的基础。主菜单栏:包含File(文件)、Edit(编辑)、Data(数据)、Calc(计算)、Stat(统计)、Graph(图形)、Editor(编辑器)、Window(窗口)、Help(帮助)等菜单,涵盖了软件的全部功能。工具栏:提供了常用功能的快捷按钮,如打开文件、保存、打印、剪切复制粘贴、撤销重做、查找数据等。特别值得注意的是"显示Session窗口"、"显示Graph窗口"和"显示Worksheets折叠"等视图控制按钮,它们帮助您在多窗口间快速切换。项目管理窗口:Minitab支持多工作表管理,您可以在一个项目中包含多个工作表(Worksheet),每个工作表可以独立保存,也可以整体保存为一个项目文件(.mpj格式)。在统计学习和方法验证中,我们经常需要生成符合特定分布的随机数据。Minitab提供了强大的随机数据生成功能。假设我们需要生成一组男生身高的模拟数据,要求平均身高为175cm,标准差为5cm,样本量100个。操作路径为:Calc > Random Data > Normal。- 生成数据的行数(Number of rows of data to generate):输入100
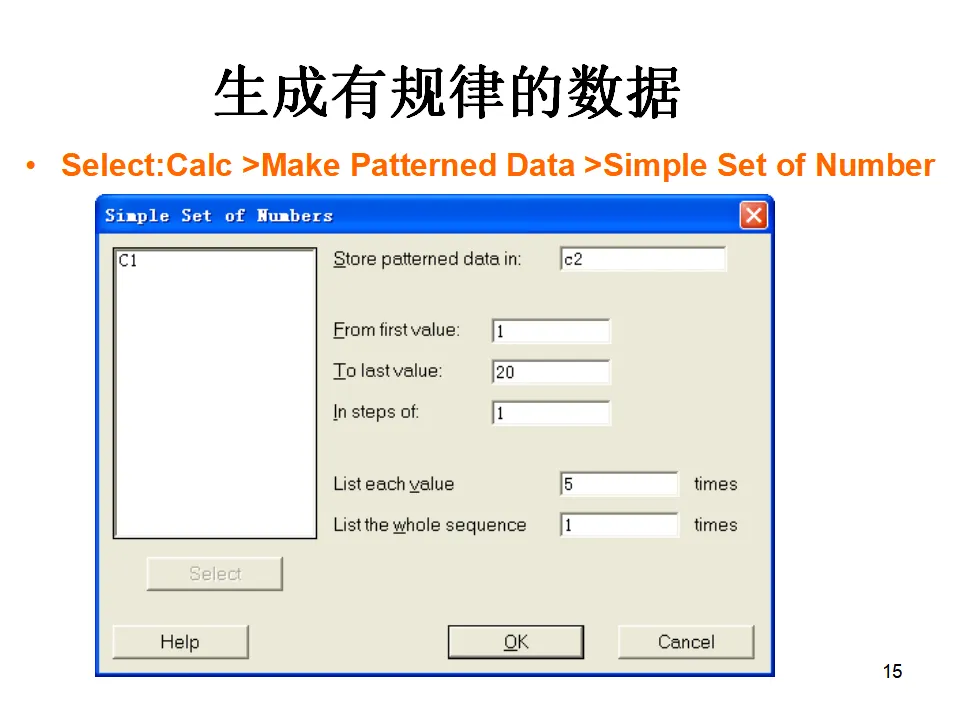
- 存储位置(Store in column):可以输入一个新的列名,如C1,或者给列起一个有意义的名字如"身高"
- 标准差(Standard deviation):输入5
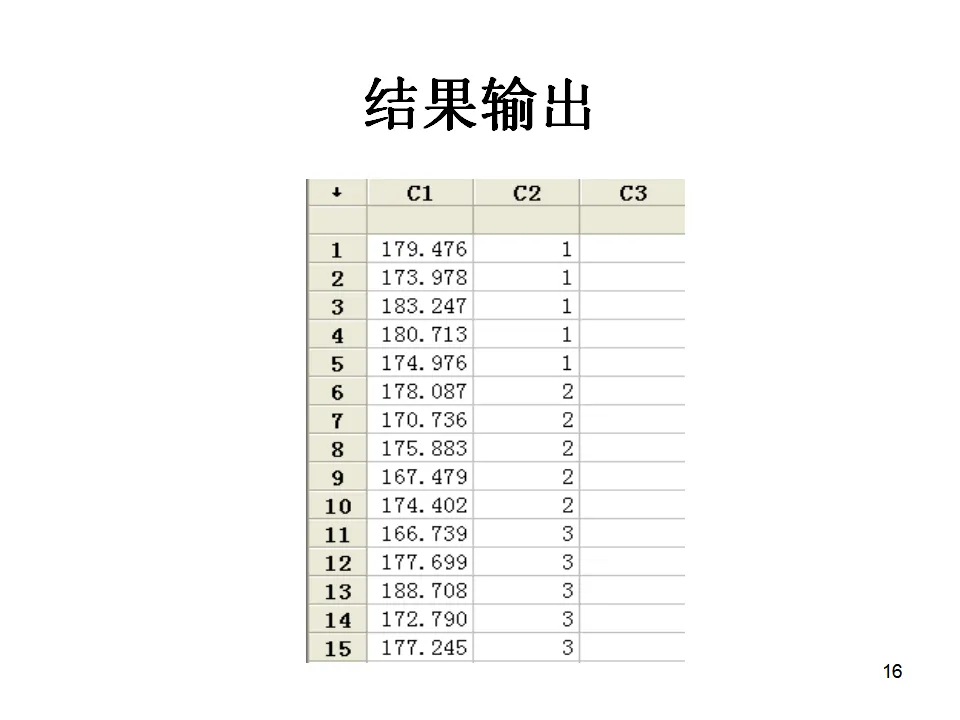
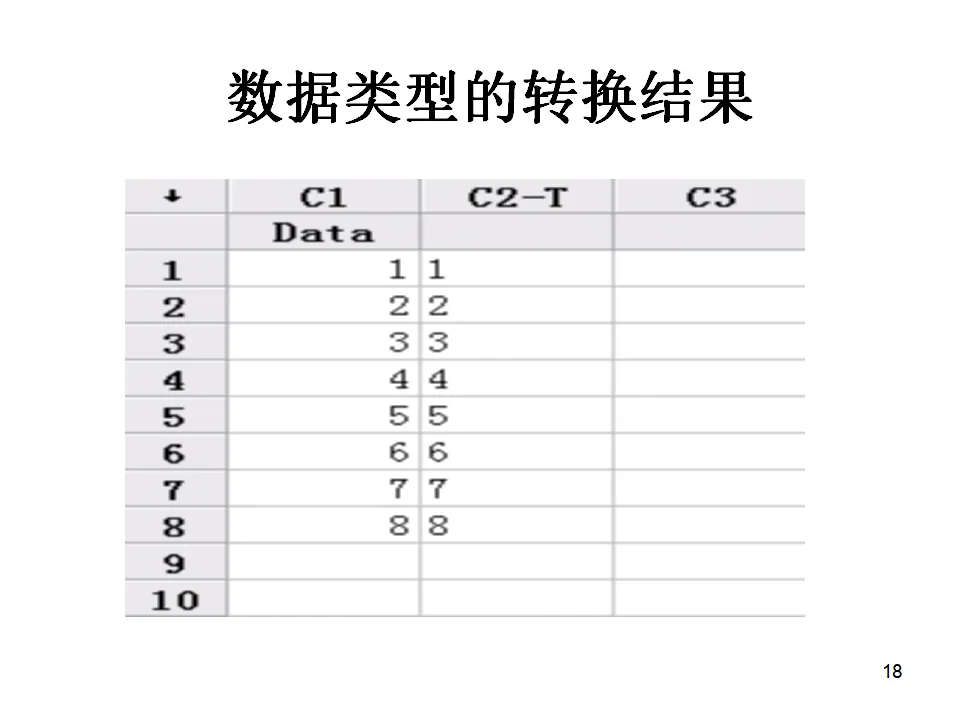
点击OK后,Minitab会在指定列生成100个符合N(175, 25)分布的随机数据。这些数据可以用于后续的直方图绘制、正态性检验或假设检验练习。除了随机数据,有时我们需要生成有规律的序列数据,如序号、等差数列等。这时使用Calc > Make Patterned Data > Simple Set of Number功能。例如,要生成1到100的序号,或者重复某种模式的数据,都可以在对话框中设置起始值、终止值、步长等参数。这在创建实验设计的因素水平、时间序列的时间轴等场景中非常有用。实际工作中,数据类型不一致是常见问题。比如从ERP系统导出的数据,数字可能被识别为文本格式,这会影响后续的统计分析。Minitab提供了灵活的数据类型转换功能。路径为:Data > Change Data Type。您可以将:- 数值转换为文本(Numeric to Text):适用于需要将数字作为类别标签处理的场景
- 文本转换为数值(Text to Numeric):这是更常见的需求,比如将"123"转换为可进行计算的数值123
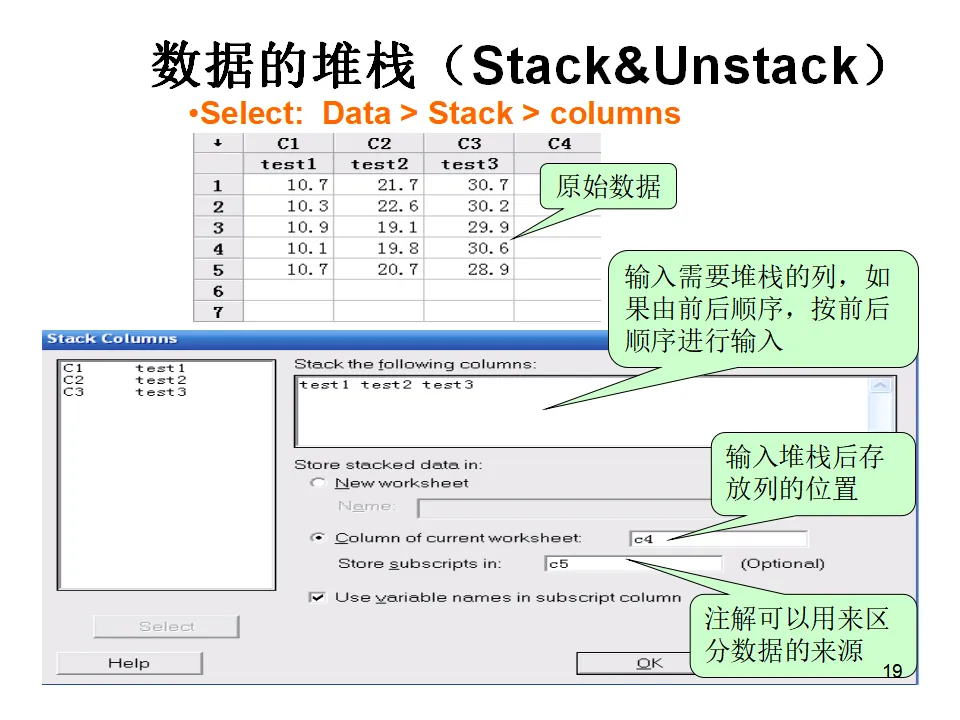
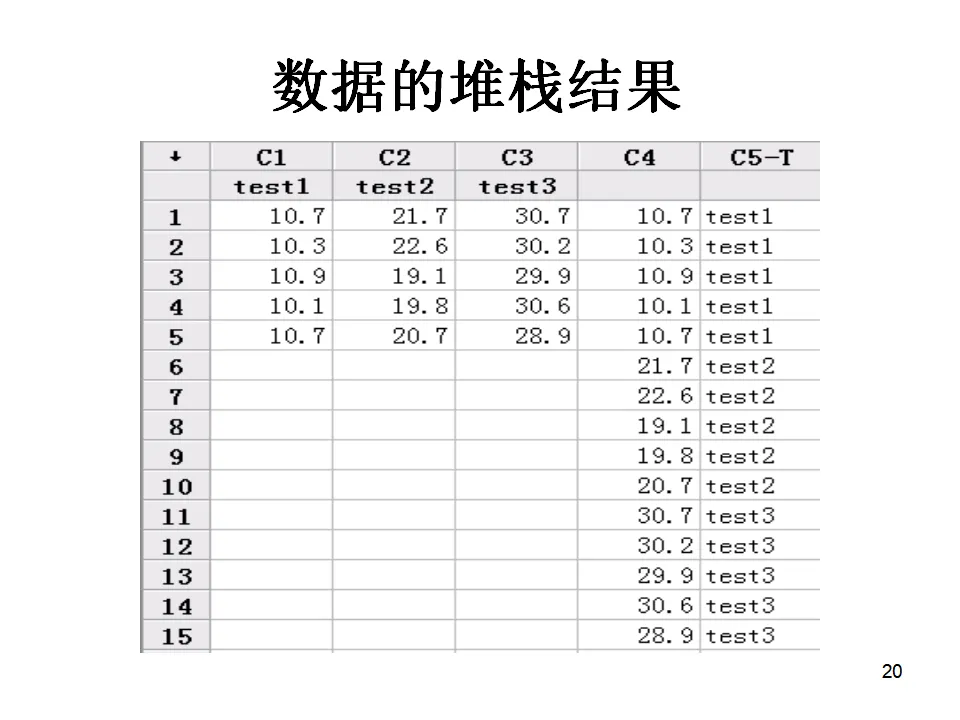
转换时需要注意,如果文本中包含非数字字符(如逗号、货币符号),转换可能会产生缺失值,需要先用Calc > Calculator配合文本函数进行清洗。在数据录入和组织中,我们经常会遇到数据格式不匹配的情况。堆栈(Stack)和解堆栈(Unstack)是解决这类问题的利器。假设您有四组不同批次的产品测量数据,分别存储在C1、C2、C3、C4四列中。为了进行方差分析,您需要将这些数据转换为一列数值和一列组别标签的两列格式。操作路径:Data > Stack > Columns。选择需要堆栈的列(C1-C4),指定存储结果的列(如C5),并选择是否在下标列中存储原始列的标识( Subgroup ID)。执行后,C5将包含所有数据,C6将包含对应的组别标签(如1,2,3,4或原始列名)。当数据以更复杂的块结构存在时,比如多列数据需要同时堆栈,使用Stack Blocks of Columns功能。这适用于重复测量数据的重整,比如将多天的测量数据合并为一个连续的时间序列。有时候需要将行变列、列变行,这在处理某些特殊格式的报表时很有用。Data > Transpose Columns功能可以实现这种转换。注意转置后变量名可能需要重新定义。如果您需要合并文本数据,比如将"产品编号"列和"批次号"列合并为"产品批次"列,使用Data > Concatenate功能。可以指定分隔符(如"-"或"_"),生成格式统一的新标识符。数据清洗中经常需要重新编码。比如将年龄分组编码为"青年"、"中年"、"老年",或将分数转换为等级评定。Data > Code功能支持数值到文本、文本到文本、数值到数值等多种编码方式,是数据预处理的重要工具。特性要因图是质量管理中用于识别问题根本原因的经典工具。它通过人、机、料、法、环、测(5M1E)六大类因素,系统地梳理可能的原因。假设我们在分析焊接不良率高的原因,现场调查收集到以下信息:将这些信息整理成表格形式,每一行代表一个原因类别,每一列是具体的原因描述。然后,执行Stat > Quality Tools > Cause-and-Effect。在对话框中:- 在"Effect"(效应)框中输入要解决的问题,如"焊接不良率高"
- 在"Categories"(类别)中指定人、机、料、法、环、测等大类
Minitab生成的特性要因图采用经典的鱼骨结构,主骨指向问题(鱼头),大骨代表六大类别,中骨和小骨分别展开次级原因和具体细节。这种可视化方式帮助团队系统性地思考,避免遗漏重要因素,同时也为后续的柏拉图分析提供了原因清单。柏拉图基于帕累托法则(80/20法则),帮助我们识别"关键的少数"因素。在质量改善中,它告诉我们应该优先解决哪些问题才能带来最大的效果提升。数据准备时,需要包含不良项目、不良数、不良率,Minitab会自动计算累计不良率。操作路径:Stat > Quality Tools > Pareto Chart。在对话框中:- 可以合并剩余项目(Combine remaining defects into one category)
生成的柏拉图包含两个纵轴:左侧是频数或百分比,右侧是累计百分比。柱状图按不良率从高到低排列,折线图显示累计百分比。从图中可以清晰看到,前3-4项不良就占了累计不良率的绝大部分,这就是我们需要优先改善的重点。散布图用于研究两个连续变量之间的相关关系。在质量分析中,常用于分析工艺参数与质量特性的关系,或两个质量特性间的关联。假设我们有以下数据,X代表加热温度(摄氏度),Y代表产品强度(MPa):将数据输入Minitab后,执行Graph > Scatterplot。在对话框中,Y变量选择强度,X变量选择温度。- 正相关:点呈从左下到右上的趋势,说明温度升高强度增加
从图形可以初步判断相关性,更精确的分析需要通过Stat > Regression进行回归分析,计算相关系数R和判定系数R²。直方图是了解数据分布形态的基础工具。它将连续数据分组,显示各组的频数分布,帮助我们判断数据是否服从正态分布,过程是否居中,变异范围如何。某零件重量规格要求为60.2克至62.6克,我们收集了120个样本的重量数据(15组,每组8个)。操作路径:Graph > Histogram。可以选择简单直方图,或带拟合曲线的直方图。- 在对话框中点击"Labels"或"Options"
- 形状:是否对称(正态),是否有多峰(不同批次混合),是否有偏斜(设备磨损或操作习惯)
- 与规格的关系:是否有数据超出规格线(不合格品),两侧是否有余量(过程能力)
结合直方图,我们可以进一步计算均值(Mean)和标准差(StDev),为后续的过程能力分析(Cp、Cpk计算)提供基础。时间序列图用于观察数据随时间变化的趋势,是SPC控制图的基础,也是趋势分析和预测的前提。某产品2006年1-9月的销售量数据:1月150件,2月126件,3月135件,...,9月176件。操作路径:Graph > Time Series Plot。选择销售量作为变量,时间作为时间轴标签。在质量控制中,时间序列图是监控过程稳定性的第一步。如果图中显示明显的趋势或周期,说明过程可能受到特殊原因影响,需要进一步分析。控制图是现代质量管理的基石,由休哈特(Walter Shewhart)博士于1924年创立。其核心思想基于产品质量的统计观点:首先,产品质量具有变异性。无论多么精密的设备、多么熟练的操作员,生产出的产品都不可能完全相同。这种变异是客观存在的,公差制度的建立正是承认这种变异的合理性。其次,产品质量的变异具有统计规律性。当我们对同一特性进行连续测量,只要样本量足够大,数据就会呈现正态分布(钟形曲线)的规律。这种规律性是统计控制的数学基础。控制图采用均值±3σ作为控制界限。在正态分布下,数据落在[μ-3σ, μ+3σ]区间内的概率为99.73%,落在区间外的概率仅为0.27%(约千分之三)。这意味着,如果过程处于稳定状态(受控),点出界是小概率事件;如果点出界发生了,我们有理由认为过程出现了异常(特殊原因)。控制图实质上是区分偶然因素(偶波)和异常因素(异波)的科学界限。偶波是过程固有的随机波动,不可避免但影响微小;异波是可查明的外部干扰,对质量影响大但可以通过措施消除。Minitab提供了丰富的控制图类型,主要分为计量型和计数型两大类。- Xbar-R图:均值-极差控制图,最常用,适用于子组容量n≤10的场合,用极差R估计变异。
- Xbar-S图:均值-标准差控制图,适用于n≥10或要求更高精度的场合,用标准差S估计变异。
- I-MR图:单值-移动极差图,适用于无法分组的情况(如每班只测一个样本,或破坏性检测)。
- I-MR-R/S图:适用于组间和组内变异的复杂情况,如多夹具、多 cavity 的模具。
- Z-MR图:标准化单值移动极差图,用于短流程或小批量生产,当过程数据不足以很好评估参数时使用。
- P图:不合格品率控制图,适用于样本量不固定的情况,监控比例变化。
- NP图:不合格品数控制图,适用于样本量固定的情况,直接监控不合格品数量。
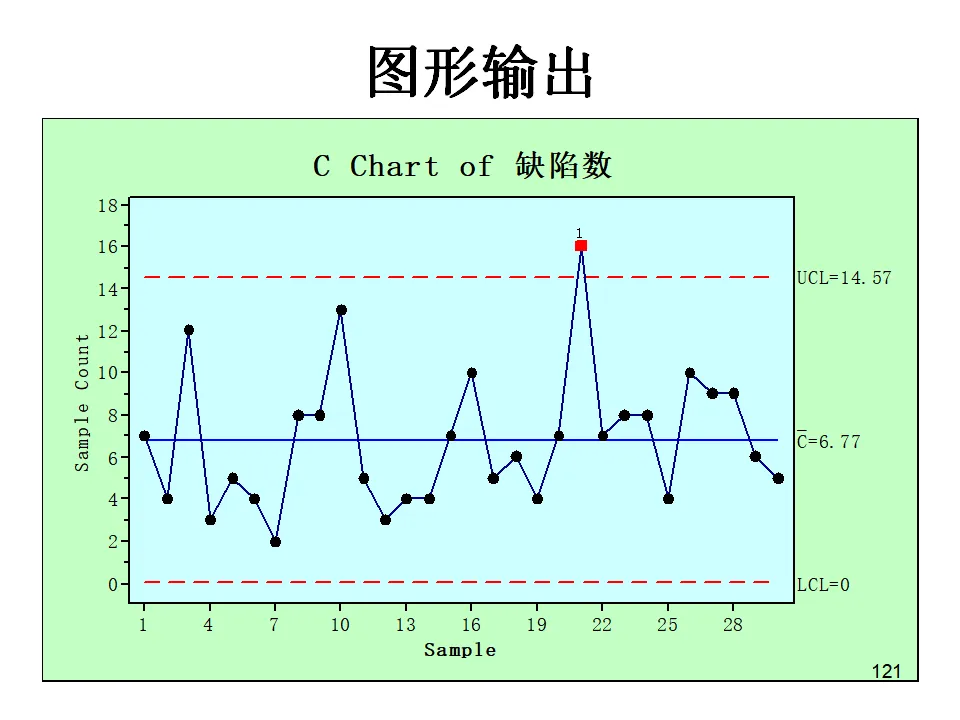
- C图:缺陷数控制图,适用于样本量固定,监控单位缺陷数(如每卷产品的瑕疵点数)。
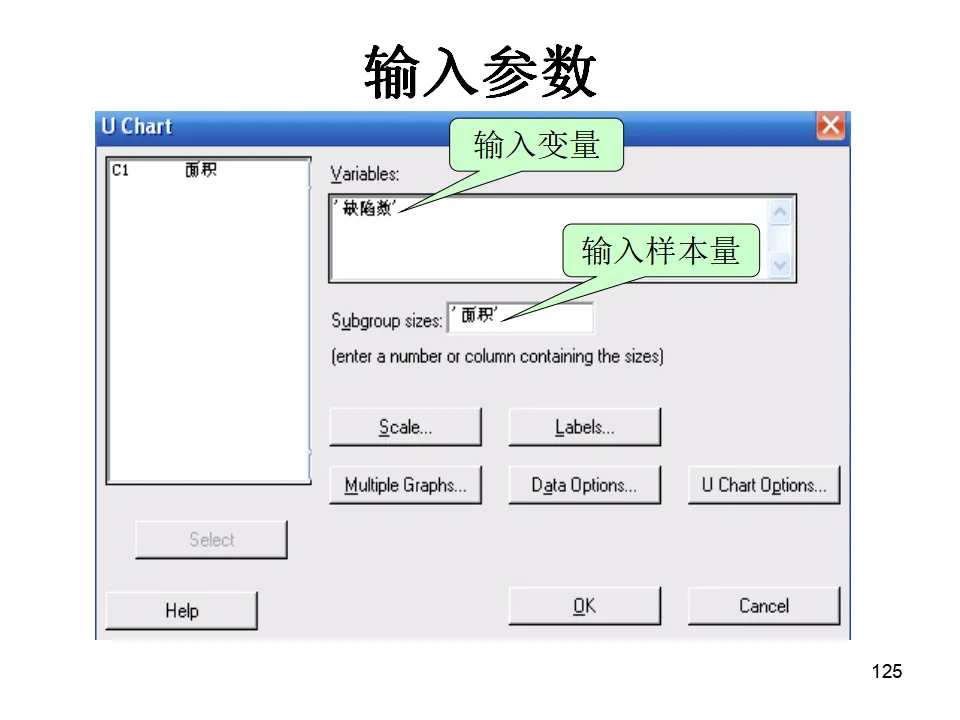
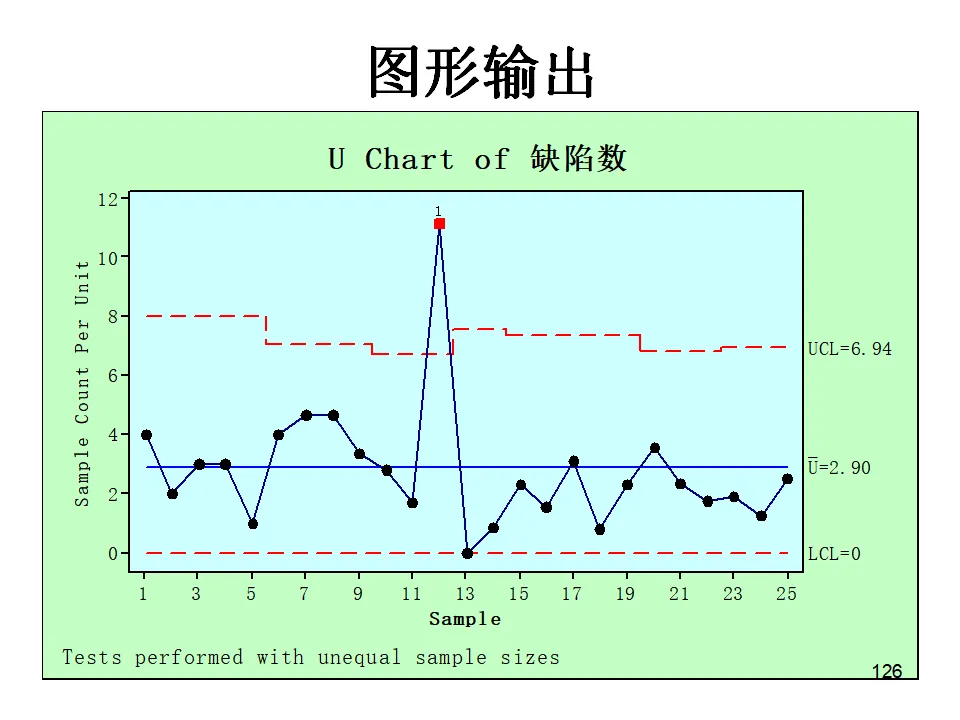
- U图:单位缺陷数控制图,适用于样本量不固定,监控平均缺陷率。
- 能否合理分组?能→Xbar-R或Xbar-S;不能→I-MR
Xbar-R图是双图组合:上方是样本均值(Xbar)的控制图,监控过程中心;下方是样本极差(R)的控制图,监控过程变异。以凸轮轴(Camshaft)数据为例,数据集包含多个子组,每个子组有5个测量值。- 数据准备:确保数据按子组组织,可以是每列一个子组,或单列数据配合子组ID列。
- 执行命令:Stat > Control Charts > Variables Charts for Subgroups > Xbar-R
- 选择数据组织方式:所有观测值在一列(All observations for a chart are in one column),选择数据列,并指定子组ID(Subgroup sizes,可以是固定数字如5,或包含子组标识的列)。
- 或选择子组跨多列(Observations are in subgroups across rows),选择包含各子组数据的列。
- 判异准则设置:点击"Xbar-R Options" > "Tests"标签,可以选择标准的Western Electric判异准则:
- 准则5:连续3点中有2点落在中心线同一侧的B区以外(2/3准则)
- 准则7:连续15点在中心线附近的C区内(过于集中,可能有数据造假或分层问题)
- 估计方法:在"Estimate"标签中,通常选择Rbar方法(用平均极差估计标准差),这是传统做法,适用于子组容量较小的情况。
- 图形输出:Minitab同时生成Xbar图和R图。
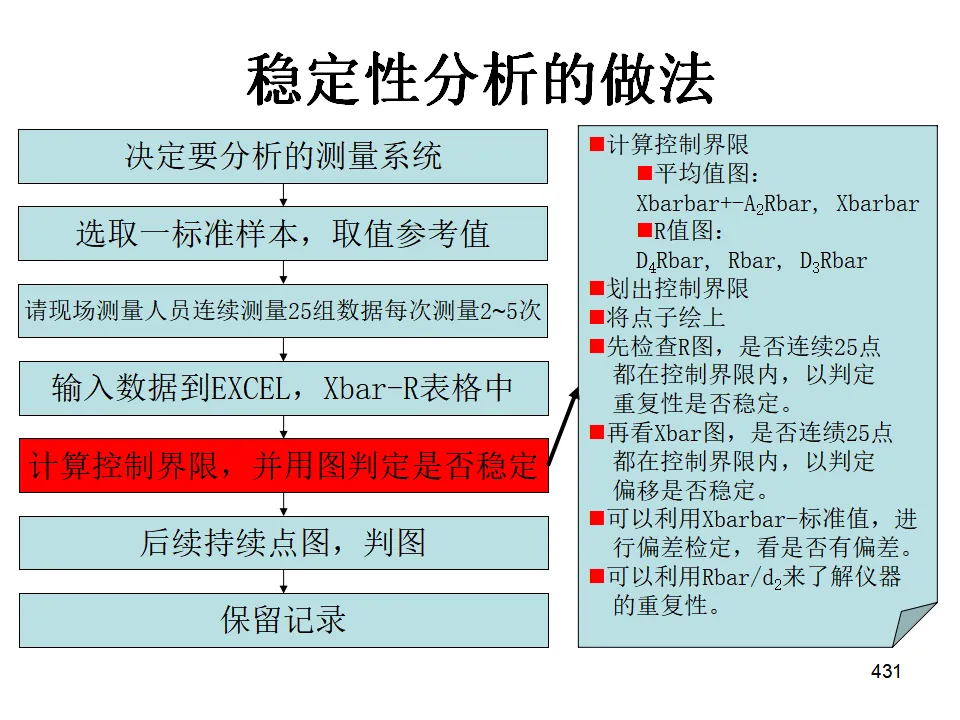
- 先看R图:如果R图失控(有点出界或非随机模式),说明过程变异不稳定,此时Xbar图的解释不可靠,因为控制限的计算基于过程变异。必须先消除R图中的异常原因,使变异稳定。
- 再看Xbar图:在R图稳定的前提下,判断过程中心是否受控。
- 解析用控制图:用于过程初期或异常排查阶段,目的是了解过程状态,识别异常原因,计算过程能力。此时控制限基于收集的数据计算得出。
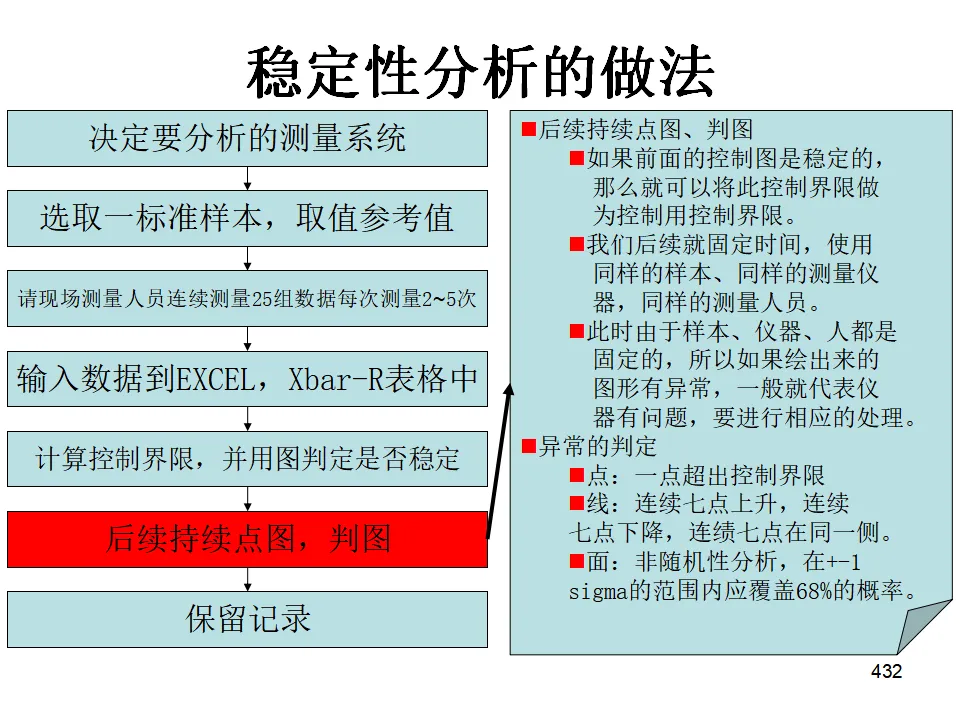
- 控制用控制图:当过程已稳定且能力充足,将解析用的控制限延长作为日常监控的标准。定期抽样打点,一旦发现异常立即采取措施。
当子组容量n较大(通常n≥10)时,极差R对变异的估计效率降低,此时应使用标准差S代替极差R。操作路径:Stat > Control Charts > Variables Charts for Subgroups > Xbar-SXbar-S图的判读方法与Xbar-R类似,但由于使用了标准差,对数据的利用更充分,控制限的计算也更精确。在子组容量较大或要求高精度分析时优先使用。当每个子组只有一个观测值时,无法计算组内极差,只能使用移动极差(Moving Range)来估计变异。移动极差通常是相邻两个单值之差的绝对值。操作路径:Stat > Control Charts > Variables Charts for Individuals > I-MR- I-MR图对轻微的过程偏移不如Xbar-R图敏感,因为缺乏取平均的统计优势
- 移动极差通常取n=2(相邻两点),也可以设置为更大的跨度,但默认是2
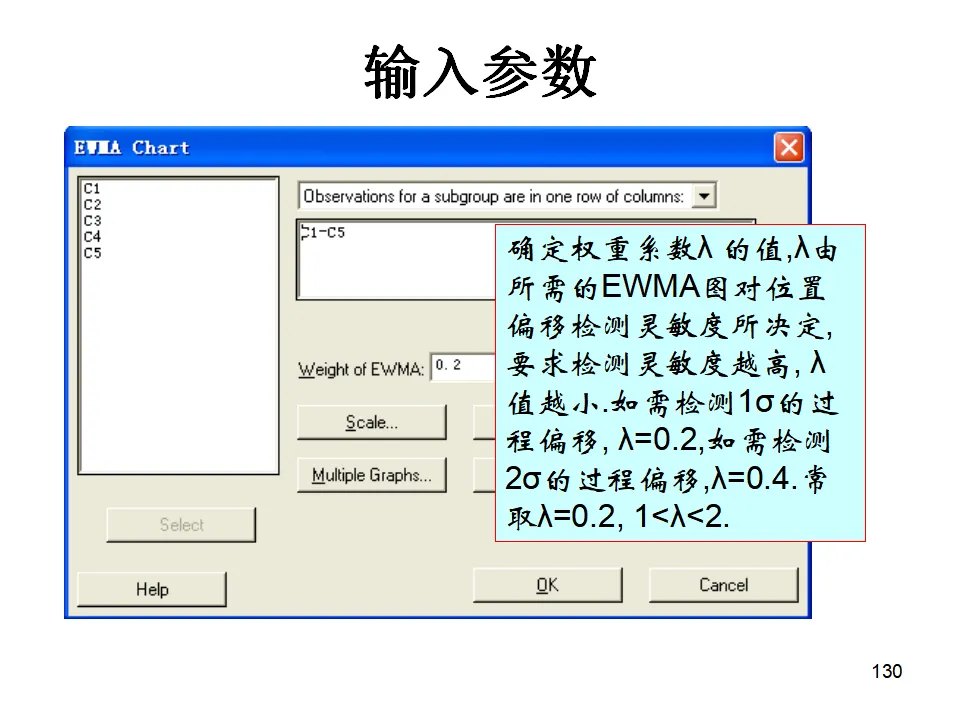
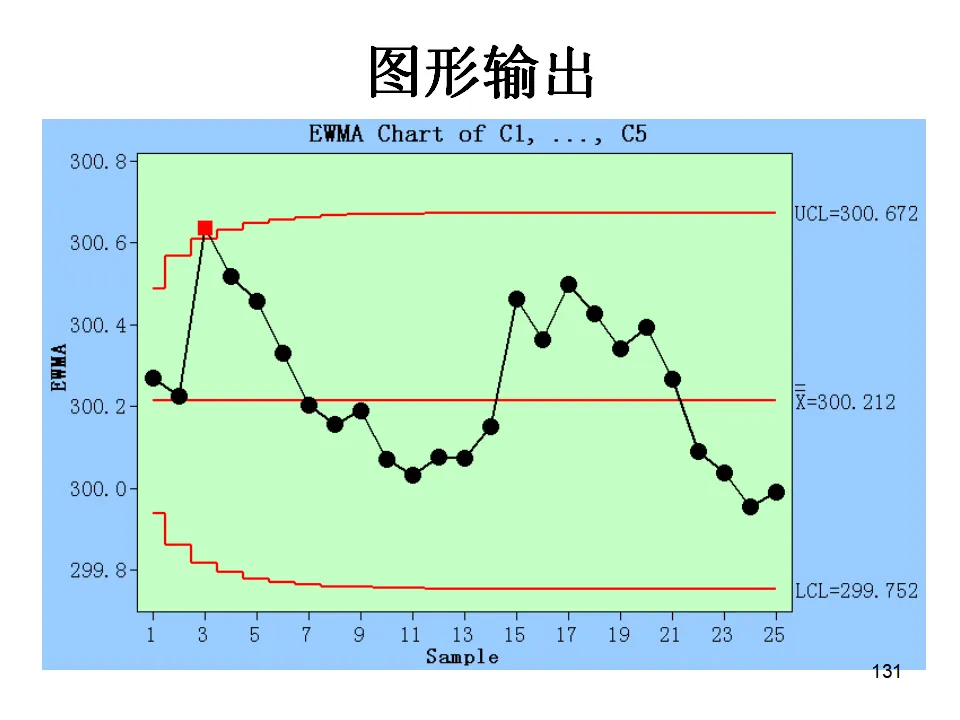
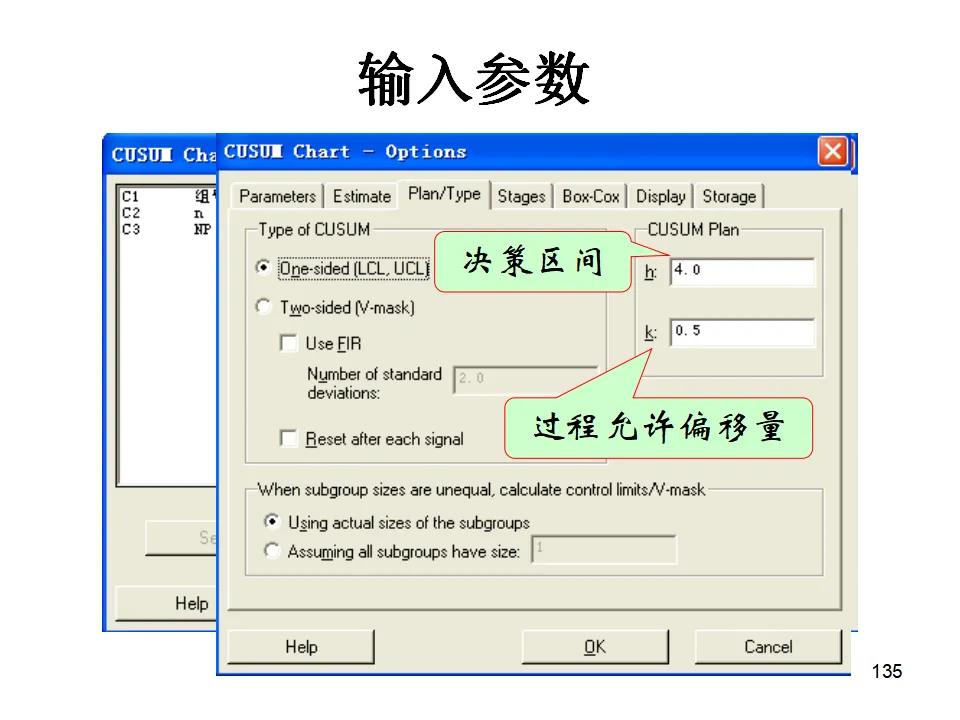
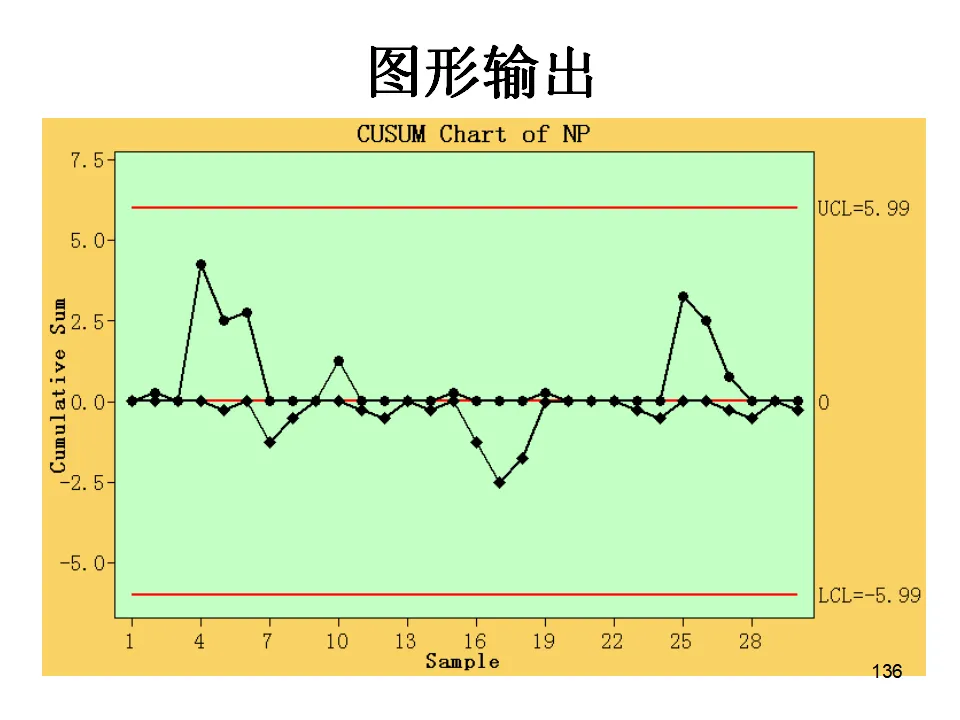
适用于二项分布数据(合格/不合格),且样本量可能变化的情况。关键要求:样本量必须足够大,通常要求np≥5(即平均不合格品数至少5个),否则二项分布近似正态分布的假设不成立,控制图可能失效。样本量应达到1/p~5/p的范围(p为平均不合格品率)。操作:Stat > Control Charts > Attributes Charts > P当样本量固定时,可以直接监控不合格品数,简化计算。如果样本量变化,必须使用P图。适用于泊松分布数据,监控单位产品上的缺陷数(如划痕数、气泡数)。要求缺陷发生的机会面积大,且各缺陷独立。关键要求:样本量(检查面积/长度/时间)必须固定,且平均缺陷数不宜太小。如果样本量变化,使用U图。当检查的样本量不固定时(如每天检查不同长度的电线),使用U图监控单位长度的缺陷数。这两种是时间加权控制图,对小的过程漂移比传统Shewhart控制图更敏感。给近期数据赋予更高权重,对过程均值的轻微偏移非常敏感,常用于化学工业等需要监控微小漂移的场合。- 通常取0.2,λ越小对历史数据记忆越长,对小幅漂移越敏感
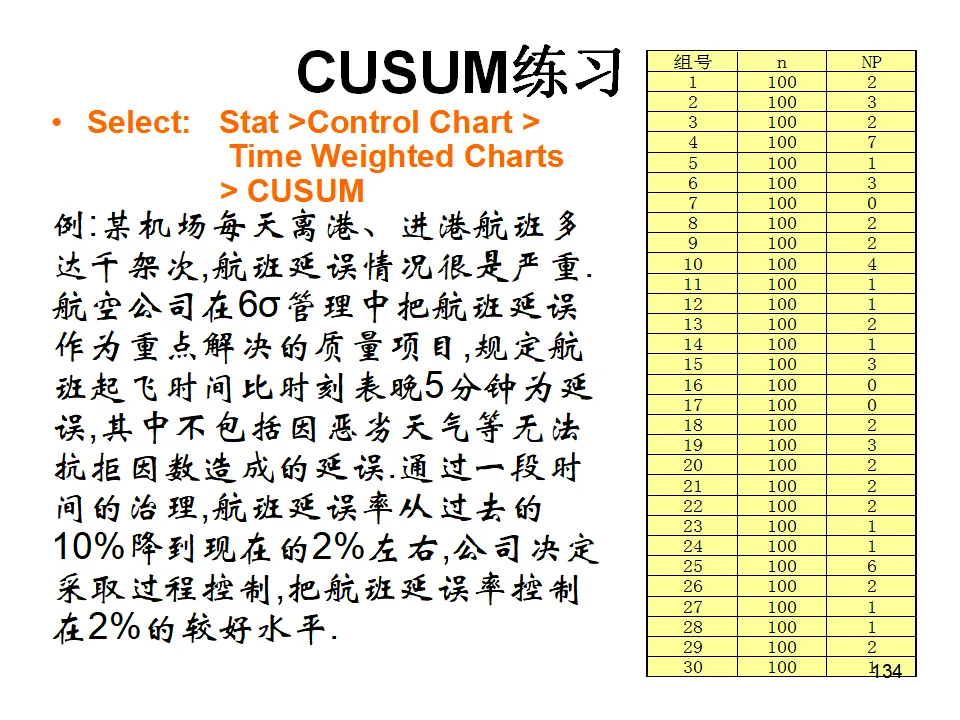
累积各样本值与目标值的偏差,适合检测过程受控状态下的微小偏离。要求子组容量相等。这两种控制图通常用于已受控过程的精密监控,而非初期的异常排查。过程能力分析是连接质量控制与质量改进的桥梁。它不仅告诉我们过程是否受控,更重要的是告诉我们过程满足规格要求的能力如何。- 过程能力(Process Capability):Cp、Cpk,反映潜在能力,基于组内变异(短期标准差),反映过程在理想稳定状态下的表现。
- 过程绩效(Process Performance):Pp、Ppk,反映实际绩效,基于总体变异(长期标准差),反映过程在当前状态下的表现。
如果Cp ≈ Pp且Cpk ≈ Ppk,说明过程稳定,短期能力与长期能力一致。如果Cp远大于Pp,说明过程存在显著的组间变异或趋势,稳定性差。操作路径:Stat > Quality Tools > Capability Analysis > Normal其中USL是规格上限,LSL是规格下限,σ是组内标准差。Cp反映过程的潜在能力,即如果过程居中时能产生多少合格品。Cp≥1.33通常被认为是可接受的,≥1.67优秀,<1.0能力不足。Cpk = min[(USL - μ)/3σ, (μ - LSL)/3σ]Cpk考虑了过程中心的位置,是过程能力与过程居中的综合体现。Cpk总是≤Cp,当过程居中时两者相等。在Cpk基础上还考虑与目标值T的偏离,适用于目标值不在规格中心的情况。计算方式类似Cp、Cpk,但使用样本标准差s(总体标准差估计)代替组内标准差。Ppk更能反映顾客实际接收到的质量水平。Zbench = Φ⁻¹(1 - Ptotal),其中P_total是总缺陷率。Sigma水平与DPMO(百万机会缺陷数)一一对应,6σ水平对应3.4 DPMO。当数据不服从正态分布时(如偏态、多峰),可以选择:- 数据转换(如Box-Cox转换、对数转换)后再分析
- 使用非参数方法或非正态分布拟合(如Weibull分布)
操作路径:Stat > Quality Tools > Capability Analysis > Nonnormal用于合格/不合格数据,分析不合格品率。输出包含过程Z值、缺陷率、置信区间等。用于缺陷数数据,分析单位缺陷数(DPU)。输出包含DPU、置信区间、与目标的比较等。过程能力六合一图(Capability Sixpack)
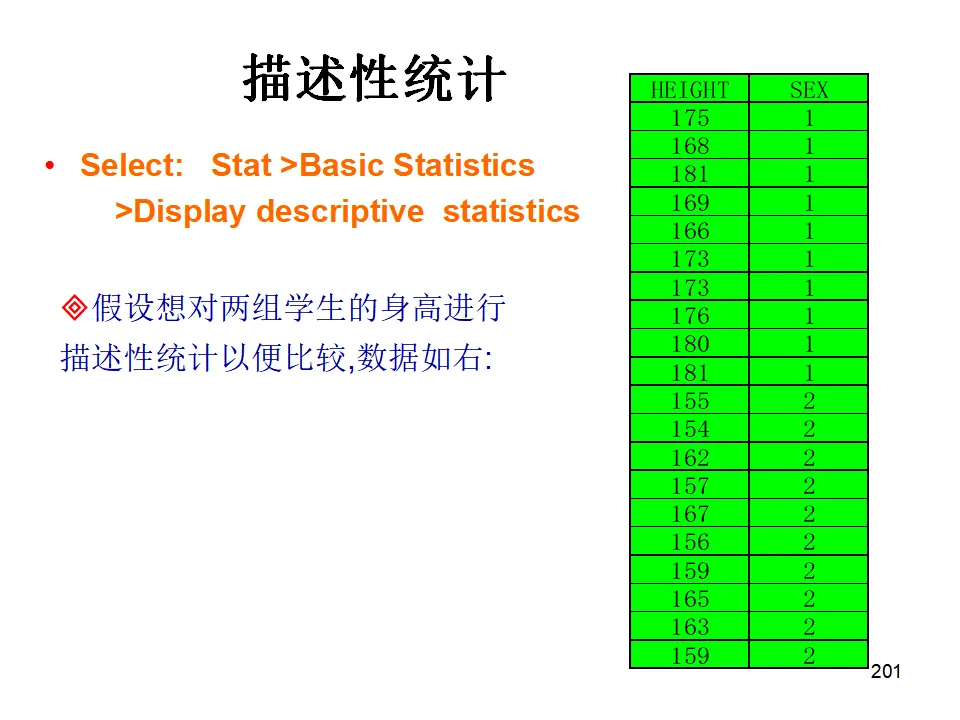
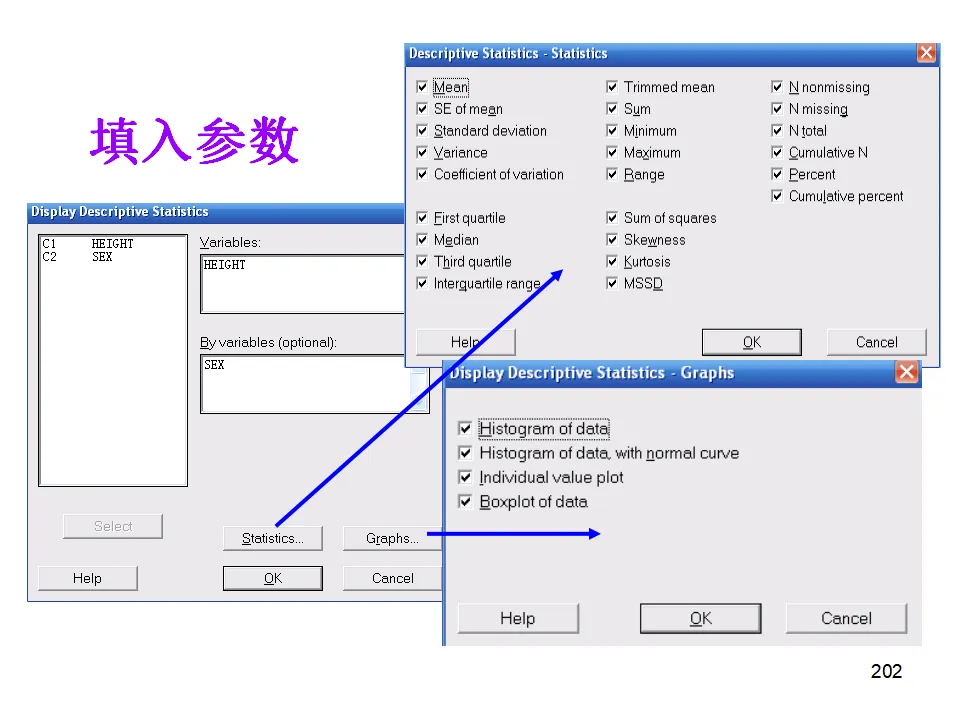
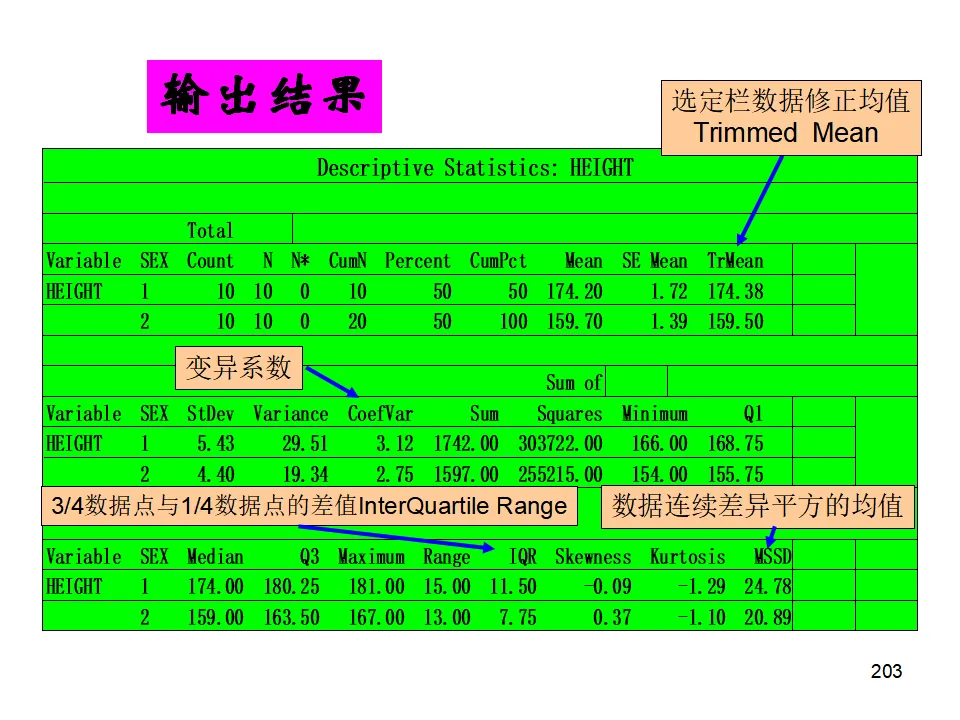
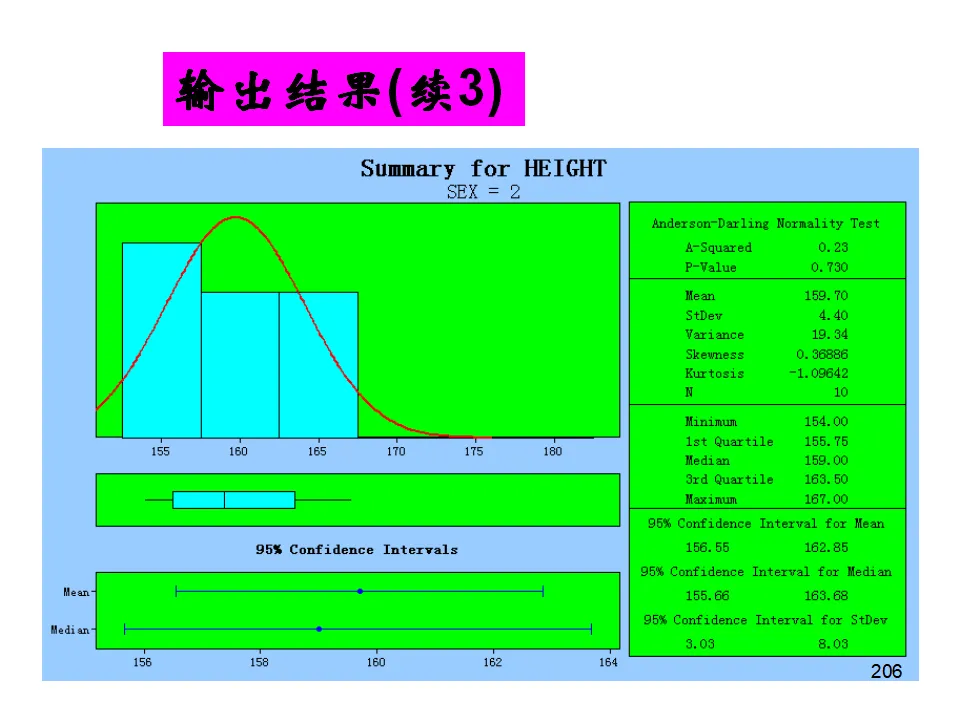
这种综合视图帮助我们从稳定性、正态性、分布形态、能力指数多个维度全面评估过程,是汇报和诊断的利器。操作路径:Stat > Quality Tools > Capability Sixpack > Normal描述性统计是数据分析的起点,通过样本统计量了解数据的基本特征。操作:Stat > Basic Statistics > Display Descriptive Statistics- 集中趋势:均值(Mean)、中位数(Median)、众数(Mode)、截尾均值(Trimmed Mean,去除极端值后的均值)
- 离散程度:标准差(StDev)、方差(Variance)、极差(Range)、四分位距(IQR)
- 分布形态:偏度(Skewness,对称性)、峰度(Kurtosis,尾部厚度)
- 位置度量:最小值、最大值、第一四分位数(Q1)、第三四分位数(Q3)
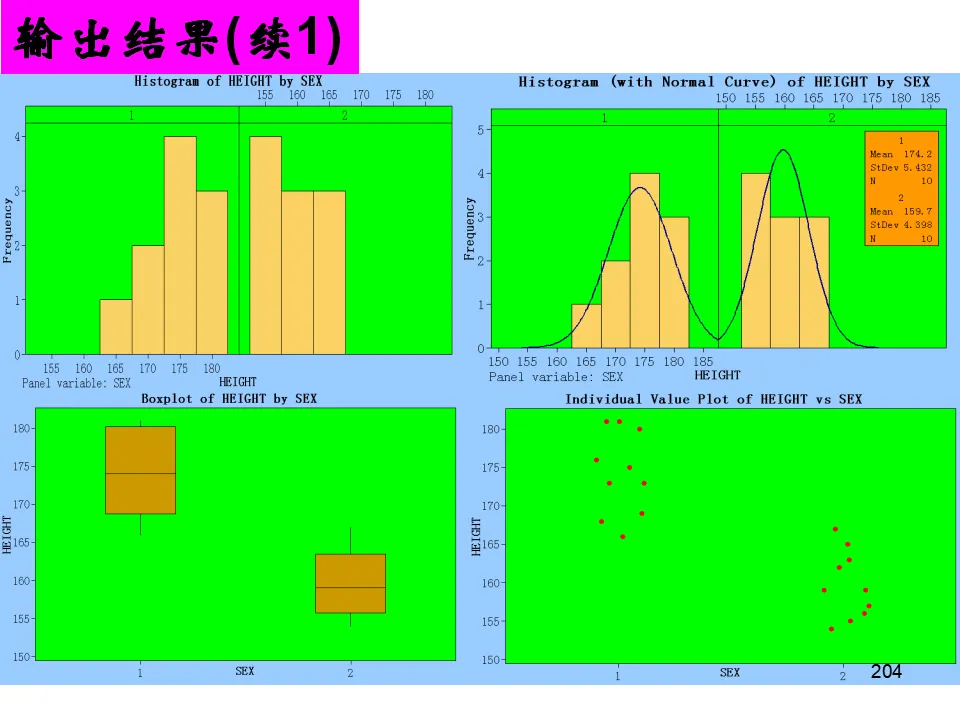
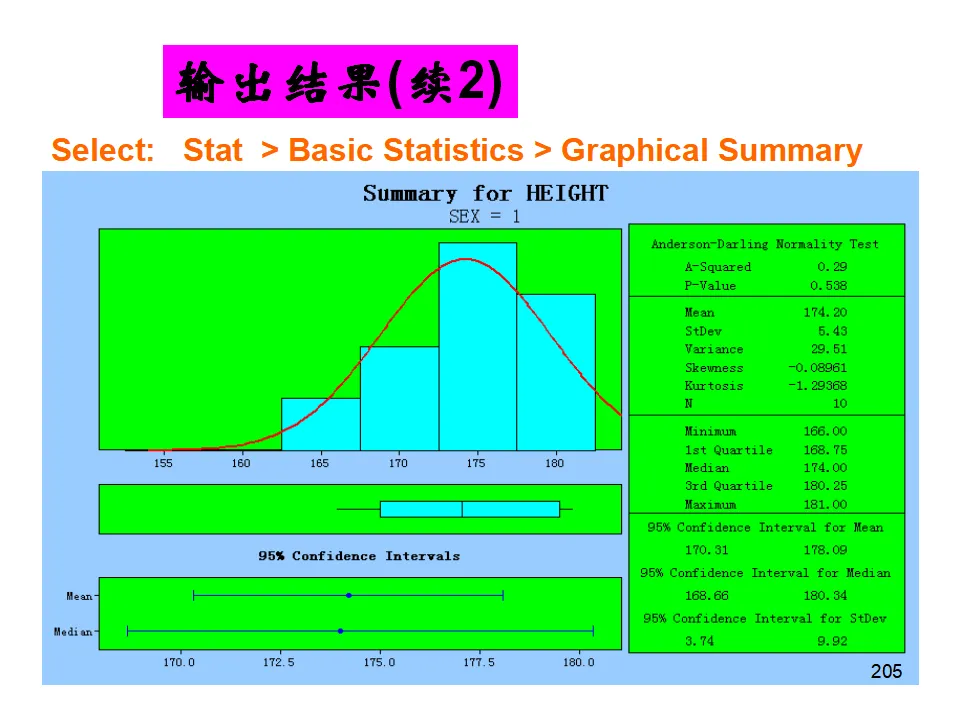
除了数字输出,Minitab还提供包含直方图、箱线图、置信区间、正态性检验的完整图形报告,是快速了解单变量特征的最佳工具。假设检验是统计推断的核心,用于基于样本数据对总体参数做出决策。- 反证法思想:假设待证命题的对立面成立(零假设H₀),如果由此推出矛盾(小概率事件发生),则拒绝H₀,间接接受备择假设H₁。
- 小概率原理:概率很小的事件在一次试验中几乎不可能发生。如果发生了,就有理由怀疑前提假设。
- 第一类错误(α错误/弃真错误):H₀实际为真但被拒绝,概率记为α(显著性水平,通常取0.05)。
- 第二类错误(β错误/取伪错误):H₀实际为假但被接受,概率记为β。检验功效(Power)=1-β,即正确拒绝错误H₀的概率。
- 提出假设:H₀(零假设,通常是无效应、无差异、等于某值)和H₁(备择假设,有效应、有差异、不等于/大于/小于某值)。
- 做出决策:如果p值<α,拒绝H₀;否则不拒绝H₀。
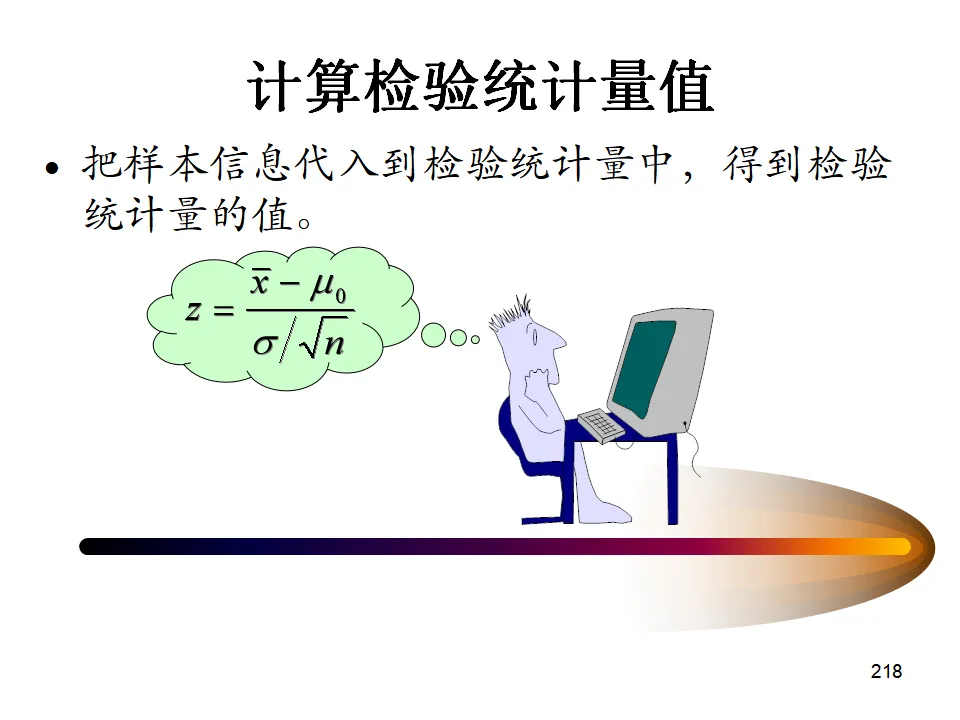
p值的含义:在H₀为真的假设下,观察到当前样本或更极端情况的概率。p值越小,反对H₀的证据越强。适用条件:总体标准差σ已知,且总体服从正态分布或大样本(n≥30)。示例:测量9个工件,已知总体σ=0.2,检验均值是否等于5。操作:Stat > Basic Statistics > 1-Sample Zt统计量:t = (x̄ - μ₀) / (s/√n),服从自由度为n-1的t分布。当n>30时,t分布接近正态分布,Z检验和t检验结果相近。操作:Stat > Basic Statistics > 1-Sample t假设:两样本独立,各自来自正态总体,方差相等(或不等,Minitab提供两种选项)。示例:比较两台炉子(Furnace.mtw数据)的均值差异。操作:Stat > Basic Statistics > 2-Sample t输出包含均值差异的估计、置信区间、t统计量和p值。当两个样本存在配对关系时(如同一批产品在处理前后的测量,或孪生兄弟分别接受不同教育后的成绩),使用配对t检验消除个体间变异,提高检验功效。操作:Stat > Basic Statistics > Paired t计算每对数据的差值,然后对差值进行单样本t检验(检验均值是否为0)。单样本比例检验:检验总体比例是否等于某特定值(如声称的不合格率≤1%)。双样本比例检验:比较两个总体的比例是否有差异(如比较两种教学方法的学生通过率)。操作:Stat > Basic Statistics > 1 Proportion / 2 Proportion可以使用汇总数据(输入事件数和试验数)或原始数据列。许多统计方法(如t检验、控制图、能力分析)都假设数据服从正态分布,因此正态性检验是前提。- Anderson-Darling检验:最常用的方法,对尾部偏离敏感。
- Kolmogorov-Smirnov检验:基于经验分布与理论分布的最大距离。
- Ryan-Joiner检验:基于相关系数,类似于Shapiro-Wilk检验。
操作:Stat > Basic Statistics > Normality Test如果p值<0.05,拒绝正态性假设,需要考虑数据转换或非参数方法。当我们需要比较多个总体(三个或以上)的均值时,两两进行t检验不仅繁琐,而且会增加第一类错误的概率(多重比较问题)。方差分析通过一次检验判断所有均值是否相等。- 组间变异(SSB):不同水平(组)间的差异,反映处理效应。
- 组内变异(SSW):同一水平内的随机波动,反映误差。
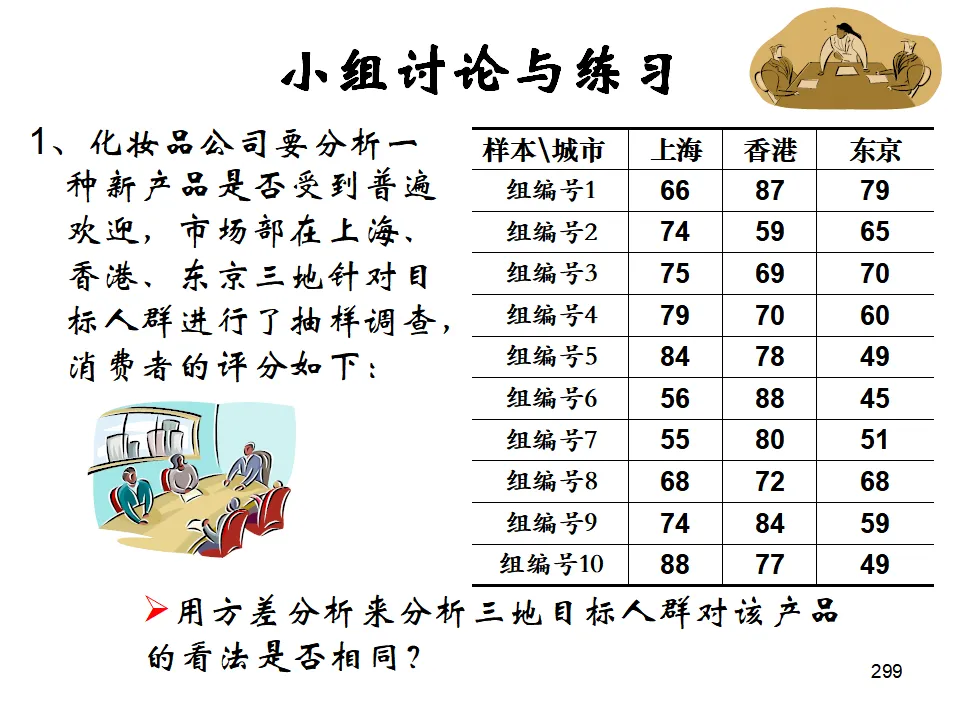
如果组间变异显著大于组内变异(F = MSB/MSW 较大),则认为不同水平的均值存在显著差异。只有一个分类变量(因素),研究该因素不同水平对响应变量的影响。示例:比较三个城市(北京、上海、广州)分支机构的员工素质评分。操作:Stat > ANOVA > One-Way- 各组数据来自正态总体(可通过正态性检验或残差图验证)。
- 各组方差相等(齐性),可通过Test for Equal Variance检验。
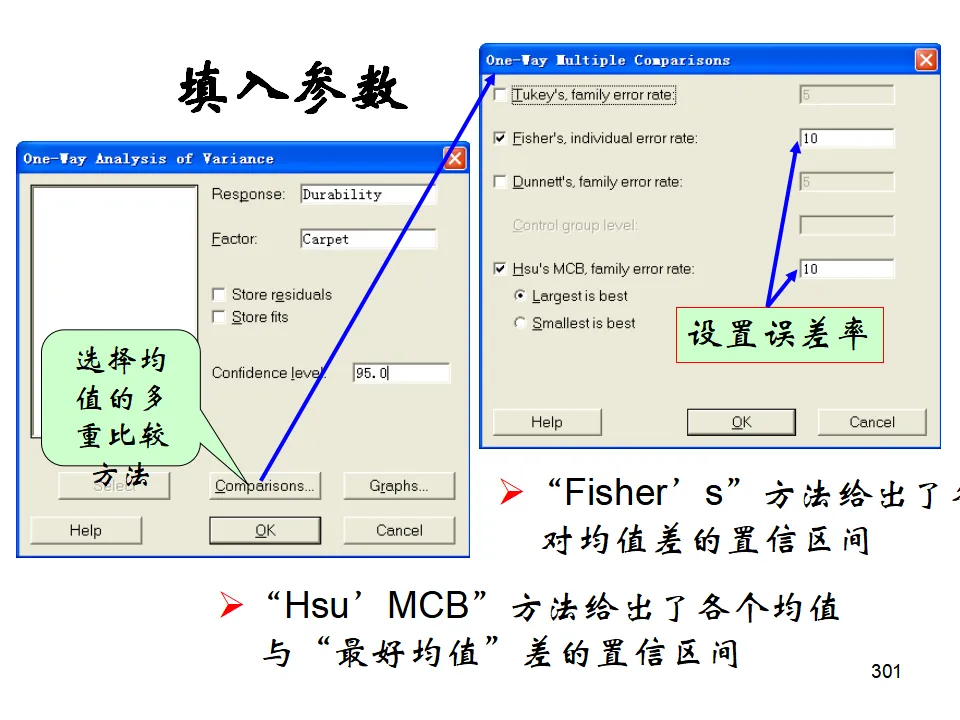
如果ANOVA显示显著差异,还需要知道具体哪些组之间存在差异。Minitab提供多种方法:- Fisher's LSD:最宽松,控制每次比较的α,不控制整体α。
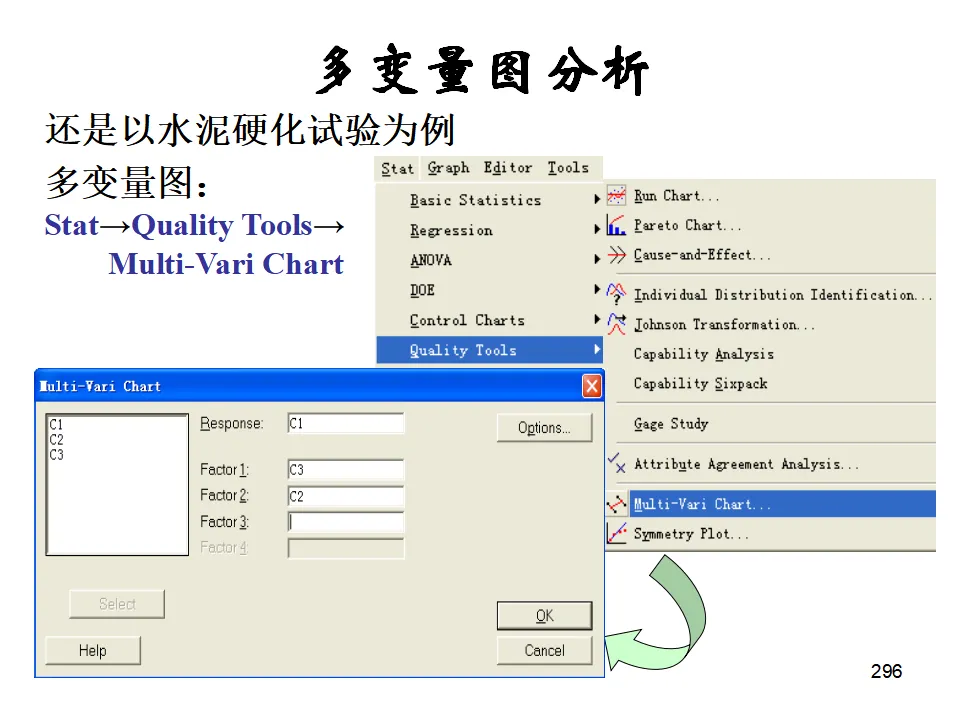
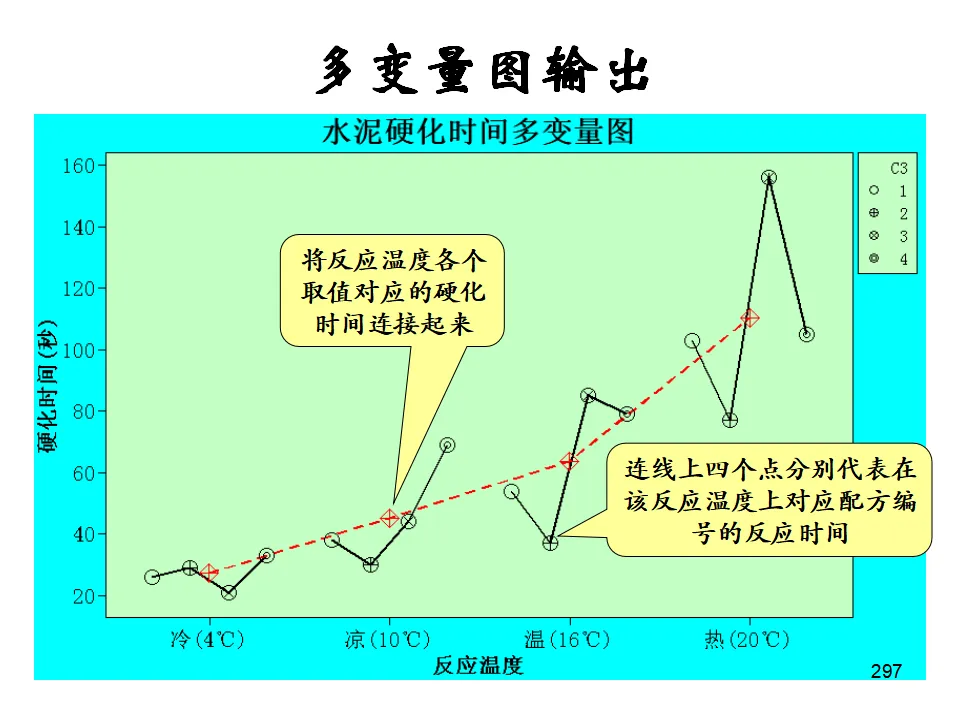
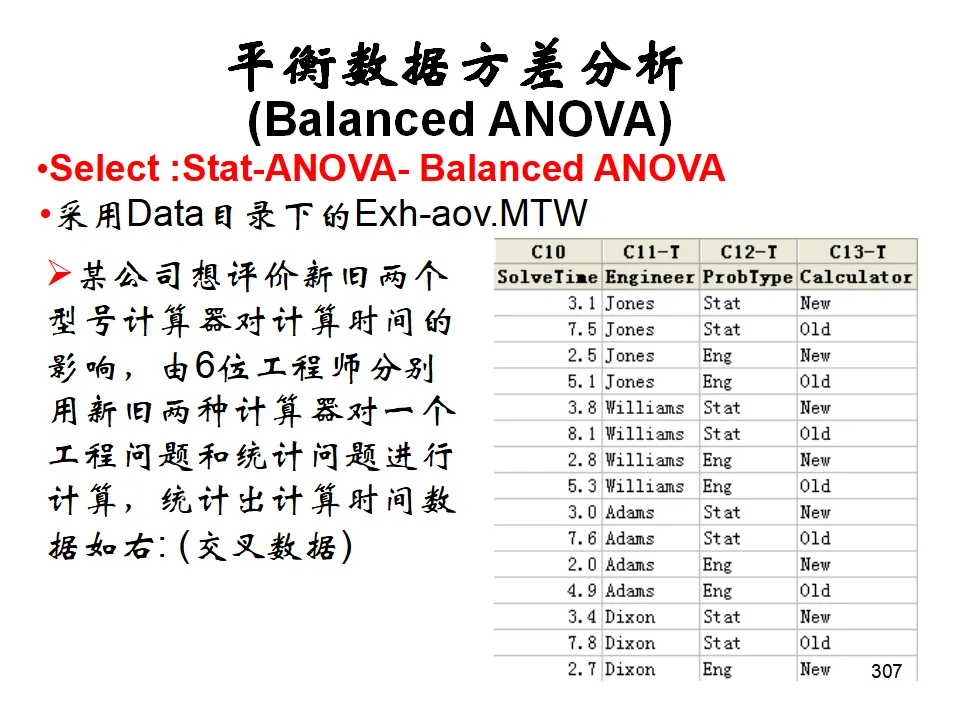
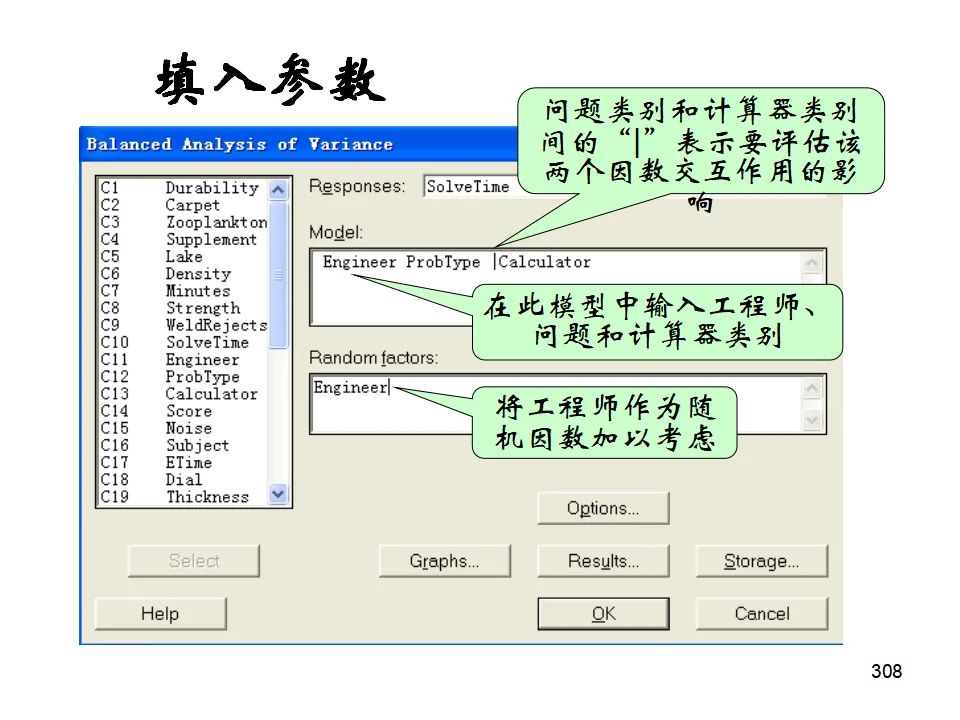
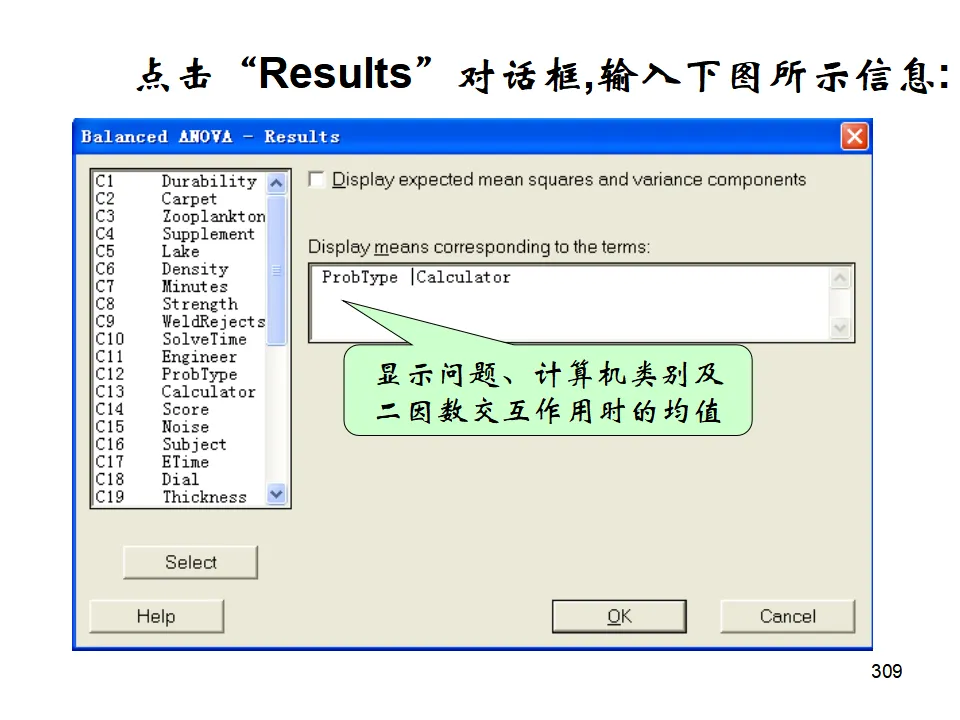
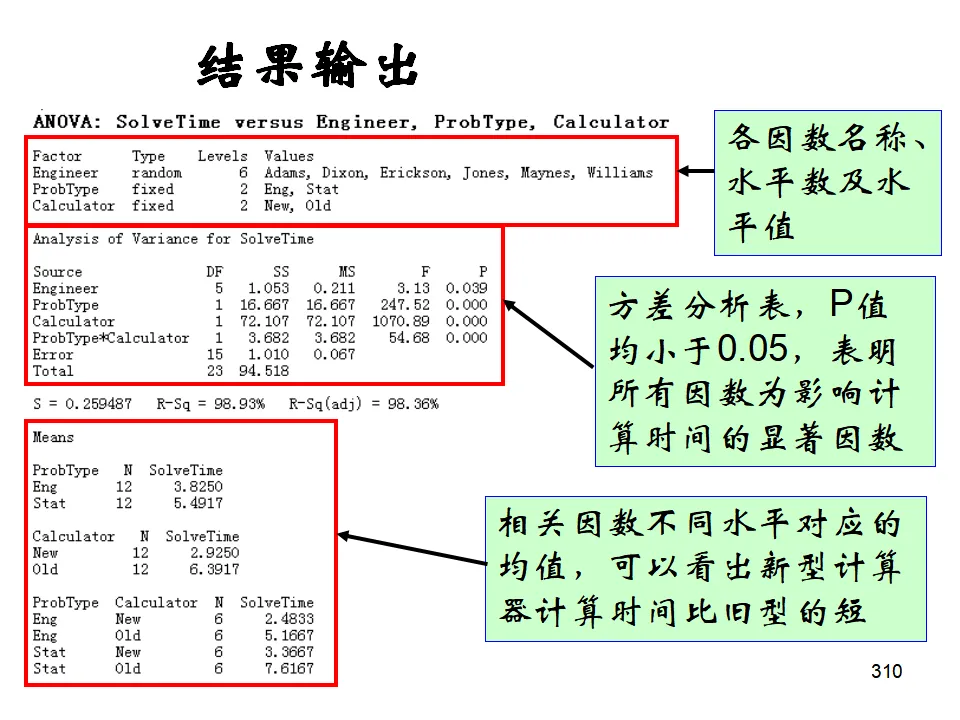
示例:研究水泥配方(因素A)和反应温度(因素B)对硬化时间的影响。模型:Y = μ + αᵢ + βⱼ + (αβ)ᵢⱼ + εᵢⱼₖ其中(αβ)ᵢⱼ代表交互作用,即一个因素的效果依赖于另一个因素的水平。操作:Stat > ANOVA > Two-Way可视化双因素效应的图形工具,可以直观看出主效应和交互作用的存在。平衡数据方差分析(Balanced ANOVA):各单元格样本量相等时的多因素分析,计算效率高。通用线性模型(General Linear Model, GLM):处理非平衡数据、协方差分析、复杂交互作用的最通用方法。嵌套方差分析(Nested ANOVA):因素间存在层级嵌套关系时使用,如不同工厂(A)内的不同机器(B),B嵌套于A而非交叉。多变量方差分析(MANOVA):同时分析多个相关的响应变量,考虑变量间的相关性。相关分析研究变量间关系的强度和方向(相关系数r,-1≤r≤1),但不区分自变量和因变量。回归分析则建立变量间的数学模型,用于预测和控制。简单线性回归模型:Y = β₀ + β₁X + ε其中β₀是截距,β₁是斜率(回归系数),ε是随机误差。模型估计:最小二乘法(OLS),使残差平方和最小:Σ(Yᵢ - Ŷᵢ)² = Σ(Yᵢ - b₀ - b₁Xᵢ)² → min- R²(决定系数):解释变量X能解释Y变异的百分比,0≤R²≤1,越接近1拟合越好。
- 回归系数的t检验:检验斜率是否显著不为0(即X对Y是否有显著影响)。
- 点预测:给定X₀,预测Y的期望值Ŷ₀ = b₀ + b₁X₀。
- 区间预测:包括均值置信区间(预测平均响应)和个体预测区间(预测单个观测)。
当因变量Y受多个自变量X₁, X₂, ..., Xₖ影响时,使用多元回归。模型:Y = β₀ + β₁X₁ + β₂X₂ + ... + βₖXₖ + ε多重共线性:自变量间高度相关会导致回归系数估计不稳定,方差膨胀。需要通过VIF(方差膨胀因子)诊断,VIF>10通常认为存在严重共线性。- 逐步回归(Stepwise):逐步引入或剔除变量,基于F检验或AIC/BIC准则。
调整R²:考虑变量个数后的R²修正,防止过度拟合。当变量间关系非线性时,可通过变量变换转化为线性模型:- 对数变换:Y与X呈指数关系 Y = ae^(bX) → lnY = lna + bX
- 倒数变换:Y与X呈双曲线关系 Y = a + b/X → Y = a + b(1/X)
- 幂函数变换:Y = aX^b → lnY = lna + blnX
- 多项式回归:Y = β₀ + β₁X + β₂X² + ...,通过引入高次项拟合曲线关系。
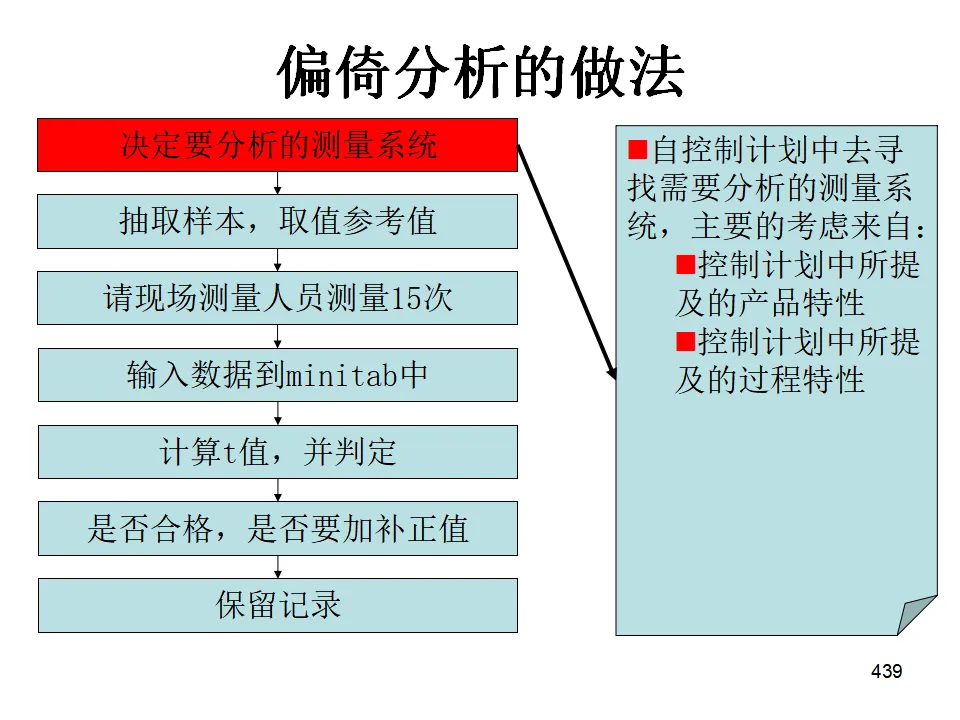
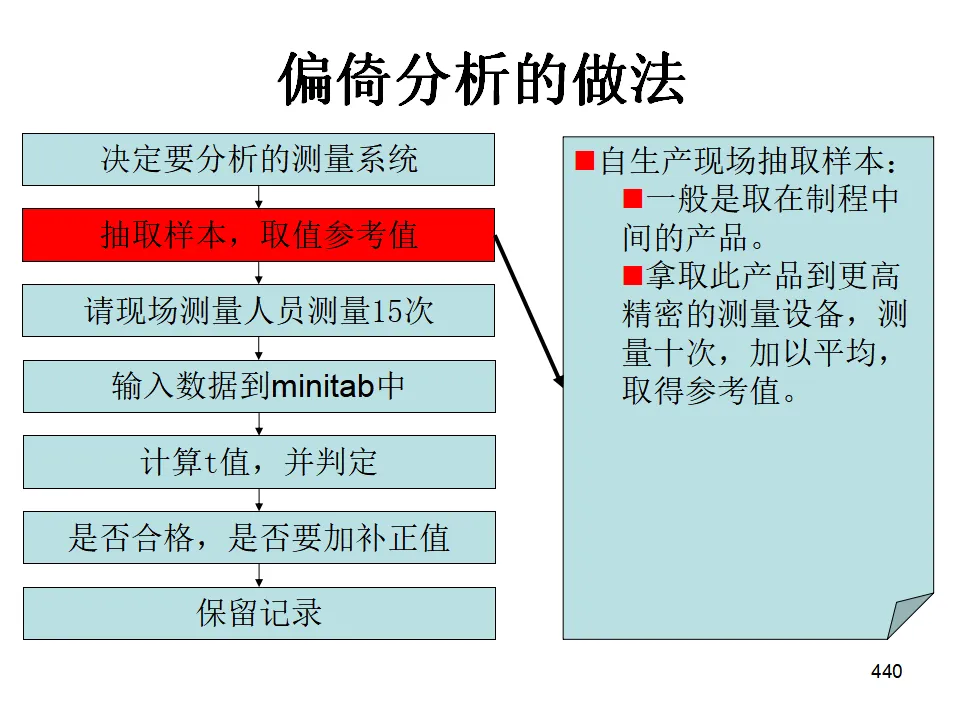
"工欲善其事,必先利其器"。测量系统分析确保我们用于决策的数据是可靠的。如果测量系统本身误差太大,任何基于数据的分析和决策都是不可靠的。- 偏倚(Bias):测量平均值与基准值的差异(准确度)。
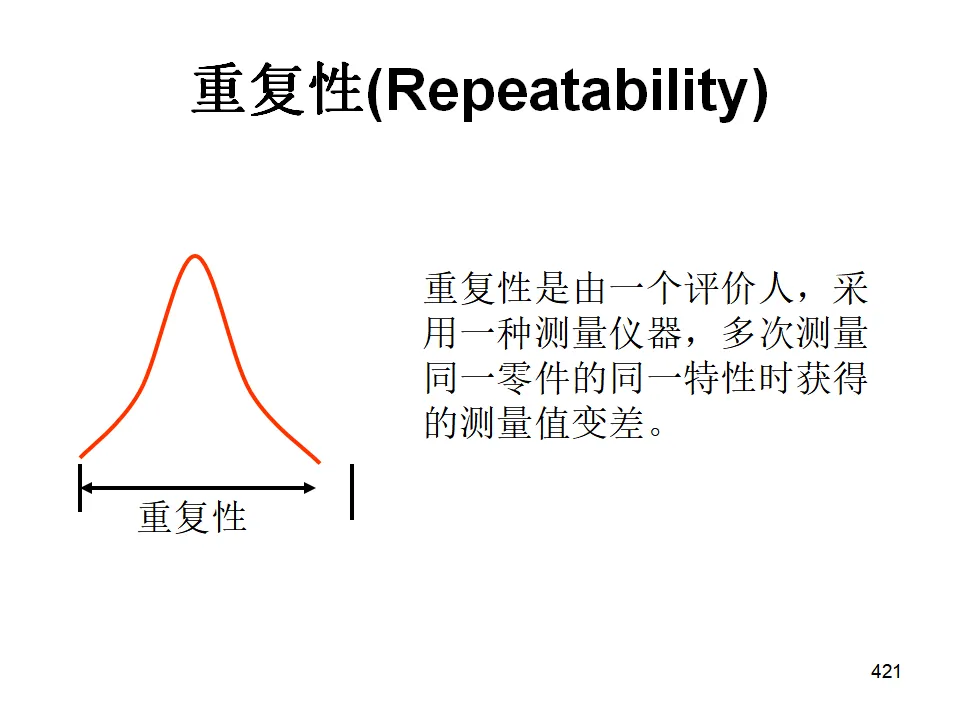
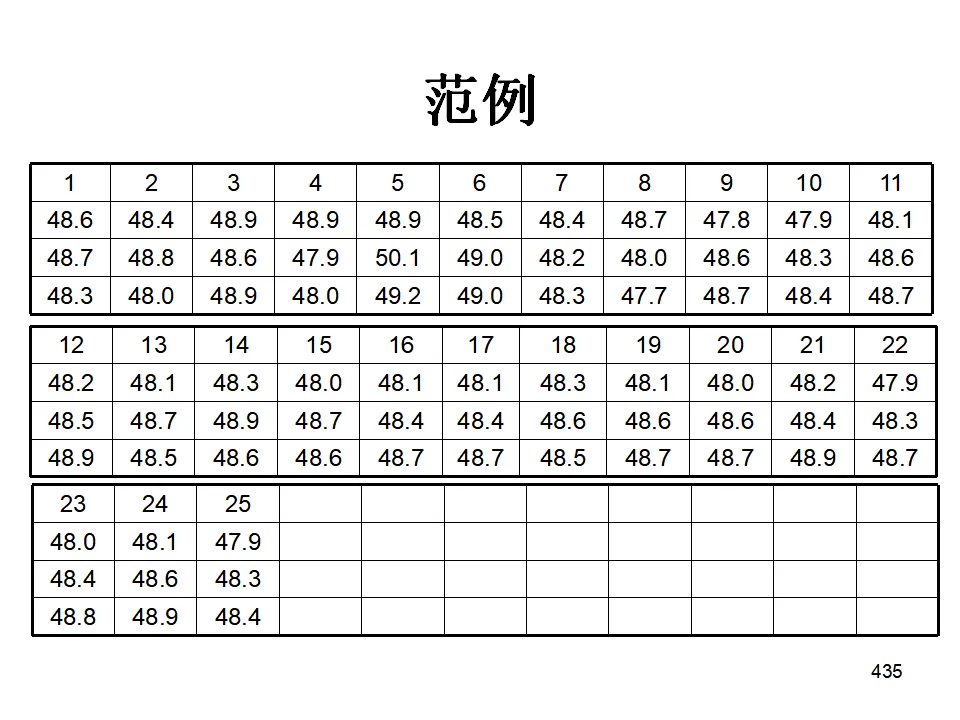
- 重复性(Repeatability):同一评价人多次测量同一零件的同一特性时的变异(设备固有变异)。
- 再现性(Reproducibility):不同评价人测量同一零件同一特性时均值的变异(操作者间变异)。
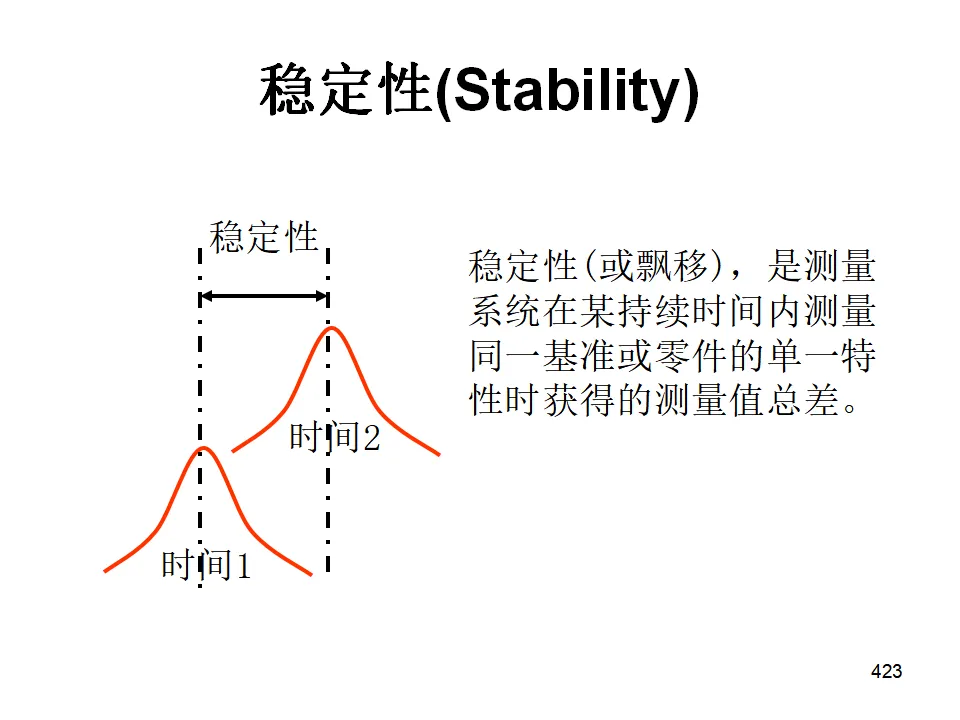
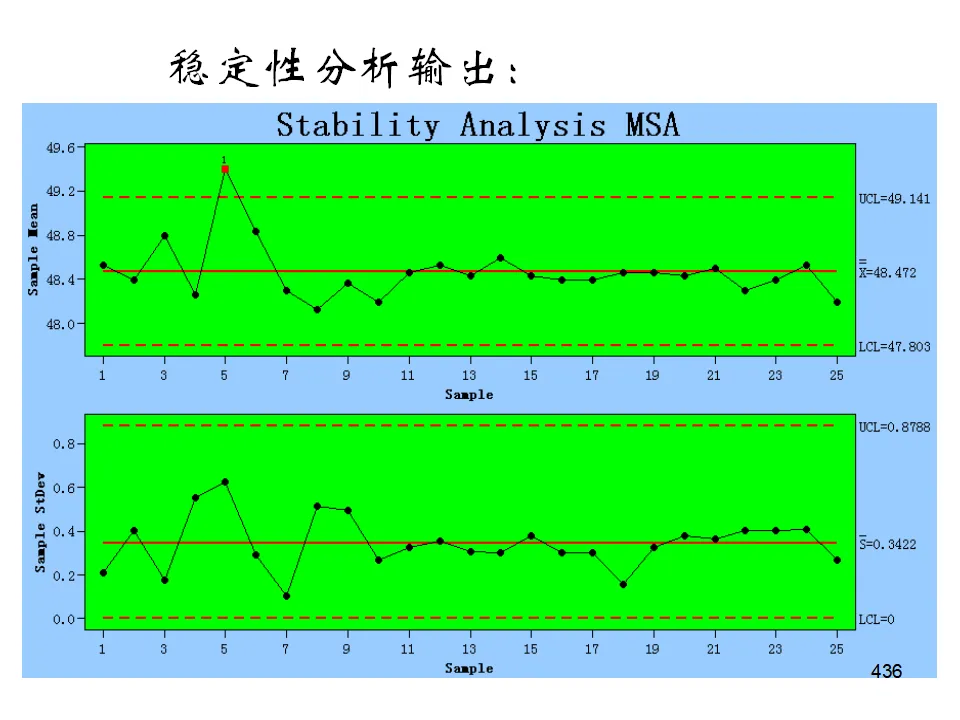
- 稳定性(Stability):测量系统随时间的变异(漂移)。
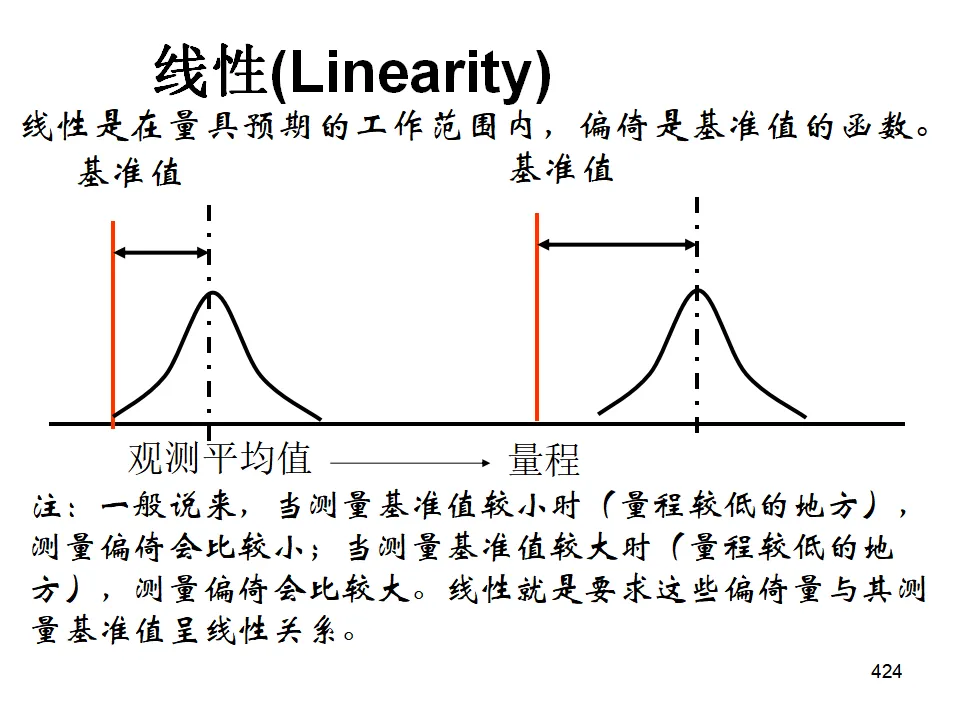
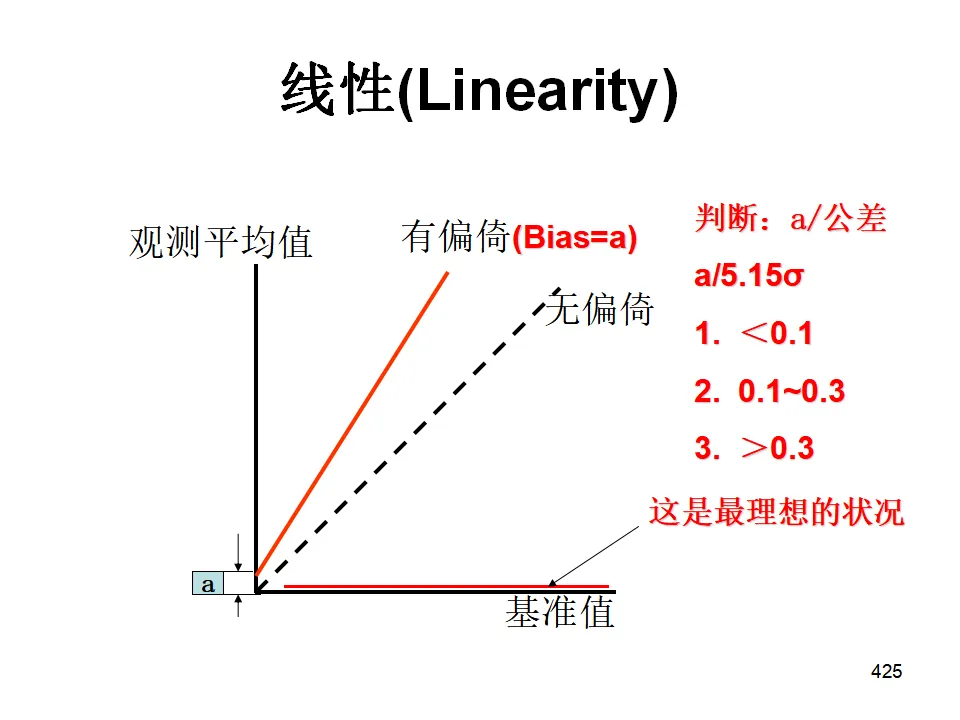
- 线性(Linearity):偏倚在量程范围内的变化情况。
交叉设计(Crossed):每个评价人测量每个零件多次,适用于零件不被破坏的情况。操作:Stat > Quality Tools > Gage Study > Gage R&R Study (Crossed)通常采用ANOVA方法(比传统极差法更精确,可分析交互作用)。- %Study Var < 10%:测量系统可接受。
- 10% ≤ %Study Var < 30%:条件接受,取决于应用重要性、成本等。
- %Study Var ≥ 30%:不可接受,必须改进。
可区分类别数(Number of Distinct Categories):测量系统能够区分的过程组数,应≥5。嵌套设计(Nested):当测量是破坏性时,每个零件只能测一次,不同评价人测不同但相似的零件。偏倚研究:选择覆盖量程的标准件,由操作者重复测量,比较均值与基准值,进行t检验。线性研究:在量程范围内选择5个基准值(通常均匀分布),每个测12次,建立基准值与偏倚的回归方程。检查:- 线性度 %Linearity = Slope × Process Variation。
定期(如每周)测量标准件3-5次,建立I-MR控制图监控测量系统是否受控。如果点出界或出现趋势,说明测量系统需要校准或维修。操作:Stat > Quality Tools > Attribute Agreement Analysis可分析每个评价人、评价人之间、评价人与标准的一致性百分比和置信区间。试验设计是研究如何科学安排试验、高效获取数据、分析因素效应的统计方法。- 重复(Replication):同一条件下多次试验,估计随机误差。
- 随机化(Randomization):试验顺序随机,消除时间趋势等干扰。
- 区组化(Blocking):将异质性分组,在组内比较,提高精度。
- 全因子设计(Full Factorial):研究所有因素及其交互作用,2^k设计(k个因素,每因素2水平)最常用。
- 部分因子设计(Fractional Factorial):当因素较多时,通过折中研究部分交互作用,节省试验次数。
- 响应曲面设计(RSM):在找到关键因素后,用中心复合设计(CCD)或Box-Behnken设计拟合曲面,寻找最优条件。
- 混料设计(Mixture Design):当因素为配方成分且总和为100%时使用。
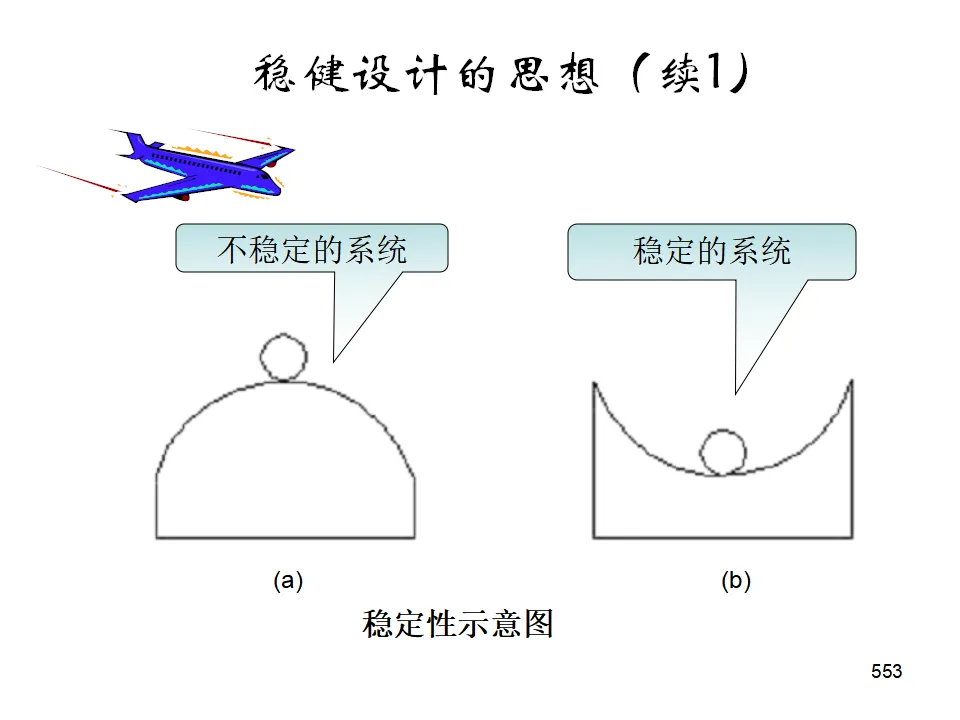
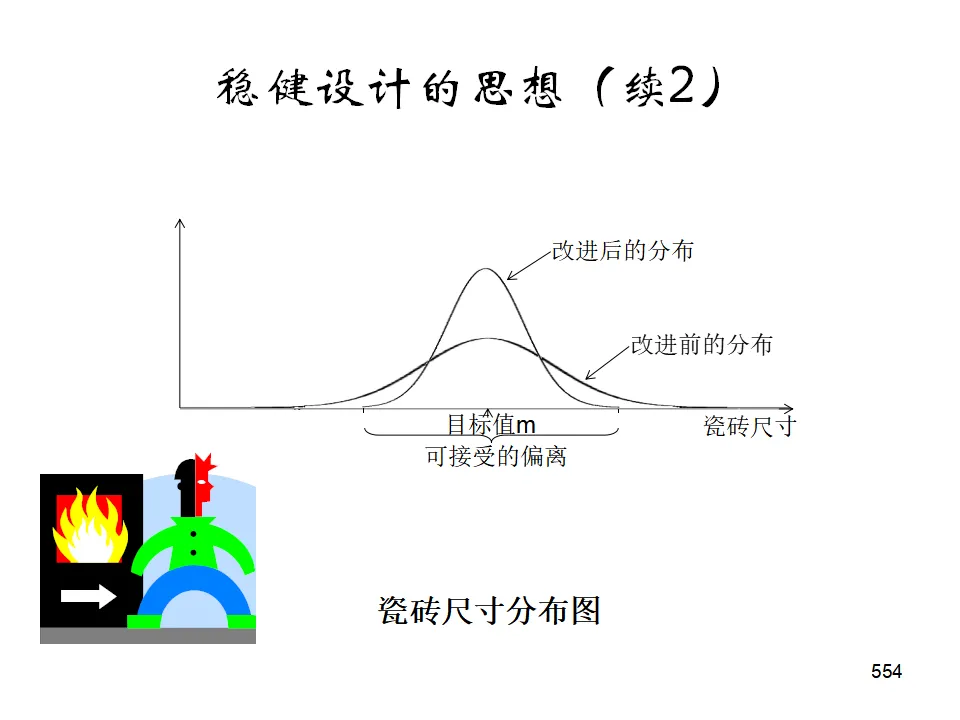
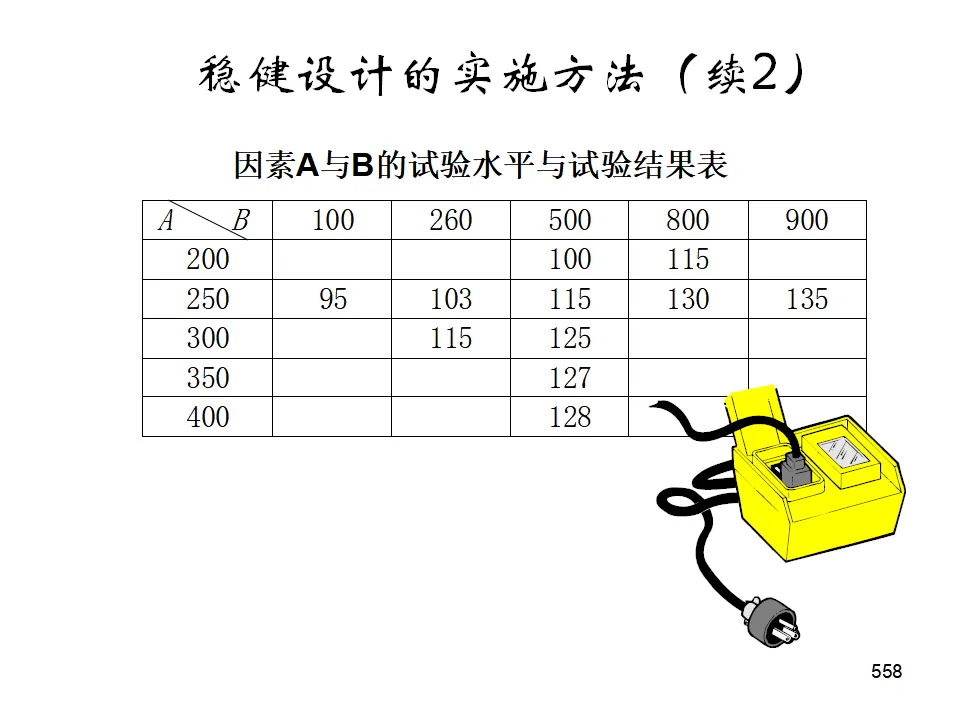
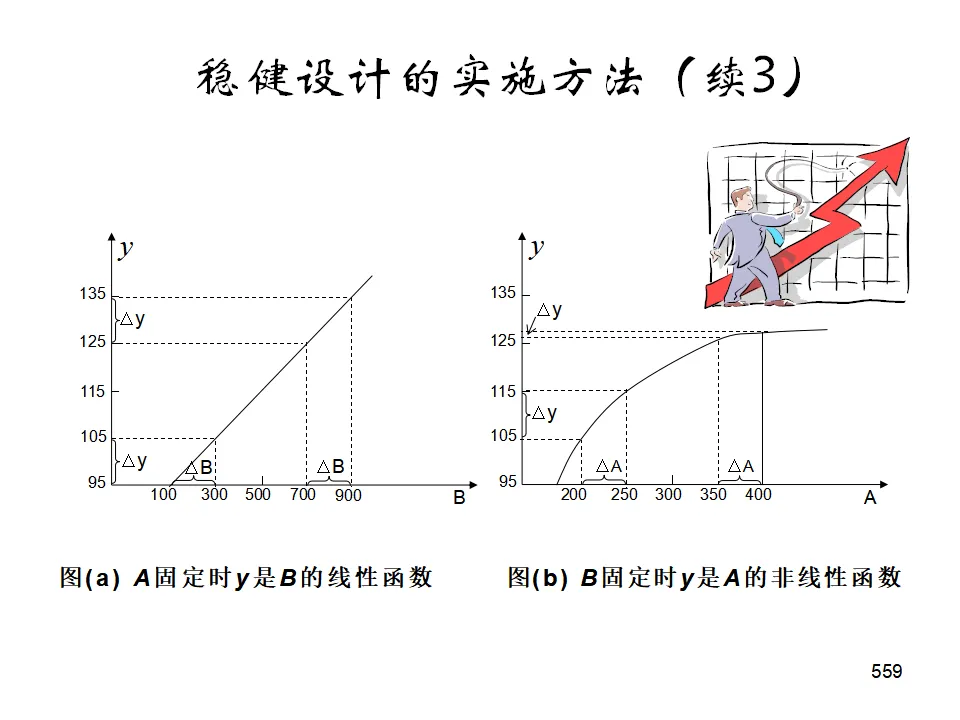
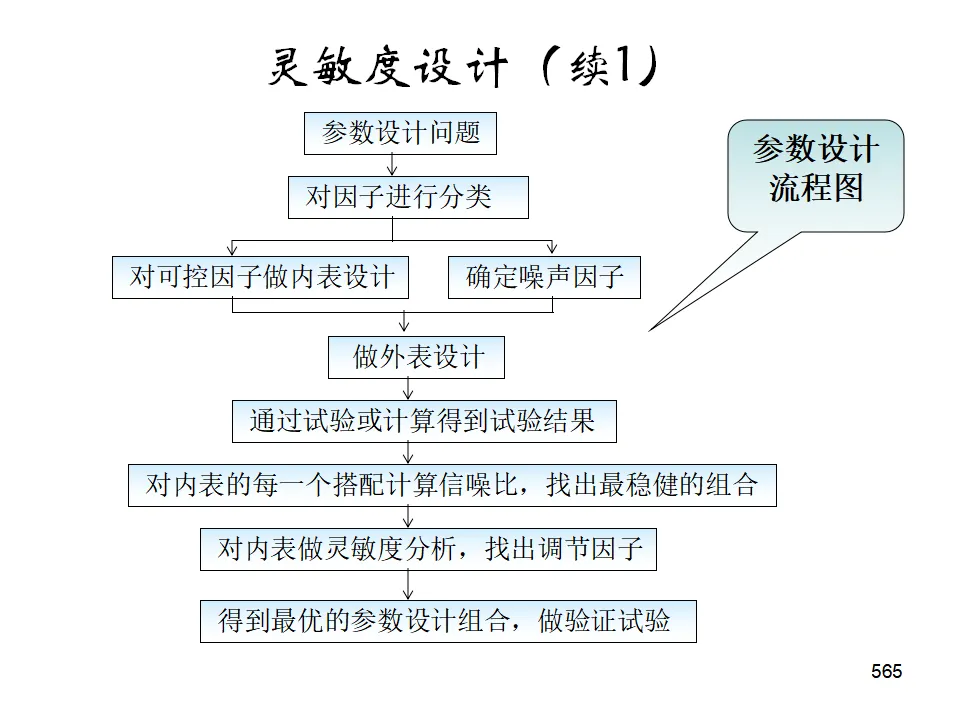
均分法:在范围内均匀布点,适合多峰函数或单调函数,整体设计可并行执行。0.618法(黄金分割法):适用于单峰函数,每次淘汰约38%的范围,高效寻找最优。斐波那契法:类似0.618法,但使用斐波那契数列确定试验点,适合离散情况。稳健设计的目标不仅是使响应达到目标值,更重要的是使响应的变异最小(对噪声因素不敏感)。- 内表(Control Factors):可控的工艺参数,安排正交表。
- 外表(Noise Factors):不可控的干扰因素(如环境温度、原料批次波动),对每个内表组合进行噪声试验。
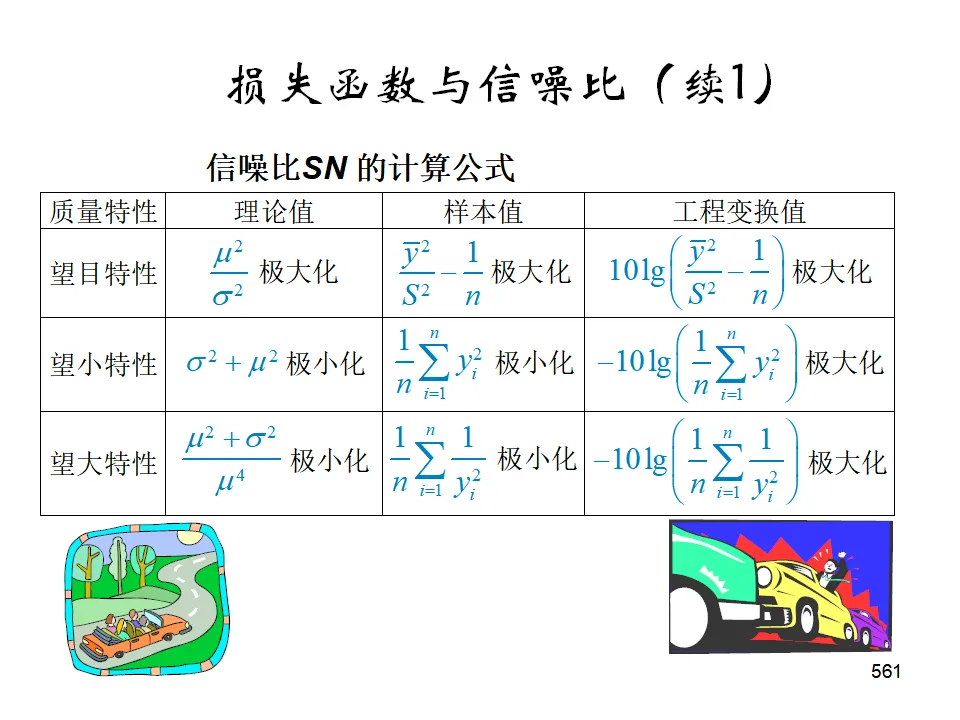
- 望小特性(越小越好):S/N = -10log(Σy²/n)
- 望大特性(越大越好):S/N = -10log(Σ(1/y²)/n)
- 望目特性(接近目标最好):S/N = -10log(Σ(y-m)²/n) 或考虑变异与偏倚的组合
通过选择使S/N最大的因素水平组合,获得稳健性,再通过调整因素(对S/N影响小但对均值影响大的因素)使响应接近目标值。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。