在日常办公中,数据往往不是规规矩矩地躺在表格里,而是以各种“混合体”的形式出现:身份证号里藏着生日、产品编码夹杂着型号、一长串文本里只有几个数字是有用的。面对这些杂乱数据,你是否还在用“复制+粘贴”的笨办法,或者盯着屏幕手动一个个敲?
别急,Excel(及WPS)中有三位“文本处理三剑客”——LEFT(左)、RIGHT(右)和MID(中)。它们就像精准的剪刀,能帮你从字符串的任意位置剪下所需的信息。今天,我们不讲枯燥的语法,直接通过三个实战案例,带你彻底玩转这三大函数。
案例一:从身份证号中提取出生日期
身份证号是结构化数据的典型代表,其中第7位到第14位,恰好是我们的出生日期(格式为YYYYMMDD)。如何将它“挖”出来,并变成标准的日期格式?
操作步骤:
1. 假设A列是身份证号,我们在B列输入公式。
2. 首先使用MID函数定位提取。MID的作用是从文本中间开始截取,语法为MID(文本, 开始位置, 字符个数)。
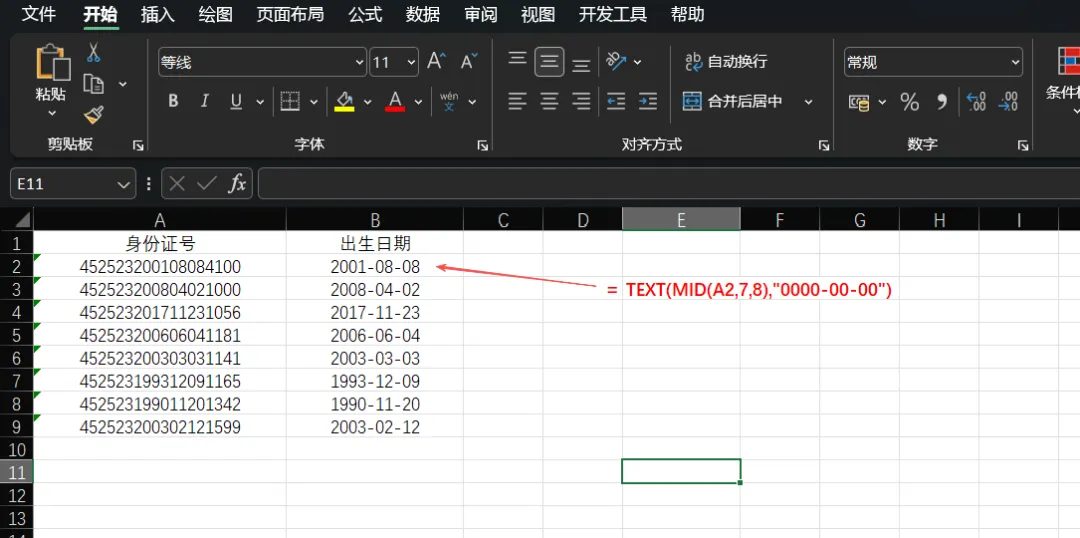
3. 在B2单元格输入公式:=MID(A2,7,8)。
4. 按下回车,此时我们得到了“19900307”这样的文本字符串。
5. 为了让它变成Excel能识别的日期,我们嵌套TEXT函数进行格式化:=TEXT(MID(A2,7,8),"0000-00-00")。
公式解析:
MID(A2,7,8):这是核心提取逻辑。A2是源数据,从第7个字符开始数,连续抓取8个字符,正好对应身份证中的“出生年月日”。
TEXT(..., "0000-00-00"):MID提取出来的东西默认是“文本”格式,无法直接用于计算年龄等操作。TEXT函数在这里充当了“翻译官”,将8位数字强制转换为“年-月-日”的日期显示样式。
案例二:从“姓名-电话”混合文本中分离姓名
在很多导出的数据表中,姓名和电话号码常常挤在一个单元格里,中间用短横线“-”或空格隔开,例如“张三-13800000000”。如果一个个手动删除电话,效率极低。
操作步骤:
1. 假设A列是混合数据,我们要在B列提取姓名。
2. 这里我们使用LEFT函数结合FIND函数。LEFT用于从左边开始截取,但我们需要动态确定截取到哪里。
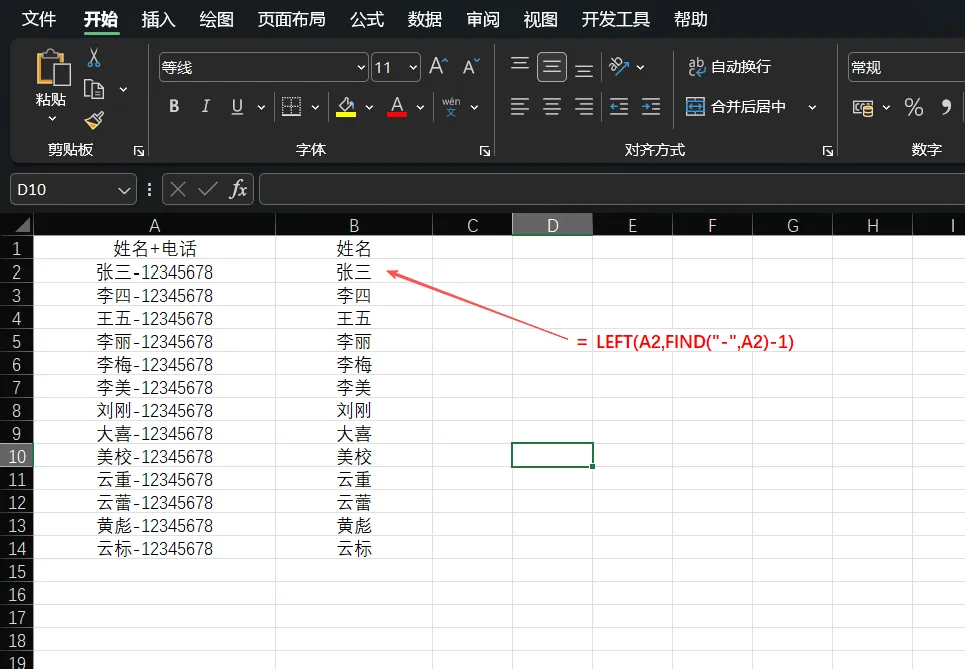
3. 在B2单元格输入公式:=LEFT(A2,FIND("-",A2)-1)。
4. 按下回车,姓名“张三”就被精准提取出来了。
公式解析:
FIND("-",A2):这个函数的作用是“找位置”,它会返回短横线“-”在A2单元格中是第几个字符。
FIND(...)-1:因为我们只想保留“-”前面的姓名,所以截取的长度应该是短横线位置的前一位。
LEFT(...):LEFT函数根据FIND计算出的长度,从左边开始截取相应字符。这套组合拳的关键在于,无论姓名是两个字还是三个字,FIND函数都能自动找到分隔符位置,实现动态分离。
案例三:提取不规则文本中的唯一数字
这是最让人头疼的场景:文本完全没有固定格式,比如“订单号ORD2024001已发货”或者“产品编码:A123B456C789,库存75件”。我们需要把其中的数字“揪”出来。这里介绍一种利用“分列”功能的巧解法,以及针对特定格式的函数解法。
操作步骤(针对“前文后数”格式):
1. 如果数字总是出现在文本的最后,例如“库存75”,我们可以使用RIGHT函数。
2. 但难点在于数字的位数不固定。此时需要结合LEN(计算总长度)和FIND(找第一个数字的位置)。
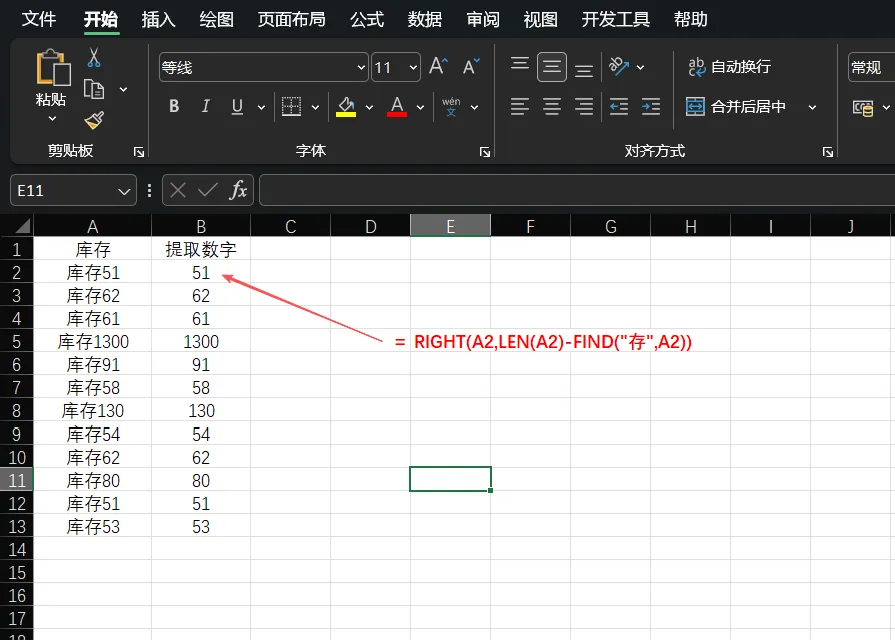
3. 假设数字前面有一个固定的汉字,比如“库存”,我们可以用:=RIGHT(A2,LEN(A2)-FIND("存",A2))。
4. 如果数字位置完全随机且无前缀,建议使用Excel的“数据分列”功能(数据选项卡 -> 分列 -> 选择“分隔符号” -> 勾选“其他”输入非数字字符)或者在Excel 365中使用TEXTSPLIT函数。
公式解析:
LEN(A2):计算出整个字符串的总长度。
FIND("存",A2):找到汉字“存”所在的位置。
RIGHT(文本, 总长-标识位):用总长度减去“标识位”之前的字符数,剩下的就是数字的位数。RIGHT函数则从右侧截取这部分内容。
进阶提示:
对于极其复杂的“纯提取数字”需求,如果数字前后没有固定标识符,通常需要使用数组公式(如SUMPRODUCT配合MID)或VBA,但在日常办公中,利用“分列”功能通常比写复杂公式更高效。
结语
数据清洗是数据分析的第一步,也是最基础的一步。掌握了LEFT、RIGHT和MID这“三剑客”,配合FIND、LEN等辅助函数,你会发现90%的杂乱文本都能被快速整理成规整的表格。赶紧打开你的Excel,找几组数据练练手吧!
关注我,每周解锁一个Excel神技。让我们一起,用更少的时间,做更酷的工作。