数据透视表做不到的, pivotby可以!
- 2026-05-20 04:15:23

Excel情报局
用案例讲Excel

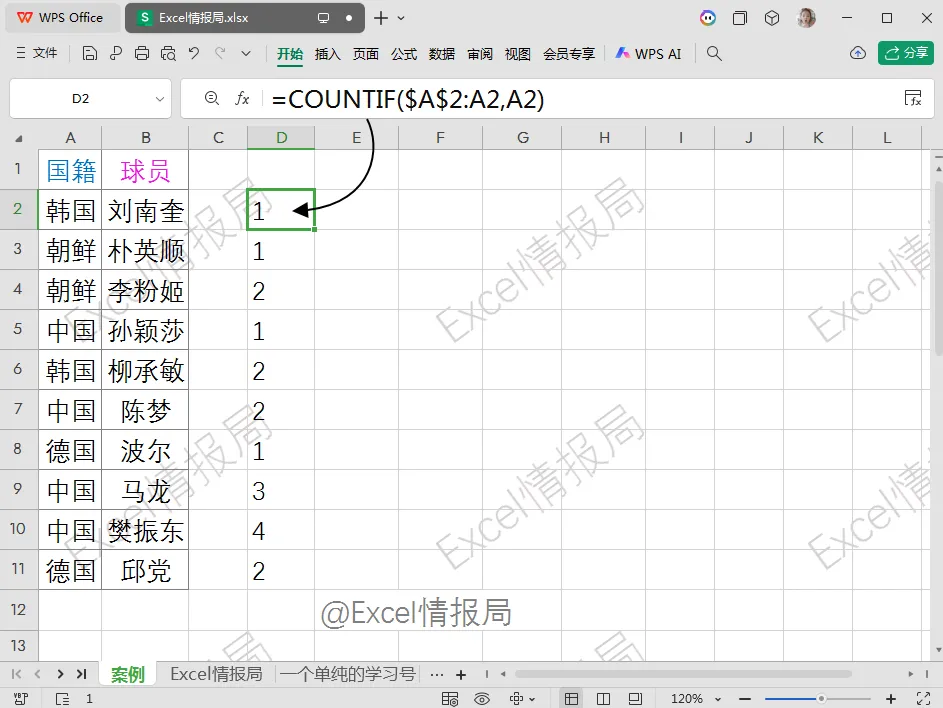
=COUNTIF($A$2:A2,A2)
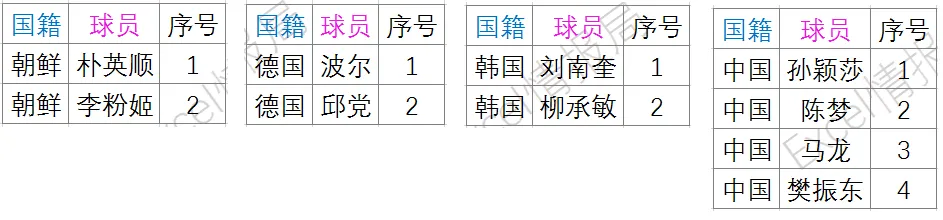
这个公式的作用是统计从A2到当前行中,与当前行A列值相同的单元格个数,生成出现顺序编号。
第2步
用lambda封装countif计算逻辑
使用lambda自定义函数:
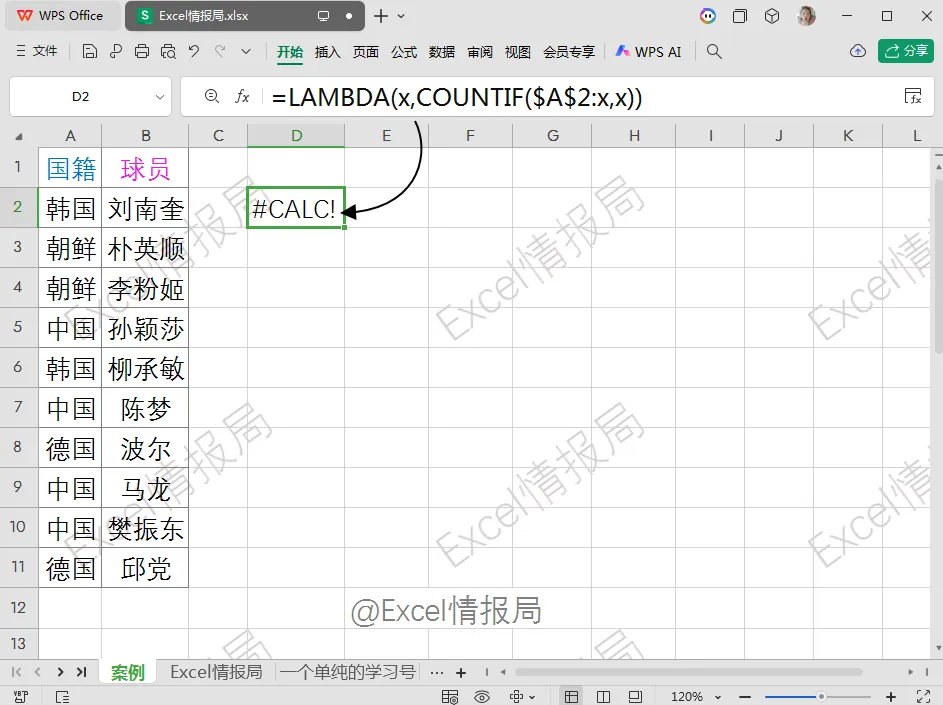
=LAMBDA(x,COUNTIF($A$2:x,x))
将步骤①的逻辑封装成 LAMBDA 自定义函数,方便后续调用。
参数x代表当前单元格(如 A2, A3…A11),函数返回该国家在$A$2:x范围内出现的次数。
第3步
map函数遍历数组
=MAP(A2:A11,LAMBDA(x,COUNTIF($A$2:x,x)))
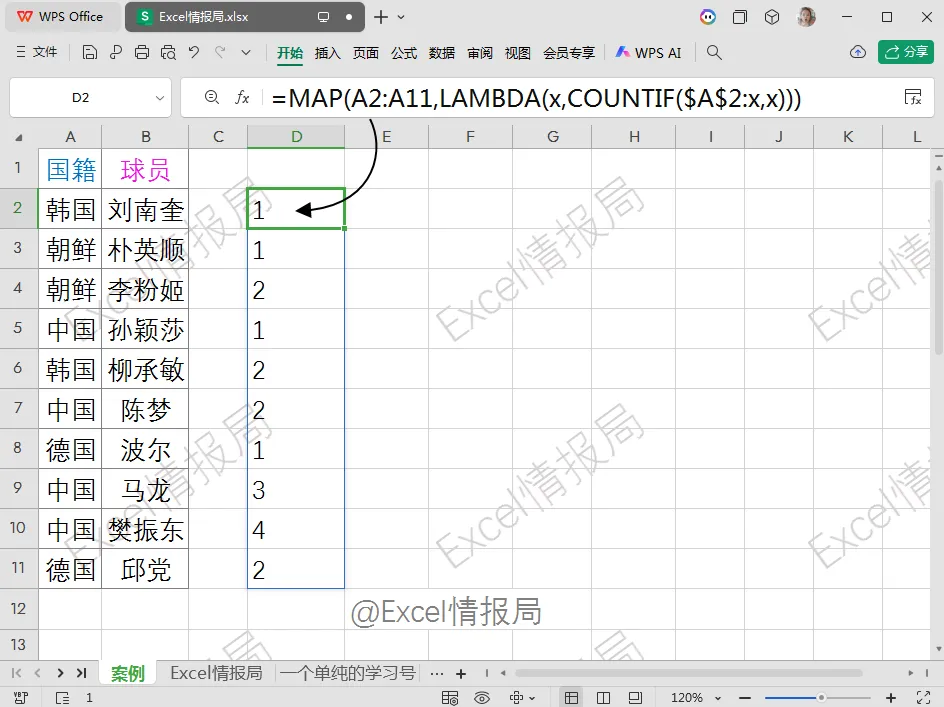
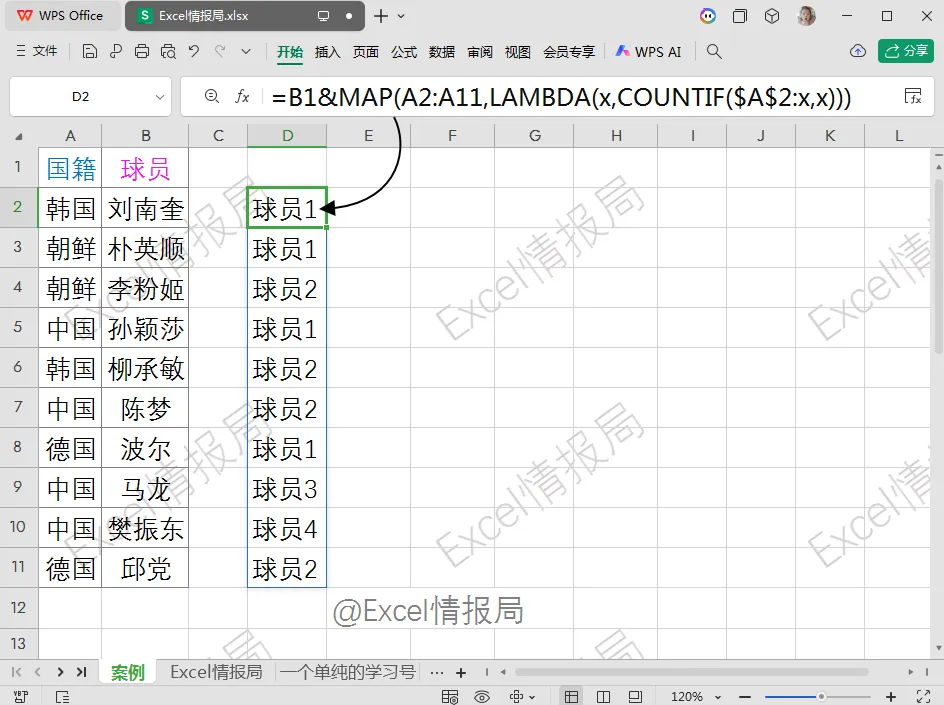
=B1&MAP(A2:A11,LAMBDA(x,COUNTIF($A$2:x,x)))
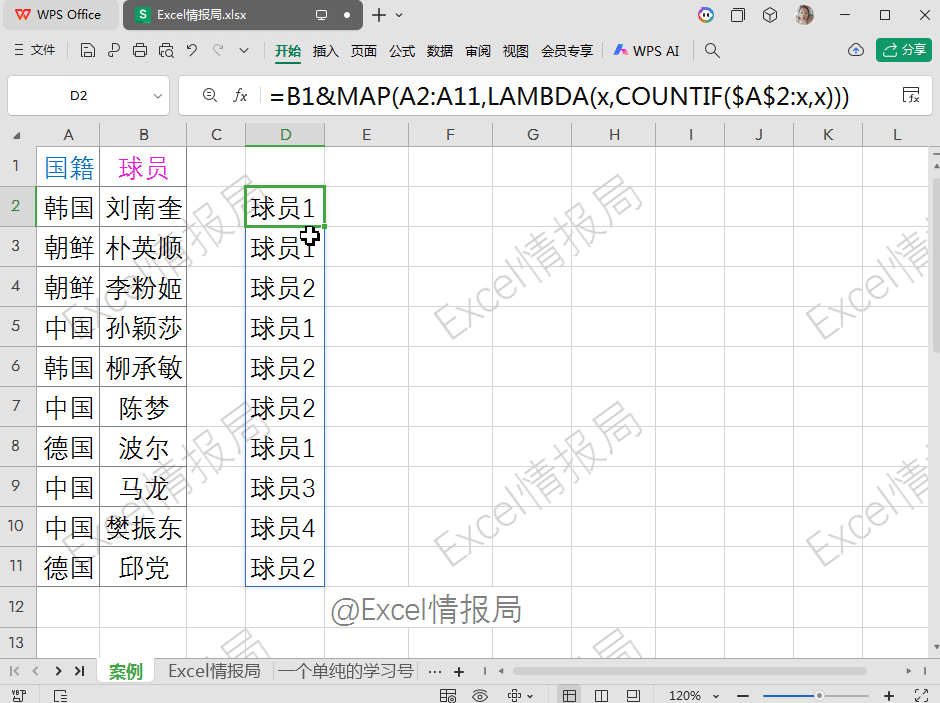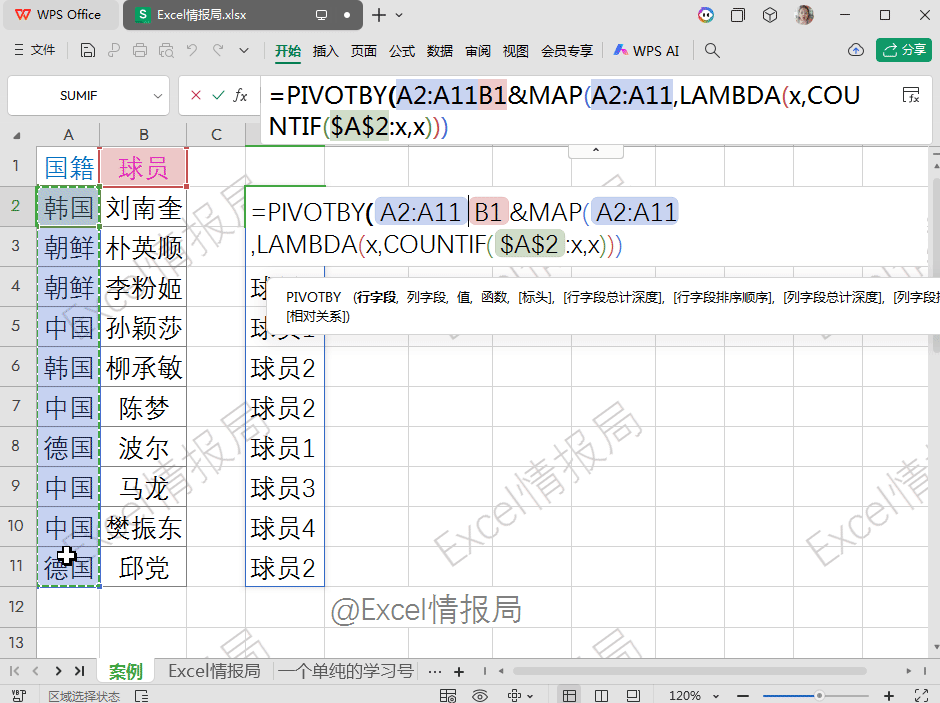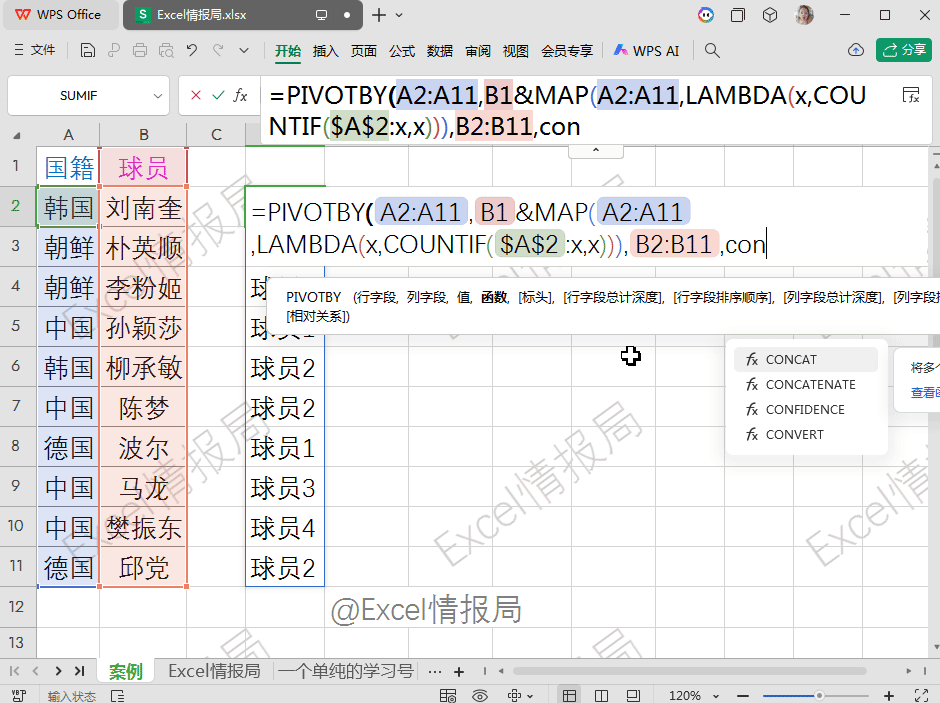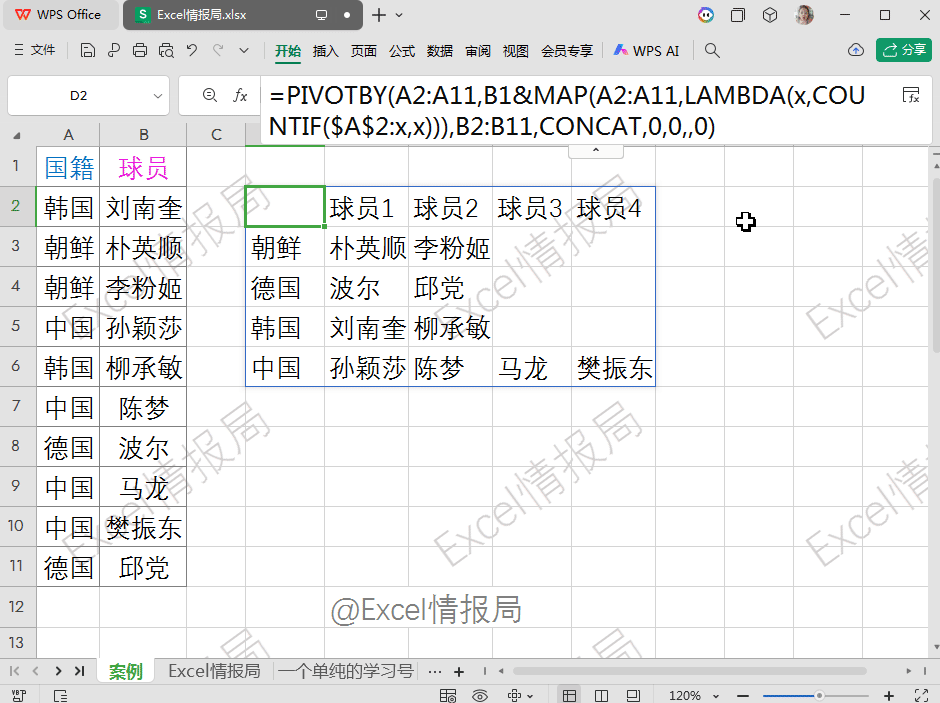
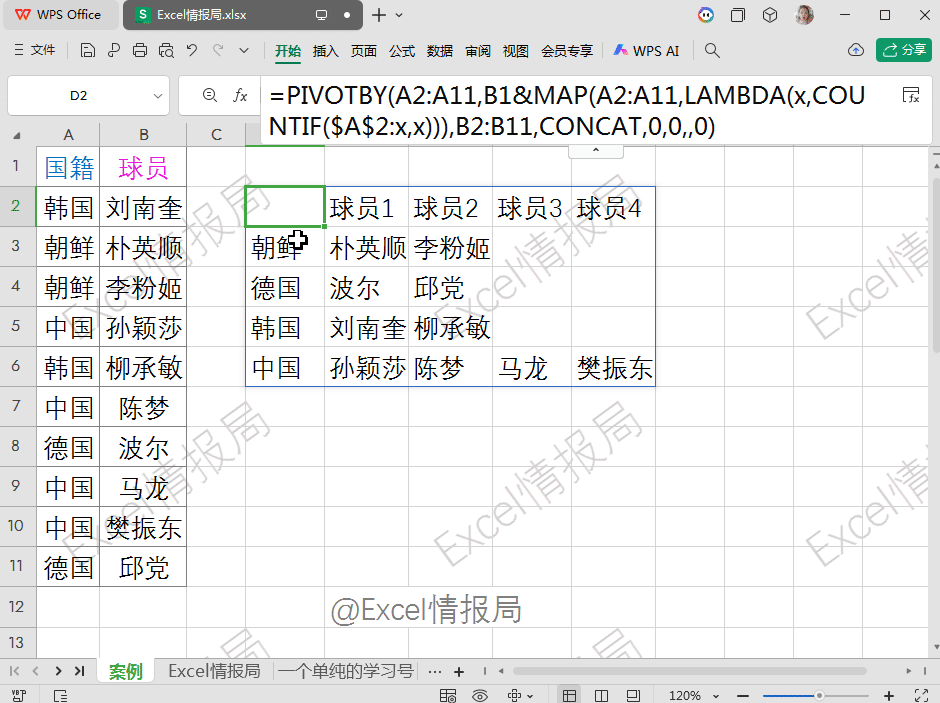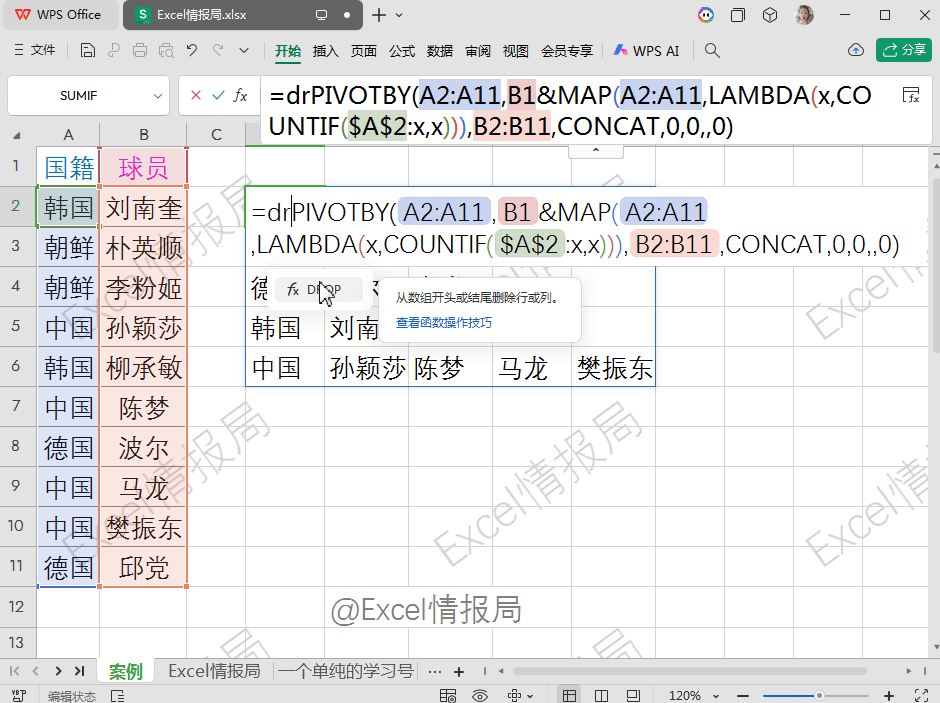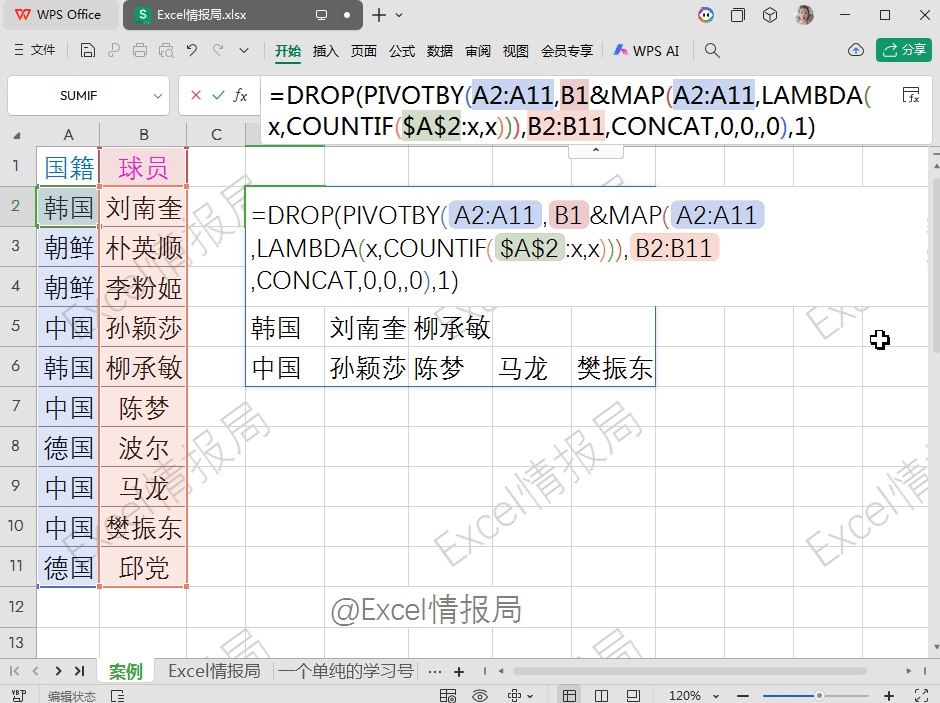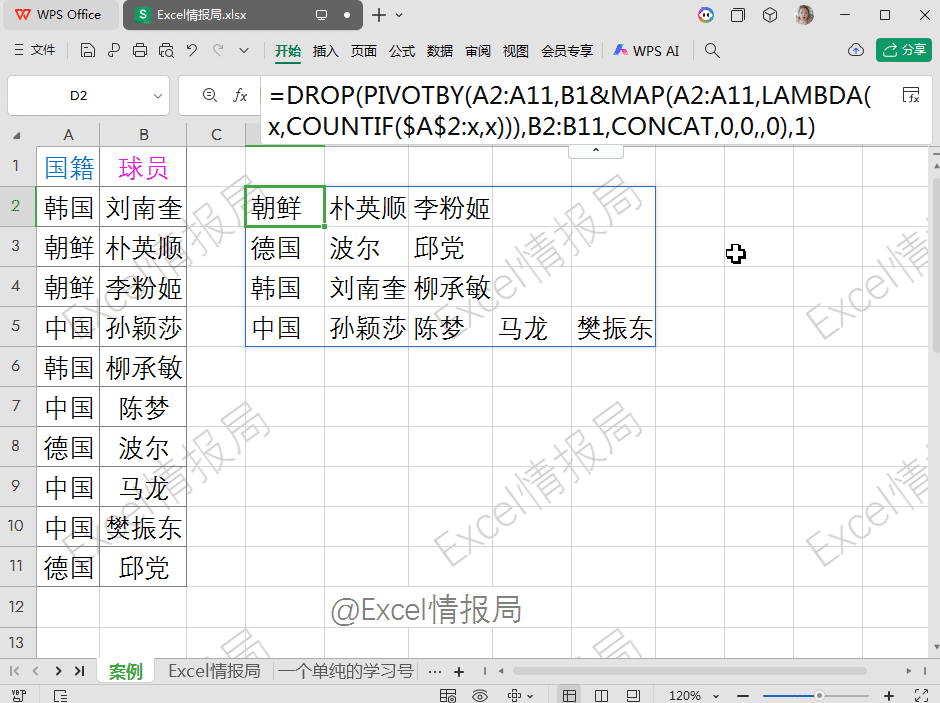
=PIVOTBY(A2:A11,B1&MAP(A2:A11,LAMBDA(x,COUNTIF($A$2:x,x))),B2:B11,CONCAT,0,0,,0)
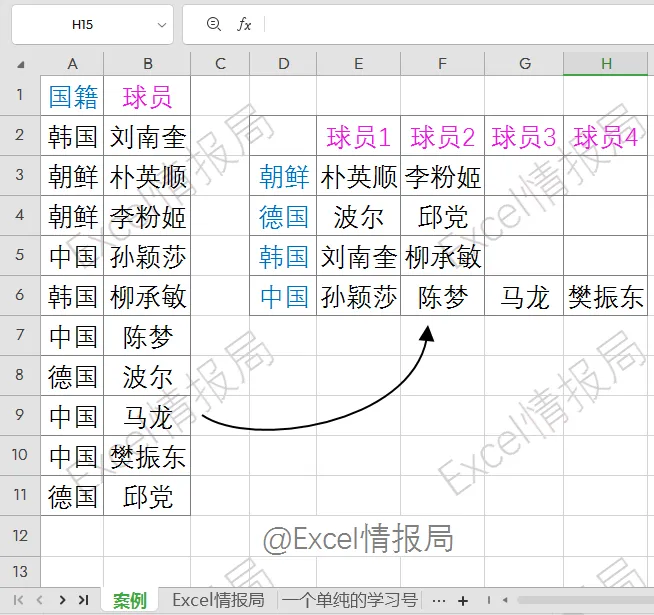
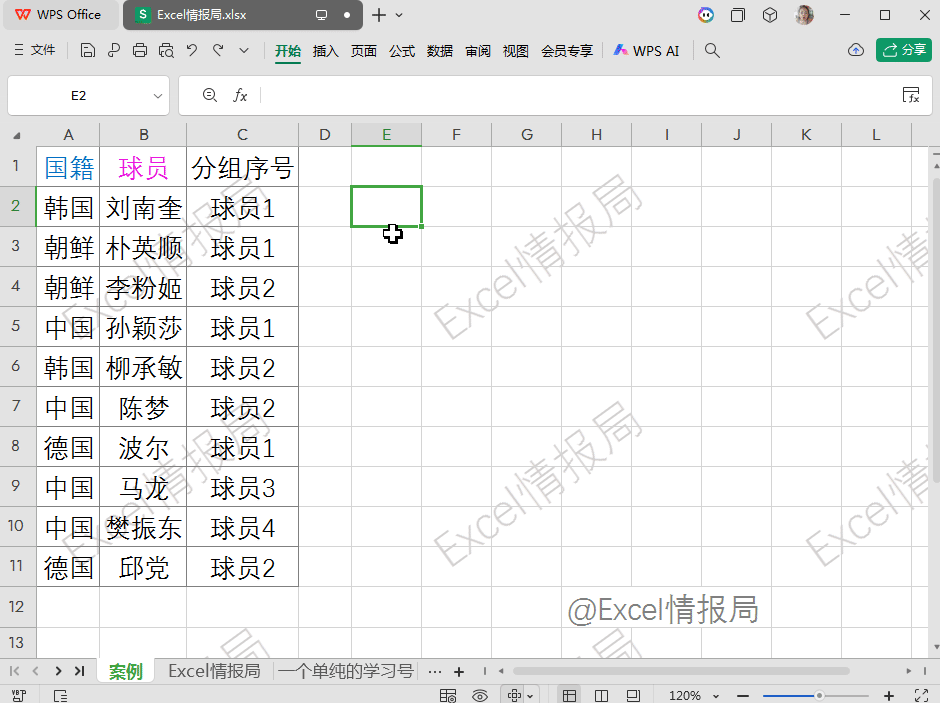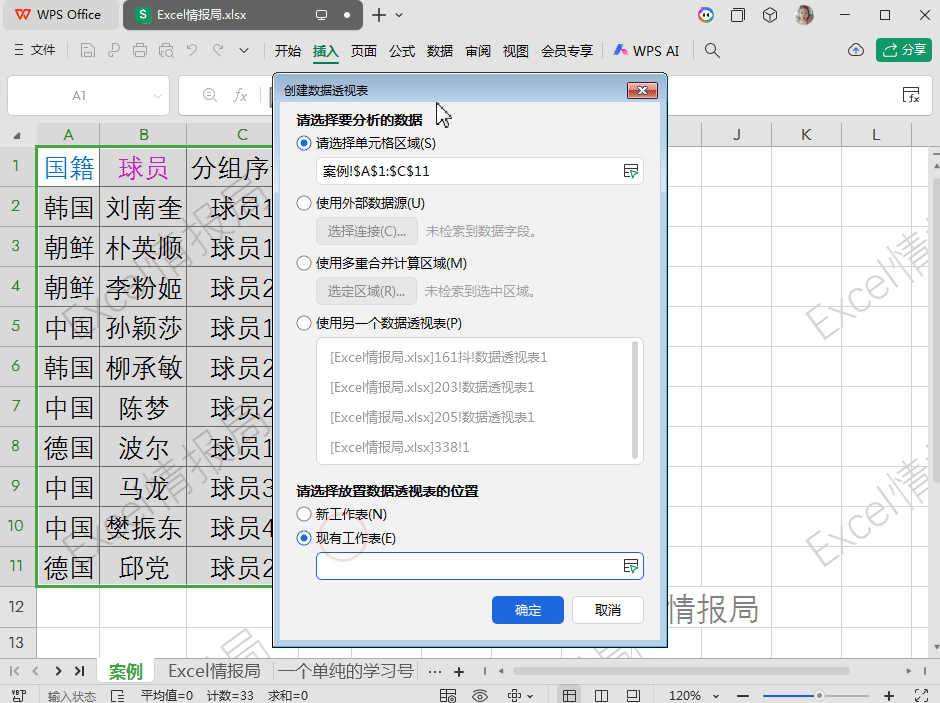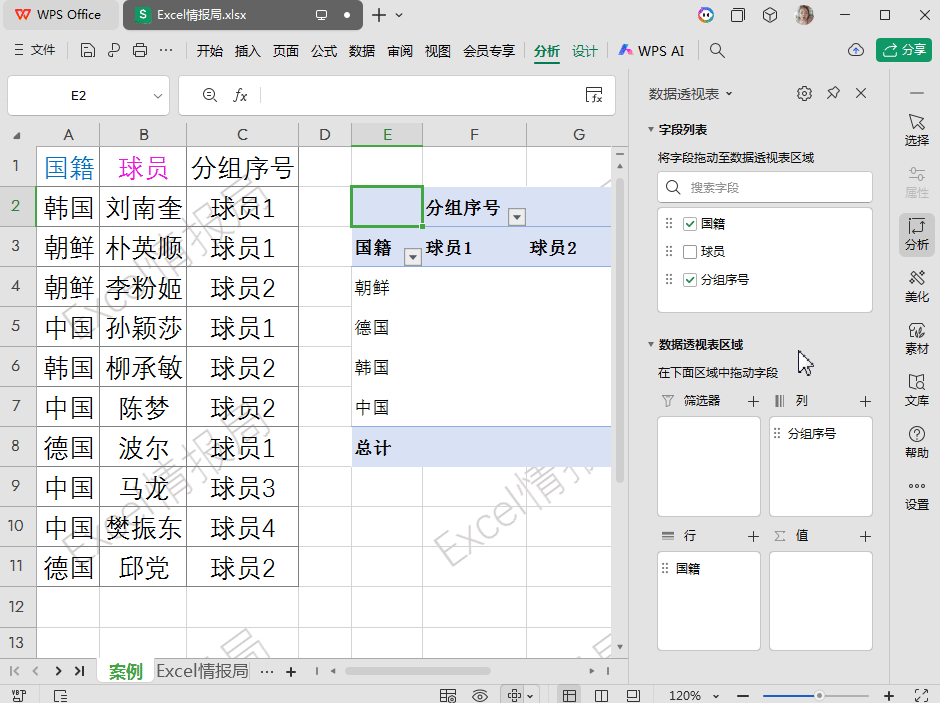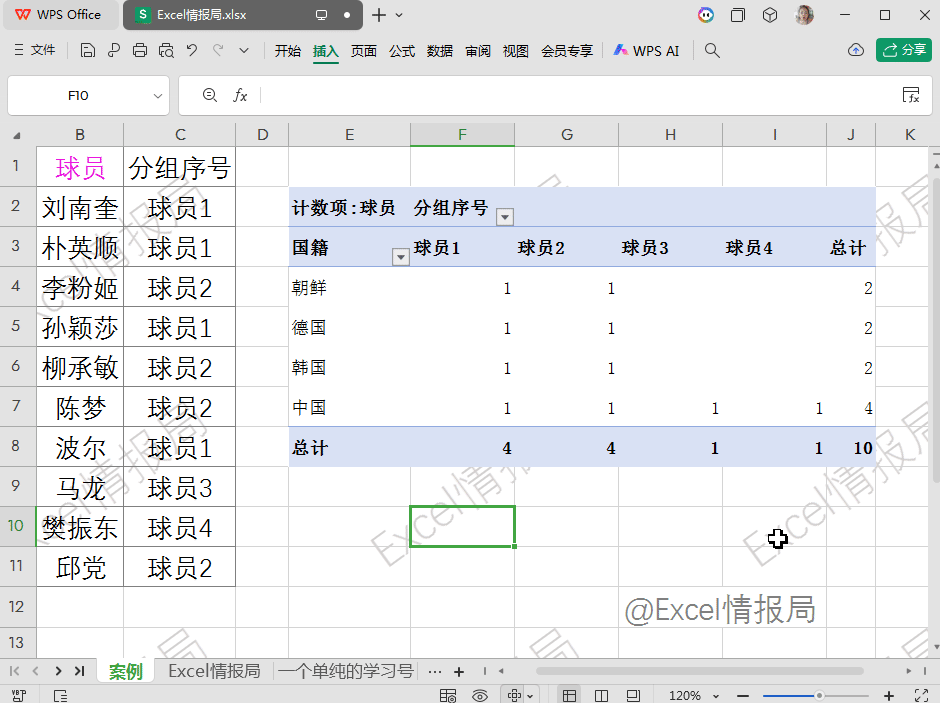
第1参数:A2:A11,行分组依据:按“国籍”分组。
第2参数:B1&MAP(...),列分组依据:按“球员1”“球员2”…分组。
第3参数:B2:B11,要聚合的值:球员姓名。
第4参数:CONCAT 聚合函数:将同一单元格内的多个姓名拼接。本例中每个国家每个编号只对应一个球员,实际也可用于合并重复项。
第5参数:0无标头。
第6参数:0无总计行。
第7参数:跳过,默认按行字段首列升序。
第8参数:0无总计列。
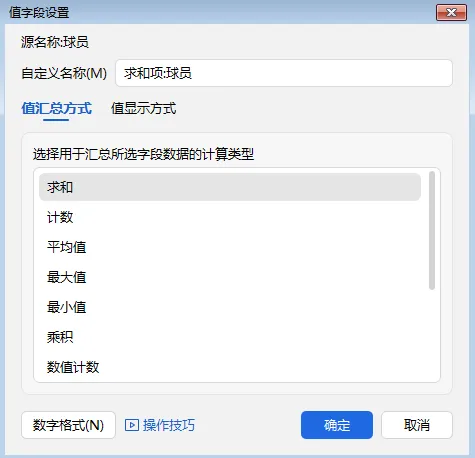
求和(Sum)
计数(Count)
平均值(Average)
最大值(Max)
最小值(Min)
乘积(Product)
数值计数(Count Numbers)
标准偏差(StDev)
总体标准偏差(StDevp)
方差(Var)
总体方差(Varp)
非重复计数(Distinct Count)
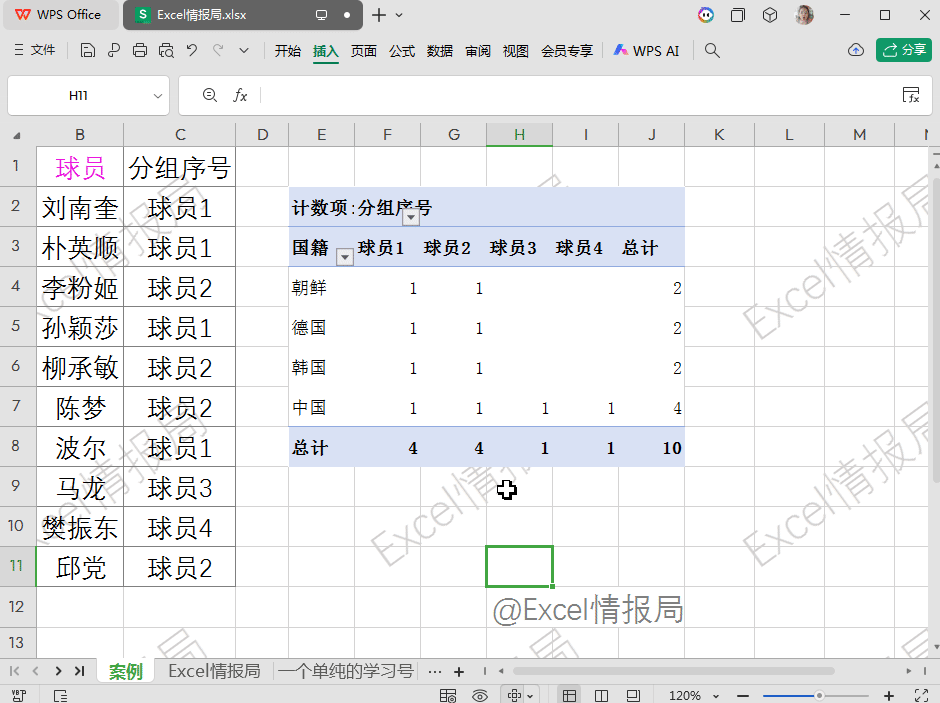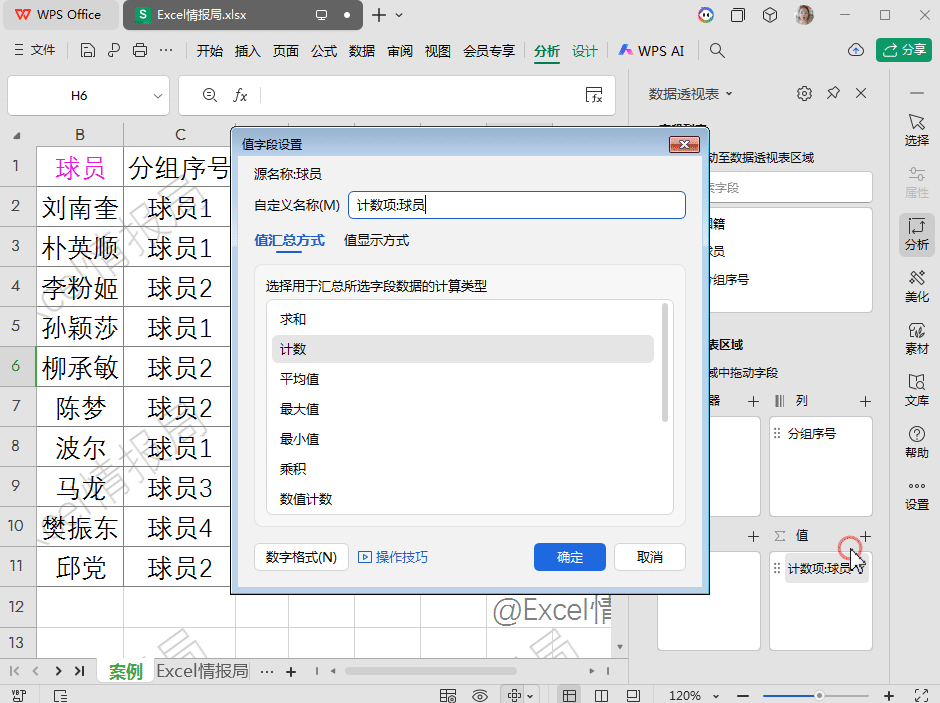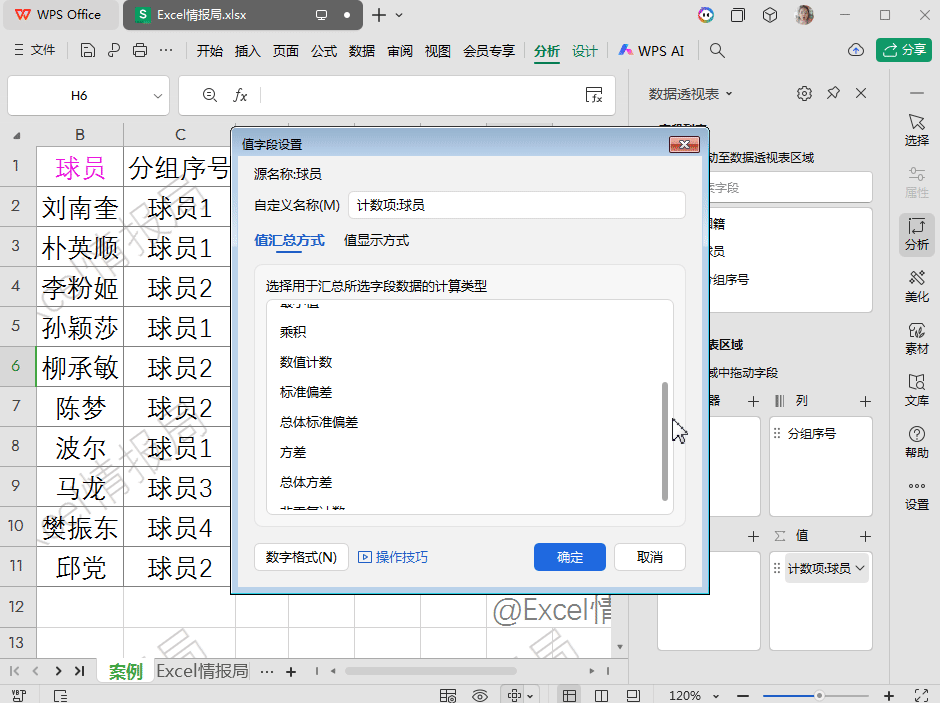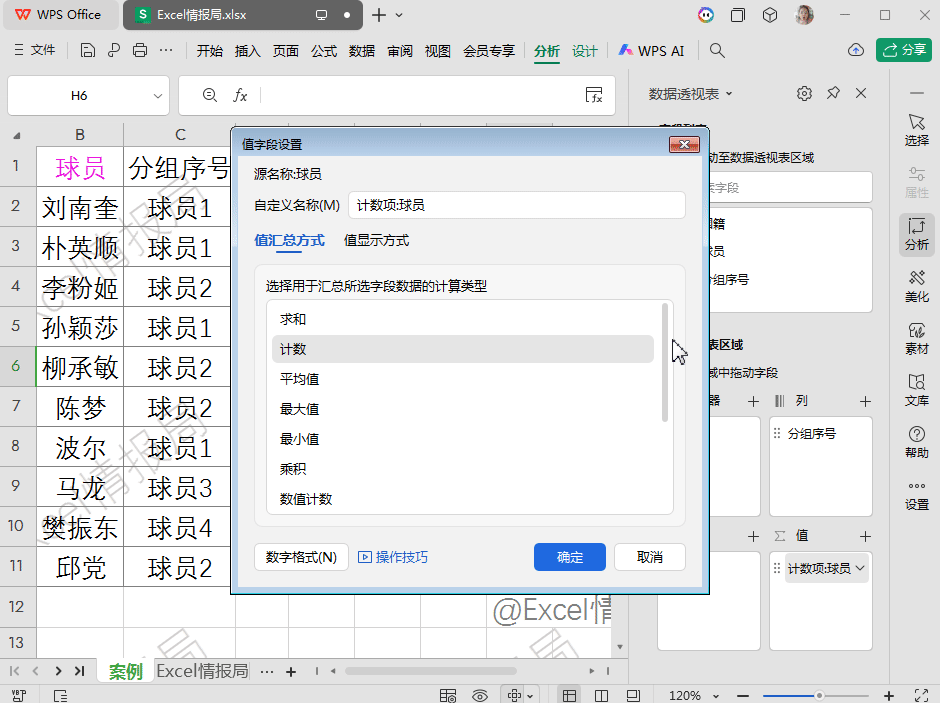
PIVOTBY函数的聚合计算方式在灵活性和功能上相比传统数据透视表有显著扩展。
PIVOTBY支持通过lambda函数自定义复杂的聚合逻辑,自定义聚合函数。例如文本合并、条件统计等。PIVOTBY函数通过公式化操作,突破了数据透视表在灵活性、动态性和复杂计算方面的限制,更适合自动化、动态数据处理场景。=DROP(PIVOTBY(A2:A11,B1&MAP(A2:A11,LAMBDA(x,COUNTIF($A$2:x,x))),B2:B11,CONCAT,0,0,,0),1)
DROP(...,1)
表示删除第1参数返回结果的第1行。





随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 别再只会Excel!9 种数据分析方法小白也能学会
- NanoBanana2一键美化Excel图表,你还不会就out啦!(附10个AI提示词)
- excel统计表小程序,内附学员获奖情况汇总统计,仅供参考
- excel统计表小程序,内附学员获奖情况汇总统计,仅供参考
- 当你的手机里住了个“量子大脑”:Excel如何算出那每秒10万亿次的算力革命?
- 当你的手机里住了个“量子大脑”:Excel如何算出那每秒10万亿次的算力革命?
- 如何压缩数据较大的 Excel 表格使文件体积减小?
- 如何压缩数据较大的 Excel 表格使文件体积减小?
- 原来Excel可以这么爽!高效函数全在这
- 每天加班处理 Excel?我用 Python 3 分钟搞定,同事都惊呆了
