中科院 PPTAgent V2 重磅更新:从套模板到无模板自由生成!DeepPresenter 刷新行业榜单,渲染后实时纠错改代码
- 2026-05-20 18:32:11
请在微信客户端打开
▋ 推荐阅读:
Meta 杀疯了!VecGlypher 用 LLM 一步生成矢量字体,两阶段训练配方,彻底解决 SVG 生成痛点重构字体设计范式
基于 OpenClaw 的移动端重构:ClawMobile 来了,跨 App 复杂任务 100% 搞定,让手机 Agent 彻底本地跑起来
开源修图模型的新卷王?爆肝清洗16亿训练数据!只为教AI‘P图’:小红书 FireRed 开源即:死磕‘精准控制’,支持本地部署
CVPR2026开源的 3D 重建神器,手机拍的照片就能用。Adobe开源新作 tttLRM:打破 Transformer 瓶颈,线性复杂度实现大场景 3D 重建
端侧 AI 的王炸!Mobile-O 正式开源:不卷云端大参数,1.6B 实现理解生成一体化,手机 3 秒出图
浙大开源Fuse3D!多图生 3D,20 秒出精准模型:多图融合 + 自动对齐,把 “局部编辑” 做到极致
字节开源 OpenViking:彻底重构 Agent 内存,RAG 时代要结束了?
帮写PPT、核对发票、搞科研,港大/理大InfiAgent V3开源:靠“外置记忆”实现长跑,比对话框更务实的“全流程数字员工”。
42k小时数据+零样本!SoulX-Singer开源:中英粤三语自由切换,歌词随意改,音色随便换,AI歌声合成’准’到离谱”
9B小钢炮!面壁MiniCPM-o 4.5焕新升级:能在Mac跑的全模态AI,边看视频边聊天,还能克隆声音

资源导航:
这几天,PPTAgent V2(及其背后的学术框架 DeepPresenter)的开源代码和技术论文更新了。
现在的多模态大模型写文章是一把好手,画单张的插图也挺惊艳,但只要你让它生成一份排版规整、逻辑清晰、图文并茂且可以直接编辑的幻灯片(PPT),它往往会表现出一种“偏科”的固执。要么给你一堆纯文本大纲让你自己去填,要么生成的页面元素重叠、文字溢出,甚至排版风格千篇一律。
这次 PPTAgent V2 的更新,其实提供了一个相当务实且具有工程启发性的解法。
一句话总结:这是一个不套用固定模板、采用双智能体(研究员+演示员)打配合,并且懂得“一边看渲染效果一边改代码”的幻灯片生成系统。

老规矩,咱们先扒一扒它背后的技术细节(Paper/Repo双重解析),看看它底层的 Infra 和模型协同是怎么设计的,再看实测效果和本地部署怎么玩。
在聊 V2 之前,简单提一嘴背景。这个项目组之前在 EMNLP 2025 发表了 PPTAgent V1 的论文,在 GitHub 上也揽获了 1000+ 的 Stars。
V1 时期的做法比较像我们人类的“打工人思维”:它采用的是一种基于编辑(Edit-based)的方法。给定一篇文档,V1 会先去分析一个高质量的“参考演示文稿(Reference Presentation)”,把里面优秀的幻灯片提取成各种 Schema(大纲/版式),然后通过代码调用(API),把新文档的内容“塞”进这些旧的优秀版式里。
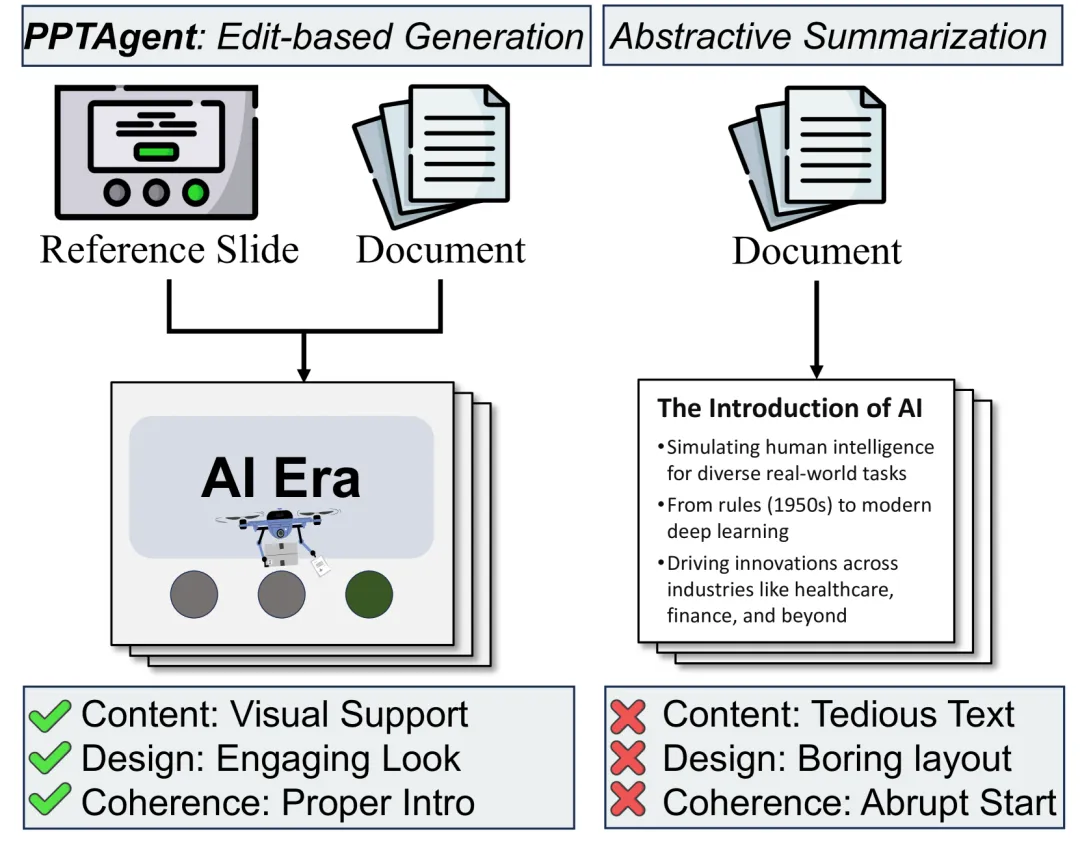
(图片来源:PPTAgent 论文 Figure 1。左侧为 V1 采用的基于参考幻灯片编辑的生成方式,右侧为传统的摘要生成方式。)
这种方法虽然比纯文本生成靠谱,但也带来了局限性:严重依赖参考模板的质量,遇到跨领域的复杂需求时,排版容易受限。
于是,PPTAgent V2(对应 DeepPresenter 论文) 选择了另起炉灶,彻底抛弃了固定模板,走向了 无模板自由生成(Free-form) 和 环境反馈反思(Environment-Grounded Reflection) 的路子。
身份定义:它现在是谁?
PPTAgent V2 是一个协调了两个专业化智能体的框架,通过共享的沙盒环境(文件系统)进行协作生成任务。你可以把它理解为一个微型的“数字内容工作室”。
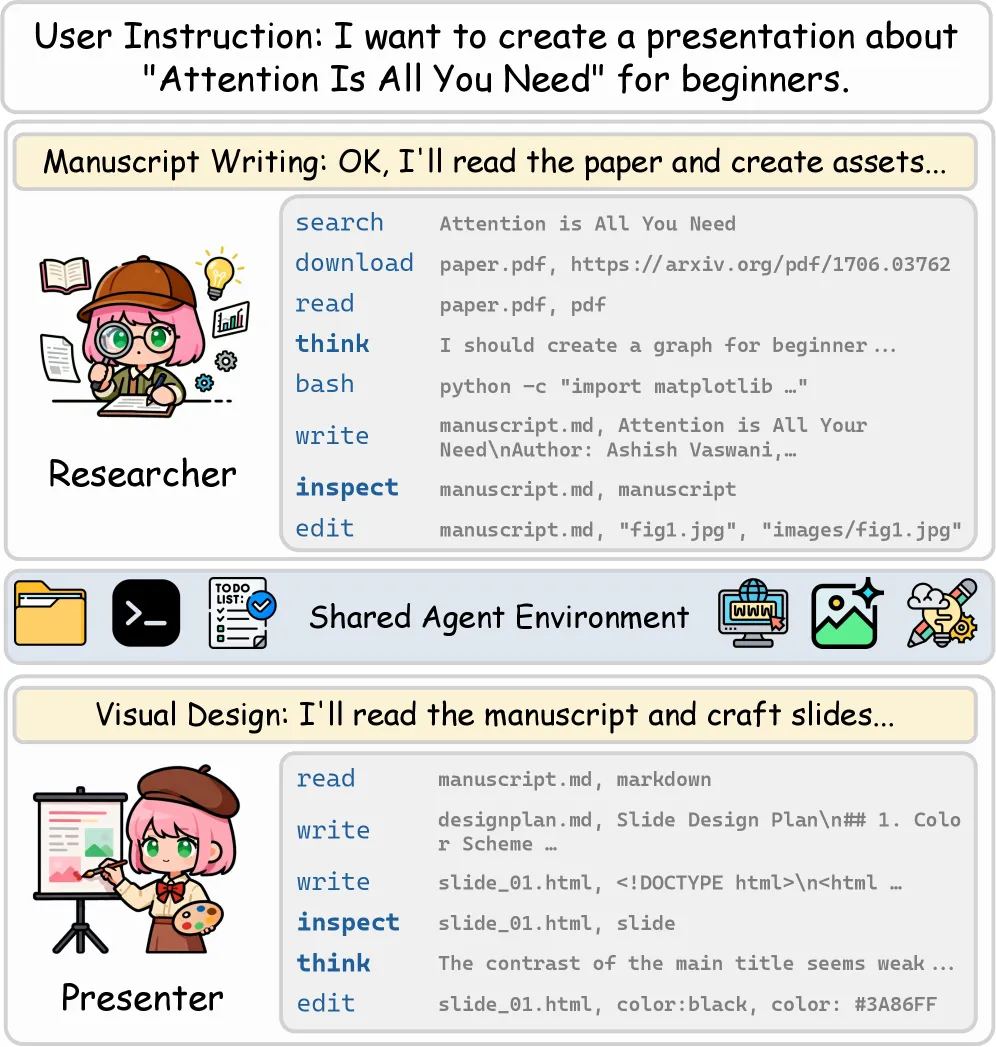
(图片来源:DeepPresenter 论文 Figure 1。展示了双智能体协作流程:Researcher 负责查资料写 Markdown 手稿,Presenter 负责将手稿转换为视觉幻灯片,双方在共享环境中协作并反思修正。)
核心创新点 A:双智能体解耦与深度研究(Deep Research)
描述:它怎么处理复杂需求?系统将“查资料/写大纲”和“做排版/写代码”这两件事分给了两个不同的 Agent。
• Researcher Agent(研究员):不按照预设死板的工作流走,而是根据你的指令,自主调用检索工具(连网搜索、arXiv 查论文等),然后把零散的信息综合起来,写成一份带有叙事张力、结构化的 Markdown 手稿(Manuscript)。如果发现缺图,它还能调用工具去下载或生成图片素材。 • Presenter Agent(演示员):拿到 Markdown 手稿后,它不去找模板套,而是从零开始(from scratch)制定全局的视觉设计方案(比如根据环保主题设定大地色系,或者为学术汇报设定极简网格)。接着,它会一页一页地写 HTML/CSS 代码,把内容转换成幻灯片。
行业对标:现在“多智能体分工”在复杂任务上算是基操了。但把它专门用在长文本到复杂视觉结构的转换上,并且开放这么细颗粒度的工具链,在目前开源的 PPT 生成库里属于完成度较高的。 解决了什么:缓解了以往模型“写的内容没深度”或者“排版与内容调性不符”的问题。
核心创新点 B:环境锚定的反思机制(Environment-Grounded Reflection)
描述:这是 V2 版本里技术含金量很足的一个点。它专门加强了模型对后期渲染缺陷的感知和纠错能力。 细节:传统的大模型在写代码时,也会做“自我反思(Self-reflection)”。但问题是,对于网页或 PPT 来说,代码没报错不代表画面好看。文字可能超出了文本框,图片可能把标题挡住了,这些在纯代码日志里是看不出来的。 为了解决这个状态错位(State mismatch),团队引入了一个叫 inspect 的工具。当 Presenter 写完一页 HTML 后,系统会在后台用无头浏览器把它渲染成真实的像素图片。模型此时会“看”到这张图片,发现“哎呀,主标题对比度太低看不清”,或者“文字溢出了”,然后生成具体的修改指令回去改代码。
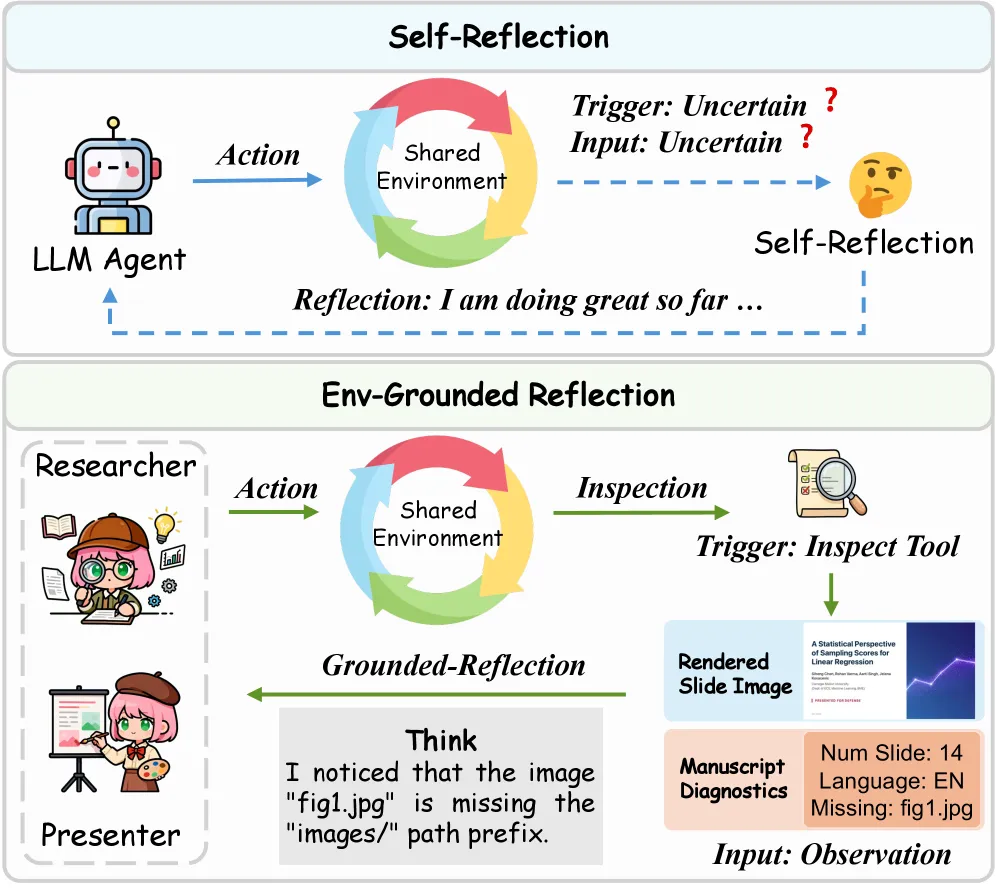
(图片来源:DeepPresenter 论文 Figure 2。上半部分是传统的盲目自我反思,下半部分是引入 inspect 工具后的环境锚定反思,模型能直接看到渲染后的视觉缺陷并进行修正。)
(这个机制其实点出了当前多模态发展的一个方向——让模型具备“物理/视觉沙盒”的感知能力,而不是仅仅在抽象的文本符号层面上做逻辑推演。)
论文中有一个关于数据合成与模型训练的技术点值得展开讲讲,那就是外部验证(Extrinsic Verification)。
概念引入:在训练智能体时,我们通常会让大模型自己生成轨迹(Trajectories),然后自己检查。但这会带来一个叫“自我验证偏差(Self-verification bias)”的问题——模型往往会过度自信,觉得“老子写的代码完美无缺”,从而放过很多明显的排版错误。
原理解析(举例法): 本来只需要让大模型检查一下自己生成的幻灯片,现在它会找一个“独立的裁判(Critic)”来挑刺。就像大家常说的“旁观者清”,这个独立的 Critic 不在生成的上下文状态里,它只看最终的图片和需求。 如果 Critic 发现背景色和文字颜色太接近(比如白底浅灰字),它会生成一段逻辑清晰的推理轨迹(Reasoning Trace):“我注意到这页幻灯片的文字对比度太低,导致阅读困难,我需要将字体颜色调整为黑色。”
项目团队把这些高质量的“挑刺与修正”轨迹收集起来,构建了一个包含 802 条极高质量轨迹的数据集。
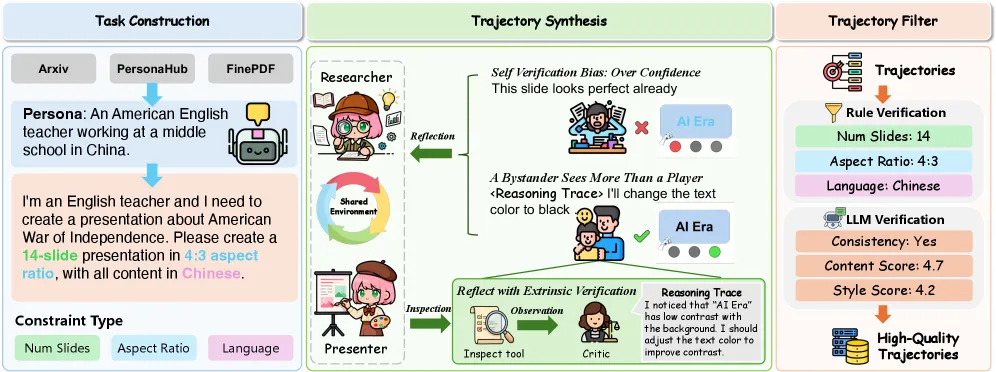
(图片来源:DeepPresenter 论文 Figure 3。展示了通过引入独立的 Critic 进行外部验证,从而合成高质量修正轨迹的流水线。)
降本增效的体现(DeepPresenter-9B): 用 GPT-4o 或者 Gemini-3-Pro 跑这套双智能体流程,API 账单是相当可观的。于是团队做了一件很有开源精神的事:他们用上述过滤后的高质量数据集,去微调了一个相对小参数的开源多模态模型(GLM-4.6V-Flash),得到了 DeepPresenter-9B。
测试数据显示,这个仅有 9B 参数的蒸馏模型,在幻灯片生成的综合评分上不仅超越了所有未经微调的开源大模型,甚至在效率和成本大幅降低的前提下,性能逼近了旗舰级的专有模型。这就为中小型企业或者个人开发者进行本地化部署铺平了道路。
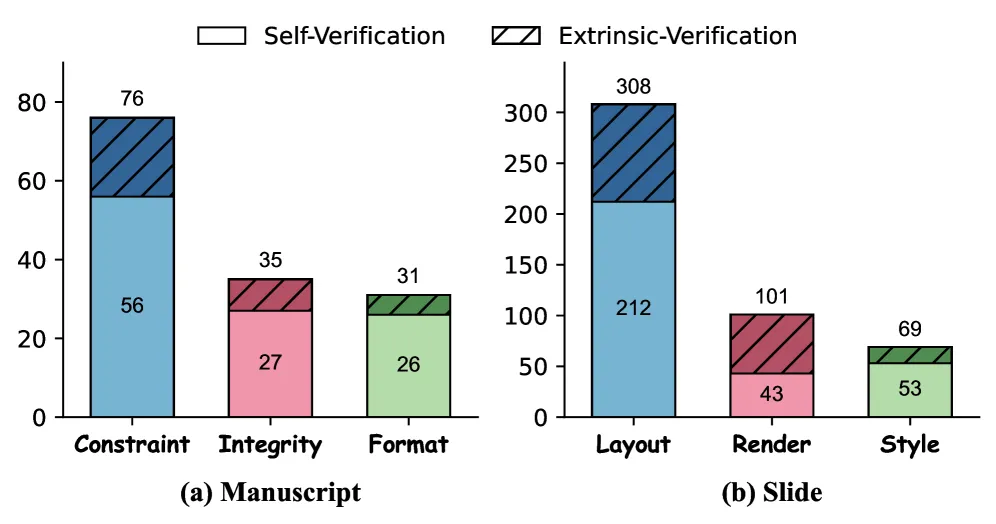
(图片来源:DeepPresenter 论文 Figure 4。对比了自我验证和外部验证在发现缺陷上的数量差异。明显看出外部验证(蓝色/红色条)能捕捉到更多隐藏的布局和渲染错误。)
在 GitHub 的 Repo 中,PPTAgent V2 已经提供了比较完整的工具链和部署方案。内容聚焦于它的工程实践:
1. 沙盒环境与 20+ 工具库(Tools)
PPTAgent V2 不仅仅是一个对话框,它为模型提供了一个包含 20 多种工具的沙盒环境(Agent Environment)。主要分为几大类:
• 检索(Retrieve):包含 search_web,search_papers,fetch_url等。如果你的主题比较前沿,模型会自己去网上爬取最新的资料补充到手稿里。• 文件操作(File):读写、移动文件。生成的 Markdown 和 HTML 文件都在这里流转。 • 审查(Reason):前文提到的核心工具 inspect_slide(将HTML转成像素图供视觉审查)和inspect_manuscript。• 生成(Create): image_generation。当网上找不到合适的配图时,模型会调用文生图接口自己画一张(Text-to-Image Generation),这提升了图文并茂的程度。
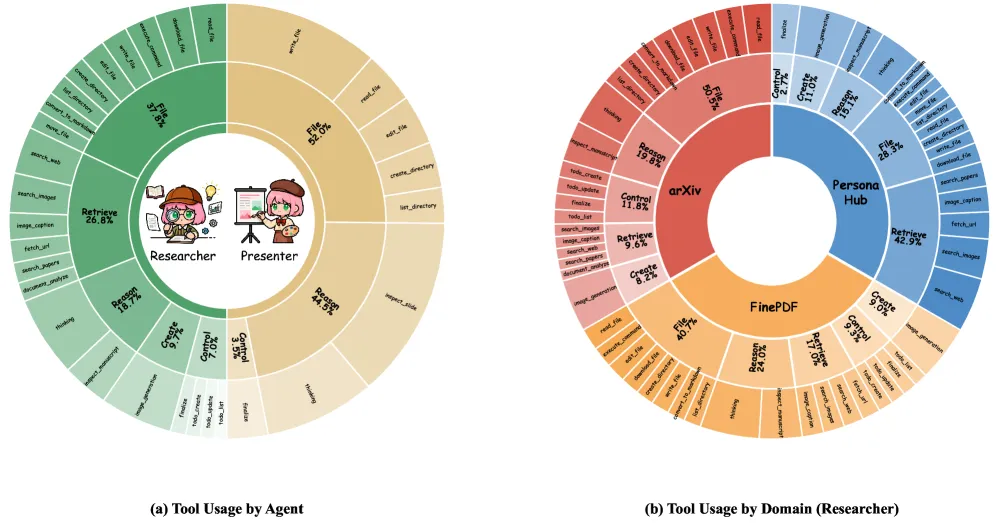 (图片来源:DeepPresenter 论文 Figure 8。展示了 Researcher 和 Presenter 在实际任务中调用不同工具的频率分布,可以看出两者分工非常明确。)
(图片来源:DeepPresenter 论文 Figure 8。展示了 Researcher 和 Presenter 在实际任务中调用不同工具的频率分布,可以看出两者分工非常明确。)
2. 本地部署与离线模式(Offline Mode)
考虑到企业内部文档的隐私安全,V2 版本对本地部署非常友好:
• 环境配置:官方建议使用 Python 3.11 和 Conda 进行环境隔离。通过 config.yaml配置各类 API Keys(如无头浏览器的依赖、LLM 接口等)。• 离线解析支持:支持接入 MinerU。如果你有本地的 PDF 报告需要转成 PPT,可以在内网部署 MinerU 服务,并在配置中开启 offline_mode: true,这样模型在处理时就不会调用依赖外网的搜索工具,纯靠本地解析和本地大模型完成工作。• 导出格式:在底层的 HTML 渲染稳定后,V2 版本已支持将其导出为打工人刚需的 .pptx 格式,不再是只能看不能改的图片。
3. MCP Server 支持(模型上下文协议)
这是一个值得关注的前沿特性。PPTAgent V2 适配了 MCP Server。这意味着你可以把它作为一个标准化的能力模块,挂载到其他支持 MCP 的复杂 AI 工作流系统中,让“生成 PPT”成为更大宏观任务中的一环。
4. 解决上下文溢出(Context Management)
长序列生成有个痛点:模型在不断反思、修改 HTML 代码时,Context Window 很容易爆掉。V2 在工程上加入了显式的上下文管理机制。当累积消耗达到最大限制的 50% 和 80% 时,系统会向 Agent 发出警告,迫使模型调整策略(比如合并修改步骤或加快定稿),提高了生成成功率。
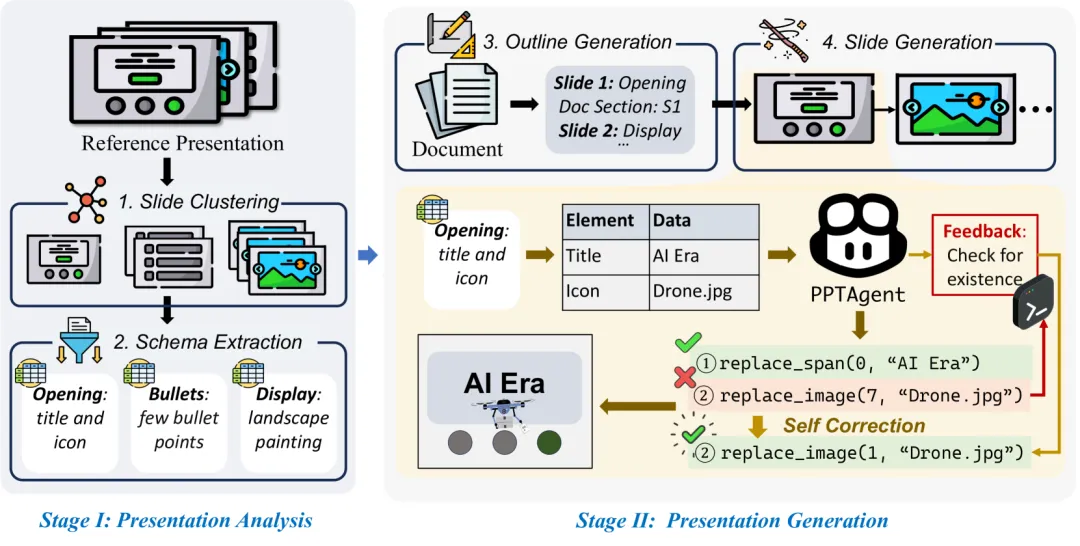
(图片来源:PPTAgent 论文 Figure 2 局部。展示了模型通过类似 replace_span, replace_image 的指令直接与文档元素互动的逻辑基础。)
我们结合论文给出的评测数据(PPTEval 评估框架:从内容、设计、连贯性三个维度打分),将 PPTAgent / DeepPresenter 与市面上常见的几种方案做一个横向对比。
1. 商业闭源代表:Gamma
• 产品特点:目前在 C 端非常流行的产品。操作丝滑,生成速度快。 • 对比表现:Gamma 在连贯性和基础版式上做得很商业化。但在 DeepPresenter 的评估中,Gamma 存在几个问题:一是容易生成“文本密集型(Text-heavy)”的页面;二是严重依赖 AI 生成的装饰性插图,当你给它喂一份非常硬核的学术 PDF 时,它有时会曲解原文档里的架构图。 • 数据参考:在综合评分(Avg)上,Gamma 拿到了 4.36 分。而 DeepPresenter(搭配 Gemini-3-Pro)拿到了 4.44 分。DeepPresenter 在学术或深度文档的处理上显得更“言之有物”。
2. 学术规则/模板基线:DocPres 与 KCTV
• 产品特点:这是两类传统的学术基线。DocPres 是基于规则的,KCTV 则是依赖预定义的格式模板。 • 对比表现:这些方法由于是“单通道”生成,且模板固定,在多样性(Diversity)上得分极低(仅在 0.2-0.3 左右)。也就是说,无论输入什么主题,它们生成的 PPT 看起来都长得差不多。 • 数据参考:DeepPresenter 因为采用了无模板的 Free-form 策略,多样性得分高达 0.79,并且在视觉设计(Style)上拉开了明显差距。
3. 成本与效能的博弈(Pareto 前沿分析)
• 优势与代价:利用 GPT-4o 或 Gemini-3-Pro 去跑双智能体沙盒,能得到高质量的幻灯片,但不可回避的现实是推理成本(API Cost)和耗时较高。它需要经过多次交互、渲染、反思。 • 降本方案表现:如前文所述,DeepPresenter-9B 模型在这种情况下展现出了它的工程价值。它在成本曲线上极大地向左推移,虽然最高上限略逊于 GPT-5 级别的满血调用,但其 4.19 的平均得分依然稳压了开源的 GLM-4.6 甚至部分闭源小模型。
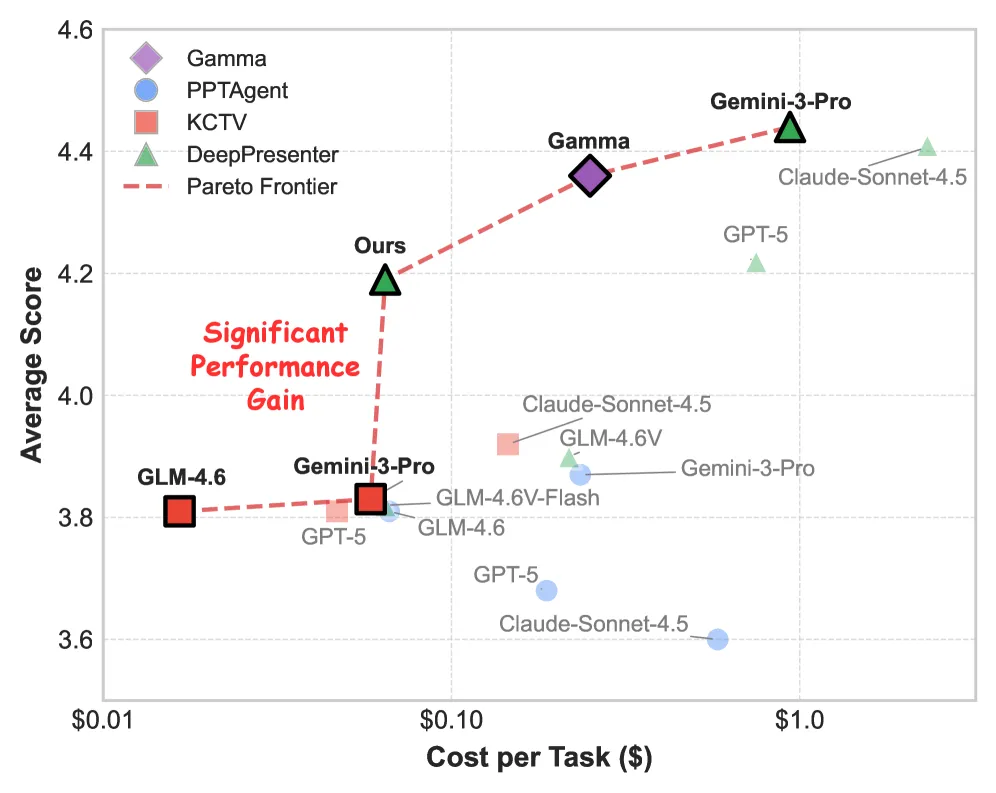
(图片来源:DeepPresenter 论文 Figure 6。展示了各框架和模型在“成本-性能”散点图上的位置。绿色的 DeepPresenter-9B 在较低的成本区间取得了突出的性能,推动了帕累托前沿。)
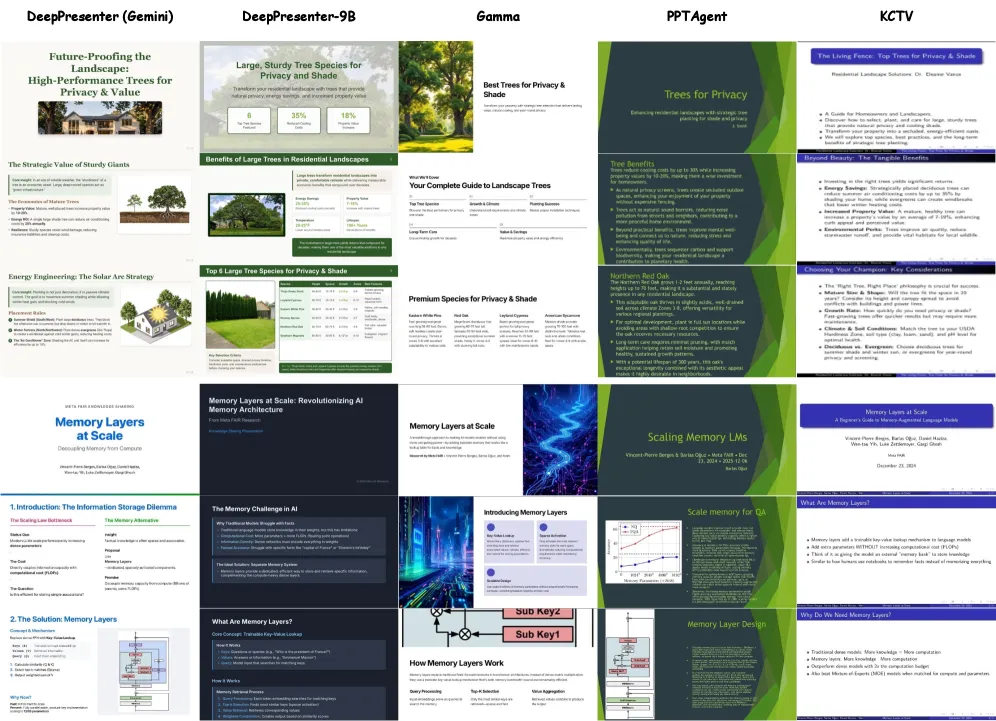
(图片来源:DeepPresenter 论文 Figure 7。定性对比了不同模型生成的视觉效果。可以看出基线方法(右侧)版式僵化,而 DeepPresenter(左侧)能够根据主题生成对应的设计感。)
整体梳理下来,PPTAgent V2(DeepPresenter)的项目逻辑非常清晰。
它没有走“堆砌海量人类 PPT 强行端到端训练”的黑盒路线,而是回归了白盒的智能体工程(Agentic Engineering)。把任务拆解为“搜资料整理手稿”、“编写前端代码”、“渲染后视觉纠错”三个符合人类直觉的步骤,并给模型配齐了工具箱。
这种设计的潜力在于:
1. 它打破了“模板”对 AI 排版创造力的束缚。 2. 环境锚定反思(渲染看图再修改)的方法,可以广泛借鉴到 UI/UX 代码生成、前端报表自动生成等更多对视觉有严格要求的场景中。
同时需要正视的局限性: 论文团队也坦言,依靠多步工具调用和环境渲染,在提升质量的同时也增加了系统的不稳定性。在某些复杂的长序列任务中,依然可能因为环境超时或极端的上下文截断而导致生成失败。未来的优化方向或许在于如何让“外部裁判(Critic)”的验证逻辑在推理阶段以更低成本生效,以及探索更高效的局部重新渲染机制。
对于关注 AI 辅助设计、多模态应用落地或者想要在企业内部搭建本地知识库自动汇报工具的开发者来说,PPTAgent V2 提供了一个架构相当完整的开源参考实现。
如果你手头有空闲的算力,不妨按照官方仓库的 config.yaml.example 配置一下 API,结合 MinerU 试跑几个本地的长篇 PDF。眼见为实,看看如今的开源小模型在有了合理的 Agent 框架加持后,到底能不能替代你做做日常的汇报大纲和粗排版。
请在微信客户端打开

