Excel VSTO 编程 -- 大数据量写入数据库
- 2026-05-17 22:46:50
Excel VSTO 编程 -- 大数据量写入数据库对于将 10 万条记录的 Excel 数据集写入数据库的情况,我们已经讨论过三种实现方案:VBA、Delphi、Python/Pandas。这三种方案的性能对比如下: 
当时,我们认为 Python/Pandas 的方案就是将大型数据集写入数据库的优化方案了。今天我们讨论另外一种实现方案——VSTO 方案。 关于 VSTO,请参看《Excel VBA 编程 -- 四谈保护知识产权》一文。 首先,我们先来看 VSTO 方案的结果: 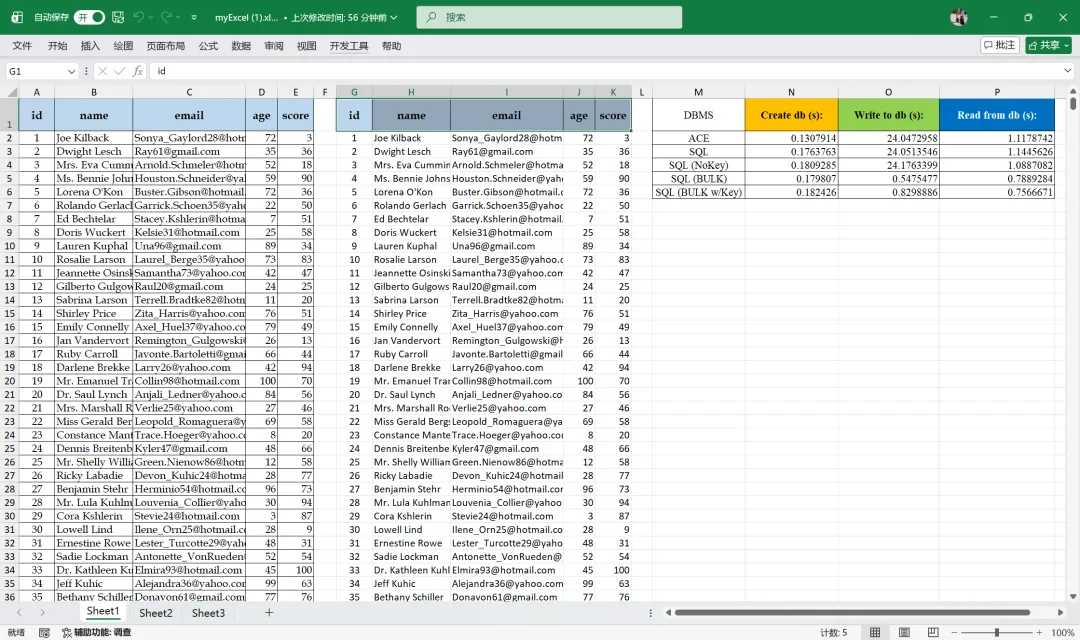
上图中,左侧是原始数据集,中间是的从数据库中读出的数据集,右侧是几种实现方式的对比: 从上图可以看出,前三种实现方式的效率相差不大,后两种方式的效率极高。从四种针对 SQL Server 的实现方式可以看出,有没有 Primary Key,结果相差不大。 下面来看代码。 
我们的项目名称为 MyAddin,所以对应的名字空间也是 MyAddin。创建 MyAddin 项目时,Visual Studio 自动生成 ThisAddIn 类。这个类包含两个事件处理器:一个是加载项加载时的 ThisAddIn_Startup,一个是加载项卸载时的 ThisAddIn_Shutdown。我们在 Startup 事件处理器中调用数据集写入数据库的程序 SqlTest 或 AceTest。 先来看 SqlTest: 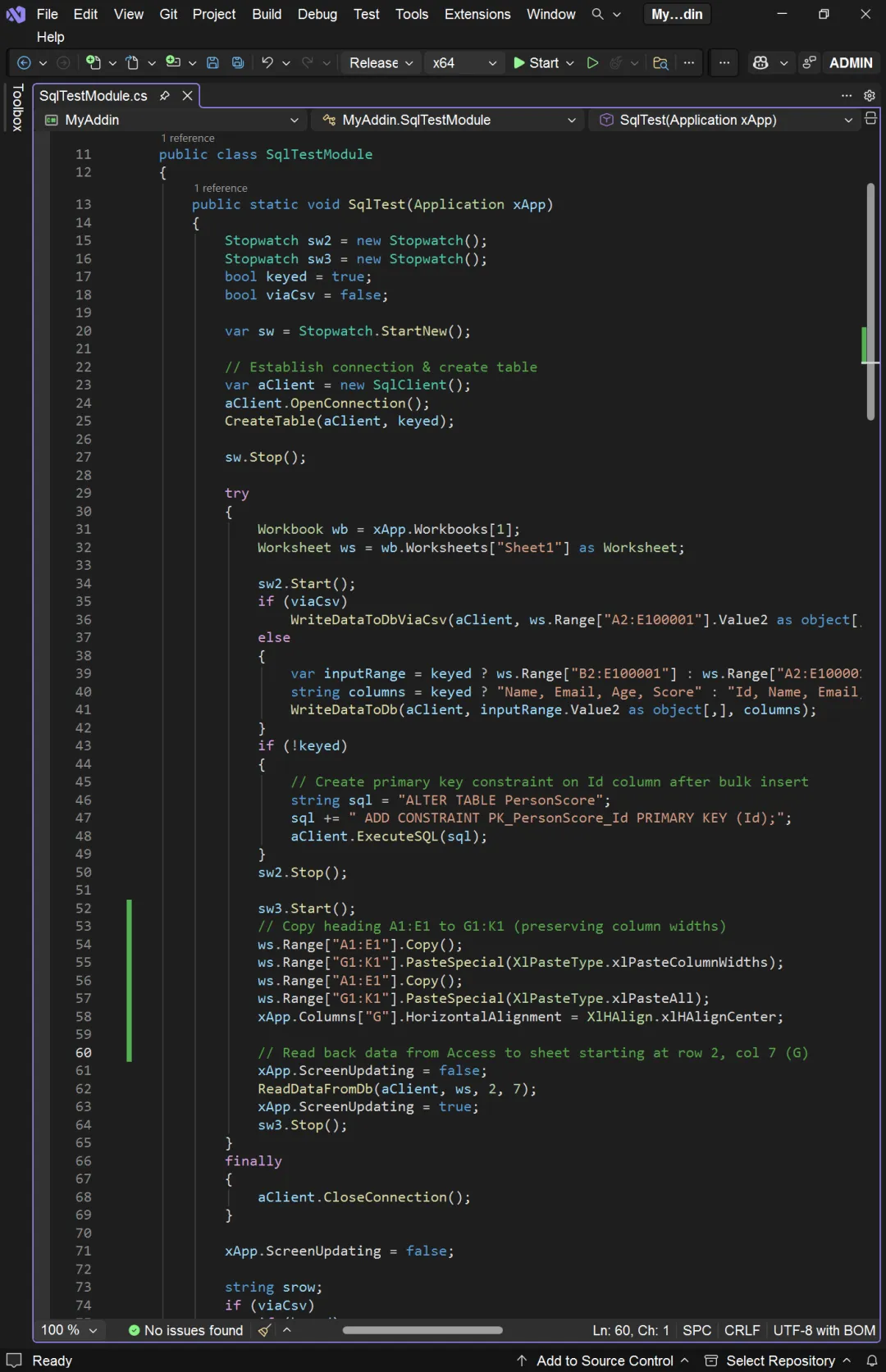
SqlTest 方法包含四个部分: 下面是 WriteDataToDb 的代码: 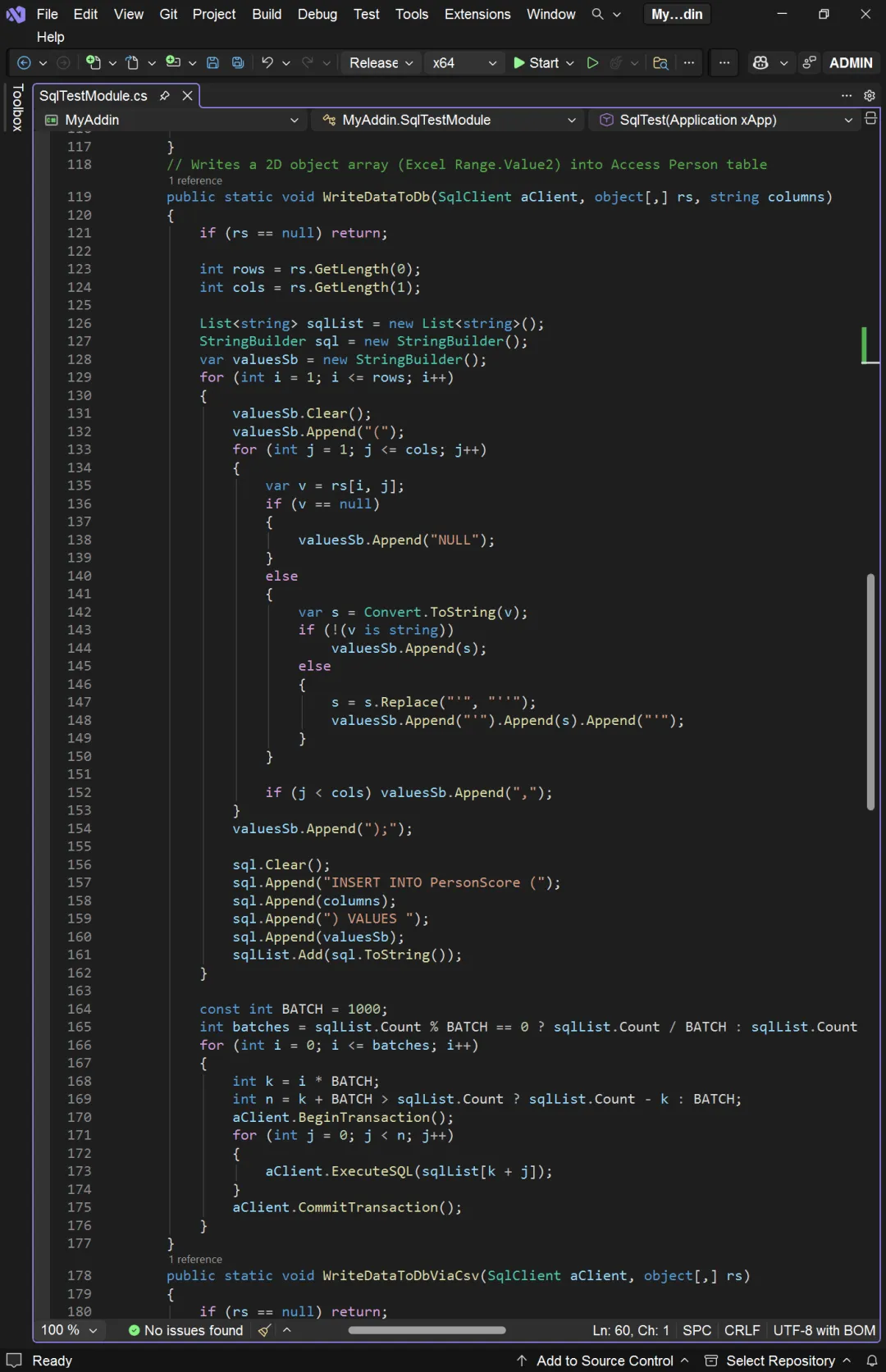
WriteDataToDb 代码中值得一说的,是最后的批量执行部分。我们要写入数据库的数据集有 10 万条记录,会形成 10 条 INSERT INTO 的 SQL 语句。执行大量的 INSERT INTO 语句,需要包括在事务处理语句中批量执行。但数据库引擎执行事务处理时,也不是无限制的,批量也是有“粒度”的,这个“粒度”一般是 5000 至 10000 条 SQL 语句。我们的代码中取为 1000,取 5000 似乎效果更好一些。 下面来看 WriteDataToDbViaCsv: 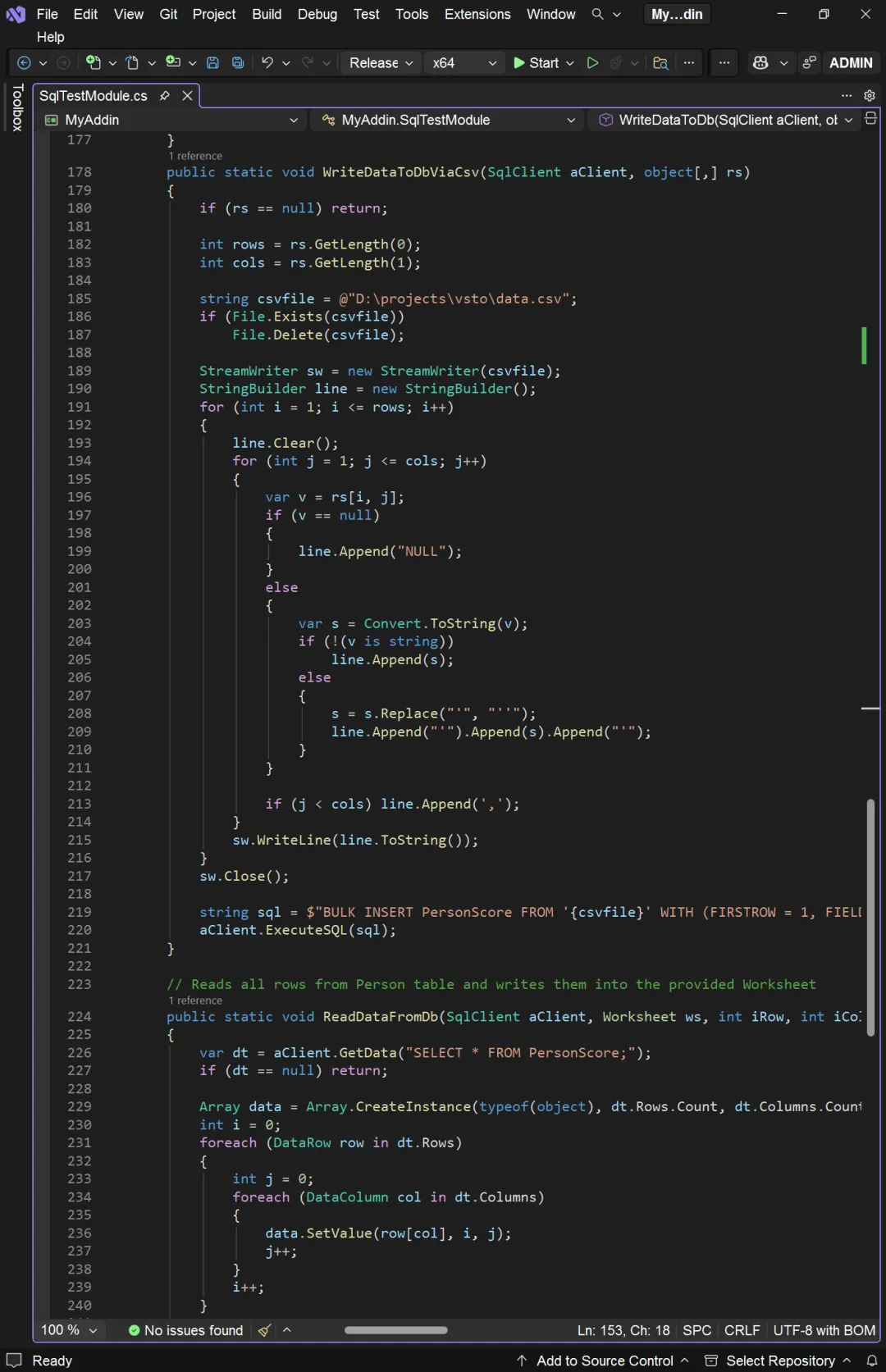
WriteDataToDbViaCsv 与 WriteDataToDb 的不同之处在于,这里不是构造 INSERT INTO 的 SQL 语句,而是将数据记录形成 CSV 格式,写入 .csv 文件。然后执行 BULK INSERT 语句,从 .csv 文件中读取数据,批量写入数据库。从文章开头的测试结果中可以看出,BULK INSERT 的效率极高。所以经常用于海量数据的迁移以及 ETL(Extract, Transform, Load)场景中。 最后是 ReadDataFromDb 的代码: 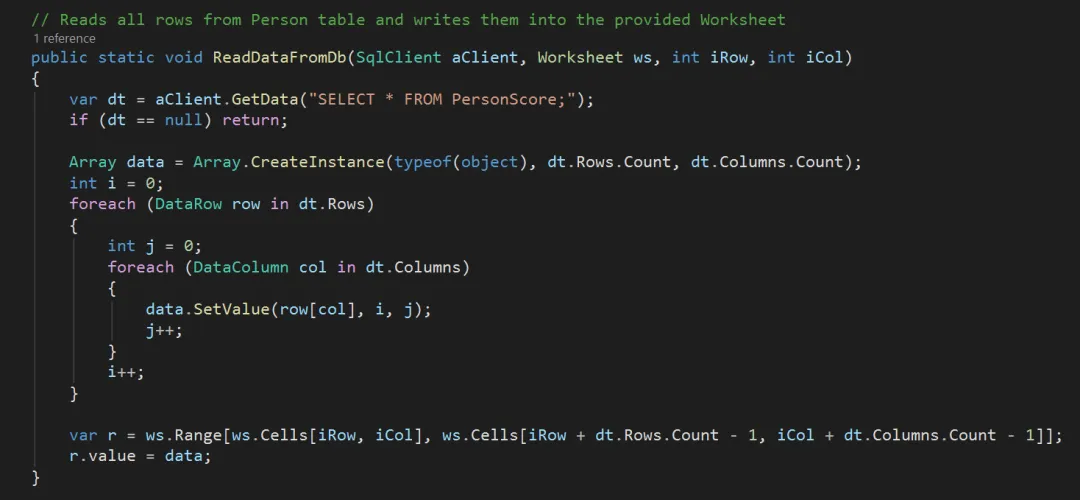
ReadDataFromDb 的代码中,有两点值得说一说: 关于 SqlClient,其与 AceClient 大致相同,只是 AceClient 使用 System.Data.OleDb 作为 Provider,而 SqlClient 使用 Microsoft.Data.SqlClient 作为 Provider。AceClient 的代码已经在前面的文章中讨论过了,故此处不再赘述。 相关阅读 Excel VBA 编程 -- 大数据量写入数据库(一) Excel VBA 编程 -- 大数据量写入数据库(二) Excel VBA 编程 -- 大数据量写入数据库(三) Excel VBA 编程 -- 四谈保护知识产权
ACE:数据集写入 Access 数据库。 SQL:使用 INSERT INTO 语句将数据插入 SQL Server 数据库表,表自身具有自生成的 Id 字段作为关键字。 SQL(NoKey):使用 INSERT INTO 语句将数据插入 SQL Server 数据库表,表自身无关键字字段,Id 的值来自数据集。 SQL(BULK):使用 BULK INSERT 将 .csv 文件插入 SQL Server 数据库表,表自身无关键字字段。 SQL(BULK w/Key):使用 BULK INSERT 将 .csv 文件插入 SQL Server 数据库表,表具有关键字字段。
建立与数据库的连接,并创建接受数据集的表。 将数据集写入数据库表的 WriteDataToDb/WriteDataToDbViaCsv: WriteDataToDb:使用 INSERT INTO 语句将数据插入数据库表。 WriteDataToDbViaCsv:使用 BULK INSERT 将 csv 文件批量插入数据库表。 将数据集读取到 Excel 的 ReadDataFromDb。
创建二维的动态数组:Array.CreateInstance 可以用于创建各种类型的动态数组,创建二维数组的方法接受三个参数: Type elementType:数组元素的类型 int length1:第一维的长度 int length2:第二维的长度 Excel 的区域更新:当用一个数组取更新一个 Excel 的区域(Range)时,如果一个单元格一个单元格地更新,将是效率非常低下的做法。高效更新工作表区域的做法是:直接将数组赋值给工作表的区域,当然二者要对等。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

