Excel合并单元格太坑了?别再用鼠标一个个复制了,13行Python代码搞定“快递明细”整理!
- 2026-04-08 11:08:23
Excel合并单元格太坑了?别再用鼠标一个个复制了,13行Python代码搞定“快递明细”整理!昨天才分享了《单元格拆分太复杂?Python助你三下五除二完成菜品的拆分(插上Ai的翅膀)》,就收到了一个反向需求的问题:快递单每行一个商品,怎么把同一人的订单的多行商品合并到一行? 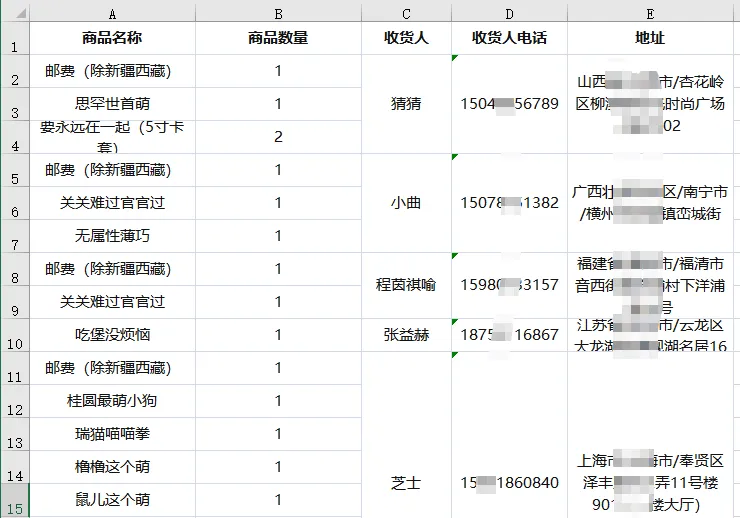
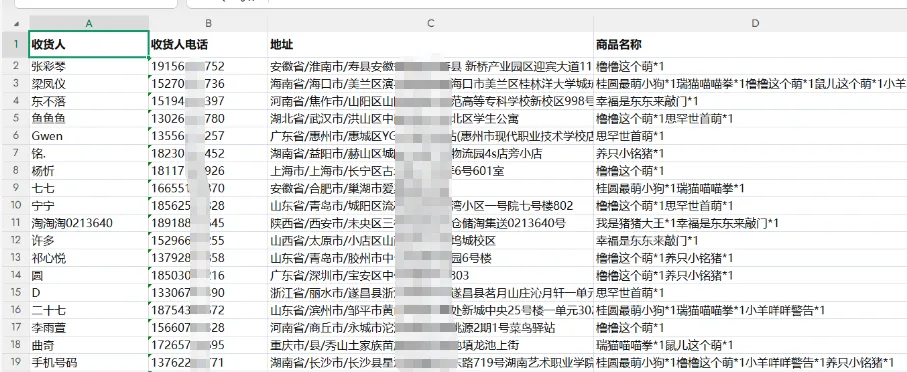
先卖个关子:你有没有遇到过这样的excel表格,明明是同一收货人的信息,因为有多个商品,被拆成了好几行。现在想把这些行合并为一行,把所有商品及数量塞到一个单元格里。 针对这个问题,用python来解决,仅13行代码就能搞定。 先上完整代码: 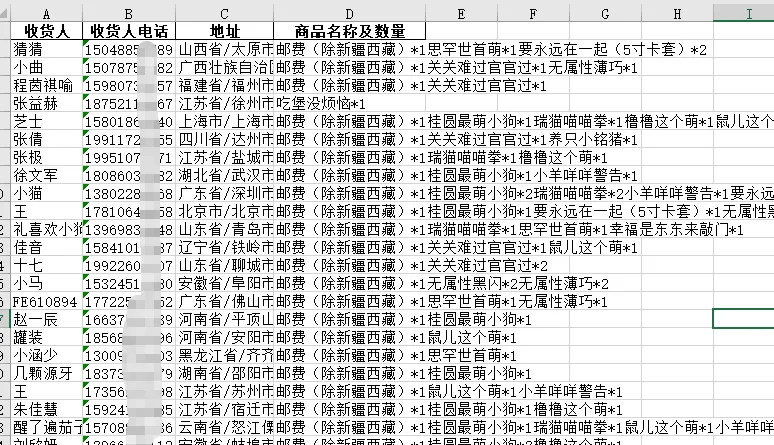
最后来看解决的思路和过程 第一步:读取源Excel文件 在这里使用了pandas来读取excel文件,pandas是数据清洗整理的强大工具。 第二步、构建字典,智能合并 这段代码首先判断当前行“地址”是否为空,如果不为空,说明是一个新的收货人,把所有字段追加到列表;如果为空,则说明是上一条的延续,只把商品拼接到列表的最后一个元素后面。 第三步:转为DataFrame并导出 这里借用pandas的强大功能,把字典转换为标准的DataFrame,并直接输出为新的Excel文件。 今天的分享是《单元格拆分太复杂?Python助你三下五除二完成菜品的拆分(插上Ai的翅膀)》的逆操作。无论是拆分单元格,还是合并单元格,你都不会再被繁琐的手动操作所束缚,不再因格式混乱而焦虑,你可以轻松应对各种类似的奇葩表格。 如果你觉得这篇文章对你有所帮助,欢迎转发给身边需要的朋友。
import pandas as pddf = pd.read_excel(r"E:\快递明细.xlsx")address_dict = {"收货人":[],"收货人电话":[],"地址":[],"商品名称及数量":[]}for _,row in df.iterrows():if not pd.isna(row.iloc[4]):address_dict["收货人"].append(row.iloc[2])address_dict["收货人电话"].append(row.iloc[3])address_dict["地址"].append(row.iloc[4])address_dict["商品名称及数量"].append(f"{row.iloc[0]}*{row.iloc[1]}")else:address_dict["商品名称及数量"][-1] += f"{row.iloc[0]}*{row.iloc[1]}"df = pd.DataFrame.from_dict(address_dict)df.to_excel(r"E:\快递明细_合并后.xlsx",index=False)
再来看效果:import pandas as pddf = pd.read_excel(r"E:\快递明细.xlsx")
address_dict = {"收货人":[],"收货人电话":[],"地址":[],"商品名称及数量":[]}for _,row in df.iterrows():if not pd.isna(row.iloc[4]):address_dict["收货人"].append(row.iloc[2])address_dict["收货人电话"].append(row.iloc[3])address_dict["地址"].append(row.iloc[4])address_dict["商品名称及数量"].append(f"{row.iloc[0]}*{row.iloc[1]}")else:address_dict["商品名称及数量"][-1] += f"{row.iloc[0]}*{row.iloc[1]}"
df = pd.DataFrame.from_dict(address_dict)df.to_excel(r"E:\快递明细_合并后.xlsx",index=False)
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【PPT】50、新入职人员医院感染预防与控制知识培训
- 上班第五天的EXCEL学习:查找和替换的几个技巧(四)
- 【2026春开学第一课】马力全开 PPT+发言稿(附下载链接)
- 如何在PPT 中嵌入AI写的H5/html代码直接使用?霹雳设计助手支持嵌入Gemini,豆包,元宝,deepseek生成的代码放映啦!实操指南已上线!
- 为什么那些年薪百万的PPT高手,开始去卖保险了?
- 33页PPT | 数据要素流通交易解决方案(附下载)
- 【Excel VBA编程】数据格式化大师:NumberFormat属性与Format函数谁才是王者
- 初中下班主任开学第一课PPT(CCK6)
- 幼儿园2026教职工启动大会:PPT/方案/总结/主持稿/各岗位工作安排......
- 告别 Excel 噩梦!我给 HR 伙伴们做了一个九宫格人才盘点“拖拉神器”
