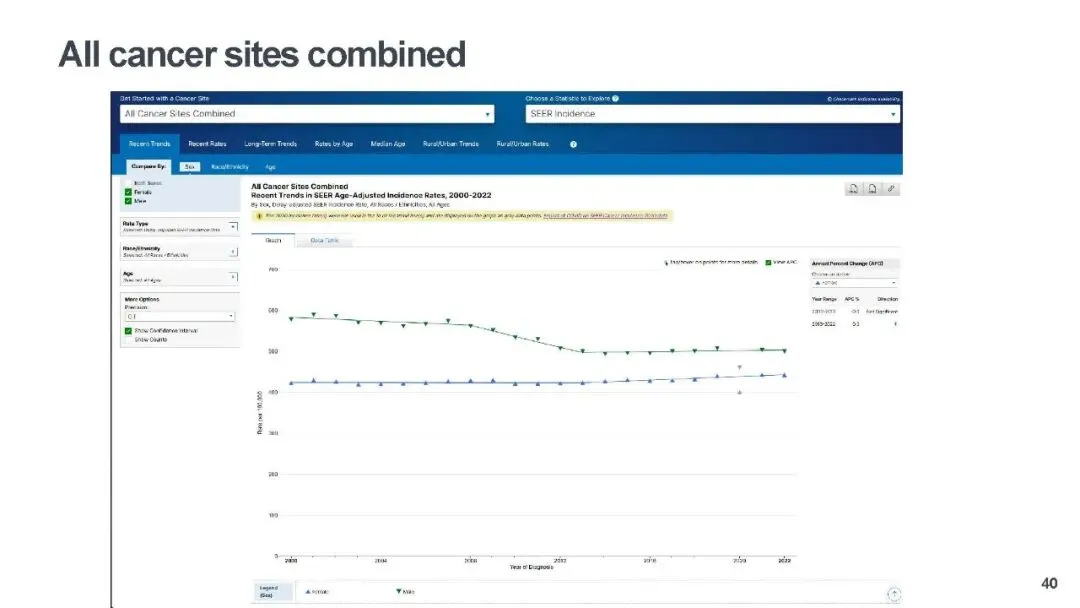
SEER 数据库是全球最权威的癌症流行病学研究工具之一,由美国国家癌症研究所(NCI)维护,涵盖海量癌症发病、死亡、生存及临床特征数据,是开展癌症趋势分析、危险因素研究的重要基础。2025 年,SEER 发布最新一期数据,涵盖 1975 至 2022 年癌症诊断信息,此次更新从种族编码、人口数据、临床字段三大维度完成优化,不仅让基础数据更精准,还为初学者的数据分析和挖掘工作降低了门槛,提升了研究的深度与可靠性。
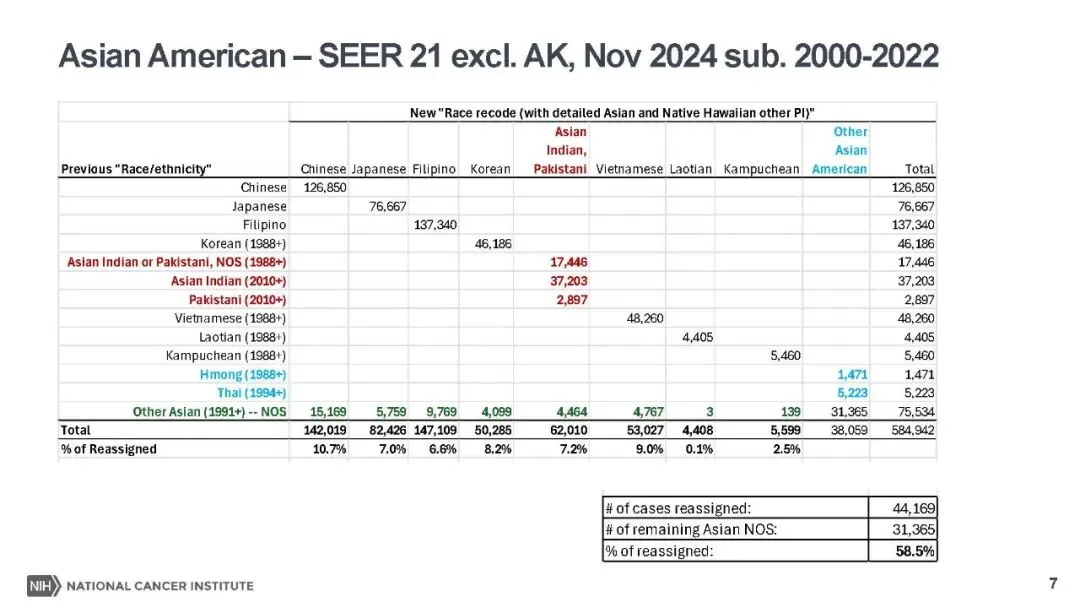
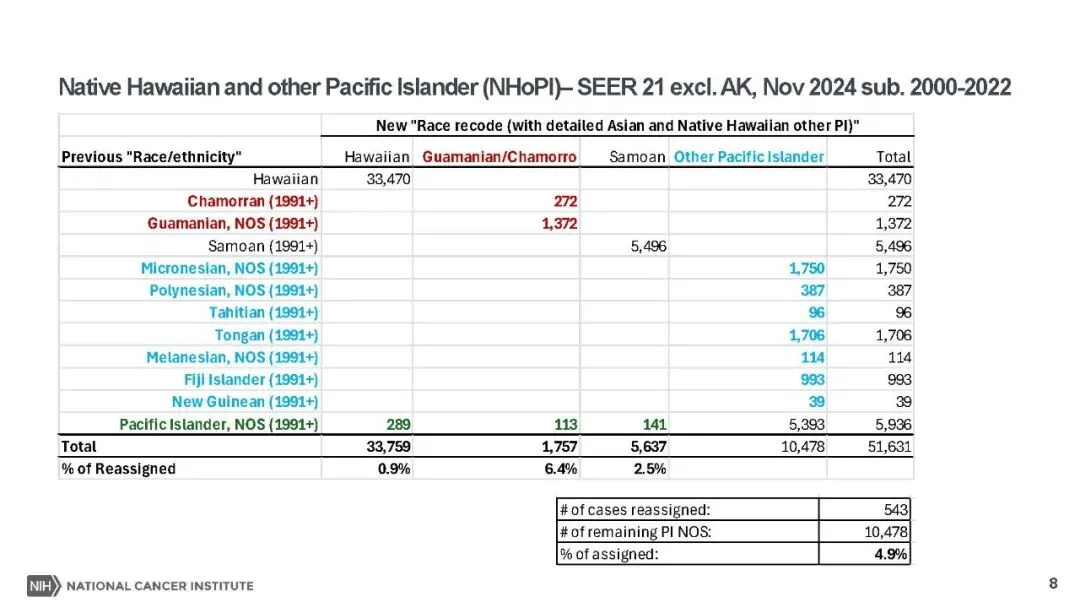
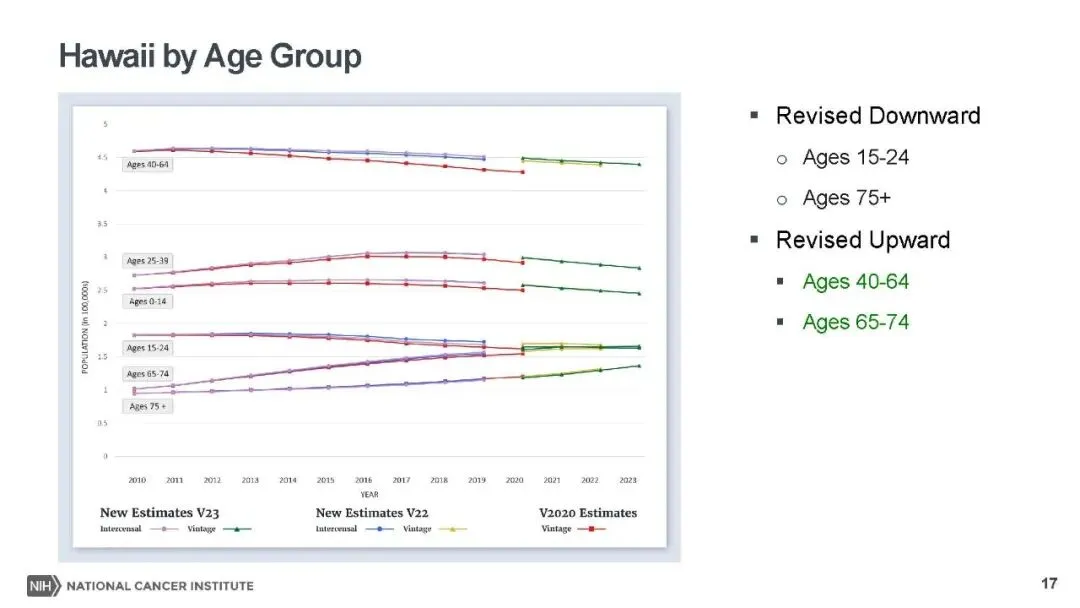
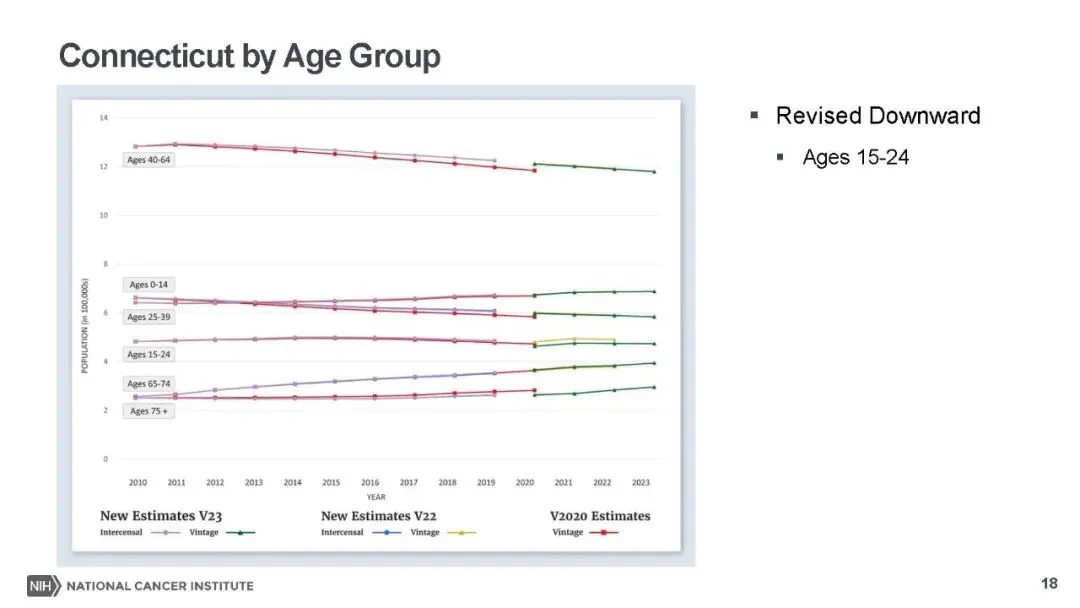
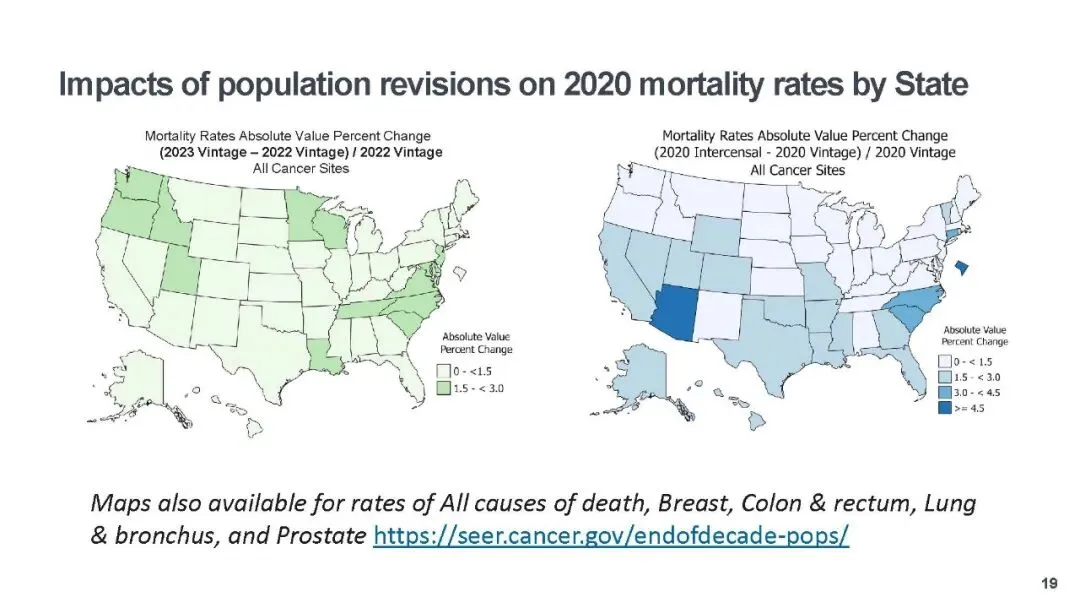
本次更新的核心亮点,是对种族编码体系的精细化升级,推出了包含详细亚裔(AA)和夏威夷原住民及其他太平洋岛民(NHoPI)分类的新型种族编码,替代了此前的 “种族 / 民族” 变量。新编码通过 NAPIIA 算法对未明确分类(NOS)的病例重新分配,58.5% 的亚裔 NOS 病例、4.9% 的太平洋岛民 NOS 病例完成精准归类,将亚裔细分为华人、日本人、菲律宾人等多个亚群,太平洋岛民也做了对应细分。同时,为避免数据披露风险,人口较少的种族被归为 “其他亚裔” 或 “其他太平洋岛民”,非亚裔、非太平洋岛民的种族分类则保持不变,既填补了小众族群的研究数据空白,也让初学者无需重新适应基础分类体系。
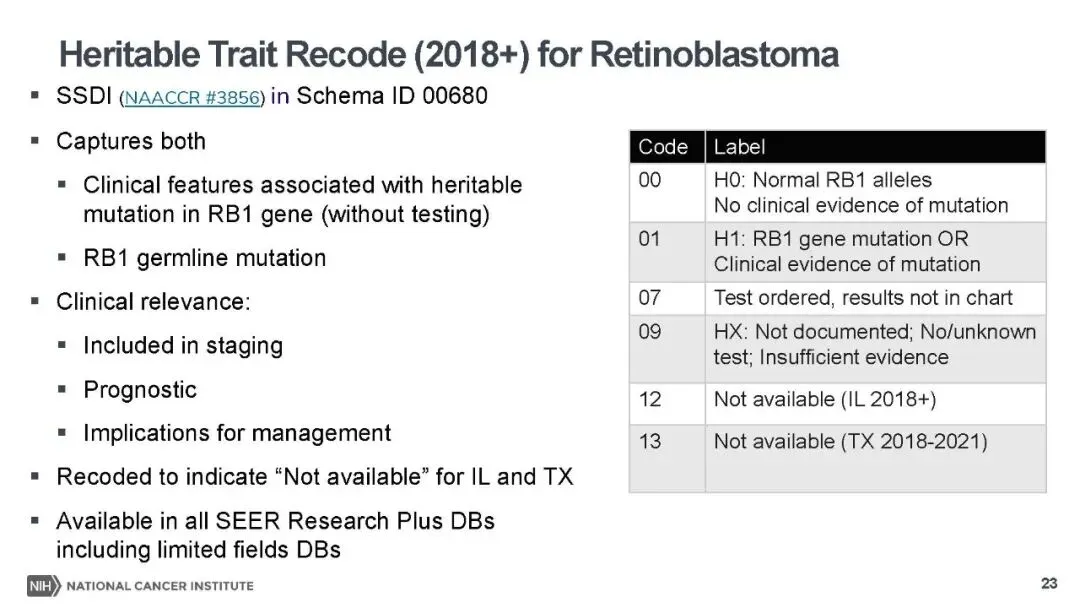
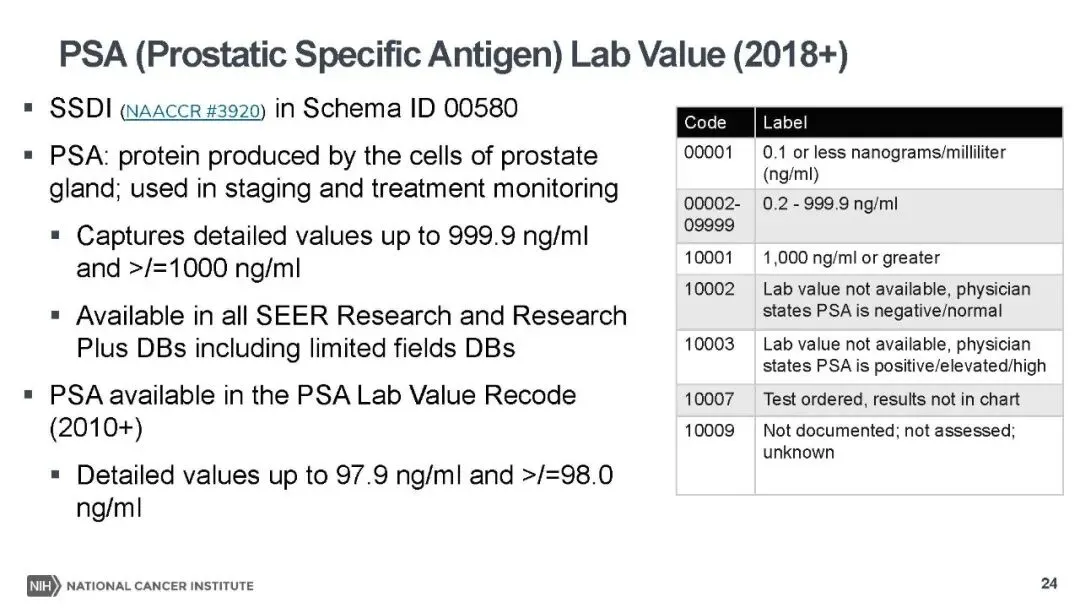
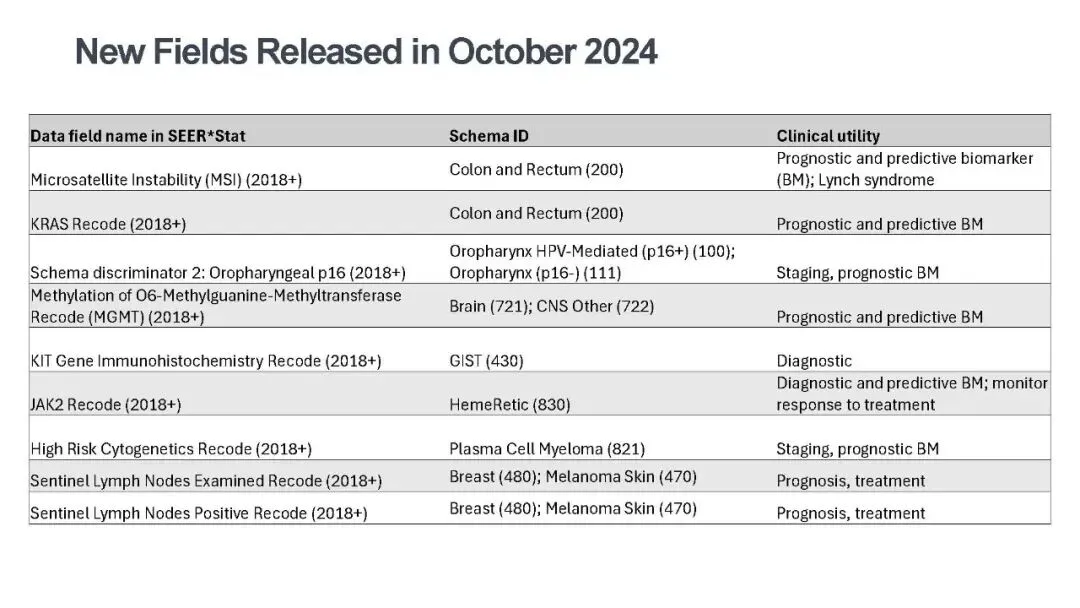
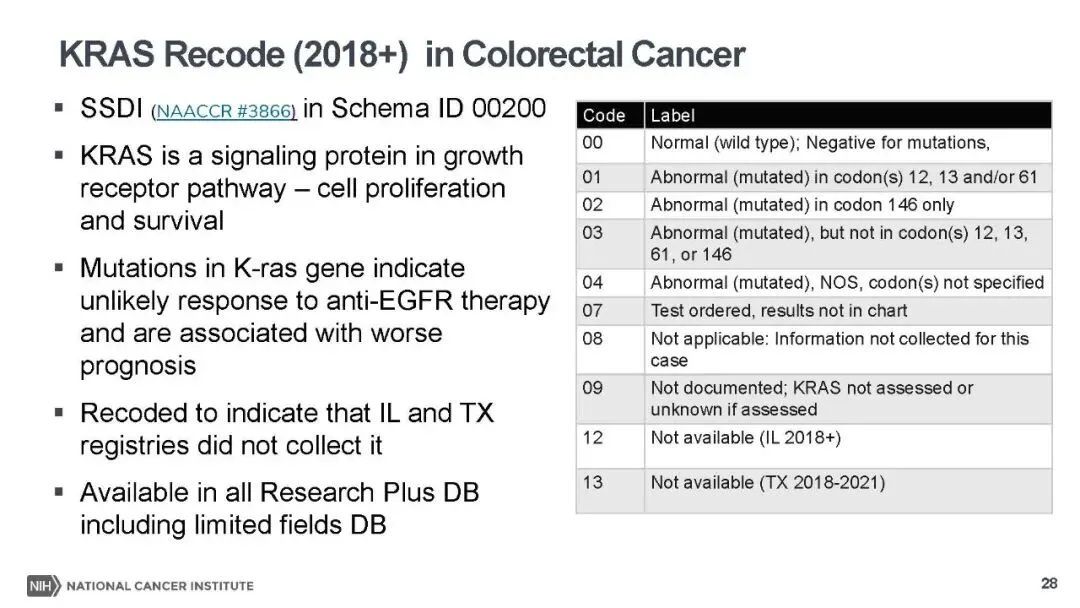
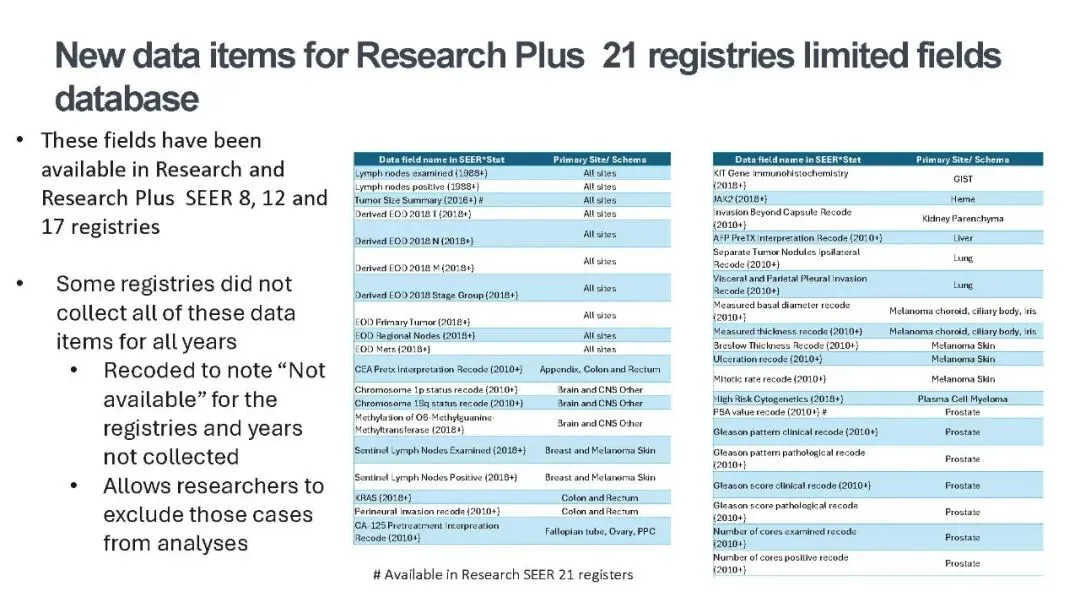
同时,多项核心分子检测和肿瘤标志物指标被纳入,包括前列腺癌 PSA 详细检测值(精度提升至 999.9ng/ml)、肝癌预处理总胆红素检测值及单位编码,结直肠癌 MSI(微卫星不稳定性)、KRAS 基因编码,口咽癌 p16 检测编码等。这些指标既是肿瘤诊断的关键依据,也是预后评估和靶向治疗选择的重要参考,比如 KRAS 突变提示结直肠癌患者对 EGFR 抑制剂治疗反应不佳,MGMT 高甲基化预示脑胶质瘤对化疗更敏感。此外,淋巴结检测、肿瘤大小等此前仅在部分注册库可用的字段,也扩展至全库,让病理特征分析更全面。
本次更新后标准化的修正让数据预处理更简单,无需自行整理归类,大幅减少清洗耗时;种族细分、城乡维度、分子检测等新数据,提供了丰富的研究选题方向,贴合当前科研热点;分子和标志物字段的加入,让研究能从简单的描述性分析升级为深度的关联分析,提升论文学术价值;精准的人口和年龄数据,也让研究结论更可靠、更具说服力。
另外,初学者想要快速上手,可先在 SEER 官网熟悉新增字段的注释和定义,避免误用数据;同时利用 SEERStat、SEERExplorer 等官方免费工具,其新增的城乡趋势分析功能可直接开展可视化分析,无需复杂编程技能。从简单的发病率趋势分析入手,再逐步结合分子、标志物字段开展关联研究,能循序渐进提升研究能力。
专栏内容查看请点击公众号文章下方的阅读原文。

市面上的 R 语言培训班和书籍(包括网络上的文章或视频),由于受限于培训时间或书籍篇幅,往往难以深入探讨 R 语言在数据科学或人工智能中的具体应用场景,内容泛泛而谈,最终无法真正解决实际工作中的问题。同时,它们也缺乏针对医药领域的深度结合与讨论。为了解决这些痛点,我们推出了《用 R 探索医药数据科学》专栏。该专栏将持续更新,不仅为您提供系统化的学习内容,更致力于成为您掌握最新、最全医药数据科学技术的得力助手。
- 每篇文章篇幅在5000字 至9000字之间,已经超过220万内容。
- 内容涵盖试验统计、随机配对技术、临床预测模型、高级科研绘图、孟德尔随机化 、机器学习等热点领域。
- 其中数据库讲解包括:NHANES、FAERS、GBD、GEO、NHIS等。





























 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
