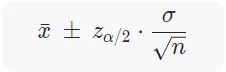置信区间的理解一直是个老生常谈的问题,今天我们使用Excel做一个简单的数据生成的实验,来快速理解什么是置信区间,跟着做一遍,相信大家一定会对置信区间有一个深刻的理解。
首先我们回顾90%,95%和99%置信区间的定义。
置信区间:是在一个给定的置信水平下,用来估计总体参数(通常是均值)可能落在的区间范围。它告诉我们:如果我们用同样的方法多次抽样并构建区间,那么有 X% 的区间会包含真实的总体参数。
这个“X%”就是置信水平(90%, 95%, 99%)。置信水平越高,区间就越宽(因为要更“确信”能包含真值,就要把网撒得更大)
在已知总体为正态分布,总体方差为σ,抽样量为n,抽样均值为x_bar,临界值为z时,不同置信水平下的置信区间计算方式为:
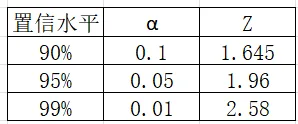
对于不同的置信水平,临界值Z分别为:
下面我们假设一个场景,并用Excel模拟出不同的抽样过程,然后统计根据抽样过程计算的不同区间包含真实均值的比例:
某公司生产了一批试剂,共计10000片,其重量均值是100g,总体标准差是10g。qc部门从当批生产的试剂中随机抽取25片,并计算了该批抽样的置信区间
现在我们假设这个实验可以无损耗的抽样1000次,那么就可以构造1000个置信区间,使用不同置信水平计算出来的置信区间,应该包含了均值100g分别是900次,950次和990次,下面我们用excel进行抽样的模拟。
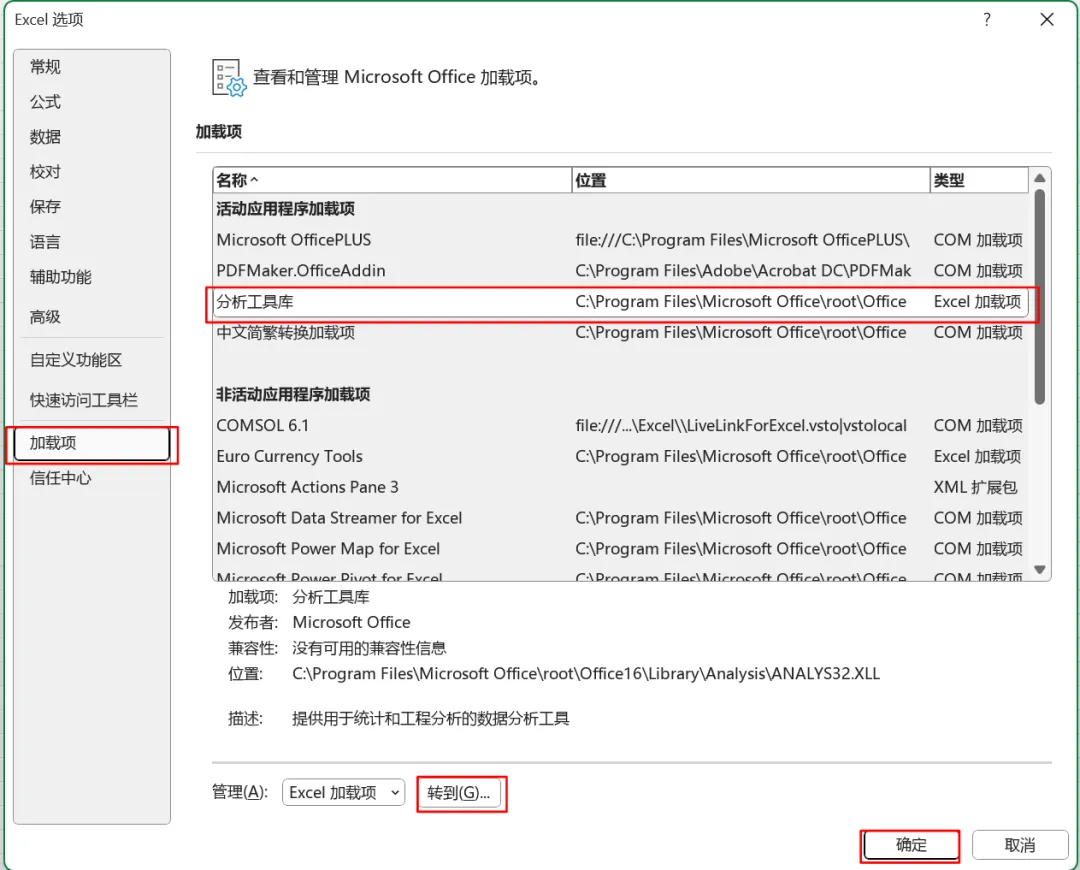
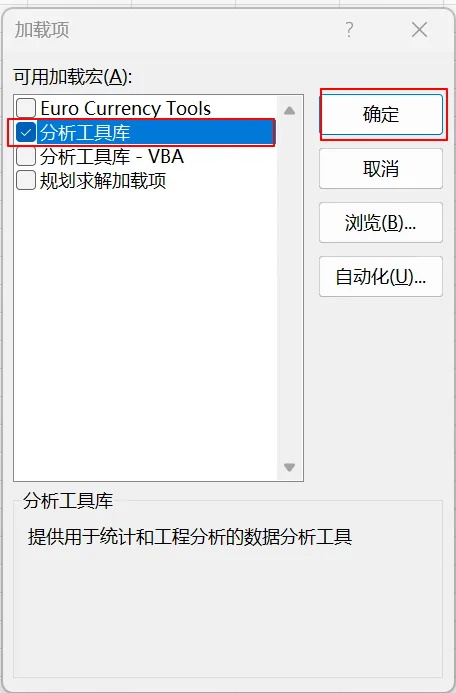
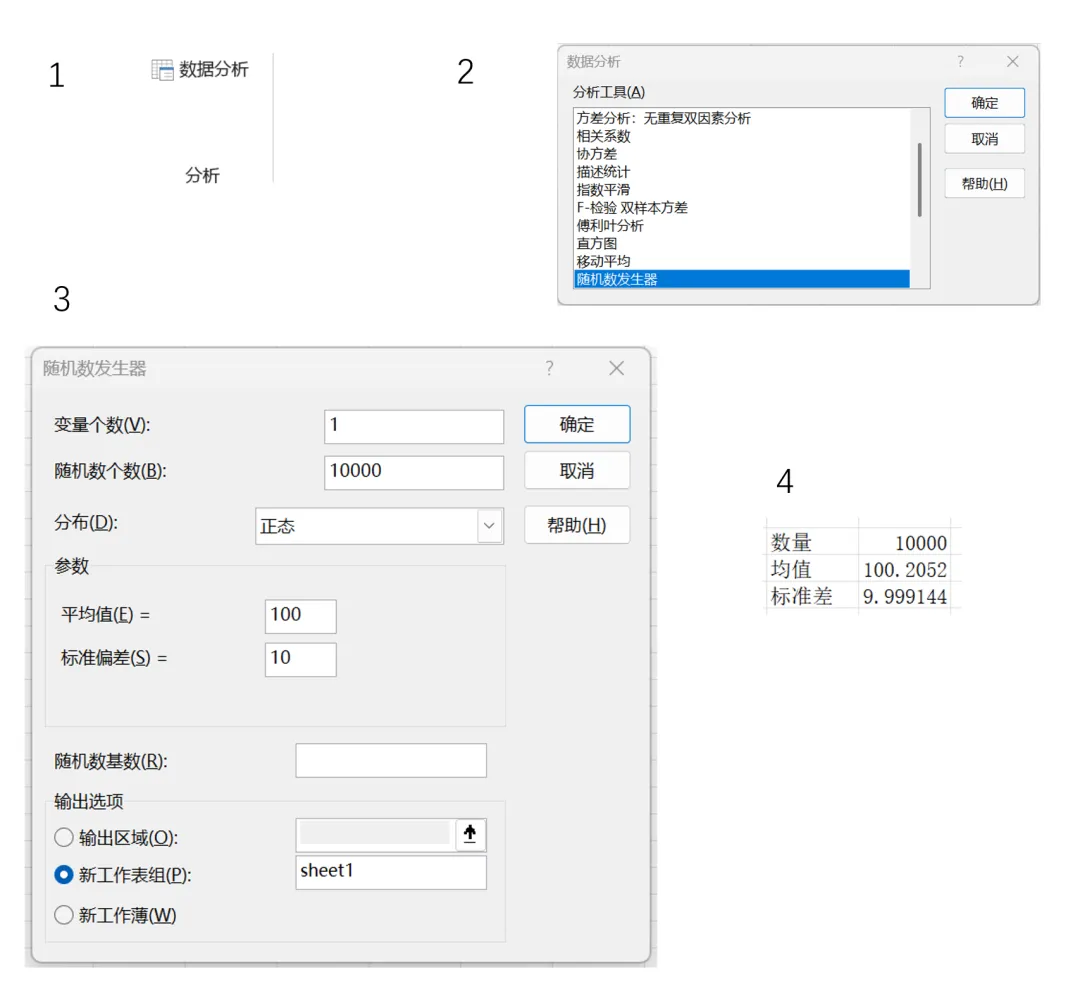
打开Excel文件,分别点击‘文件-选项-加载项-分析工具库’,点击下方的‘转到’,勾选‘分析工具库’,最后‘确定’。
在数据菜单栏中会出现分析功能,点击“数据分析”后进入随机数发生器界面,按照上面的条件“共计10000片,其重量均值是100g,总体标准差是10g”设置随机数发生器的参数,最后我们得到了10000个数据。随后我们用count函数,average函数和stdev函数确认生成数据的参数,是没有问题的。
在sheet2中使用下面的函数生成1000行数据,每行25个。得到的数据每一行表示一次抽样,一次抽样共计25个。
=INDEX(sheet1!$A:$A, RANDBETWEEN(1, 10000))
注1:生成后的数据可以复制到另一个sheet,只保留数字,可以避免每次修改单元格都会触发函数。
注2:用上述函数生成的抽样数据,同一行有很小的概率会重复抽到同一个数字,不影响后面的计算。
有了上述数据后,我们可以分别计算每一次抽样(每行)构造的置信区间,并判断该区间是否包含均值100,函数如下
第一次抽样均值:Z2=AVERAGE(A2:Y2)
第一次抽样置信区间下限:AB2=Z2-1.645*10/5
第一次抽样置信区间上限:AC2=Z2+1.645*10/5
第一次抽样的置信区间是否包含总体均值:AD2=IF(AND(AB2<100, AC2>100), "Y", "N")
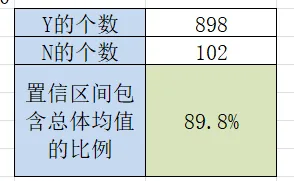
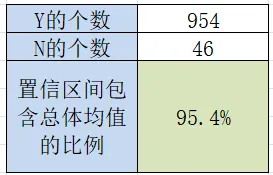
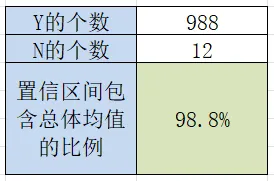
1000次抽样Y的个数:AF2=COUNTIF(AD:AD, "Y")
1000次抽样N的个数:AF3=COUNTIF(AD:AD, "N")
1000次抽样置信区间包含总体均值的比例:AF4=AF2/1000
我们得到下面的数据
90%置信度下:
95%置信度下
99%置信度下:
抽样量继续增加,包含的比例会无限接近90%,95%和99%。
这就是置信区间的含义:如果我们用同样的方法多次抽样并构建区间,那么有 X% 的区间会包含真实的总体参数。
希望本篇文章可以对读者有一些启发,感谢您的阅读。