大数据核心特征可概括为经典的“4V”:海量的数据规模(Volume)、高速的数据产生速度(Velocity)、多样的数据类型(Variety),以及蕴含其中的巨大价值(Value)。
提到数据处理,很多人首先想到Excel。可一旦数据量突破百万行,表格就会变得异常卡顿,甚至无法打开......
这就是大数据的核心特征:其规模已远超个人工具的处理极限。Excel的百万行上限,在TB、PB级的业务数据面前,无异于杯水车薪。面对海量的数据洪流,进行实时分析与高效管理,它已力不从心。
这正是大数据技术与服务器集群登场的时候。它们如同数据世界的“超级工厂”,通过分布式架构突破单机极限,实现对海量数据的可靠存储与智能挖掘。
为什么单台计算机的能力会有上限?
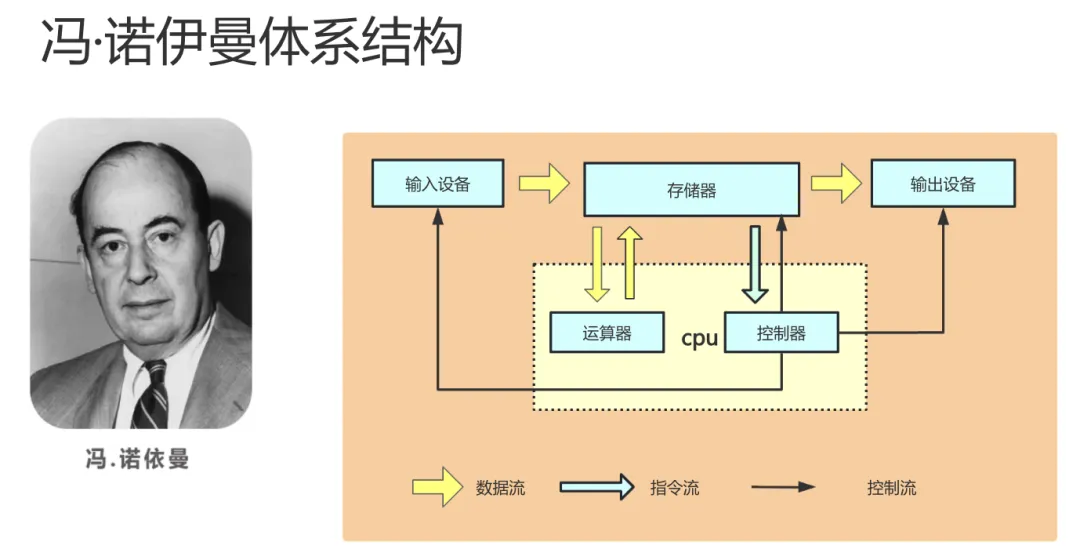
要理解这一点,我们需要从近80年前提出的冯·诺依曼架构说起。
冯·诺依曼架构的核心是“存储程序”概念:
计算机由CPU、存储器、输入输出设备三大部件组成,程序指令和数据都以二进制形式存放在存储器中。CPU的核心工作,就是从存储器中逐条取出指令并顺序执行。
这种“读取-解码-执行”的串行工作模式,在大数据处理场景下会暴露明显短板,核心是三大关键瓶颈:
🔴 内存墙:数据搬运的效率制约
冯·诺依曼架构中,CPU与内存是物理分离的。尽管CPU运算速度极快,但数据存取必须通过总线在两者间频繁搬运。当数据量剧增时,数据搬运速度会远远跟不上CPU处理速度,形成一道“内存墙”(Memory Wall)——此时CPU大部分时间都在等待数据,根本无法实现高能效比。
🔴 顺序执行:制约并行处理能力
该架构下的程序指令需串行执行,由程序计数器严格控制顺序。哪怕后续指令所需的数据已经准备就绪,也必须排队等待前一条指令完成。而海量数据的高效处理,恰恰依赖并行计算能力,这种串行机制直接卡住了效率提升的关键。
🔴 硬件天花板:纵向扩展性价比骤降
靠提升单机硬件配置(比如更快的CPU、更大的内存)来提升性能,这种“纵向扩展(Scale-up)”的思路很快会触及物理极限。如今CPU频率、集成电路集成度的提升已逐渐逼近硅材料的物理上限,且硬件升级的成本会随性能提升急剧增加,单纯靠升级单机硬件的路径,性价比越来越低。
看懂了冯·诺依曼架构的这些根本性限制,就不难理解:当数据规模持续增长时,换一台更强的单台计算机并非最优解。这也顺势引出了大数据时代的核心应对策略——分布式计算,而这正是服务器集群登场的核心原因。
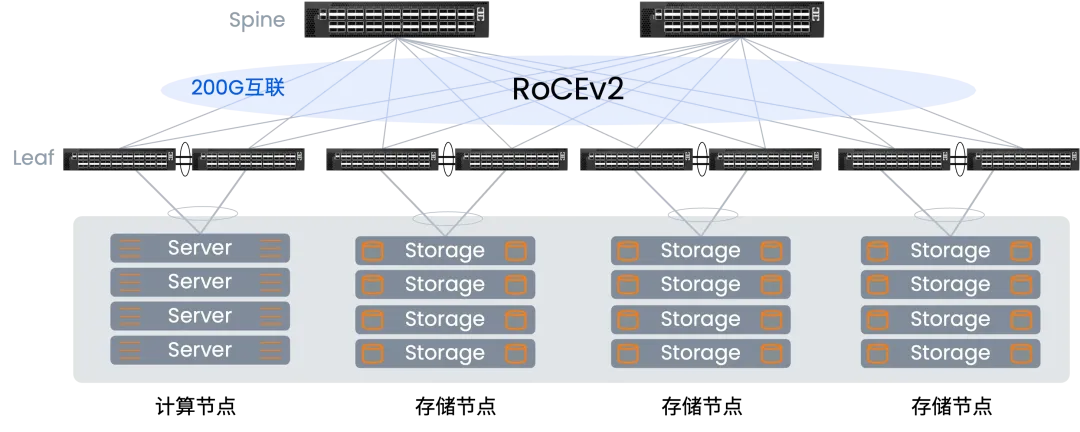
这张图,就是高性能数据中心的“核心骨架”——一套分工明确、协同高效的网络结构。正是这套结构的服务器集群,才能稳稳接住大数据处理的海量需求。
整个架构主要靠三层关键组件撑起来,咱们一个个说清楚:
🔴 计算节点
其实就是一堆服务器凑成的“团队”。面对海量数据任务,它们不搞“单枪匹马硬扛”,而是靠“分工协作”:把大任务拆成无数小任务,多台服务器同时开工处理,直接突破了单台电脑的算力上限。
🔴 存储节点
由多台存储设备组成,专门负责存数据。它的聪明之处在于“分布式存放”:把海量数据拆成小块存在不同设备里,既解决了单台设备装不下的问题,还会自动做多份备份——哪怕某台设备坏了,数据也不会丢,安全性拉满。
🔴 高速交换网络
这是整个架构的“大动脉”,核心是独特的叶脊(Spine-Leaf)设计,专门解决设备连接的“扩展难题”:
🔹Leaf-叶交换机:每个机柜顶部的“本地枢纽”
直接连自己机柜里的服务器和存储设备,把本地的数据流汇总起来。但受机柜空间、端口数量限制,它没法无限扩展——总不能把机柜堆成山吧?
🔹 Spine-脊交换机:所有枢纽的“核心骨干”
相当于把所有Leaf交换机连起来的“超级枢纽”,形成一个全互联的骨干网。
为啥要搞“叶”和“脊”两层?核心就是解决“扩展难”的问题!
它走的是“横向扩展”思路:
需要多连服务器,就新增Leaf交换机(对应新增机柜);Leaf多了不够用,就新增Spine交换机提升骨干带宽。
这样一来,任意两台服务器通信,最多只经过1台Spine+2台Leaf交换机,路径最短、最稳定,能稳定提供高带宽、低延迟的传输支撑——这是整个“数据处理体系”顺畅运转的关键!
数据中心网络可不只是大数据集群的“地基”,更是当下计算机网络领域的热门方向。尤其是现在人工智能这么火,GPU的大规模应用更是带来了一连串连锁反应——不管是网络传输、计算架构,还是存储模式,都被它悄悄改变了。
关于GPU带来的这些具体变化,咱们接下来单独拎出来唠唠~