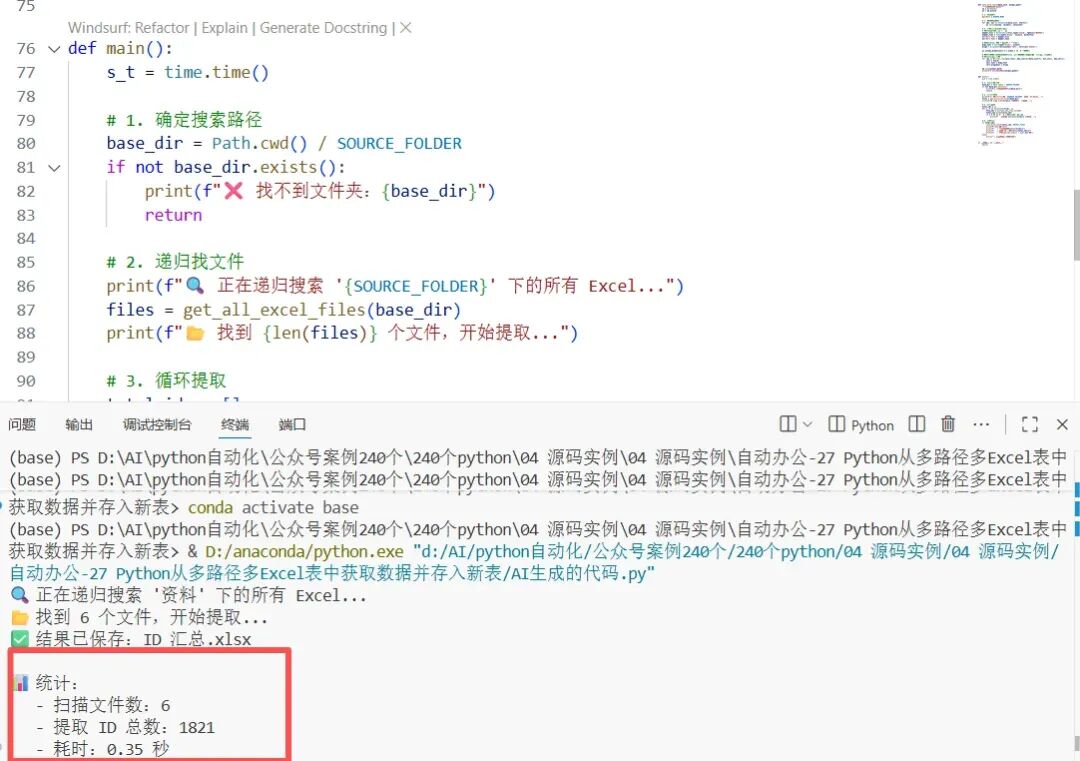
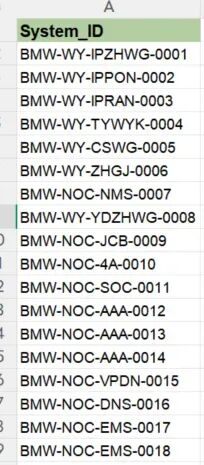
import osimport timefrom pathlib import Pathfrom openpyxl import load_workbook, Workbookfrom openpyxl.styles import Font, PatternFill, Alignment# --- 配置区 ---SOURCE_FOLDER = "资料" # 你的目标文件夹名OUTPUT_FILE = "ID_汇总.xlsx"TARGET_COL_INDEX = 0 # A列索引是0(openpyxl read_only模式或者pandas习惯),这里用openpyxl原生是1HEADER_NAME = "System_ID"def get_all_excel_files(root_dir): """递归获取所有子文件夹下的 .xlsx 文件""" p = Path(root_dir) # rglob('*') 是递归查找所有文件 return [f for f in p.rglob("*.xlsx") if not f.name.startswith("~$")] # 排除临时文件def extract_ids_from_file(file_path): """从单个 Excel 提取 A 列数据(跳过表头)""" ids = [] try: # data_only=True 读取计算后的值,read_only=True 提升读取速度(大文件必开) wb = load_workbook(file_path, read_only=True, data_only=True) ws = wb.active # 遍历 A 列(min_col=1, max_col=1),从第2行开始 for row in ws.iter_rows(min_row=2, min_col=1, max_col=1, values_only=True): val = row[0] if val is not None: ids.append(val) wb.close() except Exception as e: print(f"⚠️ 读取失败:{file_path.name} -> {e}") return idsdef save_with_style(data_list, output_path): """保存并美化 Excel""" wb = Workbook() ws = wb.active # 1. 写入表头 ws["A1"] = HEADER_NAME # 2. 批量写入数据 for idx, val in enumerate(data_list, start=2): ws.cell(row=idx, column=1, value=val) # 3. 设置格式(美化环节) # 表头:淡绿色背景 + 加粗 header_fill = PatternFill(fill_type='solid', fgColor="B3CFA1") header_font = Font(name='Arial', size=10, bold=True) ws["A1"].fill = header_fill ws["A1"].font = header_font # 正文:Arial 9号 + 左对齐 + 垂直居中 body_font = Font(name='Arial', size=9) align = Alignment(horizontal='left', vertical='center') ws.column_dimensions['A'].width = 20 # 设置列宽 # 遍历设置样式(数据量大时,建议只设置列样式或最后统一设,逐行设会慢) # 这里演示逐行设置 for row in ws.iter_rows(min_row=2, max_row=len(data_list)+1, min_col=1, max_col=1): cell = row[0] cell.font = body_font cell.alignment = align wb.save(output_path) print(f"✅ 结果已保存:{output_path}")def main(): s_t = time.time() # 1. 确定搜索路径 base_dir = Path.cwd() / SOURCE_FOLDER if not base_dir.exists(): print(f"❌ 找不到文件夹:{base_dir}") return # 2. 递归找文件 print(f"🔍 正在递归搜索 '{SOURCE_FOLDER}' 下的所有 Excel...") files = get_all_excel_files(base_dir) print(f"📂 找到 {len(files)} 个文件,开始提取...") # 3. 循环提取 total_ids = [] for i, f in enumerate(files, 1): file_ids = extract_ids_from_file(f) total_ids.extend(file_ids) if i % 50 == 0: # 每50个打印一次进度 print(f" 已处理 {i}/{len(files)} 个文件...") # 4. 保存结果 if total_ids: save_with_style(total_ids, OUTPUT_FILE) print(f"\n📊 统计:") print(f" - 扫描文件数:{len(files)}") print(f" - 提取 ID 总数:{len(total_ids)}") print(f" - 耗时:{time.time() - s_t:.2f} 秒") else: print("⚠️ 未提取到任何数据。")if __name__ == "__main__": main()

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
