一、相关背景
地籍项目的权籍资料整理,绕不开户口本。
确权登记需要采集权利人的姓名、身份证号码、与户主关系等信息。这些内容分散在每户几张扫描件里,字体是手写体,图片质量参差不齐,部分图片还存在拍摄角度倾斜的问题。
常规做法是人工逐张翻看、逐项录入 Excel。一个村几十户,几百张图片,纯手工下来,容错率和效率都有限。
身份证号码是重灾区——18位数字手写潦草,录错一位,后续核查要花数倍时间。
地籍项目权籍资料 OCR 识别系统是针对这个场景开发的工具,用来将户口本扫描图片批量识别并导出为标准 Excel 表格。
二、软件介绍
2.1 技术实现
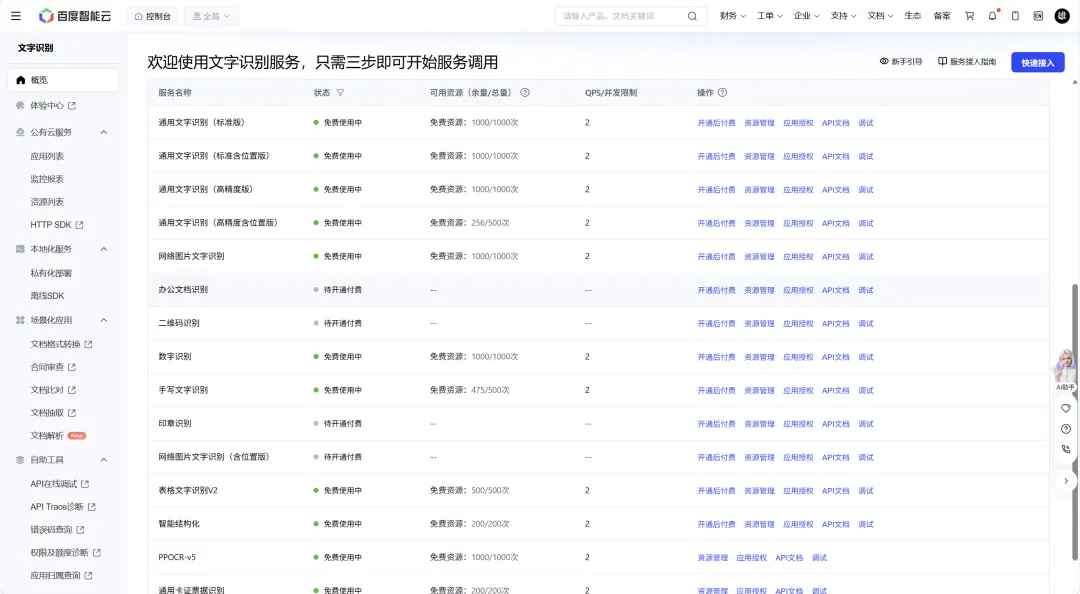
工具对接百度 OCR 三种接口,按场景选用:
- 户口本专用接口:百度专门针对户口本格式训练,直接返回结构化字段,姓名、身份证、与户主关系逐项输出,无需自行解析,识别准确率最高,50 次/天免费;
- 精准识别接口:通用场景兜底,支持自动方向检测,图片拍歪了可自动纠正,1000 次/天免费;
- 手写体专用接口:针对手写汉字优化,字迹较难辨认时切换使用,200 次/天免费。
封面页(有户口专用章但无登记卡字段的图片)自动识别并跳过,不消耗 API 额度。
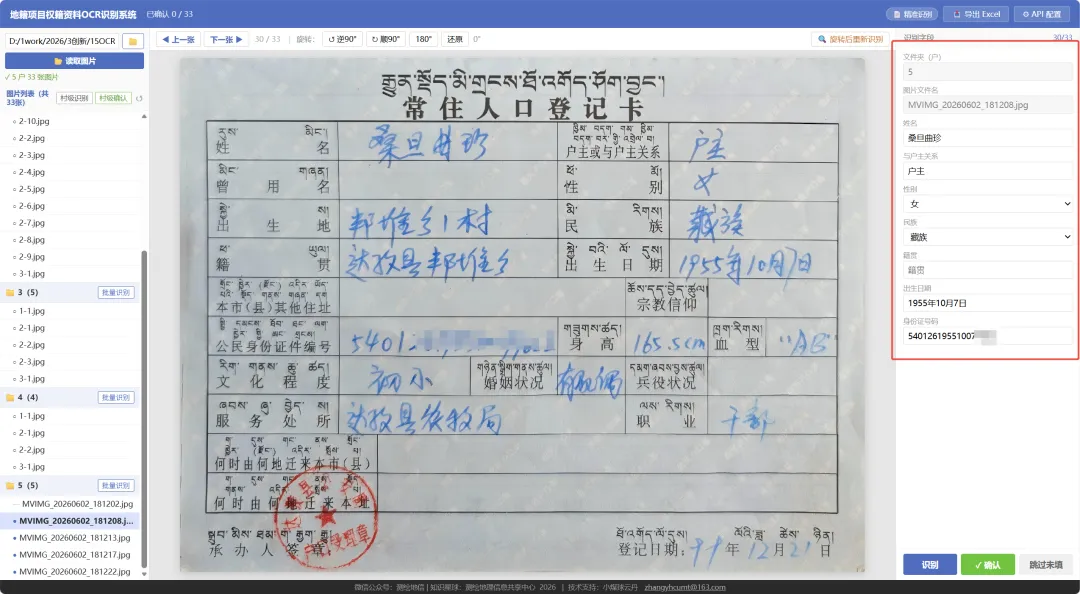
2.2 身份证校验
身份证号码录入后自动触发三项校验:
校验不一致的条目实时高亮,确认后写入校验日志,方便后续核查。
2.3 运行环境
Web 界面,本地 Flask 服务,浏览器访问。打包为独立 exe,Windows 10/11 开箱即用,无需安装 Python 或其他依赖。
三、操作说明
第一步:配置 API
右上角进入 API 配置,填入百度 OCR 的 API Key 和 Secret Key,选择识别接口,保存后测试连接。百度智能云注册即可申请,每日免费额度覆盖常规作业量。
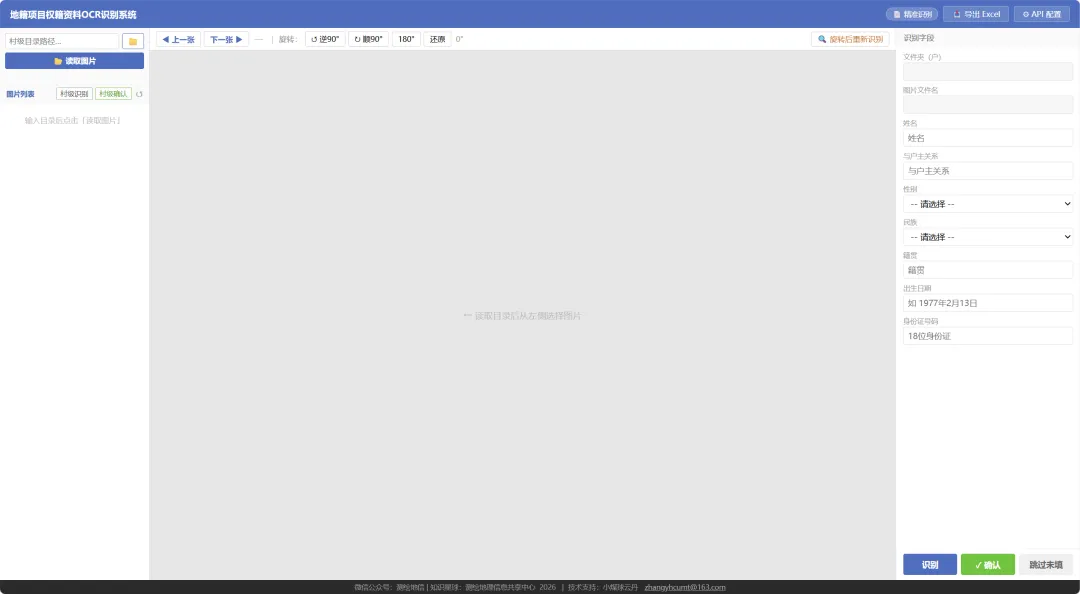
第二步:读取图片
输入或浏览选择村级目录,点击"读取图片"。程序自动扫描子文件夹,每个文件夹视为一户,图片按户分组展示。
目录结构示例:
D:\户口本扫描件\ ├── A村\ │ ├── 张三户\ │ │ ├── 001.jpg │ │ ├── 002.jpg │ │ └── 003.jpg │ └── 李四户\ │ ├── 001.jpg │ └── 002.jpg │ └── B村\ ├── 王五户\ │ ├── 001.jpg │ └── 002.jpg └── 赵六户\ ├── 001.jpg └── 002.jpg
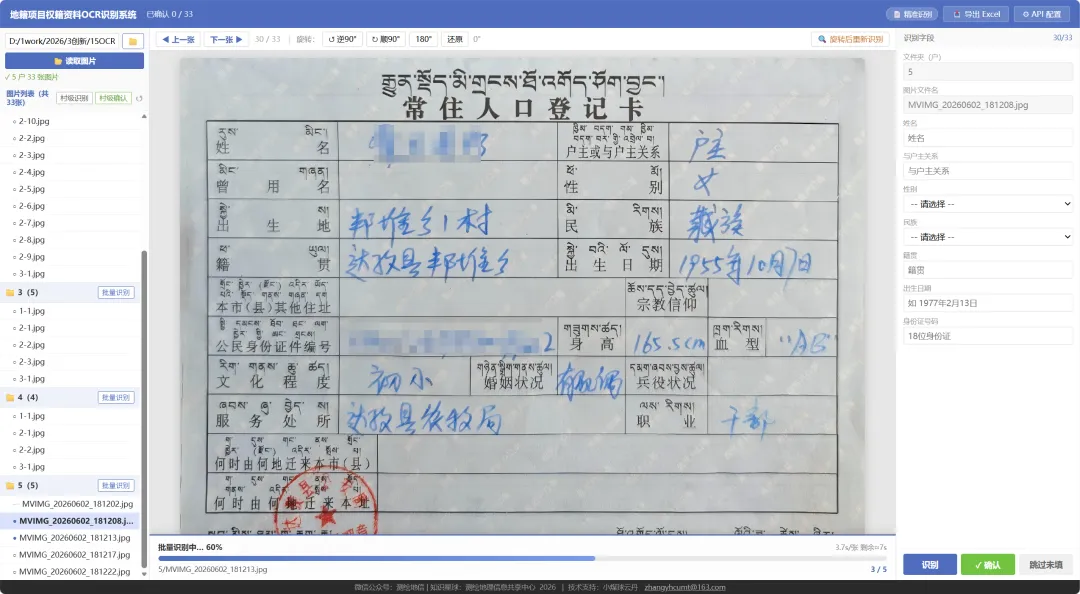
第三步:批量识别
点击"村级识别",对全村图片一键识别。识别过程实时推送进度,每张完成后立即可交互,无需等待全部结束。
第四步:核查确认
逐张翻看识别结果,错误字段直接修改,性别和民族支持下拉选择。身份证校验不一致时字段自动标红。确认后跳下一张,图片区顶部显示当前进度。
质量可信的批次,可直接点击"村级确认"批量通过,省去逐张核查。
第五步:导出
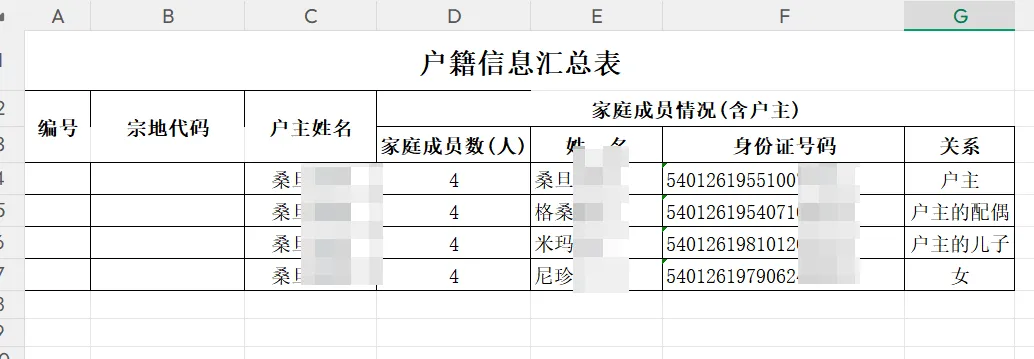
点击"导出 Excel",同时生成两个文件:
按户分组,格式对照标准模板,宗地代码列留空供手动补充。适配自研软件地籍测量图库一体化数据处理软件中DWG地籍图导出SHP\MDB数据库。同步输出校验日志,记录所有不一致条目。
以某村 4 户 20 张图片为例,村级识别约 2 分钟完成,逐张核查约 10 分钟,合计导出两份 Excel。