万众期待的 Claude Mythos 终于发布了。
时间倒回3月份,两名网络安全研究员发现了 Anthropic CMS (内容管理系统)配置错误导致的公开数据缓存,里面暴露了约 3000 个未发布的内部资产,其中包括一份博客文章的草稿,而 Mythos 这个名字第一次出现在里面。
Claude Mythos,内部代号 Capybara,是 Anthropic 全新的旗舰模型,远超当时的 Opus 系列。被 Anthropic 描述为 “by far the most powerful AI model we’ve ever developed”(迄今为止我们开发过的最强大模型)。
Fortune 杂志以《独家报道:数据泄露曝光 Anthropic “Mythos” AI 模型,标志着能力的“阶跃式提升”》为标题,发布了独家报道,随后 Anthropic 承认 Mythos 模型确实存在,仍在内部测试中。
4月7日,Anthropic 正式官宣 Mythos preview,并公布了模型的性能,在多个基准上较 Claude Opus 4.6 有“striking leap”(惊人飞跃)。
USAMO 2026 的成绩从 42.3% 提升至 66.2%,CharXiv Reasoning 等多项任务大幅领先,SWE-bench、GPQA Diamond、MMMU-Pro、Humanity’s Last Exam 等多个基准接近或达到满分。
在软件工程、长时程推理、计算机使用(computer use)、知识工作、科研辅助等领域展现出极强的代理能力,可“set and forget”(下达任务后自主完成多小时工作,几乎无需人工干预)。
最强大的是它的网络安全能力,Anthropic称它为分水岭(watershed moment):
能以极少人工指导,自主发现开源/闭源软件的零日漏洞(zero-days),并开发出可工作的 PoC 漏洞利用程序。
Cybench 100% 通过率,CyberGym 得分 0.83( Opus 4.6 为 0.67);在 Firefox 等真实软件上大幅超越人类专家。
由于能力太强、太危险,连 Anthropic 自己都害怕。毕竟能发现这么多网络安全漏洞,如果被恶意利用,会造成更严重的后果。
因此 Anthropic 当时决定暂时不对用户开放 Mythos,而是推出 Project Glasswing计划,将 Mythos 提供给合作伙伴用于防御性安全工作。
一个月之后的5月22日,Anthropic还公布了Project Glasswing的阶段性成果报告,在这一个月的时间里合作伙伴总共发现了超过 10,000 个高危或严重级漏洞,每个合作伙伴平均发现数百个漏洞,漏洞发现率提升超过 10 倍。不仅用于找漏洞,还帮助一家合作伙伴银行检测到了一笔 150 万美元的欺诈转账。
气氛已经烘托好了,大家都期盼着 Mythos 早点发布,一睹真容。
6月9日,X上开始有用户说 Anthropic 将于明天正式发布 Mythos,几个小时之后,发布文章出现在 Anthropic的官方博客里。
和preview版本不同,Mythos的正式版有两个版本,Fable 5和Mythos 5,这两个版本在模型层面是一致的,Fable 5是面向公众的版本,带有完整安全护栏,会把部分敏感的主题转到 Opus 4.8。
而 Mythos 5 则是在某些领域解除了护栏,能力更强,主要面向Project Glasswing合作伙伴和美国政府。
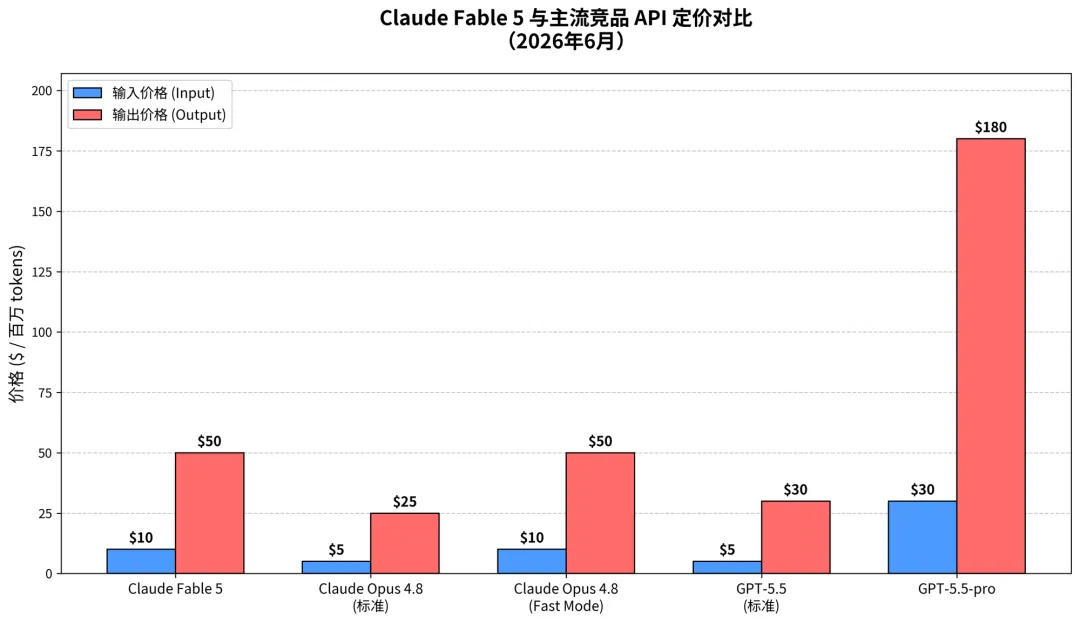
Fable 5 和 Mythos 5 的定价为 每百万输入 Token 10 美元,每百万输出 Token 50 美元——不到 Claude Mythos 预览版价格的一半,但是和其它模型的价格相比,还是比较贵的。
虽然贵,但是贵的有道理。
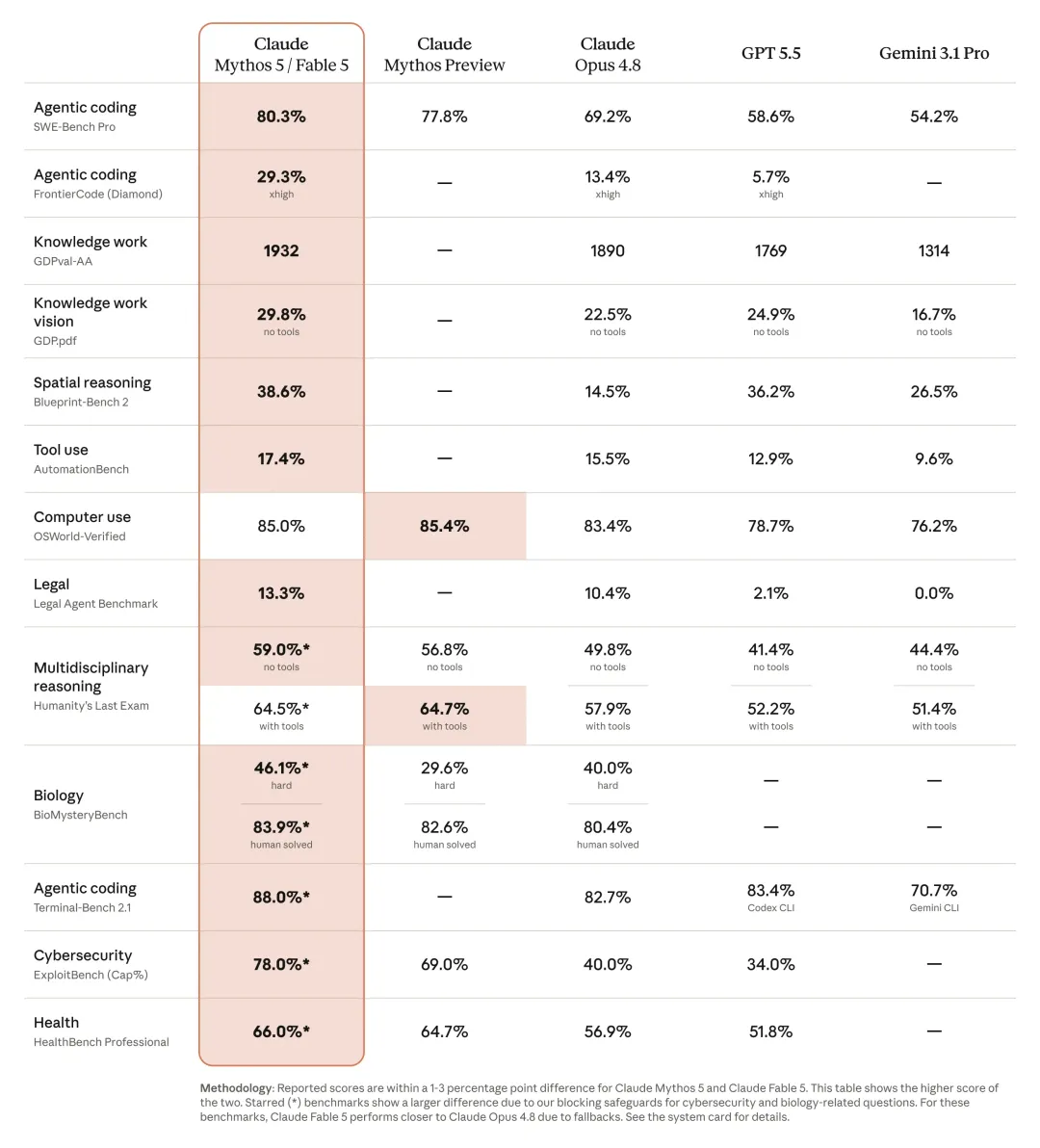
在各项测试中,Fable 5 和 Mythos 5 都是遥遥领先于其它模型,说是碾压也不过分。
在多个领域内都表现出色:
软件工程。Fable 5 具有极高的 Token 效率。在早期测试中,Stripe 报告称该模型将原本需要整个团队手动处理两个月的代码库迁移工作(5000 万行 Ruby 代码)缩短至一天。
知识工作。在复杂分析任务中表现强劲。在 Hebbia 的高级推理金融基准测试中获得最高分;在 IMC 的交易分析评估中几乎获得全胜。
视觉能力。全新的视觉 SOTA 模型。它能从详细的科学图表中提取精确数字,仅凭屏幕截图即可重建 Web 应用源码。它甚至在没有任何辅助工具的情况下,仅凭纯视觉通关了游戏《宝可梦 火红》。
记忆与长上下文。能够在跨越数百万 Token 的长期任务中保持专注,并利用自己的笔记改进输出。在游玩《杀戮尖塔》时,表现比 Opus 4.8 提升了 3 倍。
药物设计。将药物设计过程加速了约 10 倍,在无人类协助下达到或超越了熟练人类专家的水平。在双盲测试中,科学家有 ~80% 的时间更倾向于 Mythos 提出的分子生物学假设。在基因组学研究中,Mythos 5 训练的自定义机器学习模型超越了近期发表在《科学 (Science)》期刊上的模型(且体积小 100 倍)。
用一句话来形容这个模型:强得没边。
最后 Anthropic 还玩了一把饥饿营销,普通的订阅会员在6月22日之前可以免费试用 Fable 5,在这之后只能按照 API 额度来使用,后面还开不开放,看算力的负载情况再决定。
Claude Fable 5 vs GPT 5.5
性能实测
纸面成绩确实很强,那实际效果怎么样?毕竟高分低能的模型还是很多的。
AI Coding 一直是 Claude 模型的强项,这次的 Fable 5 肯定也不弱,但是对于普通用户而言,很难去直接评价 Coding 的能力,而非编程的场景表现可能是更多用户真正关心的。
这次我们从 PPT 创作、小游戏和互动网页三个项目上,对比 Fable 5 和GPT 5.5 在完成度、审美、结构、交互和细节上的差异,来看看 Fable 5 到底配不配得上最强模型的称号。
同一套提示词给两个模型,一次性生成,不追问、不修正,直接看结果。
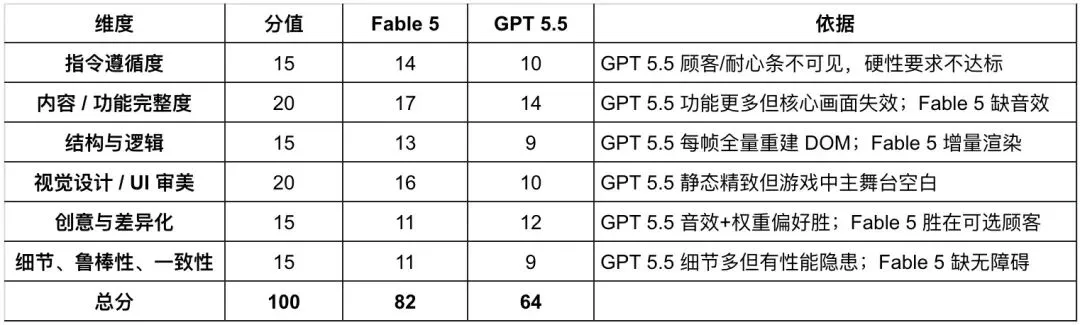
根据指令遵循度、内容/功能完整性、结构与逻辑、视觉设计和细节鲁棒性这 5 个角度评分。
两个模型都用最高的推理等级,比的就是模型的上限有多高。
小游戏生成测试
让模型生成一个网页小游戏,详细的提示词如下:
“请一次性完成一个可玩的轻量浏览器小游戏。不要只给策划案。
游戏名:《月球咖啡馆》
背景:
玩家经营一家开在月球上的小咖啡馆,需要在 90 秒内为不同外星顾客制作正确饮品,获得尽可能高的满意度。
硬性要求:
请生成一个完整的单文件 HTML,CSS 和 JavaScript 全部内嵌,不依赖外部图片、音频、字体或第三方库。
页面打开后必须能直接玩,不能只展示静态页面。
必须包含:开始页、玩法说明、游戏中界面、暂停/继续、倒计时、得分、连击、结算页、重新开始。
至少包含 3 种原料:
月尘咖啡
星云奶泡
陨石糖
至少包含 4 种外星顾客,每种顾客有不同外观、耐心值或点单偏好。
订单需要随机生成,例如“月尘咖啡 + 星云奶泡”或“星云奶泡 + 陨石糖”。
玩家点击原料完成饮品,点击“出餐”提交。正确加分,错误扣时间或扣连击。
顾客必须有耐心条,等待太久会离开并扣分。
度要随时间上升:后期顾客出现更快、耐心更低、订单更复杂。
持鼠标操作,也支持键盘快捷键:
选择月尘咖啡
选择星云奶泡
选择陨石糖
Enter:出餐
Esc:暂停
视觉风格:可爱复古科幻。请包含月球窗景、霓虹招牌、星空背景、柔和动画、按钮 hover/pressed 状态。
游戏画面优先采用 16:9 横屏布局,同时在手机宽度下也不能完全崩坏。
游戏需要有明确反馈:正确、错误、连击、顾客离开、时间快结束时都要有视觉提示。
代码中可以添加少量注释说明核心逻辑,但不要输出长篇解释。
最后请只输出完整可运行代码,不要输出额外说明。”
先看GPT 5.5 的结果,开始界面还挺像那么回事的,标题有光晕效果,有单独的玩法说明界面。
点击开始营业进入游戏界面,这里就有点不对劲了,左边的图案不知道是什么意思,可能是咖啡的液面。
右边有个咖啡杯的形状,但是杯子的形状和位置都有问题,还有个最大的bug,整个游戏中看不到任何顾客的形象。
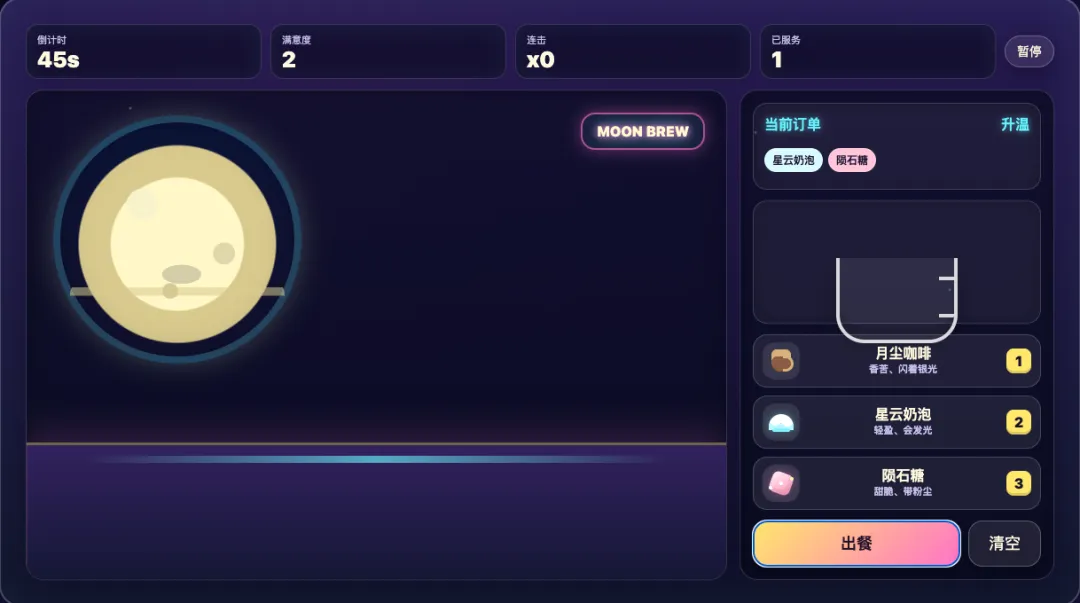
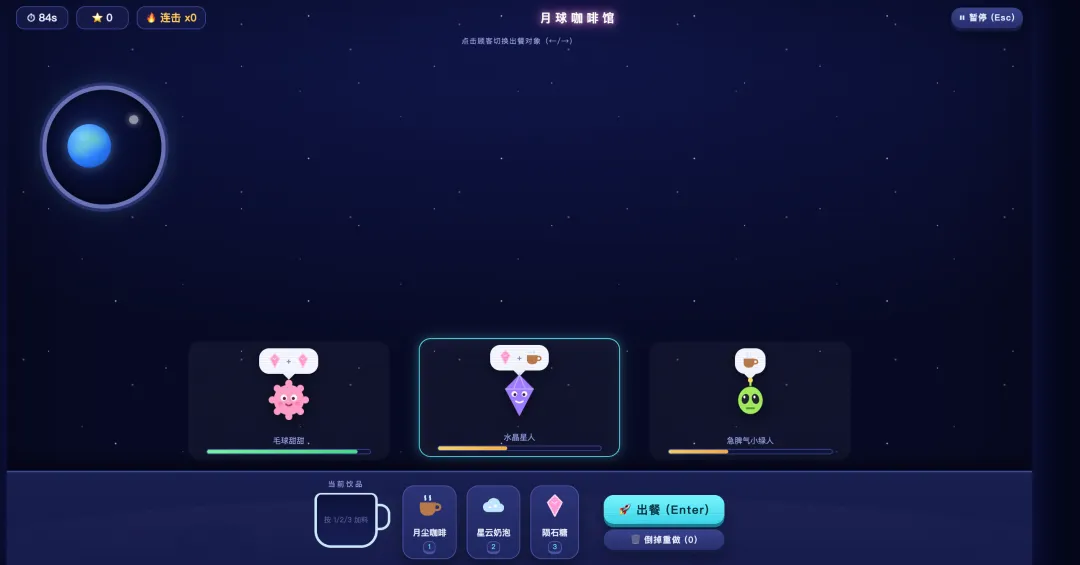
下面来看 Fable 5 这边。没有对比就没有伤害,开始界面非常精致,背景增加了太空的插画,还给咖啡馆取了英文名加上 EST. 2077,氛围感一下子就上来了。
进入游戏界面,观感差距更大,最明显的体现在 Fable 5 设计了多个外星人顾客的形象,最多同时显示 3 个顾客,让整个游戏玩法更有策略性,不管是从游戏完整度还是美观度上 Fable 5 的版本给人的第一感觉都明显要好。
但是 GPT 5.5 的版本其实有一些设计的小细节,比如:
但是最大的 bug 掩盖了其它的设计优点,在这个项目上 Fable 5 的作品相对而言是完成度更高的。
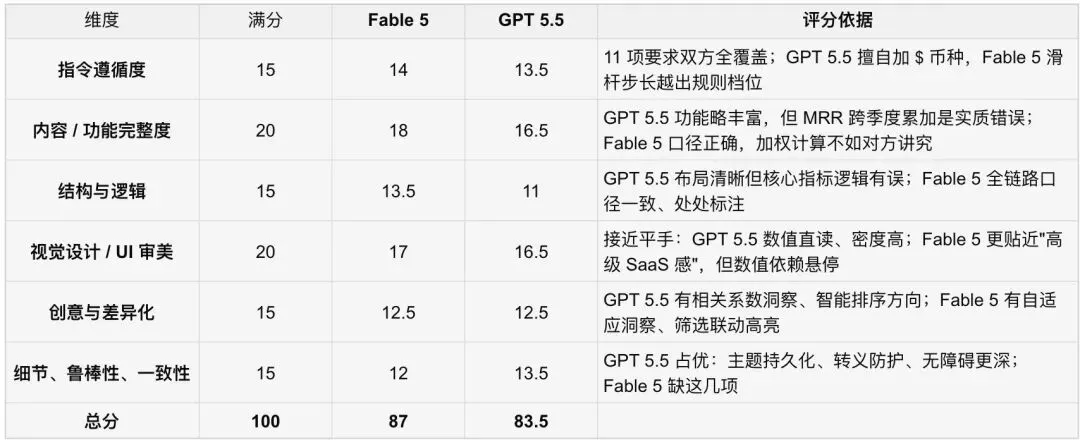
互动网页测试
下一项测试是互动网页,根据制定的提示词和数据,生成可以互动的网页,提示词如下:
“请基于下面 CSV 数据,生成一个可直接运行的单页互动数据看板。
看板名称:
《北极星订阅业务经营驾驶舱》
输出要求:
生成一个完整单文件 HTML,CSS 和 JavaScript 全部内嵌。
不使用外部库、不依赖外部图片、不联网。
所有数字必须来自下方 CSV 数据计算,不要编造额外数据。
页面需要有高级 SaaS 数据产品的设计感,而不是普通表格。
必须包含:
顶部标题区
KPI 卡片:总 MRR、总活跃用户、平均 NPS、加权平均流失率
地区筛选器
季度筛选器
MRR 趋势图
活跃用户柱状图
CAC 与流失率关系的气泡/散点图
地区经营表现对比表,支持排序
自动生成的 3 条关键洞察
一个 What-if 滑杆:模拟 ARPU 上涨或下降 -15% 到 +15%
What-if 逻辑:
当 ARPU 每上升 5%,流失率增加 0.4 个百分点。
当 ARPU 每下降 5%,流失率降低 0.3 个百分点。
根据调整后的 ARPU 和流失率,重新估算 MRR。
页面中需要显示“调整前 MRR”和“模拟后 MRR”。
图表可以用原生 SVG、Canvas 或 DOM 实现,但必须可视化,不要只用表格代替。
页面需要有暗色 / 亮色模式切换。
移动端宽度下仍然可读。
需要有基本可访问性:按钮有清晰文字,图表有简短说明。
最后只输出完整可运行代码,不要输出解释。
CSV 数据如下.......
”
这个项目考察的除了页面的设计和交互,还有最重要的一点是数据计算的准确性,这是数据类项目的前提。
从页面的设计来看,两边各有特色。
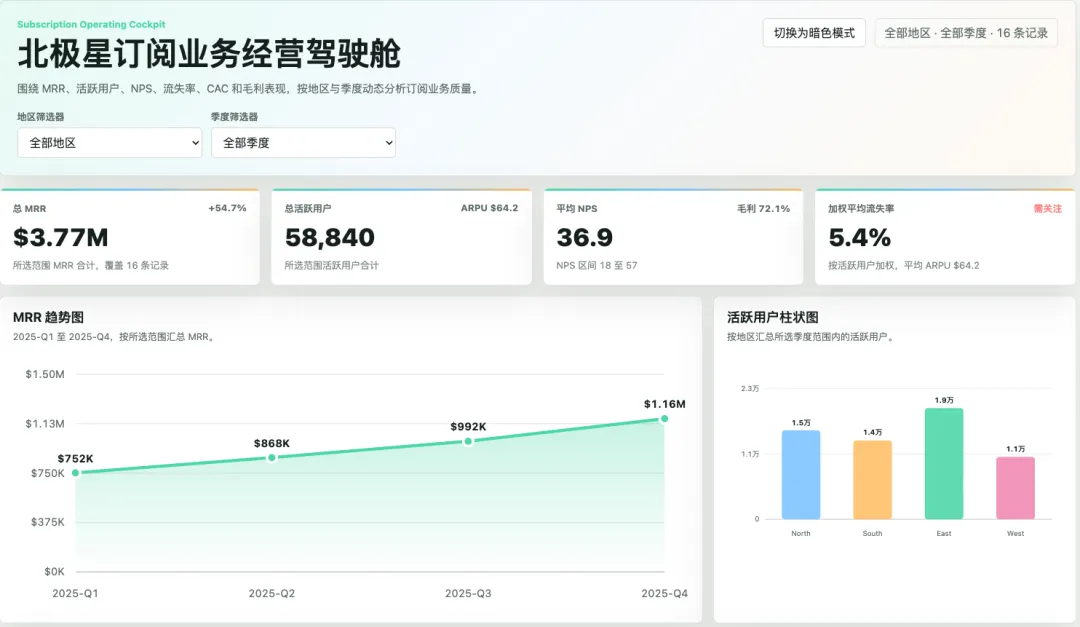
GPT 5.5 的页面整体采用绿色色调,页面展示的内容更多,能同时看到趋势图和用户活跃柱状图,数字直接标注在图标中,更直观。
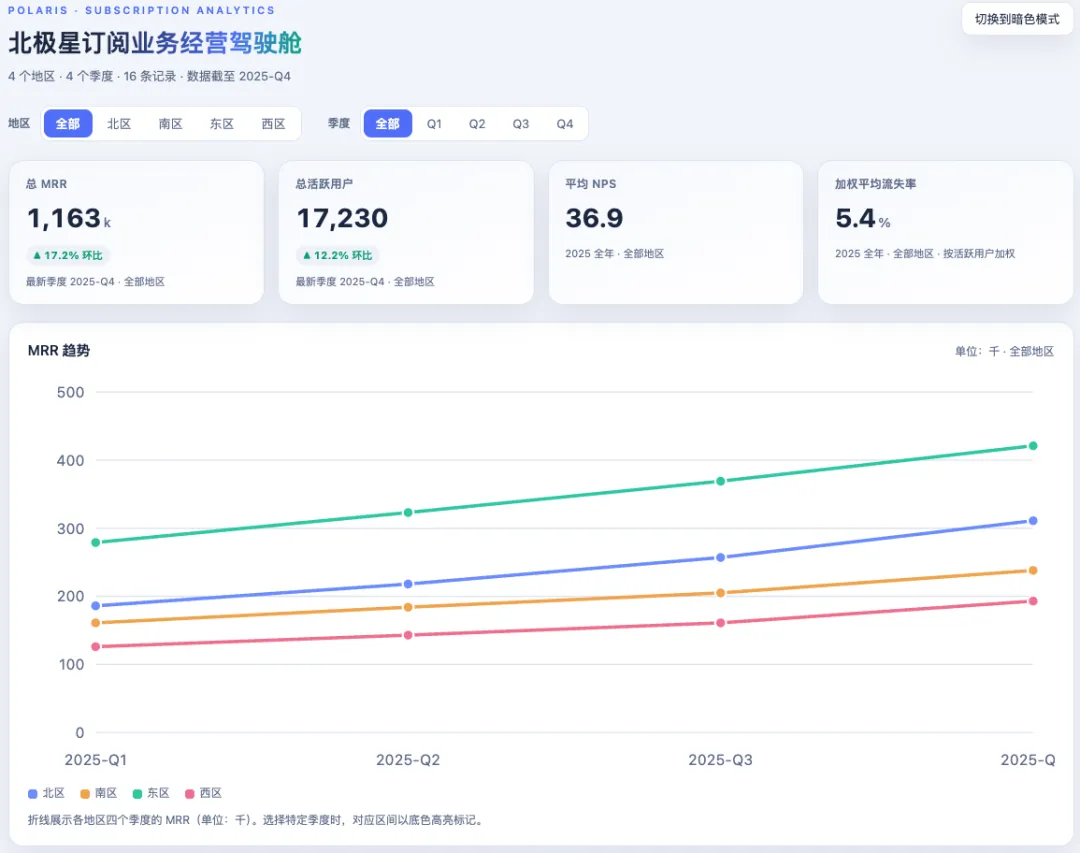
Fable 5 这边在字体上更有设计感,页面的标题采用了渐变色,但是横向显示的内容更少,也没有清晰的数字标注,不如 GPT 5.5 直接。
但是这里有个关键的差异点:“总MRR” 到底应该怎么算。
MRR 指的是 Monthly Recurring Revenue,也就是月度经常性收入,它反映的是某个时刻的经营指标,严格来说没有“总MRR”这个概念,这里也算是个小的陷阱。
先来看 GPT 5.5 的算法,它把 4 个季度的 MRR 直接相加,活跃用户数也是同样的逻辑,直接相加意味着同一批人被计算了 4 次。反观 Fable 5 这边,总MRR和活跃用户数取的是 25/Q4 的最新值,从逻辑上来说 Fable 5 的算法更准确。
除了这个错误之外,在工程和技术上,两边各有优劣。
主题切换的持久化都支持深色/浅色切换,但 GPT 5.5 做了状态保存:用户选了浅色,下次打开页面依然是浅色。而 Fable 5 没有保存这一步,刷新后会回到默认的深色。
两个版本都做了基础无障碍(按钮有明确文字、图表有文字说明),但GPT 5.5 做得更深:每张图表内置了完整的数据文字描述,读屏软件可以直接把图表内容朗读出来;筛选结果和模拟结果的区域还加了"动态播报",数据一变,读屏用户能立刻收到更新。Fable 5 仅仅停留在"能用"的层面。
GPT 5.5 的代码里还有个小细节,增加了一道"安检"机制:所有要显示到页面上的文字都先转义,防止有人往数据里塞恶意内容。虽然这个场景下其实用不上——数据是写死在页面里的,没人能改——但这是个很好的工程习惯,值得肯定。
在互动网页这个环节,两边的设计其实各有特点,GPT 5.5 在工程和技术上还藏了很多小细节,但很可惜的是在最开始的数据计算上犯了根本性的错误,Fable 5 的版本更成熟、可用性更高。
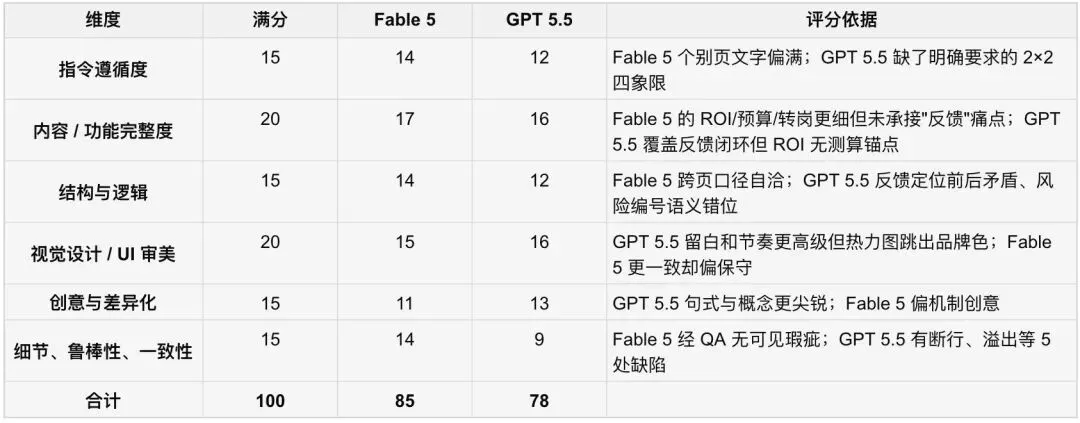
PPT 生成测试
最后是 PPT 生成测试,这里不使用任何 PPT 生成的 skill,只看模型的原生能力,提示词如下:
“请生成一份可直接给董事会汇报的中文 16:9 PPT。
主题:
《从工具到同事:AI Agent 在连锁咖啡品牌 Luma Coffee 的 90 天落地方案》
公司背景:
Luma Coffee 是一家中高端连锁咖啡品牌:
全国 218 家门店
年营收约 18 亿元
注册会员 1200 万
线上小程序订单占比 46%
主要痛点:
客服响应慢,高峰期平均首次响应 9 分钟
门店排班依赖店长经验,临时调班频繁
营销素材生产慢,新品上架平均需要 18 天准备周期
用户反馈分散在小程序、点评平台、社群和客服系统里
管理层目标:
90 天内完成 AI Agent 试点
不替代门店员工,而是提升效率
试点预算不超过 500 万元
必须控制数据安全和品牌风险
PPT 要求:
总共 12 页。
每页必须有一个“结论型标题”,不要用空泛标题。例如不要写“市场背景”,而要写“AI Agent 的价值首先来自高频、重复、可验证的运营环节”。
受众是董事会和 CEO,风格要像顶级咨询公司 + 高端消费品牌发布会。
每页文字不要堆满,优先用图示、表格、流程图、矩阵、时间轴表达。
......”
先看PPT首页,这一页能看出整个 PPT 的视觉设计风格。
GPT 5.5 左侧奶油色竖条 + 蓝色细线分割,右上"AI 行星轨道"插画,标题区大量留白,三个关键数字(218 / 46% / 500 万)各配一行论证性注释,这个细节不错。但是"总部与门/店"不应该换行。
Fable 5 采用全幅深咖啡 + 拉花同心圆装饰,底部是四个指标数据。信息更全,但数字只陈述、不解释。
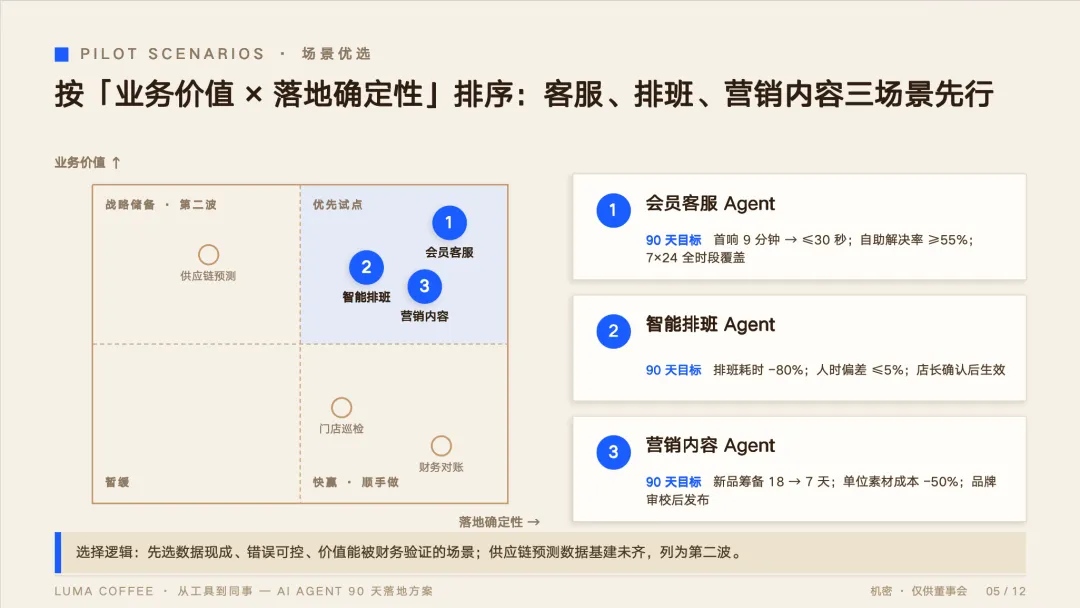
第 5 页是讨论试点场景的选择。GPT 5.5 只画了坐标轴 + 一块"优先试点区"高亮,左下区域的"反馈洞察"“会员权益”没有明确的说明。Fable 5 有完整的 2×2,四个象限都有战略标注,每个场景都有明确的落点,试点场景增加了 90 天量化目标。
第10页风险热力图。
GPT 5.5 用了传统红黄绿热力色,在深咖啡底上色系冲突明显,是整个PPT中唯一跳出品牌色的页面。但是这里有个逻辑上的错误:热力图上的 R1–R5 点位标的是风险位置,但是右侧却写的是对策,逻辑上不统一。
Fable 5 在热力图上直接写出 R1–R6 的风险名称,右侧是和风险对应的措施,逻辑清晰,内容完整。
整体风格上 GPT 5.5 是"海报式极简"风格——大留白、等宽字体、低信息密度,气质接近发布会 Keynote,而Fable 5 则是"咨询式高密度"——每页一个完整论证闭环,机制细节多,气质接近麦肯锡的风格。 内容上双方框架高度相似,但数字口径、论证锚点和工艺质量差异明显。
经过上面三个简单项目的测试,可以明显感受到,这次发布的 Fable 5 确实有实力。无论是工程实现还是设计完成度,几个作品都表现得相当成熟,基本不需要大幅修改,第一版就已经接近可直接使用的状态。
相比之下,GPT 5.5 在部分细节上也有不少可圈可点之处,但整体来看,仍然需要更多优化和打磨。
当然,Fable 5 虽然表现亮眼,却并不适合所有人。
最直接的原因是成本。它的额度消耗是 Opus 的 2 倍。虽然官方强调 token 效率有所提升,但从我的实际体验来看,这一点并不明显。Pro 用户如果做一个稍微大一点的项目,很快就会触发冷却。
另一个不得不提的问题,是 Claude 的客户端体验。之前我转向 Codex,很大一部分原因就是 Claude 客户端用起来不够顺手。现在隔了这么多个版本再回来体验,还是忍不住想吐槽:Claude 客户端在产品设计和使用体验上,和 Codex 相比依然有明显差距。
所以现阶段,我觉得 Fable 5 很适合尝鲜,也很适合拿来做能力上限测试。但如果作为日常高频使用的生产力工具,我目前还是更推荐 Codex。
而且,Fable 5 这次表现得这么强势,GPT 5.6 还会远吗?











 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
