如果你是工厂的 IE 工程师,面对这样一堆 BOM 表,你会怎么办。
一个一个测。一个产品 5 道工序,测完 1828 个,明年都交不了差。
估。估出来的数,生产部不信,财务部不敢用,排产计划永远在扯皮。
这不是假设。这是我这一周真实面对的问题。
一、先搞清楚到底有什么
事情的开头是一份 BOM 数据。
ERP 导出来的,Excel 格式,9119 行。每一行代表一个产品下面的一个原材料。产品叫「母件」,原材料叫「子件」。
比如产品 040110740805,它的 BOM 结构很简单。插头 ×2M12 传感器连接器 ×1弯式电缆护套插头 M16 ×1
就这么简单。母件到子件,一层展开,没有嵌套。
但这些看起来规规整整的数据,读起来却费了老大劲。ERP 导出的 xlsx 不是标准格式,openpyxl 和 pandas 直接报错。得用 PowerShell 调 Excel COM 对象来读,日期存的是序列号(45509 = 2024-08-09),表头还合并单元格。
够折腾的。
但折腾完发现,事情反而简单了。
315 种子件,拉到 ABC 分析表上一看,电线类和连接器类占了总工时的 90% 以上。剩下的密封圈、标签、扎带,都是辅助物料,对工时影响微乎其微。
这个发现很重要。
它让我意识到:我不需要建立一个复杂的模型。我只需要搞清楚两件事。这个产品用了什么电线,装了什么连接器。
有了这个认知,我设计了一个工时测定方案:选 12 个最有代表性的料号,覆盖最常见的连接器组合场景,逐个实测工时。然后拿这 12 个作为基准,去推算剩下的 1816 种产品。
听起来很合理。但具体怎么「推算」?
二、欧氏距离试过了,不行
第一版我用的是欧氏距离。
把每个产品的连接器特征变成一个向量。插头 2 个、M12 传感器 1 个、M16 插头 1 个……然后跟 20 个基准向量算距离,取最近的作为匹配结果。
代码跑通了,结果也出来了。覆盖率大概 89%。
但有个致命的问题。说不清为什么。
一个产品匹配到了基准 A 而不是基准 B。你问为什么。因为欧氏距离更小。但距离小意味着什么?意味着在 N 维空间里更近。这对业务人员来说毫无意义。
「所以呢?为什么是这个产品跟我像?」
「呃……因为它在向量空间里离你更近……」
这种对话进行不下去的。
制造业的工程师不信黑盒。他们需要一个能说清楚的理由:因为你们都有插头和 M12,而且插头数量只差 1 个。
这让我换了一个思路:不看数量,先看类型。
三、核心创新:类型签名
什么叫类型签名。
把每个产品的连接器特征中,数量大于 0 的类型挑出来,排序,得到一个字符串数组。
比如产品 A 有「插头 ×2、防水接头 ×1」,签名是 [插头, 防水接头]。产品 B 有「插头 ×1、防水接头 ×1」,签名也是 [插头, 防水接头]。产品 C 有「插头 ×2、M12 ×1」,签名是 [插头, M12]。
A 和 B 签名相同,所以它们是一类产品。C 跟它们签名不同,不是一类。
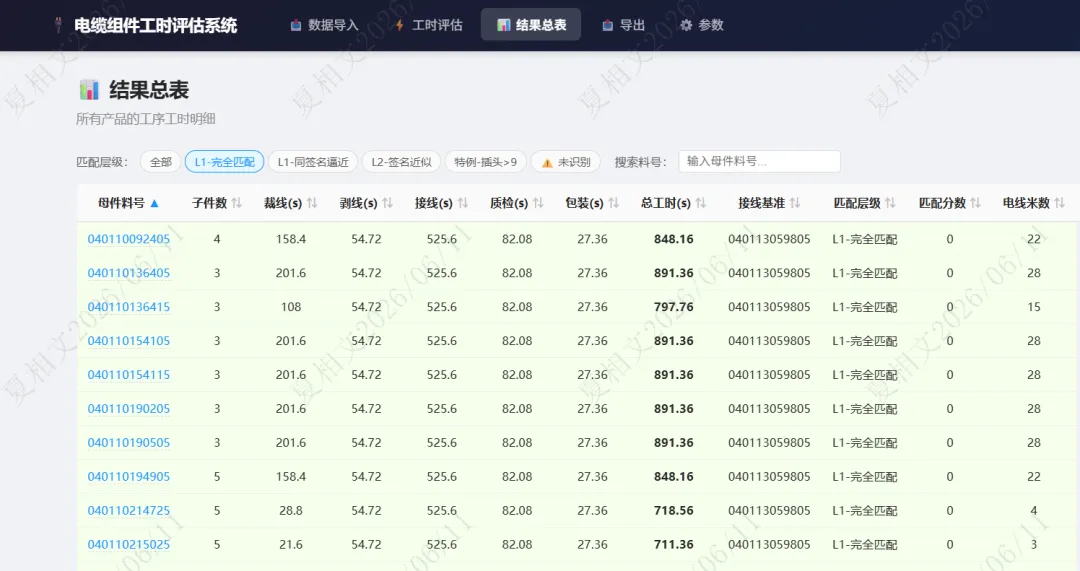
这就是分层匹配的第一层。L1-完全匹配。
如果签名相同,再比数量。插头差 1 个扣 10 分,M12 差 1 个扣 5 分,选扣分最少的基准。这叫 L1-同签名逼近。
如果签名根本不一样,就进入第二层。L2-签名近似。看签名的交集和差集,用一套加权公式算相似度,选最接近的。
这套规则看起来简单,但效果出乎意料的好。
L1-完全匹配(签名完全相同,唯一命中):覆盖约 35%L1-同签名逼近(签名相同,数量差异最小):覆盖约 63%L2-签名近似(签名不同但最接近):覆盖约 2%
L1 合计:98%。
只有 2% 的产品需要人工复核。
更重要的是,这套规则完全可解释。任何一个产品匹配了哪个基准,你都能说清楚。因为类型签名一致,插头数量差 2 个,M12 数量差 1 个……
业务人员听得懂,信得过,还能自己调权重。
技术上的感悟是:很多问题,解决方案不是更复杂的模型,而是更清晰的规则。
四、从命令行到拖拽上传
算法搞定了。但离「用起来」还差一步。
最初的版本是 Python 脚本。python evaluate_all.py,跑完出 CSV。能做数据分析的人用得挺好,但车间里的同事呢。不会装 Python,不会配环境,甚至不太习惯敲命令行。
这个工具要想真正产生价值,需要变成一个打开浏览器就能用的东西。
于是有了第二段开发。一个纯前端的 Web 应用。
零后端,零数据库,零框架。6 个 JS 文件,1 个 HTML,1 个 CSS。
config.js 管参数配置和 localStorage 持久化。公式存在浏览器里,下次打开还在。parser.js 管文件解析。JSON 和 xlsx 都支持,xlsx 还做了多重容错策略,对付 ERP 导出的各种奇奇怪怪的格式。engine.js 是核心引擎。特征提取加分层匹配加 5 工序计算。ui.js 渲染表格、看板、图表、分页、筛选、排序。export.js 做导出。CSV、Excel(4 个 Sheet)、工艺路线 33 列模板。app.js 是胶水代码,把上面所有东西串起来。
我最满意的一个设计是特征提取的优先级链。
子件名称千奇百怪。有的叫「防水插头」,有的叫「航空插头 M12」,有的就叫「插头」。如果按顺序匹配关键词,防水插头必须先于插头匹配,否则会被错误归类。传感器线缆必须先于电缆匹配,否则会被当成普通电线。
检测顺序变成了一串 if-else:
1. 电源线 → 电源线米数2. 信号线 → 信号线米数3. 传感器线缆 → 传感器线缆米数4. 防水插头 → 防水插头数量5. M12 传感器连接器 → M12 数量6. 航空插头 → 航空插头数量7. 插头 → 普通插头数量
优先级即逻辑。逻辑即代码。代码即规则。
没有机器学习,没有神经网络。几十条 if-else,把业务知识直接翻译成了程序逻辑。数据见得多的人会明白,很多时候 if-else 比神经网络更可靠。前提是你得真的懂业务。
五、导出:最后一公里
工具做完了,能算了,能看了。
但制造业有个硬需求。数据要能进 ERP。
于是做了工艺路线导出。按 ERP 导入模板的 33 列格式,每个产品生成 5 行记录。裁线 D01、剥线 D02、接线 D03、质检 D04、包装 D05。标准工时填在第 24 列,单位填「秒」。
Excel 导出另外还有汇总统计、工时分布、基准覆盖 3 个 Sheet,加起来 4 个 Sheet。
一个完整的数据闭环。导入到计算到查看到导出到导入 ERP。
六、一周的感悟
从第一行 Python 代码到最终的 Web 应用,刚好一周。
回头看,最有价值的部分不是代码本身。而是找到了一种让业务人员能理解、能信任的算法。欧氏距离能做到 89%,但没人信。规则匹配做到 98%,而且每个人都能看懂。
技术选型上,纯前端架构是一个正确的决定。对于这种内部工具,部署一个服务器就是多一道门槛。「双击 html 文件就能打开」和「先装 Node.js 跑 npm install」,对一线同事来说,区别太大了。
20 个基准,1828 种产品,5 道工序。
一周前是 Excel 里一堆没人说得清的数字。一周后是一个打开浏览器就能算标准工时的系统。
工具的价值在于让专业的人不需要成为技术专家,也能用上技术的力量。
技术栈:HTML / CSS / JavaScript / SheetJS | 工具:Claude Code | 数据来源:企业 ERP BOM 数据