根据工资表自动生成工资条
一、前言
在日常工作中,制作工资条是常见需求,但网上多数教程都依赖辅助列或手动操作。这种方法存在明显缺陷:当原始数据发生变动(如增减人员)时,工资条无法自动更新,尤其在需要分页打印的情况下尤为不便。为此,我采用LET函数开发了一种解决方案,不仅能自动生成工资条,其原理还可应用于其他需要分页打印的表格场景。
工资条结构:表头行 → 单人员工数据行 → 空白分隔行,三行一组循环生成。
原始数据示例: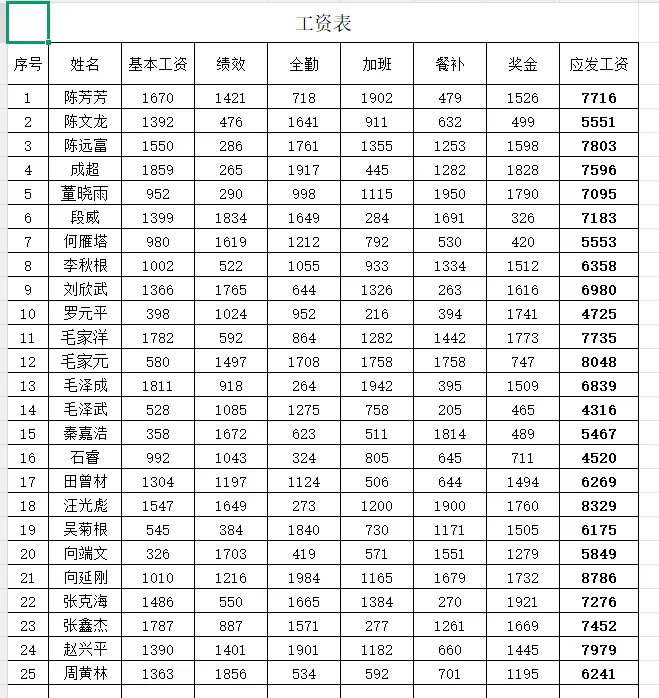
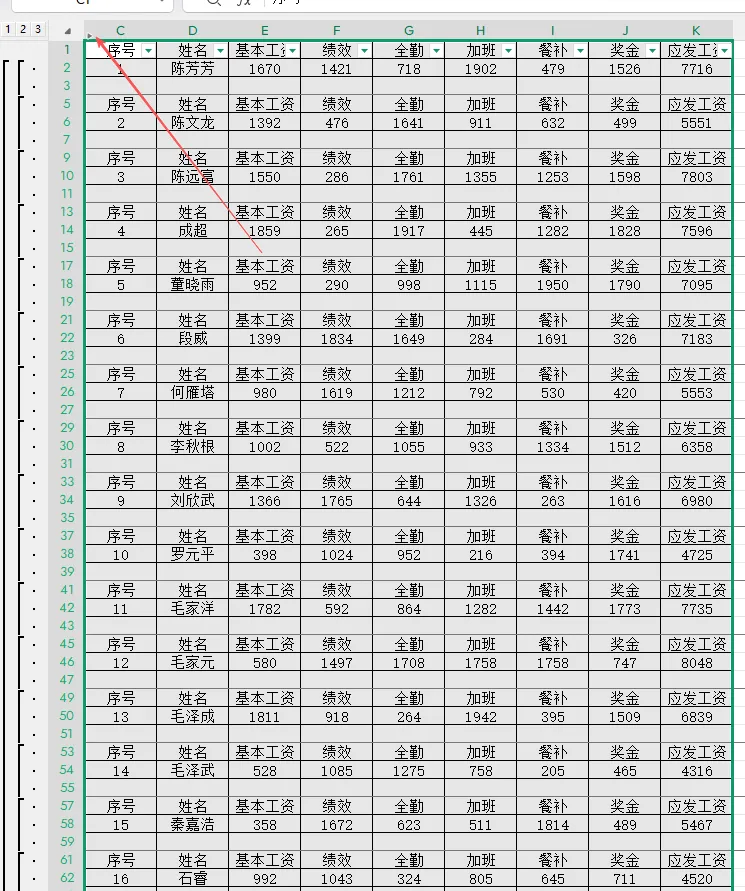
转换后工资条效果:
二、LET函数概述
语法
LET(变量名1,值1,[变量名2,值2],...,结果表达式)
核心作用
本公式用到变量
raw、header、n、pool、seq、block、row_idx
最终输出:CHOOSEROWS(pool,row_idx)
公式整体框架
=LET(
raw,数据区域,
header,表头区域,
n,数据行数,
pool,合并缓冲数组,
seq,序号序列,
block,分组编号,
row_idx,最终行索引,
CHOOSEROWS(pool,row_idx)
)
三、逐变量公式拆解解析
3.1 raw 变量定义
核心函数
CHOOSEROWS(数组,行索引序列):按指定行号批量提取数据行。
变量公式
raw,CHOOSEROWS(A1:I220,ROW(A3#))
也可简写固定区域:raw,A3:I27,要求原始数据无空行。
测试公式
=LET(
raw,CHOOSEROWS(A1:I220,ROW(A3#)),
raw
)
raw输出效果:
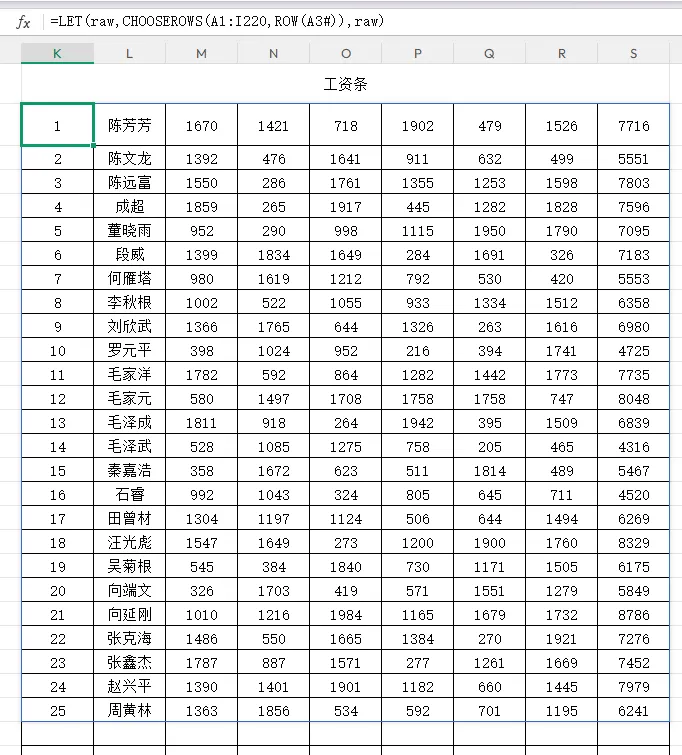
3.2 header 变量定义
直接固定引用表头行区域:A2:I2
测试公式
=LET(
raw,CHOOSEROWS(A1:I220,ROW(A3#)),
header,A2:I2,
header
)
header输出效果:
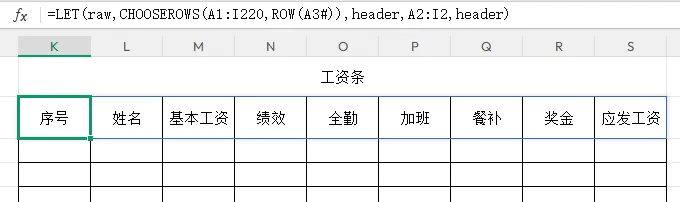
3.3 n 变量定义
函数
ROWS(数据区域):统计数据总行数
变量公式
n,ROWS(raw)
示例中员工数据共 n=25行。
测试公式
=LET(
raw,CHOOSEROWS(A1:I220,ROW(A3#)),
header,A2:I2,
n,ROWS(raw),
n
)
3.4 pool 变量定义
用到函数
变量公式
pool,VSTACK(raw,header,EXPAND("",1,9,""))
数组结构说明
测试公式
=LET(
raw,CHOOSEROWS(A1:I220,ROW(A3#)),
header,A2:I2,
n,ROWS(raw),
pool,VSTACK(raw,header,EXPAND("",1,9,"")),
pool
)
pool输出效果:
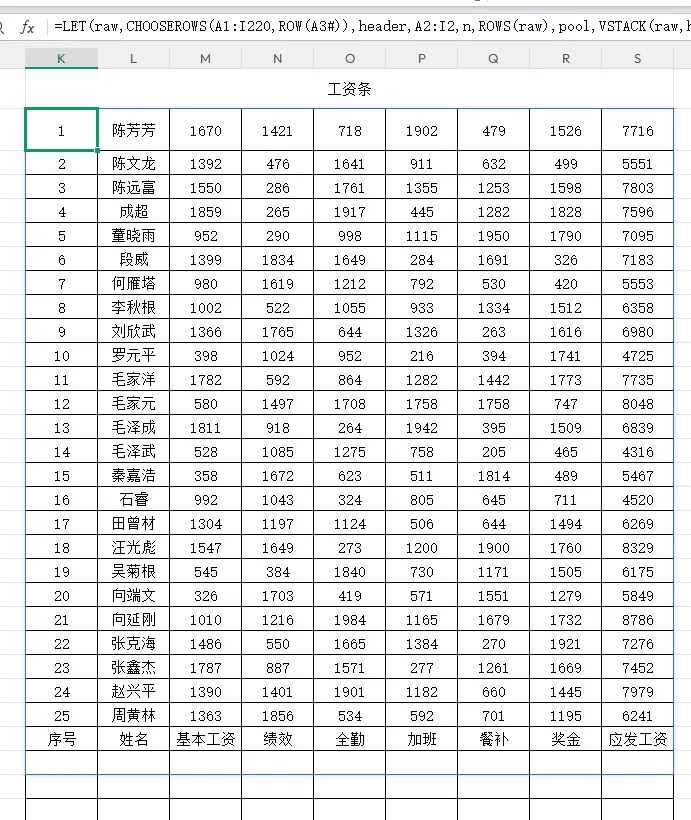
3.5 seq 序列生成
函数
SEQUENCE(行数,[列数],[起始值],[增量])
变量公式
seq,SEQUENCE(3*n,,0)
生成 0 ~ 3n-1 连续序号,示例n=25,生成0~74共75个序号。
3.6 block 分组逻辑
变量公式
block,INT(seq/3)+1
逻辑:每3个连续序号分为一组,匹配「表头+数据+空行」3行结构。
分组映射示例
3.7 row_idx 核心行索引逻辑
核心公式
row_idx,CHOOSE(MOD(seq,3)+1,n+1,block,n+2)
分步逻辑解析
- MOD(seq,3)
- +1 偏移
把0起始索引转为1起始:0→1、1→2、2→3,适配CHOOSE参数; - CHOOSE三分支匹配
- 索引=2 → 返回 block:取对应分组的员工数据行
行索引运算示例
四、最终完整工资条公式
=LET(
raw,CHOOSEROWS(A1:I220,ROW(A3#)),
header,A2:I2,
n,ROWS(raw),
pool,VSTACK(raw,header,EXPAND("",1,9,"")),
seq,SEQUENCE(3*n,,0),
block,INT(seq/3)+1,
row_idx,CHOOSE(MOD(seq,3)+1,n+1,block,n+2),
CHOOSEROWS(pool,row_idx)
)
五、动态数组性能分析
5.1 核心特性
内存隔离
:LET内部变量为临时内存数组,运算结束自动释放;维度固化
指针传参
:仅传递数组内存地址,无冗余拷贝,大幅降低内存开销。
5.2 内存隔离机制
LET内部所有变量均为局部临时数组,仅公式执行周期内有效;不污染全局命名空间,天然隔离多公式之间变量冲突。
5.3 数组维度规范
5.4 指针传递优化
- 单次传参仅增加4~8字节内存开销;超大数组场景可降低99% 无效内存占用。
5.5 理论性能数据对比
5.6 理论性能计算公式与规律
核心规律
理论公式
- 总独立单元格数:
(N+2)×9 + 9N + 27N - 内存估算(KB):
总单元格数 × 28 ÷ 1024
六、公式核心优势详解
模块化高效架构
纯函数智能分组
极致性能表现
弹性扩展能力
七、分页打印
由于我们已经对数据进行了block分组,只需在公式末尾将分组结果拼接即可:
=LET(
raw_data,CHOOSEROWS(A1:I220,ROW(A3#)),
headers, A2:I2,
row_count,ROWS(raw_data),
data_pool,VSTACK(raw_data, headers,EXPAND("",1,9,"")),
sequence,SEQUENCE(3*row_count,,0),
block_group,INT(sequence/3)+1,
row_index,CHOOSE(MOD(sequence,3)+1, row_count+1, block_group, row_count+2),
//CHOOSEROWS(data_pool, row_index) 替换掉原公式
HSTACK(block_group,CHOOSEROWS(data_pool, row_index))
)
输出效果: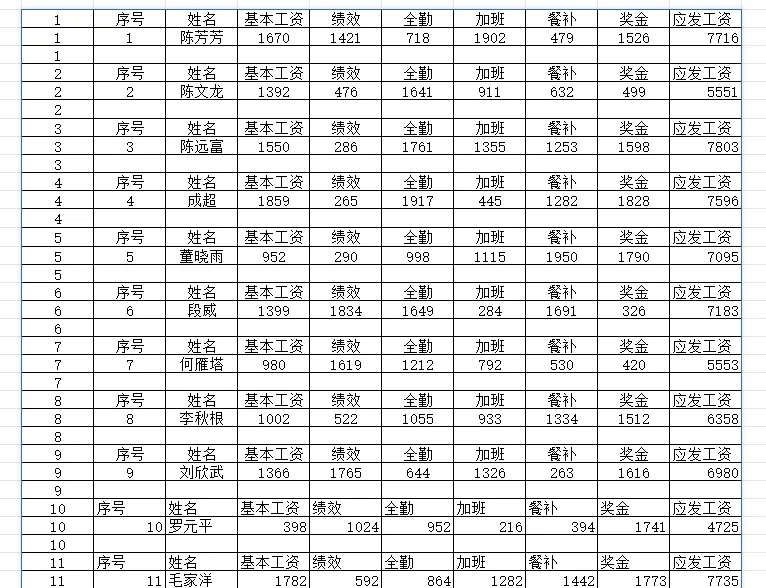 然后按以下步骤操作:点击"确定"完成操作(参考下图):
然后按以下步骤操作:点击"确定"完成操作(参考下图):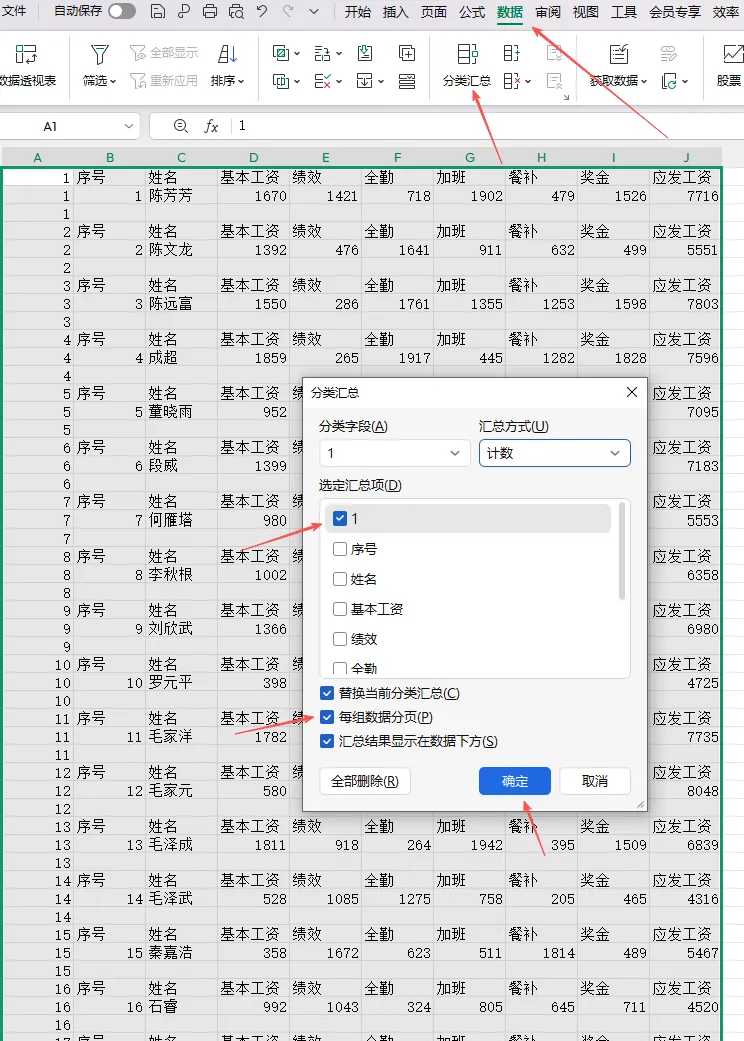 筛选A列中的空白单元格(如图示):
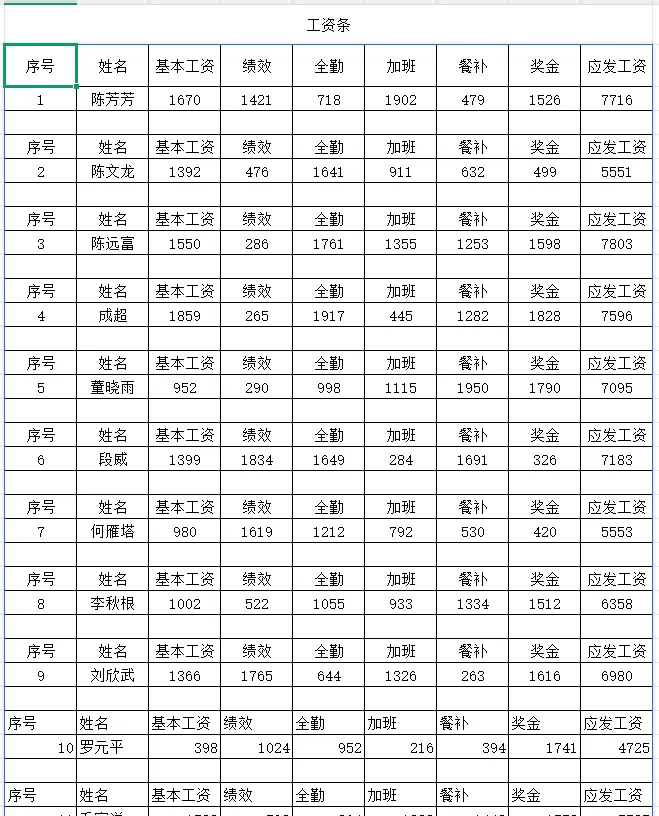
筛选A列中的空白单元格(如图示):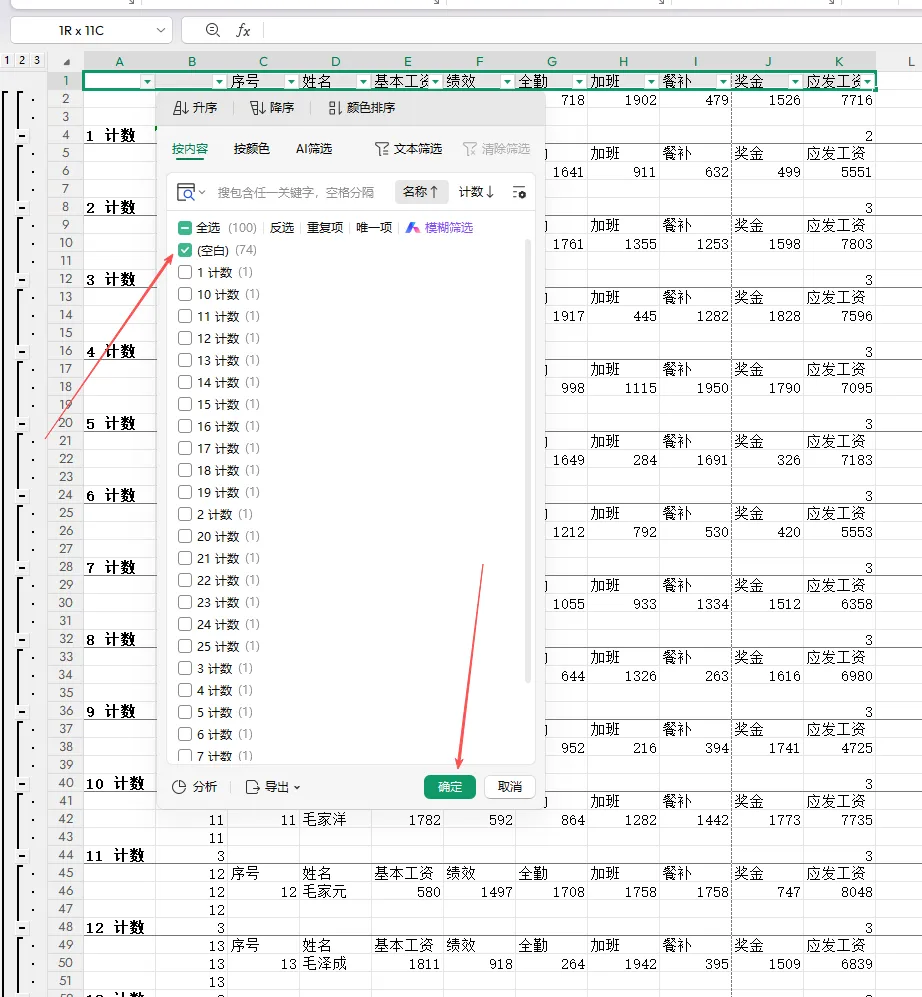 隐藏A、B列后,仅保留必要的数据列,调整单元格格式即可直接打印
隐藏A、B列后,仅保留必要的数据列,调整单元格格式即可直接打印最终打印预览时,每页对应一位人员信息。
八、版本兼容与实操注意事项
8.1 兼容版本要求
必须支持 LET/VSTACK/SEQUENCE/CHOOSEROWS 新函数:
版本查看:文件 → 账户/帮助 → 关于
8.2 操作建议
- 应用复杂公式前,先备份原始数据,建议在测试表验证效果;
https://v.douyin.com/4k_OFGZ8uUg/ :4pm iCh:/ 05/03 S@L.Jv
参考链接:

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
