你好,我是小A。
这是AI作战笔记的第三十一篇,也是扣子工作流第10篇,AI实战记录版块的第13篇。
前几篇,我们实现了单文件处理、自动推送、图表生成。今天更进一步:让AI自动解析Excel文件,提取结构化数据。
你是不是也这样?每个月收到各部门的报表,想合并分析,但不知道如何让程序读懂Excel。今天教你用扣子代码节点,一次上传,自动解析。
说明:扣子单次上传仅支持单个Excel文件。如需处理多个文件,可多次运行后手动汇总,或使用循环节点逐个处理。本文以单个文件解析为例,多个文件的逻辑同理。
一、场景痛点:Excel解析太麻烦
想用程序处理Excel数据,但pandas等库在扣子沙箱里装不上。自己从头写解析代码?听起来就很难。
今天教你一招:用Python标准库直接解析xlsx文件。xlsx本质是zip压缩包+XML文件,我们直接读取,不依赖任何第三方库。
二、解决方案:代码节点 + 标准库解析
在扣子开始节点,上传一个Excel文件。代码节点接收文件,用Python标准库(zipfile、xml.etree)直接解析xlsx格式,提取工作表数据和列名。
关键优势:不需要安装pandas、openpyxl等第三方库,扣子沙箱里直接跑通。
三、核心代码(标准库版,直接可用)
python
import zipfileimport xml.etree.ElementTree as ETimport urllib.requestfrom io import BytesIOasyncdefmain(args: Args)-> Output: params = args.params# 变量名需与代码节点输入参数名完全一致 file_url = params.get("all_data")ifnot file_url:return{"row_count":0,"columns":[],"merged_data":[],"summary":"未接收到文件"}try:with urllib.request.urlopen(file_url, timeout=30)as resp: file_bytes = BytesIO(resp.read()) rows =[] columns =[]with zipfile.ZipFile(file_bytes)as z:# 读取共享字符串表 shared_strings =[]if'xl/sharedStrings.xml'in z.namelist(): ss_tree = ET.parse(z.open('xl/sharedStrings.xml')) ns ={'ns':'http://schemas.openxmlformats.org/spreadsheetml/2006/main'}for si in ss_tree.findall('.//ns:si', ns): texts = si.findall('.//ns:t', ns) shared_strings.append(''.join(t.text or''for t in texts))# 读取工作表 sheet_tree = ET.parse(z.open('xl/worksheets/sheet1.xml')) ns ={'ns':'http://schemas.openxmlformats.org/spreadsheetml/2006/main'}for row_elem in sheet_tree.findall('.//ns:row', ns): row_data =[]for cell in row_elem.findall('ns:c', ns): cell_type = cell.get('t','') value_elem = cell.find('ns:v', ns)if value_elem isnotNone: value = value_elem.textif cell_type =='s': value = shared_strings[int(value)] row_data.append(value)else: row_data.append('')if row_data:ifnot columns: columns = row_dataelse: rows.append(row_data) result =[dict(zip(columns, row))for row in rows]return{"row_count":len(result),"columns": columns,"merged_data": result,"summary":f"解析完成,共{len(result)}行{len(columns)}列"}except Exception as e:return{"row_count":0,"columns":[],"merged_data":[],"summary":f"解析失败:{str(e)}"}代码说明:
第1-4行:只用Python标准库,无需安装pandas/openpyxl,扣子沙箱里可直接运行
params.get("all_data"):变量名需与代码节点输入参数名完全一致(本例为all_data)
urllib.request.urlopen:通过URL下载上传的文件
zipfile.ZipFile + xml.etree:xlsx本质是zip压缩包+XML文件,直接解析共享字符串表和工作表数据,提取行列内容
异常处理:解析失败时返回空数据,避免结束节点报错
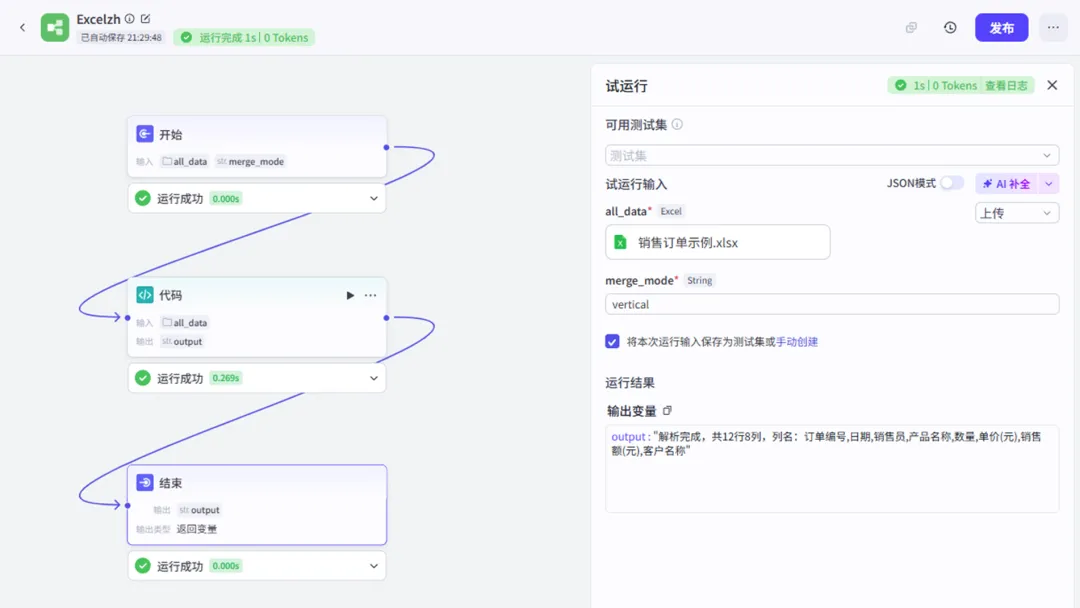
四、使用步骤
配置开始节点:添加输入参数,类型选Excel,命名为all_data(与代码中一致)
添加代码节点:
连线:开始 → 代码 → 结束,结束节点的输出关联代码节点的summary
运行测试:点击“试运行”,上传一个.xlsx文件
查看结果:运行成功后,可查看行数、列数及解析出的数据
五、注意事项
代码节点语言务必选Python(不是JavaScript)
变量名必须一致:代码中的params.get("all_data")需与代码节点输入参数名完全相同(本例为all_data)
扣子沙箱不支持pandas、openpyxl,本方案只用标准库,100%可运行
仅支持.xlsx格式(Excel 2007及以上版本),不支持.xls或.csv。如遇旧格式文件,请先用Excel另存为.xlsx
结束节点的输出务必关联代码节点的summary,不要关联开始节点的输入
如需解析多张工作表,可修改代码中的sheet1.xml为目标工作表名称
六、从今天开始
如果你想搭建自己的Excel解析系统:
准备一个.xlsx文件(测试用)
在扣子中创建本工作流,复制上面的代码
按“使用步骤”配置输入输出参数
试运行,上传文件
查看解析结果
你不需要安装任何第三方库,纯标准库搞定Excel解析。
下一篇预告
扣子工作流第11篇——数据清洗自动化:让AI帮你处理缺失值、重复值、异常值。
小A
于2026年5月8日

