讨论 AI PPT 工具时,大多数分析关注的是模型能力——"GPT-4 够不够聪明"、"Claude 的视觉理解够不够好"。但真正的瓶颈不在模型这一端,而在输出格式这一端。每个 AI PPT 工具最终都要生成一个 .pptx 文件,而 .pptx 背后是 OOXML(Office Open XML)——一个 6,546 页的 ISO 标准,27 个 XML 命名空间,三级主题继承链。没有任何 AI 模型被训练来理解这个格式的全部复杂性,也没有任何生成库完整实现了这个规范。.pptx 文件不是一个简单的文档,它是一个 ZIP 压缩包,里面是几十个 XML 文件和关系声明,遵循 OOXML(ISO/IEC 29500)标准。这个标准有 6,546 页,包含 27 个命名空间和 89 个 schema 模块。AI PPT 工具生成的每个"幻灯片"都必须翻译成合法的 OOXML XML——而这个翻译过程,就是所有模板不匹配、字体丢失、布局错位问题的根源。一个 .pptx 文件的核心是四层继承链:Theme → Slide Master → Slide Layout → Slide。颜色、字体、效果从 Theme 层层传递下来。AI 生成工具如果跳过了任何一层,输出的幻灯片在 PowerPoint 中的渲染就会出问题。
你现有的模型(可能是错的)
大多数人认为 .pptx 是一种"文档格式",类似于 .txt 或 .pdf——一个文件,一种内容。
实际上,.pptx 是一个结构化的 ZIP 压缩包,里面包含几十个 XML 文件,它们之间通过 relationship 文件互相引用。一张幻灯片不是一个独立的实体——它依赖于 Slide Layout、Slide Master 和 Theme 三个上层结构。改动 Theme 里的颜色方案,所有幻灯片的颜色都会跟着变;但如果某张幻灯片绕过了继承链直接硬编码颜色值,它就脱离了 Theme 的控制。
这就是 AI PPT 工具的核心困境:AI 生成的内容通常是"硬编码"的,不参与继承链。
真实的机制
.pptx 的内部解剖
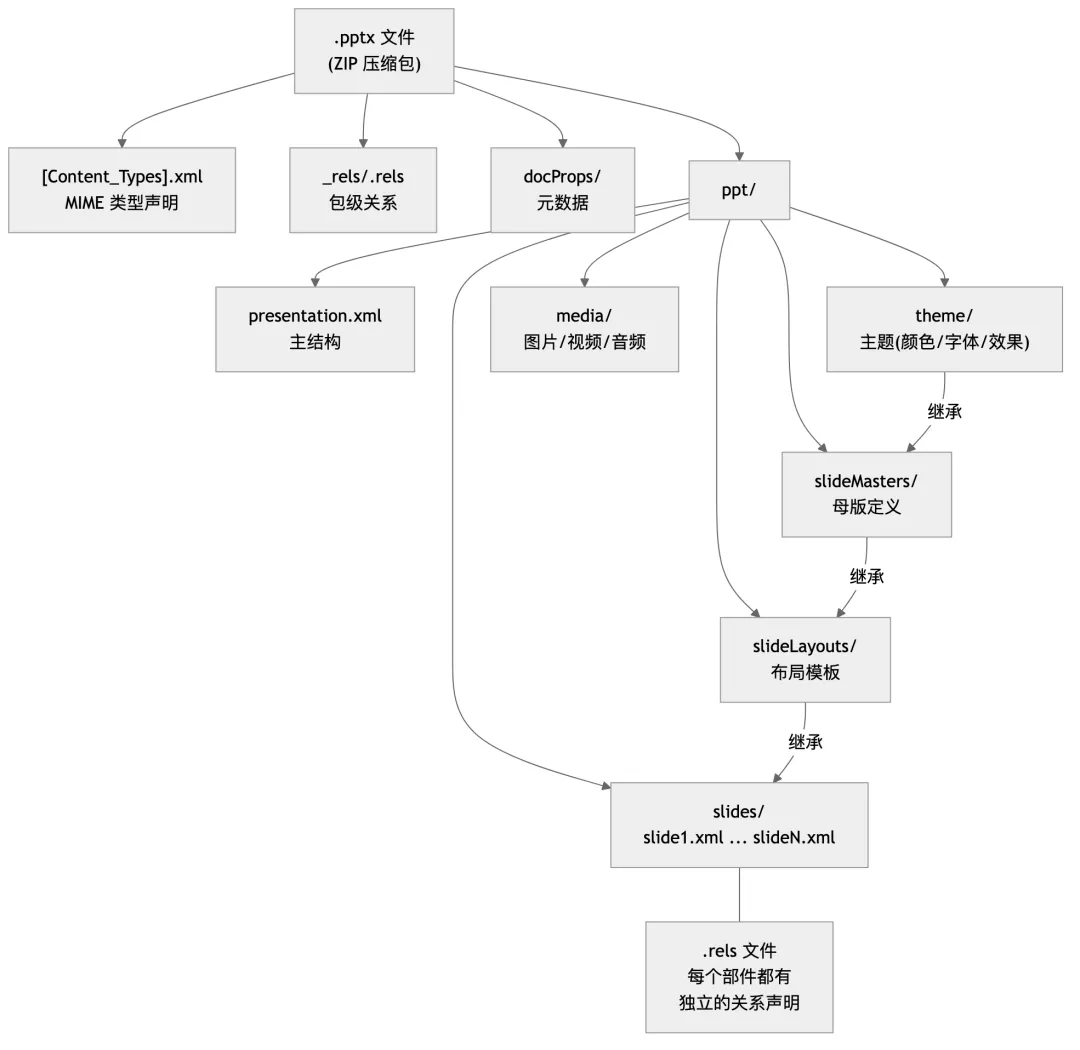
把任何一个 .pptx 文件的后缀名改成 .zip,解压缩,你会看到这样的目录结构:
[Content_Types].xml ← 声明包内每种文件的 MIME 类型_rels/ .rels ← 包级关系(指向 presentation.xml)docProps/ core.xml ← 元数据:作者、标题、创建时间 app.xml ← 应用属性ppt/ presentation.xml ← 主结构文件:幻灯片列表、尺寸 _rels/ presentation.xml.rels ← 主结构的关系:引用所有 slide、master、theme slides/ slide1.xml ← 单张幻灯片的内容 _rels/ slide1.xml.rels ← 这张幻灯片引用的图片、布局 slideLayouts/ slideLayout1.xml ← 布局模板:定义占位符位置 slideMasters/ slideMaster1.xml ← 母版:定义基础外观 theme/ theme1.xml ← 主题:颜色方案、字体族、效果 media/ image1.png ← 嵌入的图片/视频/音频
四层继承体系
OOXML 的幻灯片视觉表现由四层结构控制,每层继承上一层的属性:
Theme(主题) → 定义颜色方案(12 个语义色:dk1、dk2、lt1、lt2、accent1-6、hlink、folHlink)、字体族(主标题字体 + 正文字体,各有 Latin/East Asian/Complex Script 三套)、效果方案。
Slide Master(母版) → 继承 Theme,定义背景、默认文字样式、公共元素(Logo、页码位置)。一个 presentation 可以有多个 Slide Master。
Slide Layout(布局) → 继承 Slide Master,定义特定布局类型的占位符位置和大小。"标题页"、"标题+内容"、"两栏对比"都是不同的 Slide Layout。
Slide(幻灯片) → 继承 Slide Layout,填充实际内容。占位符里的文字、图片都在这一层。
关键问题:如果 AI 生成的幻灯片不通过 Slide Layout 的占位符放置内容,而是直接在 Slide 上创建独立的 shape,那么这些内容就脱离了继承链——改 Theme 不影响它们,换 Slide Master 不影响它们。它们变成了"孤儿元素"。
这正是 Copilot for PowerPoint 的模板问题的技术根源。 Copilot 通过 Office 插件 API 在 Slide 层面直接创建 shape,而不是通过 Slide Layout 的占位符。结果就是:浮动文本框、Logo 错位、品牌颜色不一致。
DrawingML:另一个复杂度维度
OOXML 中的所有图形元素(形状、文本框、图表、SmartArt)由 DrawingML 描述,这是一个独立于 SVG 的矢量图形语言。
DrawingML 的坐标系统使用 EMU(English Metric Unit),1 英寸 = 914,400 EMU。这意味着 AI 生成工具如果要精确控制元素位置,必须把所有尺寸换算成 EMU——一个毫无直觉可言的单位系统。
更麻烦的是,DrawingML 的文本渲染、图表数据、效果叠加各有自己的 XML 子树,嵌套深度可达 10+ 层。一个带阴影的圆角矩形文本框,仅 XML 就有 40-60 行。
Relationship 文件:隐性的胶水
OOXML 中每个部件(slide、image、layout、master)之间的引用不是直接的文件路径,而是通过 .rels 文件中的 relationship ID 间接引用。
<!-- slide1.xml.rels --><RelationshipId="rId1"Type=".../slideLayout"Target="../slideLayouts/slideLayout2.xml"/><RelationshipId="rId2"Type=".../image"Target="../media/image1.png"/>
Slide 里引用图片时用 rId2,不用文件名。如果 .rels 文件缺少这个 ID 声明,或 ID 和 XML 里的引用不匹配,PowerPoint 打开文件时会报错或丢失元素。
AI 生成工具必须同步维护 XML 内容和 .rels 文件的一致性。 这是一个容易出错的环节——程序化生成时,一个 ID 不匹配就能让整张幻灯片空白。
为什么 AI 在这里卡住了
python-pptx:事实上的瓶颈
大多数 AI PPT 工具在生成 PPTX 时依赖 python-pptx——一个 MIT 许可的 Python 库(GitHub 3,300+ stars,694 forks)。它是目前最广泛使用的 PPTX 程序化生成工具。
但 python-pptx 有严重的局限:
- 不支持动画和转场
- 不支持 SmartArt 创建
- 图表类型有限
- 不支持视频/音频嵌入
- 不支持 SVG 图片插入
- 不支持 3D 效果、形态变化(Morph)等 PowerPoint 近年新增的功能
- 443 个 open issues,88 个 open PR——维护者是单人(Steve Canny),最近一次代码提交在约 2 年前(约 2024 年中)
- 新功能通过赞助推动
- 存在已知 bug:如
Font.color 的 getter 方法会意外修改 XML(插入空的 <a:solidFill/>),Slide.background._element 返回错误节点等
python-pptx 作者自己也承认:"即使 python-pptx 做了这么多事,PowerPoint 文档格式极其丰富,仍有很多功能不支持。"
python-pptx 的状态在过去两年进一步恶化。 社区仍在提交 issue(每周有新的)和 PR,但几乎没有被合并。88 个 open PR 意味着大量社区贡献被搁置。对于依赖 python-pptx 的 AI PPT 工具来说,这是一个供应链风险——核心依赖的维护者只有一个人,且近乎停止开发。
AI 模型的输出能力上限 = python-pptx 的实现上限。 如果生成库不支持某个 OOXML 特性,AI 模型再聪明也无法在最终文件里表达它。
6,546 页规范 vs. 库的实现覆盖率
OOXML 规范(ISO/IEC 29500)全文 6,546 页——Google 在 ISO 标准化投票期间指出,ODF(OpenDocument Format)只用了 867 页就实现了类似目标。
python-pptx 实现的大约是规范的 10-15%。这意味着 AI 工具可以利用的 OOXML 特性只是冰山一角。更复杂的布局、更精细的动画、更丰富的图表——都在"支持范围之外"。
Web 原生工具的转换损失
Gamma 等 Web 原生工具选择了另一条路线:在浏览器里渲染内容,导出时再转换为 OOXML。这条路避开了直接和 OOXML 搏斗的痛苦,但引入了新的问题:
CSS 布局 → OOXML 坐标:CSS 的 flexbox/grid 是声明式布局("这些元素平均分配空间"),OOXML 是坐标式布局("这个文本框在 x=914400, y=1828800, w=7315200, h=457200 EMU 的位置")。两者之间没有无损映射。
Web 字体 → 系统字体:Web 可以加载任意 Google Fonts / Adobe Fonts,PPTX 只能使用嵌入字体或系统字体。中文字体尤其成问题——一个中文字体文件动辄 10+ MB,嵌入会让 PPTX 文件膨胀。
CSS 颜色 → OOXML 颜色方案:CSS 用 hex/rgb/hsl,OOXML 用语义色(accent1-6)。导出时如果把 CSS 颜色硬编码为 hex,就脱离了 OOXML 的颜色方案继承——之后换主题不会影响这些颜色。
这对工程师意味着什么
如果你正在构建或评估 AI PPT 工具,三个关键认知:
1. PPTX 导出质量是天花板,不是地板。 不管 AI 在 Web 端生成的内容多好看,最终用户拿到的 PPTX 文件质量取决于 OOXML 生成层。评估工具时,直接在 PowerPoint 里打开导出文件,检查模板继承、字体渲染、颜色方案是否完整。
2. "看起来对"和"结构上对"是两回事。 一个 AI 生成的 PPTX 文件可能在 PowerPoint 里打开看起来没问题,但如果所有元素都是硬编码的独立 shape(不参与继承链),后续修改会极其痛苦——换主题不生效,换布局不生效,每个元素都要单独调。
3. python-pptx 是当前的实际瓶颈。 如果你的 AI PPT 管线依赖 python-pptx,你的输出能力就被锁在它的实现范围内。替代方案包括:直接操作 OOXML XML(灵活但开发量大)、使用 Microsoft Graph API(需要 365 订阅)、或考虑 Apache POI(Java,实现更完整但 Python 生态外)。
4. 微软自己的解法:Headless Office。 2025 年底,微软在 Copilot 的 Edit with Copilot 功能中透露了一个关键架构:AI 不再直接生成 OOXML XML,而是先产出中间表示(intermediate representation),再通过无头版本的真实 PowerPoint 应用程序转换成最终文件。官方说法:"uses real Office applications — not approximations — to generate content."
这是目前唯一能从根本上绕过 OOXML 直接生成问题的方案——因为它把格式合规性交给了 PowerPoint 本身。但这条路只有微软能走:Headless Office 不是公开可用的 API,第三方无法调用。这意味着 OOXML 生成的结构性劣势,对第三方工具来说是永久性的——除非微软把 Headless Office 开放为平台能力。
补充背景
OOXML 的历史本身就是一段争议。2006 年微软将其提交给 Ecma 国际标准化,2008 年通过 ISO 快速通道投票成为 ISO/IEC 29500——但这个过程引发了激烈争议。IBM 威胁退出标准组织,批评者认为在 ODF 已经是 ISO 标准的情况下不需要第二个 XML 文档格式,挪威标准化机构甚至因为 OOXML 争议而"内爆"。
OOXML 有两个一致性级别:Strict 和 Transitional。讽刺的是,即使是微软自己的 Office 2013+ 也默认使用 Transitional 模式以保持向后兼容——这意味着"标准"的 Strict 模式在实际中几乎没有人用。
The Document Foundation(LibreOffice 的背后组织)称 OOXML 文件为"标签和元数据的迷宫"。这个评价在 AI 生成的语境下尤为贴切——让语言模型在迷宫里精确导航,目前做不到。
延伸阅读
- ISO/IEC 29500 (OOXML) — ISO 官方标准页面
- python-pptx documentation — 当前最广泛使用的 PPTX 生成库
- Open XML SDK — 微软官方的 .NET OOXML 操作库
- Office Open XML — Wikipedia — OOXML 历史和争议的全面概述
- Copilot for PowerPoint:$30/月买了什么 — 本系列第一篇,OOXML 问题在 Copilot 中的具体表现
- Gamma:$8/月的 AI 幻灯片 — 本系列第三篇,Web 原生工具如何绕开(但没有解决)OOXML 问题