import os
import openpyxl
from openpyxl.styles import Font, Alignment
save_dir = r"D:\Others\1210"
os.makedirs(save_dir, exist_ok=True)
file_path = os.path.join(save_dir, "USP_1210_Validation_Tool.xlsx")
wb = openpyxl.Workbook()
ws1 = wb.active
ws1.title = "Point Estimator"
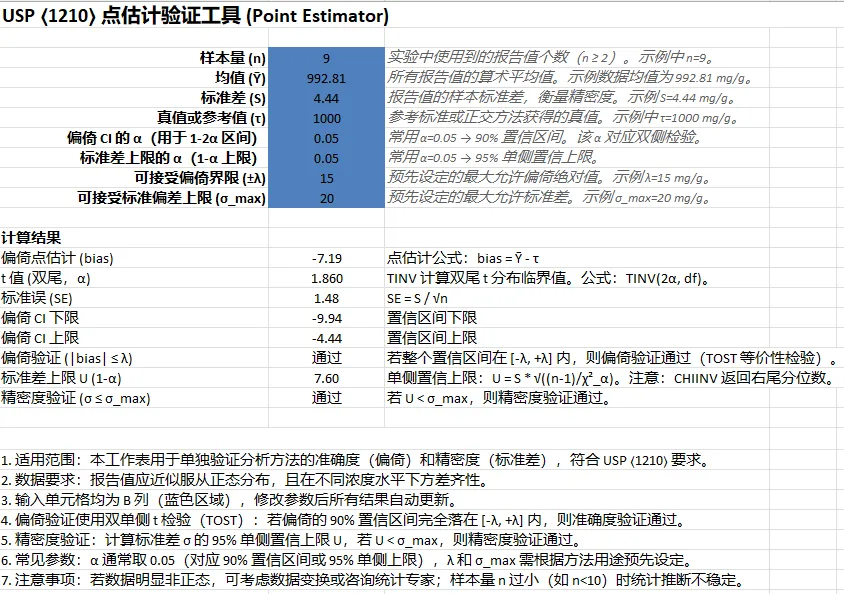
ws1['A1'] = "USP ⟨1210⟩ 点估计验证工具 (Point Estimator)"
ws1['A1'].font = Font(size=14, bold=True)
ws1.merge_cells('A1:J1')
inputs_pe = [
("A3", "样本量 (n)", 9, "实验中使用到的报告值个数(n ≥ 2)。示例中 n=9。"),
("A4", "均值 (Ȳ)", 992.81, "所有报告值的算术平均值。示例数据均值为 992.81 mg/g。"),
("A5", "标准差 (S)", 4.44, "报告值的样本标准差,衡量精密度。示例 S=4.44 mg/g。"),
("A6", "真值或参考值 (τ)", 1000, "参考标准或正交方法获得的真值。示例中 τ=1000 mg/g。"),
("A7", "偏倚 CI 的 α(用于 1-2α 区间)", 0.05, "常用 α=0.05 → 90% 置信区间。该 α 对应双侧检验。"),
("A8", "标准差上限的 α(1-α 上限)", 0.05, "常用 α=0.05 → 95% 单侧置信上限。"),
("A9", "可接受偏倚界限 (±λ)", 15, "预先设定的最大允许偏倚绝对值。示例 λ=15 mg/g。"),
("A10", "可接受标准偏差上限 (σ_max)", 20, "预先设定的最大允许标准差。示例 σ_max=20 mg/g。"),
]
for cell, label, default, note in inputs_pe:
ws1[cell] = label
ws1[cell].font = Font(bold=True)
ws1[cell].alignment = Alignment(horizontal='right')
val_cell = ws1.cell(row=int(cell[1:]), column=2)
val_cell.value = default
val_cell.alignment = Alignment(horizontal='left')
note_cell = ws1.cell(row=int(cell[1:]), column=3)
note_cell.value = note
note_cell.font = Font(size=9, italic=True, color="606060")
note_cell.alignment = Alignment(horizontal='left', wrap_text=True)
ws1['A12'] = "计算结果"
ws1['A12'].font = Font(bold=True)
ws1['A13'] = "偏倚点估计 (bias)"; ws1['B13'] = "=B4-B6"; ws1['C13'] = "点估计公式:bias = Ȳ - τ"
ws1['A14'] = "t 值 (双尾,α)"; ws1['B14'] = "=TINV(2*B7, B3-1)"; ws1['C14'] = "TINV 计算双尾 t 分布临界值。公式:TINV(2α, df)。"
ws1['A15'] = "标准误 (SE)"; ws1['B15'] = "=B5/SQRT(B3)"; ws1['C15'] = "SE = S / √n"
ws1['A16'] = "偏倚 CI 下限"; ws1['B16'] = "=B13 - B14*B15"; ws1['C16'] = "置信区间下限"
ws1['A17'] = "偏倚 CI 上限"; ws1['B17'] = "=B13 + B14*B15"; ws1['C17'] = "置信区间上限"
ws1['A18'] = "偏倚验证 (|bias| ≤ λ)"; ws1['B18'] = '=IF(AND(B16>=-B9, B17<=B9), "通过", "不通过")'; ws1['C18'] = "若整个置信区间在 [-λ, +λ] 内,则偏倚验证通过(TOST 等价性检验)。"
ws1['A19'] = "标准差上限 U (1-α)"; ws1['B19'] = "=B5*SQRT((B3-1)/CHIINV(1-B8, B3-1))"; ws1['C19'] = "单侧置信上限:U = S * √((n-1)/χ²_α)。注意:CHIINV 返回右尾分位数。"
ws1['A20'] = "精密度验证 (σ ≤ σ_max)"; ws1['B20'] = '=IF(B19
ws1.column_dimensions['A'].width = 35
ws1.column_dimensions['B'].width = 15
ws1.column_dimensions['C'].width = 50
start_row_pe = 22
ws1[f'A{start_row_pe}'] = "========== 使用说明与注意事项 =========="
ws1[f'A{start_row_pe}'].font = Font(bold=True, size=12)
ws1.merge_cells(f'A{start_row_pe}:C{start_row_pe}')
notes_pe = [
"1. 适用范围:本工作表用于单独验证分析方法的准确度(偏倚)和精密度(标准差),符合 USP ⟨1210⟩ 要求。",
"2. 数据要求:报告值应近似服从正态分布,且在不同浓度水平下方差齐性。",
"3. 输入单元格均为 B 列(蓝色区域),修改参数后所有结果自动更新。",
"4. 偏倚验证使用双单侧 t 检验(TOST):若偏倚的 90% 置信区间完全落在 [-λ, +λ] 内,则准确度验证通过。",
"5. 精密度验证:计算标准差 σ 的 95% 单侧置信上限 U,若 U < σ_max,则精密度验证通过。",
"6. 常见参数:α 通常取 0.05(对应 90% 置信区间或 95% 单侧上限),λ 和 σ_max 需根据方法用途预先设定。",
"7. 注意事项:若数据明显非正态,可考虑数据变换或咨询统计专家;样本量 n 过小(如 n<10)时统计推断不稳定。",
]
for i, note in enumerate(notes_pe, start=start_row_pe+1):
ws1[f"A{i}"] = note
ws1.merge_cells(f"A{i}:C{i}")
ws2 = wb.create_sheet("Combined Validation")
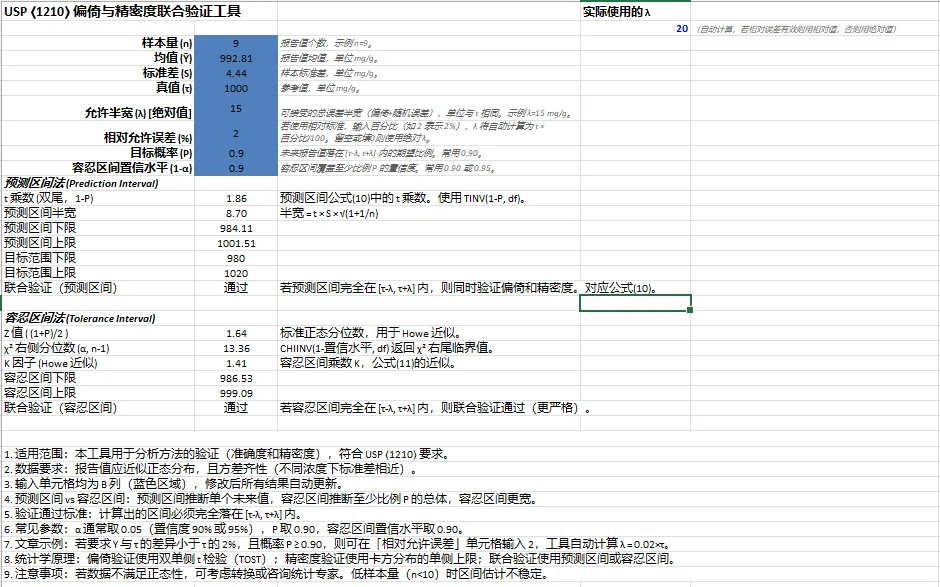
ws2['A1'] = "USP ⟨1210⟩ 偏倚与精密度联合验证工具"
ws2['A1'].font = Font(size=14, bold=True)
ws2.merge_cells('A1:J1')
inputs_cv = [
("A3", "样本量 (n)", 9, "报告值个数,示例 n=9。"),
("A4", "均值 (Ȳ)", 992.81, "报告值均值,单位 mg/g。"),
("A5", "标准差 (S)", 4.44, "样本标准差,单位 mg/g。"),
("A6", "真值 (τ)", 1000, "参考值,单位 mg/g。"),
("A7", "允许半宽 (λ) [绝对值]", 15, "可接受的总误差半宽(偏倚+随机误差),单位与 τ 相同。示例 λ=15 mg/g。"),
("A8", "相对允许误差 (%)", 2, "若使用相对标准,输入百分比(如 2 表示 2%),λ 将自动计算为 τ × 百分比/100。留空或填0则使用绝对 λ。"),
("A9", "目标概率 (P)", 0.90, "未来报告值落在 [τ-λ, τ+λ] 内的期望比例。常用 0.90。"),
("A10", "容忍区间置信水平 (1-α)", 0.90, "容忍区间覆盖至少比例 P 的置信度。常用 0.90 或 0.95。"),
]
for cell, label, default, note in inputs_cv:
ws2[cell] = label
ws2[cell].font = Font(bold=True)
ws2[cell].alignment = Alignment(horizontal='right')
val_cell = ws2.cell(row=int(cell[1:]), column=2)
val_cell.value = default
val_cell.alignment = Alignment(horizontal='left')
note_cell = ws2.cell(row=int(cell[1:]), column=3)
note_cell.value = note
note_cell.font = Font(size=9, italic=True, color="606060")
note_cell.alignment = Alignment(horizontal='left', wrap_text=True)
for merged_range in list(ws2.merged_cells):
if (merged_range.min_row <= 1 <= merged_range.max_row and merged_range.min_col <= 4 <= merged_range.max_col) or \
(merged_range.min_row <= 2 <= merged_range.max_row and merged_range.min_col <= 4 <= merged_range.max_col):
ws2.unmerge_cells(str(merged_range))
ws2.cell(row=1, column=4).value = "实际使用的 λ"
ws2.cell(row=1, column=4).font = Font(bold=True)
ws2.cell(row=2, column=4).value = "=IF(AND(ISNUMBER(B8), B8>0), B6*B8/100, B7)"
ws2.cell(row=2, column=4).font = Font(bold=True, color="0000FF")
ws2.cell(row=2, column=5).value = "(自动计算,若相对误差有效则用相对值,否则用绝对值)"
ws2.cell(row=2, column=5).font = Font(size=8, italic=True, color="606060")
ws2['A11'] = "预测区间法 (Prediction Interval)"; ws2['A11'].font = Font(bold=True, italic=True)
ws2['A12'] = "t 乘数 (双尾,1-P)"; ws2['B12'] = "=TINV(1-B9, B3-1)"; ws2['C12'] = "预测区间公式(10)中的 t 乘数。使用 TINV(1-P, df)。"
ws2['A13'] = "预测区间半宽"; ws2['B13'] = "=B12 * B5 * SQRT(1 + 1/B3)"; ws2['C13'] = "半宽 = t × S × √(1+1/n)"
ws2['A14'] = "预测区间下限"; ws2['B14'] = "=B4 - B13"
ws2['A15'] = "预测区间上限"; ws2['B15'] = "=B4 + B13"
ws2['A16'] = "目标范围下限"; ws2['B16'] = "=B6 - IF(AND(ISNUMBER(B8), B8>0), B6*B8/100, B7)"
ws2['A17'] = "目标范围上限"; ws2['B17'] = "=B6 + IF(AND(ISNUMBER(B8), B8>0), B6*B8/100, B7)"
ws2['A18'] = "联合验证(预测区间)"; ws2['B18'] = '=IF(AND(B14>=B16, B15<=B17), "通过", "不通过")'; ws2['C18'] = "若预测区间完全在 [τ-λ, τ+λ] 内,则同时验证偏倚和精密度。对应公式(10)。"
ws2['A20'] = "容忍区间法 (Tolerance Interval)"; ws2['A20'].font = Font(bold=True, italic=True)
ws2['A21'] = "Z 值 ( (1+P)/2 )"; ws2['B21'] = "=NORMSINV((1+B9)/2)"; ws2['C21'] = "标准正态分位数,用于 Howe 近似。"
ws2['A22'] = "χ² 右侧分位数 (α, n-1)"; ws2['B22'] = "=CHIINV(1-B10, B3-1)"; ws2['C22'] = "CHIINV(1-置信水平, df) 返回 χ² 右尾临界值。"
ws2['A23'] = "K 因子 (Howe 近似)"; ws2['B23'] = "=SQRT((B21^2 * (B3-1)) / B22) * (1 + 1/B3)"; ws2['C23'] = "容忍区间乘数 K,公式(11)的近似。"
ws2['A24'] = "容忍区间下限"; ws2['B24'] = "=B4 - B23 * B5"
ws2['A25'] = "容忍区间上限"; ws2['B25'] = "=B4 + B23 * B5"
ws2['A26'] = "联合验证(容忍区间)"; ws2['B26'] = '=IF(AND(B24>=B16, B25<=B17), "通过", "不通过")'; ws2['C26'] = "若容忍区间完全在 [τ-λ, τ+λ] 内,则联合验证通过(更严格)。"
ws2.column_dimensions['A'].width = 35
ws2.column_dimensions['B'].width = 15
ws2.column_dimensions['C'].width = 55
ws2.column_dimensions['D'].width = 20
ws2.column_dimensions['E'].width = 45
ws2['A28'] = "========== 使用说明与注意事项 =========="
ws2['A28'].font = Font(bold=True, size=12)
ws2.merge_cells('A28:E28')
notes_cv = [
"1. 适用范围:本工具用于分析方法的验证(准确度和精密度),符合 USP ⟨1210⟩ 要求。",
"2. 数据要求:报告值应近似正态分布,且方差齐性(不同浓度下标准差相近)。",
"3. 输入单元格均为 B 列(蓝色区域),修改后所有结果自动更新。",
"4. 预测区间 vs 容忍区间:预测区间推断单个未来值,容忍区间推断至少比例 P 的总体,容忍区间更宽。",
"5. 验证通过标准:计算出的区间必须完全落在 [τ-λ, τ+λ] 内。",
"6. 常见参数:α 通常取 0.05(置信度 90% 或 95%),P 取 0.90,容忍区间置信水平取 0.90。",
"7. 文章示例:若要求 Y 与 τ 的差异小于 τ 的 2%,且概率 P ≥ 0.90,则可在「相对允许误差」单元格输入 2,工具自动计算 λ = 0.02×τ。",
"8. 统计学原理:偏倚验证使用双单侧 t 检验(TOST);精密度验证使用卡方分布的单侧上限;联合验证使用预测区间或容忍区间。",
"9. 注意事项:若数据不满足正态性,可考虑转换或咨询统计专家。低样本量(n<10)时区间估计不稳定。",
]
for i, note in enumerate(notes_cv, start=29):
ws2[f"A{i}"] = note
ws2.merge_cells(f"A{i}:E{i}")
ws3 = wb.create_sheet("LOD_LOQ Estimation")
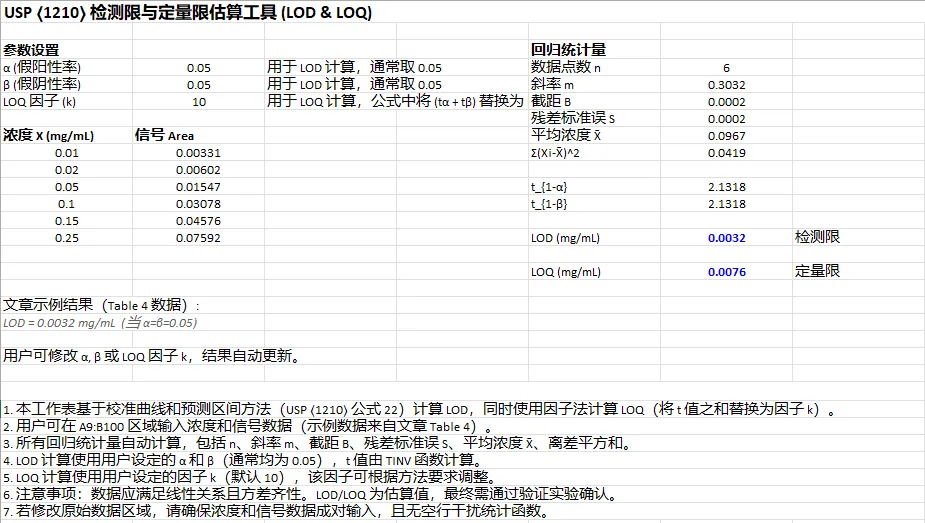
ws3['A1'] = "USP ⟨1210⟩ 检测限与定量限估算工具 (LOD & LOQ)"
ws3['A1'].font = Font(size=14, bold=True)
ws3.merge_cells('A1:J1')
ws3['A3'] = "参数设置"
ws3['A3'].font = Font(bold=True, size=12)
ws3['A4'] = "α (假阳性率)"; ws3['B4'] = 0.05; ws3['C4'] = "用于 LOD 计算,通常取 0.05"
ws3['A5'] = "β (假阴性率)"; ws3['B5'] = 0.05; ws3['C5'] = "用于 LOD 计算,通常取 0.05"
ws3['A6'] = "LOQ 因子 (k)"; ws3['B6'] = 10; ws3['C6'] = "用于 LOQ 计算,公式中将 (tα + tβ) 替换为 k。推荐值 10,可根据需要调整。"
ws3['A8'] = "浓度 X (mg/mL)"; ws3['A8'].font = Font(bold=True)
ws3['B8'] = "信号 Area"; ws3['B8'].font = Font(bold=True)
data = [
(0.01, 0.00331),
(0.02, 0.00602),
(0.05, 0.01547),
(0.10, 0.03078),
(0.15, 0.04576),
(0.25, 0.07592),
]
for i, (x, y) in enumerate(data, start=9):
ws3.cell(row=i, column=1, value=x)
ws3.cell(row=i, column=2, value=y)
ws3['E3'] = "回归统计量"
ws3['E3'].font = Font(bold=True)
ws3['E4'] = "数据点数 n"; ws3['F4'] = "=COUNT(A9:A100)"
ws3['E5'] = "斜率 m"; ws3['F5'] = "=SLOPE(B9:B100, A9:A100)"
ws3['E6'] = "截距 B"; ws3['F6'] = "=INTERCEPT(B9:B100, A9:A100)"
ws3['E7'] = "残差标准误 S"; ws3['F7'] = "=STEYX(B9:B100, A9:A100)"
ws3['E8'] = "平均浓度 X̄"; ws3['F8'] = "=AVERAGE(A9:A100)"
ws3['E9'] = "Σ(Xi-X̄)^2"; ws3['F9'] = "=DEVSQ(A9:A100)"
ws3['E11'] = "t_{1-α}"; ws3['F11'] = "=TINV(2*B4, F4-2)"
ws3['E12'] = "t_{1-β}"; ws3['F12'] = "=TINV(2*B5, F4-2)"
ws3['E14'] = "LOD (mg/mL)"; ws3['F14'] = "=(F11+F12)*(F7/F5)*SQRT(1+1/F4+F8^2/F9)"
ws3['F14'].font = Font(bold=True, color="0000FF")
ws3['G14'] = "检测限"
ws3['E16'] = "LOQ (mg/mL)"; ws3['F16'] = "=B6 * (F7/F5) * SQRT(1 + 1/F4 + F8^2/F9)"
ws3['F16'].font = Font(bold=True, color="0000FF")
ws3['G16'] = "定量限"
ws3['A18'] = "文章示例结果(Table 4 数据):"
ws3['A19'] = "LOD = 0.0032 mg/mL (当 α=β=0.05)"
ws3['A19'].font = Font(italic=True, color="606060")
ws3['A21'] = "用户可修改 α, β 或 LOQ 因子 k,结果自动更新。"
ws3['A23'] = "========== 使用说明与注意事项 =========="
ws3['A23'].font = Font(bold=True, size=12)
ws3.merge_cells('A23:G23')
notes_ll = [
"1. 本工作表基于校准曲线和预测区间方法(USP ⟨1210⟩ 公式 22)计算 LOD,同时使用因子法计算 LOQ(将 t 值之和替换为因子 k)。",
"2. 用户可在 A9:B100 区域输入浓度和信号数据(示例数据来自文章 Table 4)。",
"3. 所有回归统计量自动计算,包括 n、斜率 m、截距 B、残差标准误 S、平均浓度 X̄、离差平方和。",
"4. LOD 计算使用用户设定的 α 和 β(通常均为 0.05),t 值由 TINV 函数计算。",
"5. LOQ 计算使用用户设定的因子 k(默认 10),该因子可根据方法要求调整。",
"6. 注意事项:数据应满足线性关系且方差齐性。LOD/LOQ 为估算值,最终需通过验证实验确认。",
"7. 若修改原始数据区域,请确保浓度和信号数据成对输入,且无空行干扰统计函数。",
]
for i, note in enumerate(notes_ll, start=24):
ws3[f"A{i}"] = note
ws3.merge_cells(f"A{i}:G{i}")
for col in ['A','B','C','D','E','F','G']:
ws3.column_dimensions[col].width = 20
wb.save(file_path)
print(f"Excel 工具已成功保存至:{file_path}")
print("所有函数已替换为兼容旧版 Excel 的 TINV、NORMSINV、CHIINV,可在 Excel 2007 及更高版本中正常使用。")
print("已包含三个工作表:Point Estimator、Combined Validation、LOD_LOQ Estimation。")
print("LOD_LOQ 工作表中,LOD 使用公式 (22) 计算,LOQ 将 t 值之和替换为用户可调的因子 k(默认 10),完全符合文章描述。")









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
