Microsoft AutoGen团队搞的。pip install 'markitdown[all]' 一条命令装完,markitdown file.pdf > doc.md一条命令转完。看着朴素,但做AI应用的人离不开——因为LLM吃文本,不吃PDF。
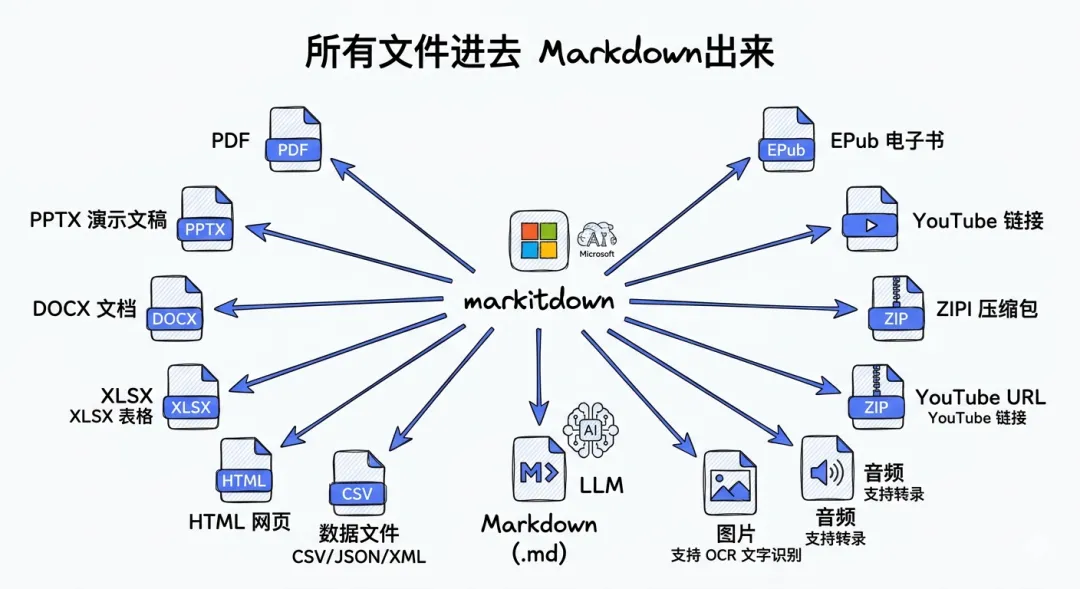
markitdown全格式转换总览
/ / /
这破玩意为什么突然火成这样
先看数据。microsoft/markitdown这个仓库从2024年11月开到现在,10万6千star,每周往上涨1万3。它是GitHub Trending上的常驻选手,最近一个月月榜前列。
一个只有280行README、功能朴素到极点的Python小工具,凭啥能到这个量级?
答案很简单:所有做AI应用的人都绕不过"文件转文本"这一步。
你要做RAG,第一步得把用户上传的PDF变成可检索的文本。你要做AI助手读会议纪要,第一步得把.docx变成plain content。你要做智能客服,第一步得把Excel里的FAQ变成模型能吞的token流。
这些场景以前的标准答案是textract、unstructured、pdfplumber、python-docx——每种格式一个库,参数一堆,装完依赖比你的主程序还大。
markitdown的思路完全不一样:一个入口,所有格式出来都是Markdown,一致的结构,LLM friendly。
Markdown extremely close to plain text, with minimal markup. 主流LLM原生"说"markdown——你把PDF转成md扔给GPT-4o或者Claude,他们都能正确读取标题层级、表格、列表。
支持的格式列表是这样的:
- ●PDF
-
- ●PowerPoint (pptx)
-
- ●Word (docx)
-
- ●Excel (xlsx, xls)
-
- ●Images (EXIF metadata + OCR)
-
- ●Audio (EXIF metadata + 语音转写)
-
- ●HTML
-
- ●文本类: CSV, JSON, XML
-
- ●ZIP files (递归处理)
-
- ●YouTube URLs (抓字幕)
-
- ●EPubs
-
- ●还有更多
最后那句"and more"不是凑数。社区插件里还有一批补全格式的,后面讲。
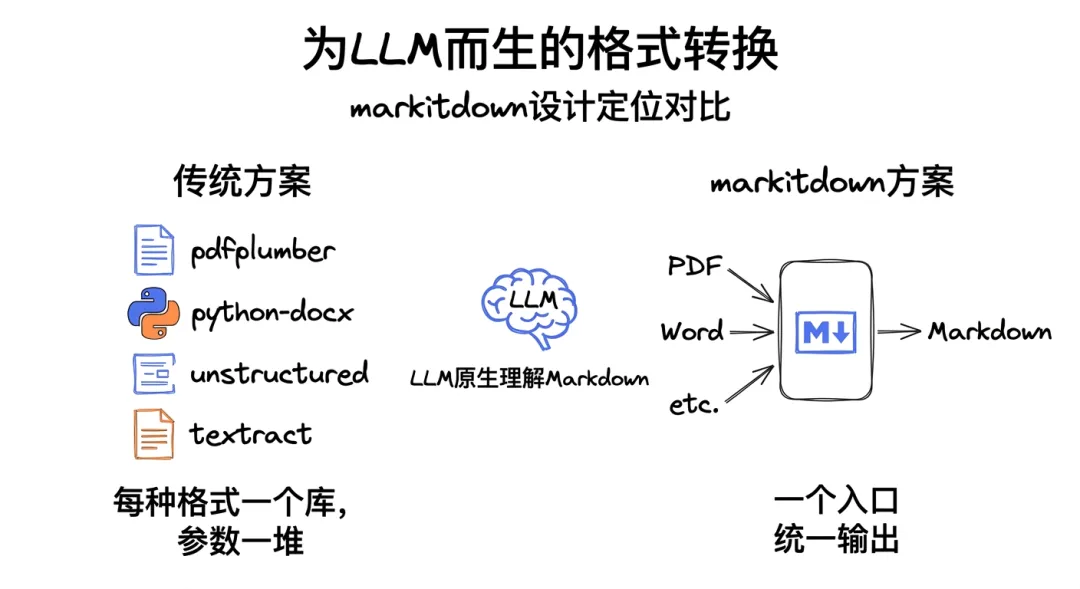
markitdown的设计定位
/ / /
装起来其实挺简单的
核心install一条命令:
pip install 'markitdown[all]'
这个[all]是关键。markitdown v0.1.0之后把依赖拆成了optional feature groups,默认pip install markitdown装的是最精简版,啥都转不了。你要[all]才把PDF、docx、pptx、xlsx、audio这些格式的依赖一股脑装全。
讲真,这个设计有点反直觉——大多数人的第一反应就是pip install markitdown,然后转PDF时报ImportError懵圈。Microsoft的工程师应该是想让用户按需安装,省空间。但实际体验上,80%用户该装[all]。
按需装的话,格式名按组名:
pip install 'markitdown[pdf, docx, pptx]' # 只要这三种
pip install 'markitdown[audio-transcription]' # 音频转写
pip install 'markitdown[az-doc-intel]' # Azure文档智能
用的时候有两种方式。命令行:
markitdown path-to-file.pdf > document.md
markitdown path-to-file.pdf -o document.md
cat path-to-file.pdf | markitdown # 也支持stdin
Python API:
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=False)
result = md.convert("test.xlsx")
print(result.text_content)
就这。没有配置文件,没有初始化仪式,没有需要起的服务。convert()直接返回结果对象,text_content就是转好的markdown字符串。
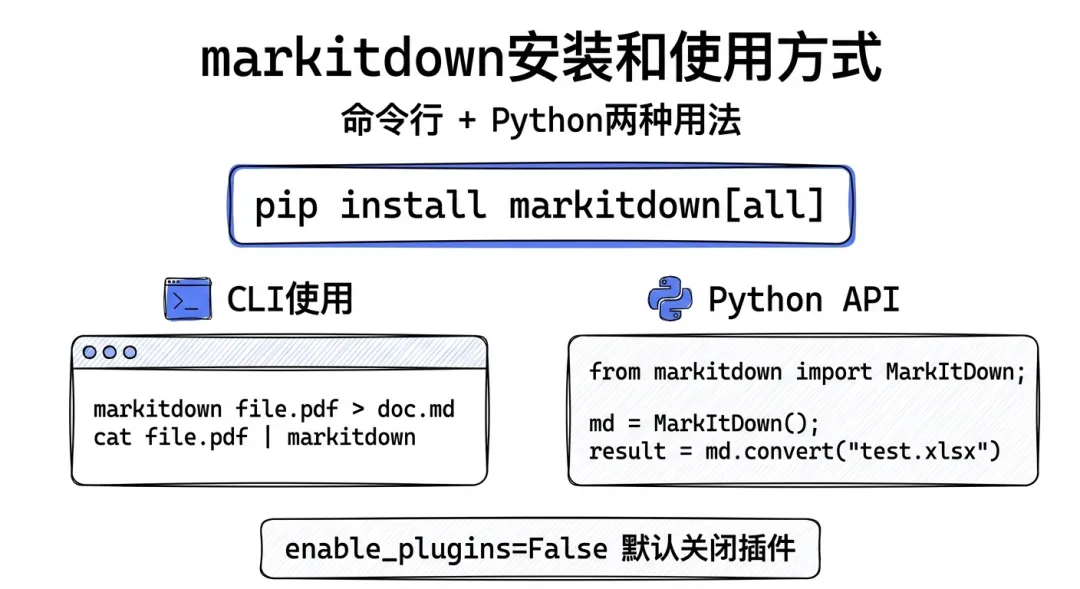
markitdown的安装与使用
/ / /
0.0.1到0.1.0的breaking change要注意
这块README里专门用了一个[!IMPORTANT]标出来,讲真挺贴心。做开源的都知道,隐藏的breaking change比明着说的更致命。
两个关键变更:
第一个:optional dependencies分组了。我上面讲过,这个影响就是默认的pip install markitdown不再装全功能依赖,要加[all]。
第二个:convert_stream()的签名变了——现在必须传binary file-like object。以前可以传io.StringIO,现在只能io.BytesIO或者open(path, 'rb')。
# 旧代码,v0.0.1能跑
md.convert_stream(io.StringIO(text_content)) # 0.1.0会报错
# 新代码,v0.1.0要这么写
md.convert_stream(io.BytesIO(text_content.encode()))
第三个(稍微隐藏一点):DocumentConverter的接口改了。以前Converter读文件路径,现在读file-like stream。没有临时文件这一环了("No temporary files are created anymore")。只有plugin作者或者自定义Converter的人会碰到这个。如果你只用MarkItDown类或CLI,无感知。
这三个改动的目的是一致的:减少side effect,提高可组合性。stream-based的接口能串起来做pipeline,比path-based的灵活得多。工程品味上的升级。
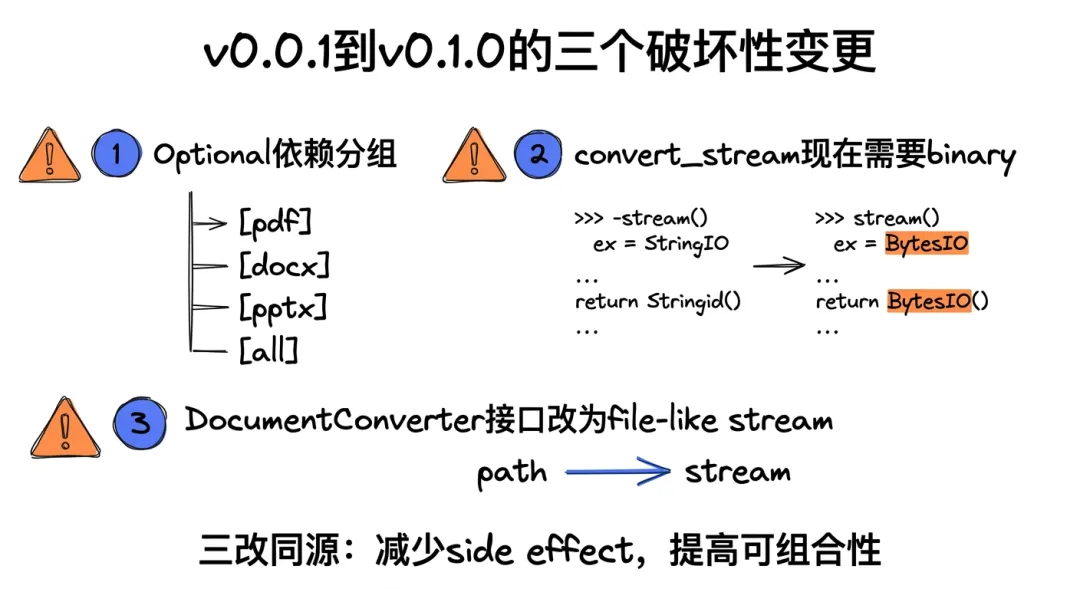
0.1.0版本breaking changes
/ / /
把LLM塞进来:让markitdown变智能
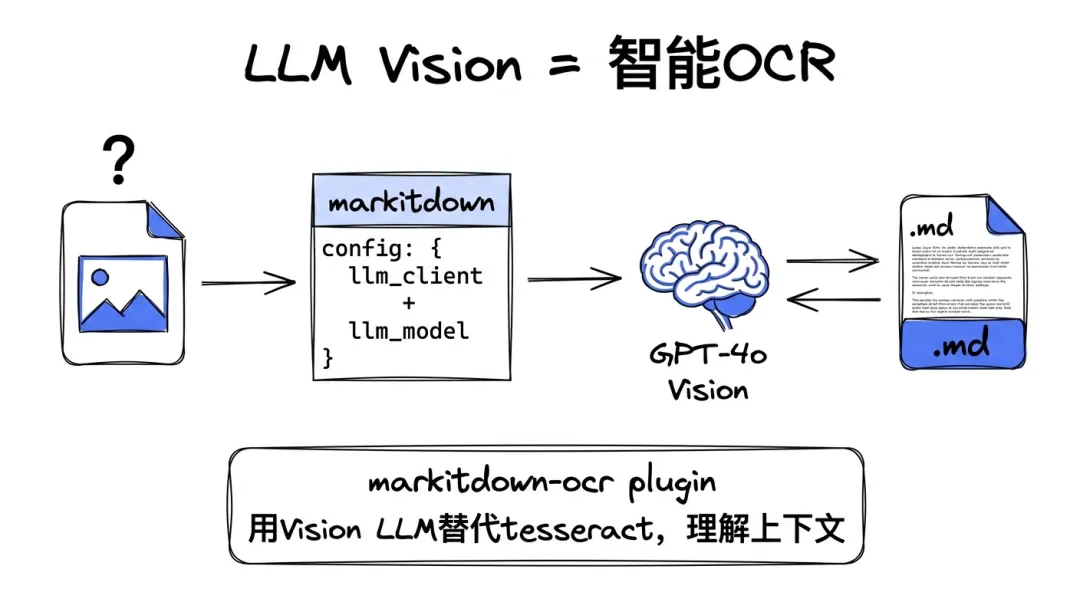
这是markitdown最有意思的一个能力——它自己就集成了LLM调用。
你给MarkItDown传一个llm_client,它会用这个LLM来给图片生成文字描述。
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(
llm_client=client,
llm_model="gpt-4o",
llm_prompt="optional custom prompt"
)
result = md.convert("example.jpg")
print(result.text_content)
传进去一张图,出来是带语义描述的markdown。目前官方支持的格式是pptx和纯图片文件——处理pptx的时候,slide里嵌入的图片也会被描述出来。
还有个更进一步的用法是markitdown-ocr plugin。这个plugin给PDF、DOCX、PPTX、XLSX都加了OCR支持,用的是LLM Vision而不是传统的tesseract:
pip install markitdown-ocr
pip install openai
md = MarkItDown(
enable_plugins=True,
llm_client=OpenAI(),
llm_model="gpt-4o",
)
result = md.convert("document_with_images.pdf")
这个设计挺聪明。传统OCR pipeline得装tesseract或者PaddleOCR,本地部署一堆CV依赖。但你做AI应用的人本来就在调LLM了,再多调一次拿图片文字描述,成本可控,效果还比tesseract准——因为Vision LLM能理解上下文,tesseract只认识像素。
如果你不传llm_client,markitdown-ocr会silently跳过OCR,退回到内置converter。不会报错,不会半途而废,这个fallback做得挺优雅。
把LLM当成一个universal function: "给我描述这个图/认这段字"。这种把LLM组合进传统工具链的思路,是AI-native工具的标志。
集成LLM做图片描述和OCR
/ / /
企业档:Azure Document Intelligence接入
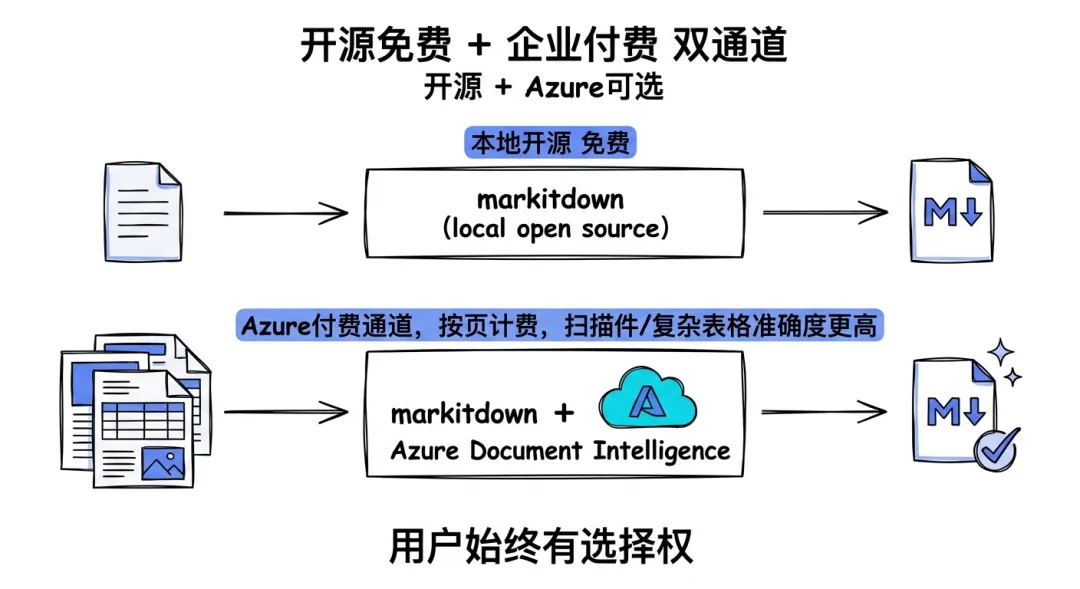
如果你不信任开源PDF库在复杂文档上的识别效果(说实话,PDF这东西格式太野,开源工具翻车很正常),markitdown内置了Azure Document Intelligence接入。
这个是微软付费的文档理解服务,对扫描件、复杂表格、手写体、跨栏排版的识别准确度都比开源方案高一档。接入方式一行:
markitdown path-to-file.pdf -o document.md -d -e "<document_intelligence_endpoint>"
Python API:
md = MarkItDown(docintel_endpoint="<document_intelligence_endpoint>")
result = md.convert("test.pdf")
要多少钱:按页计费,大概每1000页几刀,具体看你在哪个Azure region、什么tier。对需要处理大量历史文档、质量要求高的企业场景挺合适。对个人开发者、小项目,内置PDF库够用。
这里其实看得出markitdown的定位——开源社区友好,但企业通道也给你留着。不是"免费版受限专业版付费"那种split,而是"本地能跑,需要更高质量就接Azure"。用户始终有选择权。
Azure Document Intelligence可选接入
/ / /
MCP Server:直接给Claude Desktop用
这是markitdown最近新加的能力,README顶部一个[!TIP]标出来。
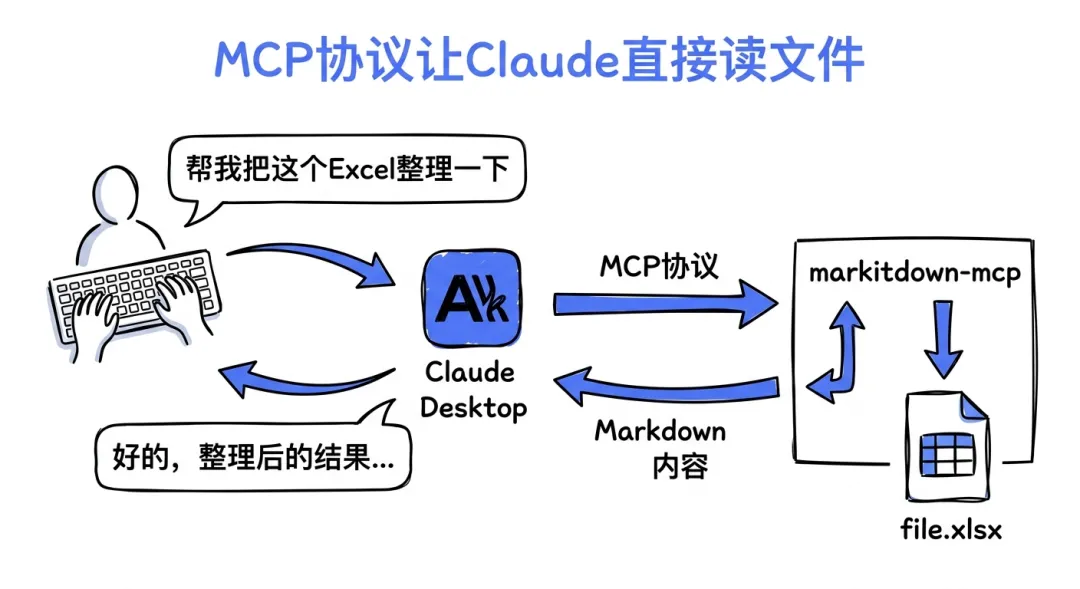
markitdown-mcp是个独立package,把markitdown包装成了MCP(Model Context Protocol)server。装完之后你可以直接在Claude Desktop里让Claude读本地文件:
你:帮我把这个Excel整理一下
Claude: (调用markitdown-mcp转换文件.xlsx)
(读到markdown内容)
好的,这是整理后的结果...
不需要你先手动转、再copy-paste、再发给Claude。Claude直接通过MCP协议调用markitdown,读到转换结果。
这个集成的意义是:markitdown从一个"dev调用的库"升级成了"AI助手的内置能力"。类似你装了个Office插件,AI就能处理Office文档,没有格式屏障。
MCP生态这一年起得飞快,Anthropic推出协议后,各种工具都在做MCP server包装。markitdown这步走得很快,而且做得干净——不用改核心逻辑,套个MCP layer就上线。
markitdown-mcp给Claude Desktop加能力
/ / /
真实场景:我用它来干什么
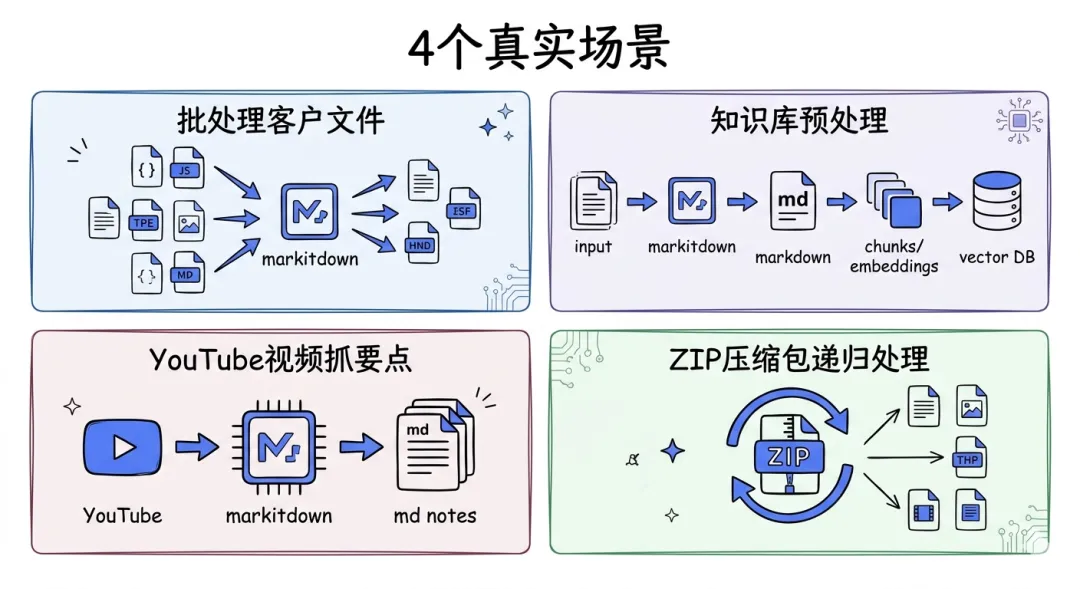
讲点实际的。这破玩意我平时主要在三个场景用:
场景1:批处理客户发来的乱七八糟文件。对方发过来可能是PDF、可能是docx、可能是邮件附件。以前要针对每种格式写读取逻辑。现在一个markitdown file解决所有,吐出来的md扔给Claude或GPT-4,让它提取关键信息。
场景2:给本地知识库做数据预处理。项目文档、会议纪要、历史邮件,格式千奇百怪。markitdown是最快的统一入口。转成md之后做chunk、embedding、入库,后面就标准RAG流程了。
场景3:YouTube视频快速抓要点。这个feature有点骚——直接扔个YouTube URL:
markitdown "https://www.youtube.com/watch?v=xxx" > video-notes.md
它会去抓字幕(需要视频有字幕),给你吐成markdown。配合LLM做总结,一个视频的核心内容5分钟搞定。
场景4(我没用过但README提了):ZIP文件递归处理。扔一个压缩包进去,它会遍历里面所有支持的格式转一遍。适合处理"一堆资料打包发来的"场景。
短板得提一句:markitdown的定位不是"高保真文档转换"。官方原话:"may not be the best option for high-fidelity document conversions for human consumption"。它的目标读者是LLM,不是人类。所以复杂表格、精美排版、PDF里的数学公式这些,别指望转完还能给人看——转完是给模型消化的。
markitdown的4个真实使用场景
/ / /
写在最后
markitdown这个工具值得写,是因为它代表了一种新的工具设计思路:不是"再加一个功能更强的PDF解析器",而是"把所有文件转成LLM最喜欢的格式"。它的价值不在于哪个单一格式的处理能力有多强(专门工具每个都比它强),而在于作为AI工作流的统一前处理入口。
Microsoft AutoGen团队做这个的时候,心里想的明显是"我们的agent需要读文件,什么格式都得能读"。所以它是从agent需求倒推出来的工具。这个视角很重要——AI原生工具的设计起点跟传统工具是反的。
用一句话总结:你的LLM应用如果要读文件,先装markitdown。10万人已经给出同样的答案,这个选择大概率错不了。
你平时做AI应用的时候,文件预处理这块是用什么方案?评论区聊聊。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
