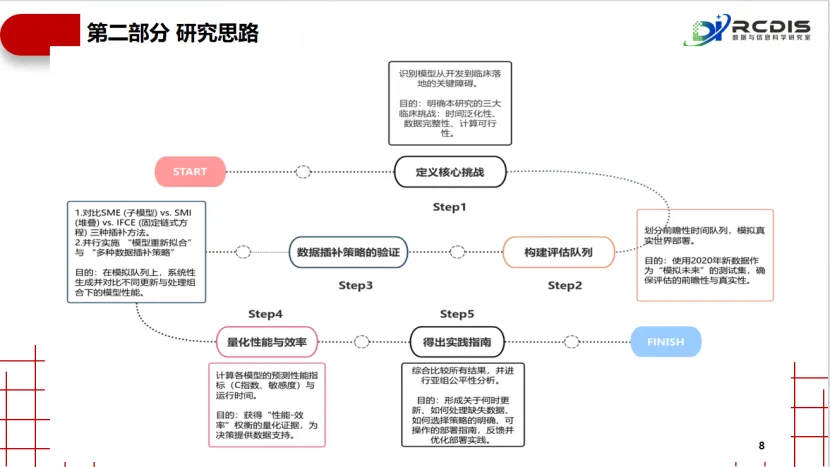
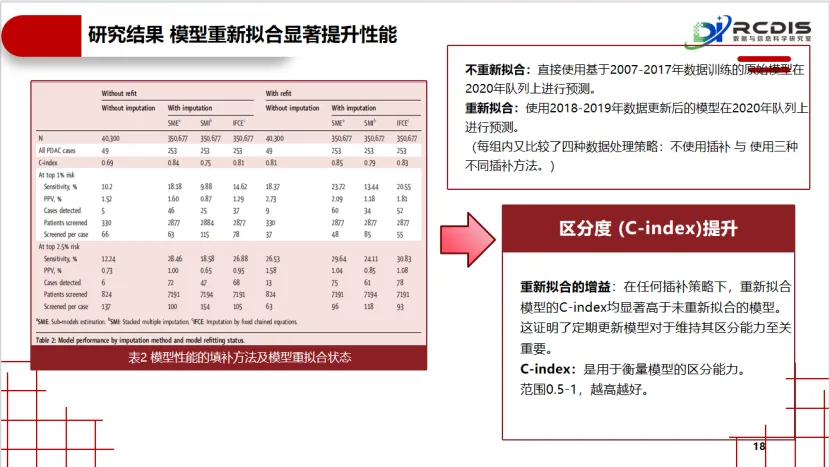
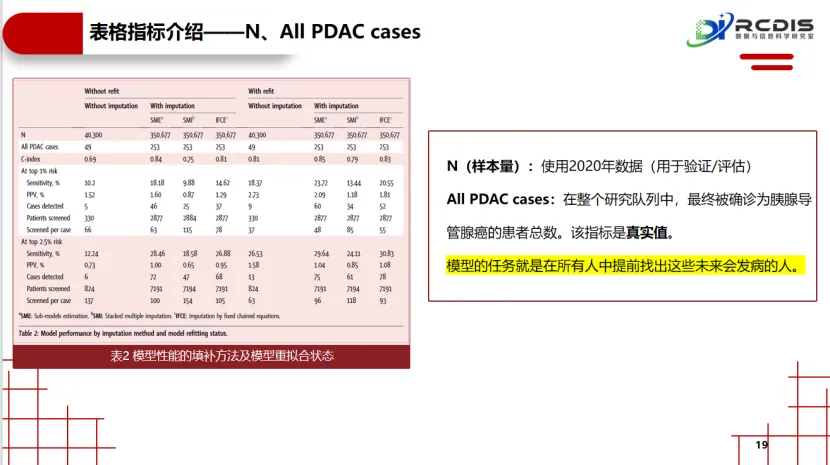
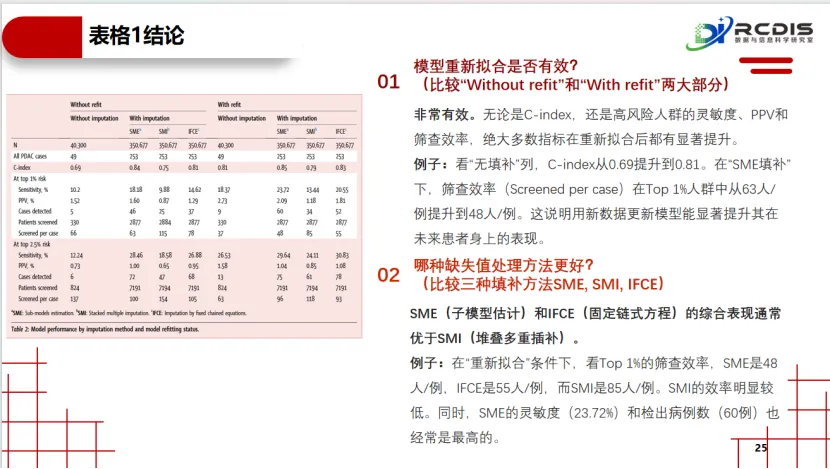
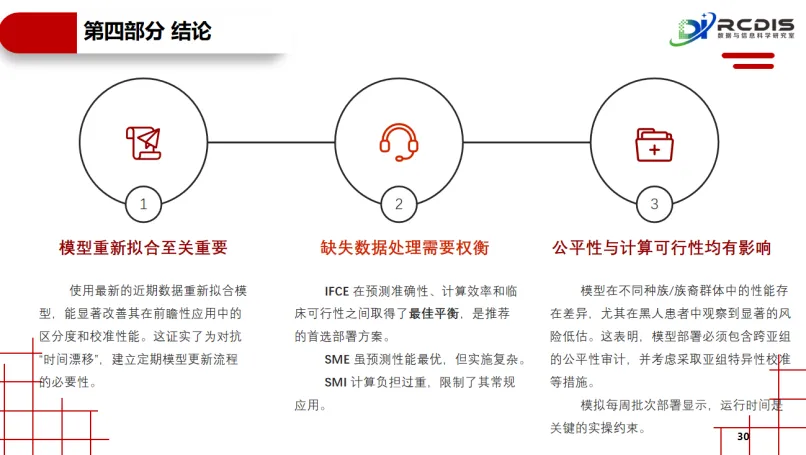
对“模型过时”的验证:研究模拟了时间效应,通过对比用旧数据训练的原始模型与用新近数据重新训练的模型,在未来患者队列中的表现差异。这直接证实了“数据漂移”的存在,为“临床AI模型需要定期维护与更新”这一常常被忽视的实践,提供了关键证据。
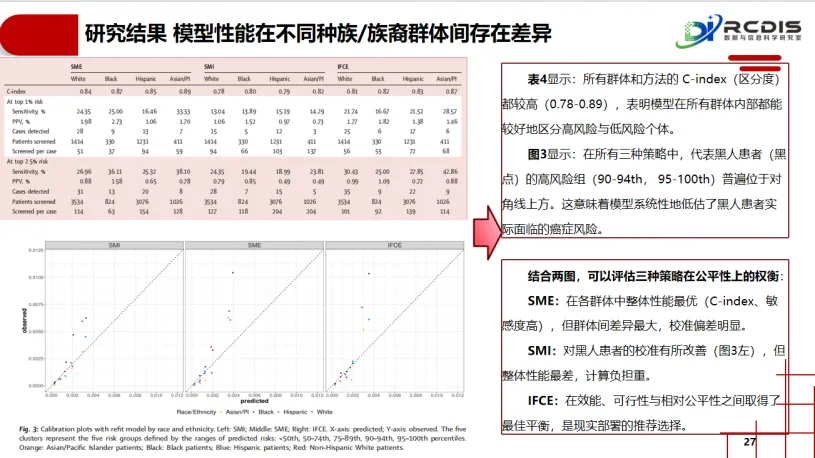
对“数据不完整”的实战测评:面对现实世界中患者信息普遍缺失的难题,该研究首次系统性地将三种主流缺失值处理策略置于部署场景中同台竞技。其评估维度远超常见的预测精度,创造性地纳入了“计算可行性”与“运维复杂性”这两个决定性的落地指标。
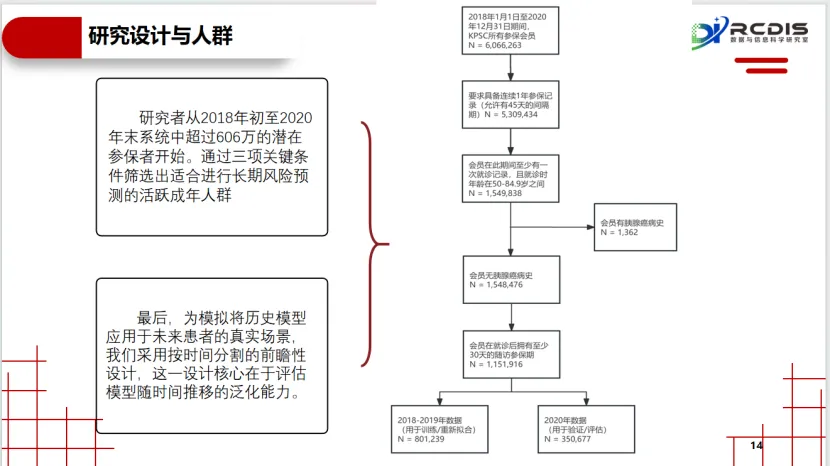
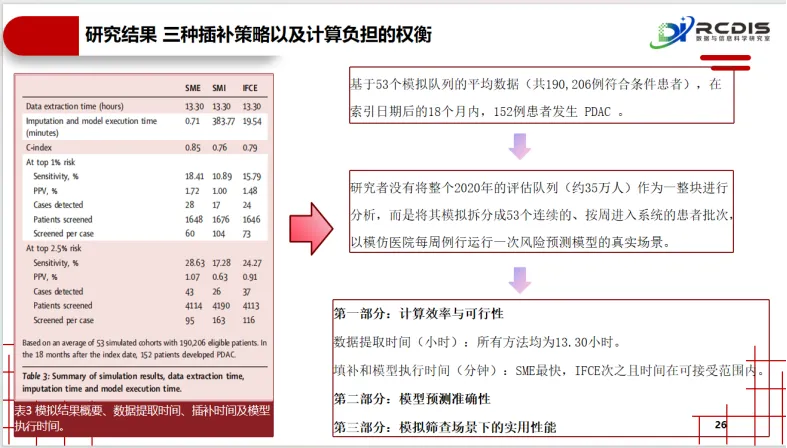
对“计算效率”的压力测试:研究设计了一个高度仿真的工作流——将超过35万患者数据,模拟为连续53个“周批次” 进行滚动预测与评估。这种方法能够精确记录每一种方案在模拟的真实工作节奏下的数据提取、处理和计算耗时。
这项研究通过搭建这样一个严谨的“模拟-评估”闭环,将部署前抽象的担忧,转化为可量化、可比较的实测结果。它标志着临床AI评估范式从静态的“性能评估”,转向动态的“生存能力评估”,为后续所有旨在落地的模型,提供了一个极具价值的创新方法范本。