
一、问题现象
很多人在处理 Excel 数据时都会遇到一个很迷惑的问题:
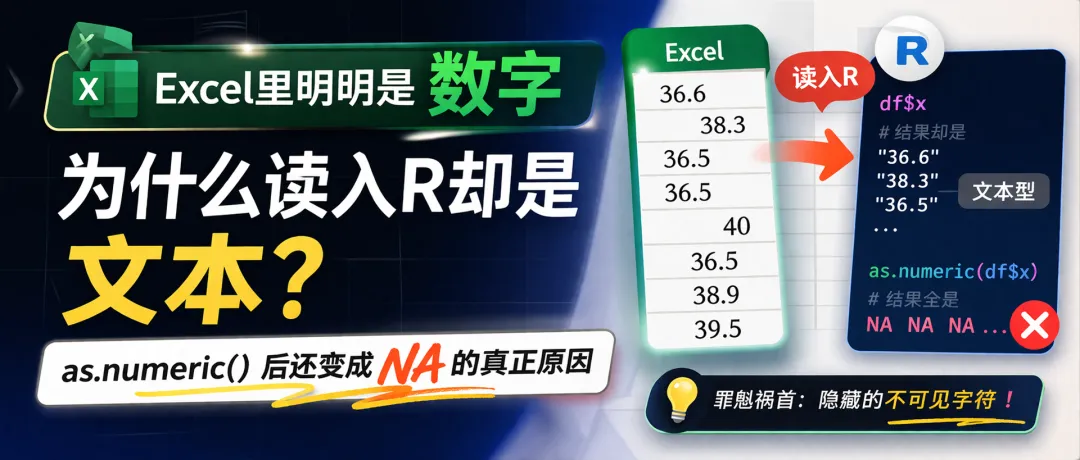
在 Excel 里看起来明明是数值,比如 36.6、38.3
读入 R 之后却被识别成 字符型(text/character)
再用 as.numeric() 强制转换时,结果却变成了 NA
例如下面这组数据,肉眼看完全是正常数字:
36.638.336.536.54036.538.939.5
但实际上,其中部分单元格前面可能藏着一个看不见的特殊字符,例如:
这就会导致 R 无法把它当作真正的数值来解析。
二、本质原因:单元格里混入了“不可见字符”
这类问题最常见的根源,不是数字本身有问题,而是 数字前后混入了隐藏字符。
这些字符包括但不限于:
U+202D Left-to-Right Override
U+200E Left-to-Right Mark
U+200F Right-to-Left Mark
从网页、PDF、Word、微信中复制带来的特殊格式字符
也就是说,在 Excel 里看起来是:
但 R 真正读到的可能是:
这个对象已经不是“纯数字字符串”了,所以:
会返回:
三、为什么 Excel 里看不出来?
因为 Excel 对这类字符的容忍度很高:
导出成 CSV 或读入 R 时,这些隐藏字符会被原样保留下来
所以问题不是 R 出错,而是 R 比 Excel 更严格。
四、这种问题通常怎么来的?
最常见的来源包括:
1. 从网页复制数据
网页表格、在线数据库、浏览器页面中常含有隐藏格式字符。
2. 从 PDF 复制数据
PDF 提取文本时很容易带入方向控制符或特殊空格。
3. 从 Word、微信、公众号、聊天记录复制
这些富文本环境经常会嵌入不可见控制字符。
4. 原始 Excel 文件本身就不干净
有时上游文件在生成时已经把特殊字符写入单元格中。
五、在 R 中如何判断是不是这个问题?
方法 1:直接查看原始内容
假设数据框叫 df,目标列叫 x:
如果看着还是正常,可以进一步用:
这个命令能更真实地展示字符内容。
方法 2:查看单个元素的底层字节
如果前面有异常字节,说明不是纯数字。
方法 3:看字符串长度是否异常
例如看起来是 36.6,理论长度应为 4;如果长度更长,通常说明夹杂了隐藏字符。
六、最实用的解决方法
方法一:保留数字、小数点和负号,其余全部删除
这是最推荐、最稳妥的方法,尤其适合“这列本来就应该全是数值”的情况。
df$x_num <-as.numeric(gsub("[^0-9.-]","", df$x))
解释:
gsub("[^0-9.-]", "", df$x):删除除数字、小数点、负号之外的所有字符
例如:
x <-c("36.6","38.3","36.5","36.5","40","36.5","38.9","39.5")as.numeric(gsub("[^0-9.-]","", x))
结果:
[1]36.638.336.536.540.036.538.939.5
方法二:定向去除常见 Unicode 隐藏字符
如果你想处理得更“规范”一些,可以只删除这类特殊字符:
df$x2 <- gsub("[\u200E\u200F\u202A-\u202E\uFEFF]","", df$x, perl =TRUE)df$x2 <- trimws(df$x2)df$x2 <-as.numeric(df$x2)
这个方法适合你已经比较确定问题来自 Unicode 控制字符的情况。
方法三:使用 readr::parse_number()
如果只是想快速提取数字,也可以用 readr 包:
library(readr)df$x_num <- parse_number(df$x)
这个函数对“数字字符串里夹杂其他字符”的情形很友好。
不过要注意,parse_number() 更适合“从字符串中提取数字”,如果数据里包含复杂格式,还是建议自己先清洗。
七、批量清理多列的方法
如果你的 Excel 中有多列都遇到类似问题,可以批量处理。
例如需要清理 temp1、temp2、temp3 三列:
cols <-c("temp1","temp2","temp3")df[cols]<- lapply(df[cols],function(x){as.numeric(gsub("[^0-9.-]","",as.character(x)))})
这样可以一次性把这些列都转为真正的数值型。
八、一个通用排查模板
日常工作里可以直接套这个模板:
# 1. 查看原始内容unique(df$temp)# 2. 查看是否有隐藏字符dput(df$temp[1:8])# 3. 清洗并转数值df$temp_num <-as.numeric(gsub("[^0-9.-]","", df$temp))# 4. 检查结果summary(df$temp_num)is.na(df$temp_num)
如果 df$temp_num 不再出现异常 NA,说明问题已经解决。
九、Excel 端能不能处理?
可以,但不一定稳定。
Excel 公式方法
假设 A1 是有问题的单元格,可以尝试:
但要注意:
所以,Excel 端有时能修复,有时修不干净。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
