卫生经济学教程:把Excel用成R语言?带你拆解最新卫生经济学建模黑科技
- 2026-04-04 18:07:31
卫生经济学教程:把Excel用成R语言?带你拆解最新卫生经济学建模黑科技点击一下 关注我哦 点亮星标 第一时间收到推送
卫生经济学中,在处理复杂的马尔可夫队列模型时,传统的 Excel 往往显得笨重、计算缓慢且极难验证。 最近国外学者提出了一种在Excel中建立马尔可夫模型的新方法(需要文献请后台私信,也可点击“阅读原文”获取)。 新方法最大的特点是利用Excel的动态数组函数,让 Excel 具备了类似 R 语言和 Python 的向量与矩阵运算能力。这不是简单的语法更新,而是给 Excel 装上了“统计编程的引擎”。 由于有大V分享过这篇文章的译文药物经济学|不使用VBA的现代Excel建模方法(一),笔者从另外的角度分享一些感受。 作者在附件中给出了非常详实的模型及其解释,在跟随着作者一步步复盘他的模型后,给我印象最深的三点分别是矩阵、堆叠及封装。 过去:构建状态转移矩阵和马尔可夫时间队列需要拖拽无数个单元格,稍有不慎就会引用错误。 现在:通过 WRAPROWS将一列概率直接生成 4×4的转移矩阵,再用 MMULT进行矩阵乘法。 笔者喜欢举例说明:MMULT矩阵乘法见下图(WRAPROWS 过于简单不做说明)。A/B/C 3家医院,按门诊/住院/手术数量列出矩阵A,各自的费用为矩阵B,现在要算3家医院的总收入。 常规算法是:医院A的门诊人数×门诊次均费用+住院人数×住院次均费用+手术台数×手术次均费用,即500*150+120*8000+30*15000=¥1485000。再依次算出医院B/C的总收入进行相加。当然进阶点的选手也可以使用 SUNPRODUCT进行计算。 但是!现在仅需要使用MMULT一个函数就可以搞定计算。且由于矩阵计算逻辑,矩阵A(3行3列)×矩阵B(3行1列)其输出的结果会自然生成3行1列的新矩阵。 
聪明的读者们肯定一下子就想到了:每个周期的转移概率和队列人群,这不就是天然的两个矩阵!直接用 MMULT一步出结果且自动排版!!! 实战意义:极大地压缩了模型的物理占地面积,让核心逻辑一目了然。 解析:在文献中,VSTACK和HSTACK 堪比排版神器。比如在蒙特卡洛模拟中,可以直接将计算好的成本、QALYs 和生命年横向拼成一个完整的结果表。 依旧举例:VSTACK和HSTACK 就简单多了。前一个是垂直堆叠,将A/B/C/D连带着各自的数值垂直堆叠成一个新的矩阵;后一个是水平堆叠。 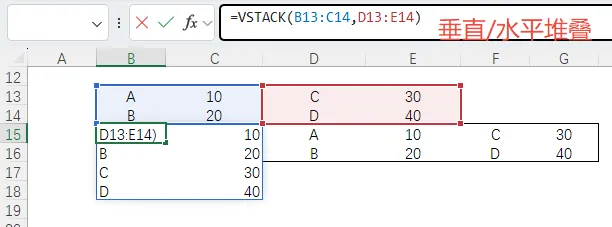
实战意义:如果不熟悉的朋友会觉得还不如CTRL+C/V,但对于规范化建模是很重要的一步。摒弃了过去为了对齐数据而预留大量空白行列的坏习惯,实现了数据的模块化拼装。 解析:LET函数允许声明变量,LAMBDA允许自定义函数。 举例: ①下图是LET 函数的文献解释,熟悉R或者python的朋友相信一眼就能看懂,LET前3行无非是先定义名称,再定义计算逻辑,第4行输出total。 
②LAMBDA 函数定义稍微绕一些,可以理解为在 Excel 里自己“创造”一个新函数,就像写一个简单的小程序,起个名字,然后像用 SUM、AVERAGE 一样反复调用它。 你想定义一个“增长率”的函数,计算逻辑是(本期-上期)/上期:=LAMBDA(old,new,(new-old)/old)(A2,B2) A列是上期数值,B列是本期数据,这样会自动显示增长率。也可以使用名称管理器将上述LAMBDA使定义为“增长率”,在excel中直接调用。 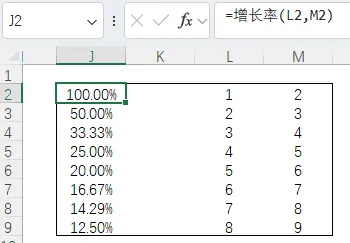
当直接用在建模时是非常有趣的,感兴趣的朋友可以自己试一下文章中结合REDUCE函数进行马尔可夫循环: =REDUCE(v_init, SEQUENCE(cycles), LAMBDA(dist, cycle, VSTACK(dist, MMULT(INDEX(dist, cycle), m_tm_A))) 解释:=REDUCE(初始分布, SEQUENCE(总周期数), LAMBDA(累计矩阵, 当前周期, VSTACK(累计矩阵, MMULT(矩阵中前一行数据, 转移矩阵)))) 实战意义:这是向 R 语言靠拢的关键一步。意味着可以在一个单元格内完成“定义参数→运行循环→输出结果”的完整逻辑闭环。 局限性剖析:这篇文献在第 4 节秀了一个极高端的操作——把整个蒙特卡洛模拟(1000 次迭代抽样 + 矩阵连乘)全部塞进了一个名为REDUCE和LAMBDA嵌套的单一单元格里。 实战举例:想象一下,你把这个只有一个超长公式的 Excel 丢给医保局的评审专家或者公司内部的HEOR。以前他们可以随便点开一个单元格看第 50 周期、第 200 次迭代的具体数字;现在,他们点开表格,只能看到一个深不见底的动态数组公式(复盘这个模型在惊叹作者巧妙设计的同时,同时也让我觉得推广使用的门槛真的很高 )。话说回来,来回在不同单元格之间验证数据是不是也很麻烦。。。
)。话说回来,来回在不同单元格之间验证数据是不是也很麻烦。。。 锐评:过度封装会导致“验证成本”剧增。代码写在 R 语言里,有完整的注释和排错机制;但把代码硬塞进 Excel 的一个单元格里,如果算错了,排查起来可想而知有多灾难! 模型主要展示了四状态马尔可夫队列,基础模型转移概率甚至是固定不随时间变化的(这验证模型已经很费脑筋了,何况随时间变化的转移概率 )。在实际的公共卫生和流行病学研究中,面对复杂的离散事件模拟(DES)或具有传染性动态变化的疾病传播模型,这种方法依然会显得捉襟见肘。但听说作者会继续更新,我也期待有新的文章!
)。在实际的公共卫生和流行病学研究中,面对复杂的离散事件模拟(DES)或具有传染性动态变化的疾病传播模型,这种方法依然会显得捉襟见肘。但听说作者会继续更新,我也期待有新的文章! 此模型的蒙特卡洛模拟虽然可以不用 VBA,但在极大规模的迭代(例如复杂模型的大量抽样)下,Excel 的单个单元格计算限制可能会成为瓶颈。把所有计算压在一个单元格里,可能会导致表格卡死。当然这个只在复杂模型中存在,简单的模型用什么方法都不会卡顿的。 对于未来有志于深入公共卫生研究或探索更前沿的流行病学建模的朋友,这套高阶 Excel 玩法确实是一个极佳的逻辑训练场和过渡桥梁。确实如作者所说,这套模型的最终意义,或许是作为一座桥梁。如果新一代的建模者能习惯这种“向量化、封装化”的思维,那么未来无论是过渡到 R 语言分析真实世界数据(RWD),还是利用 Python 爬取和清洗竞品管线信息,都会变得水到渠成。毕竟,向AI时代靠拢,多少还是要懂一些代码知识。 ---欢迎评论区留言讨论---
Paulden M. A Modern Approach for Constructing Decision Analytic Models in Microsoft Excel. Pharmacoeconomics. 2026 Mar 18.
一、眼前一亮的3大技术“矩阵、堆叠及封装”
1.降维打击——矩阵与向量运算(MMULT,WRAPROWS)
2.空间折叠——数据堆叠与动态重构(VSTACK, HSTACK)
3.封装思维——在单元格里写代码(LET, LAMBDA)
二、3大局限性
1.“黑盒审查”的噩梦:HTA 评审专家真的看得懂吗?
)。话说回来,来回在不同单元格之间验证数据是不是也很麻烦。。。2.复杂疾病模型依然是硬伤
)。在实际的公共卫生和流行病学研究中,面对复杂的离散事件模拟(DES)或具有传染性动态变化的疾病传播模型,这种方法依然会显得捉襟见肘。但听说作者会继续更新,我也期待有新的文章!3.算力瓶颈与并行计算的悖论
三、总结与讨论
帮助与交流请联系:imtxboy@126.com 转载与引用:请注明“小唐的一天”
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

