一个 Skills 真正拉开差距的,不是创建,而是迭代

前段时间,很多人都在学怎么创建 Skills。
会建目录,会写 SKILL.md,会配 description,再加一点步骤说明,一个 Skills 很快就能搭起来。第一版做出来的时候,成就感通常很强,因为它看起来已经“能用了”。
但真正把它拿到工作里反复用几天,就会发现另一件事:
创建,只是开始。迭代,才是决定这个 Skills 能不能长期干活的关键。
因为一个 Skills 刚建好的时候,往往只解决了一个问题:它大概知道自己要做什么。
但这还远远不够。
真正到了实际使用阶段,问题会一个个冒出来。
有时候,它会在不该出场的时候突然出现。有时候,明明就是它最擅长的任务,它反而没被触发。还有时候,它看起来也完成了,但输出忽高忽低,这次像个熟练同事,下次又像个刚入职的新人。
这也是为什么,很多 Skills 不是“不会建”,而是“建完就停了”。最后的结果就是:第一版看起来很完整,真正用起来却总差一口气。
所以,Skills 这件事,真正的门槛从来不在创建,而在于后续的迭代。
为什么很多 Skills 会越用越别扭
原因很简单:第一版通常只是一个“能跑起来的版本”,不是一个“能稳定交付的版本”。
很多人第一次做 Skills,习惯先把功能写全,恨不得一个 Skills 既能分析数据,又能写总结,还能顺手生成图表建议,甚至还能覆盖别的相关任务。表面看起来很强,实际上边界很容易模糊。
而边界一模糊,后面就会连锁出问题:
说白了,第一版的 Skills 更像“会做一点事”,而成熟的 Skills 才像“知道什么时候做、按什么顺序做、最后交出什么样的结果”。
这中间的差距,靠的就是迭代。
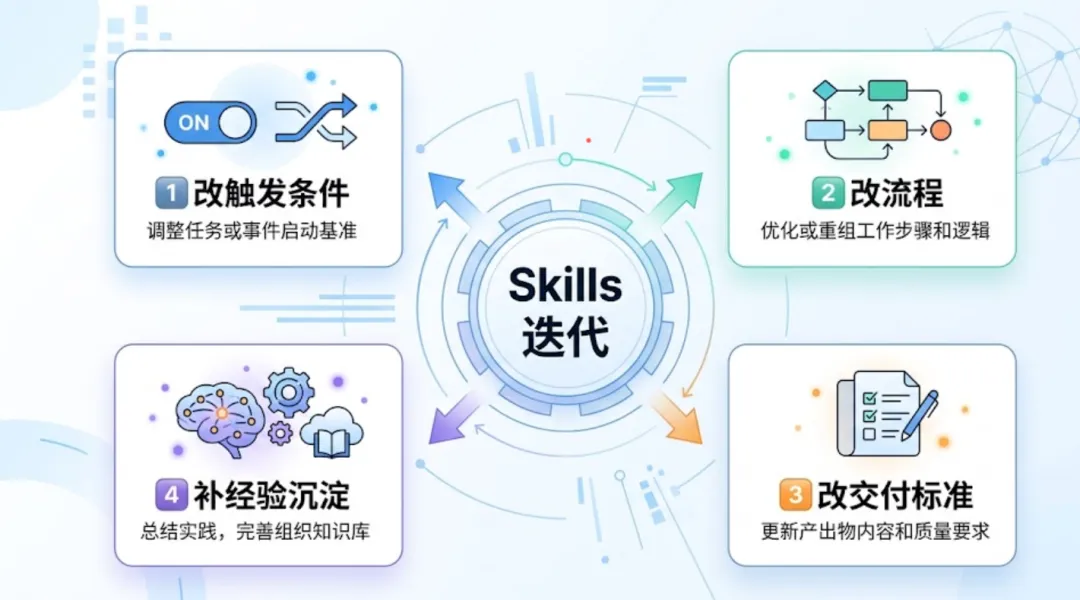
Skills 的迭代,到底在改什么
很多人一说迭代,第一反应就是继续改提示词。
当然要改,但如果把迭代理解成“补几句说明”,那就太浅了。一个 Skills 真正有效的迭代,通常至少包括四层:
这四层,基本就是一个 Skills 从“能用”走向“真能干活”的主路径。
而且这四层不是乱改的,最好是一层一层往前推。因为 Skills 的问题,很多时候不是功能不够,而是路由、顺序、标准、经验这几个环节没有写实。
第一层:先改触发条件
很多 Skills 的问题,不是做不好,而是来错了场景。
这类问题最典型的表现,就是误触发和漏触发。
比如,本来只是想写一段 VBA 代码,结果 Excel 数据分析 Skills 也跑出来了。再比如,用户明明上传了一个 CSV 文件,就是想看缺失值、异常值和汇总结论,结果这个 Skills 却没被调用。
这时候,优先要动的,往往不是 Steps,而是 description、When to use、When not to use 这些“触发条件”。
很多人第一版会这么写:
name: excel-data-analysisdescription: 帮用户分析 Excel 数据,并生成分析结果。
看起来没问题,但其实边界非常模糊。“分析 Excel 数据”这个范围太大了,写公式、做图表、写 VBA、搭 BI 报表,甚至做数据库整理,模型都有可能觉得这也算“分析”。
更稳的写法应该是这样:
name: excel-data-analysisdescription: 当用户上传 Excel 或 CSV 文件,希望完成数据清洗、字段检查、描述统计、异常值识别,并输出结构化分析结论时使用。不要用于网页开发、BI 大屏搭建、复杂数据库建模或纯 VBA 编程任务。
这类修改看起来只是把一句话写长了,但本质上是在做一件非常重要的事:
把 description 从一句介绍,改成一条路由规则。
真正稳定的 Skills,不是只会说“我能干什么”,而是会提前说明:
只要这一层没写准,后面的流程再完整,也很容易出问题。
第二层:流程要改得更像真实工作
触发条件稳了之后,接下来最常见的问题就是:它确实被调起来了,但做事顺序不对。
很多 Skills 第一版的问题,不在于内容少,而在于流程太虚。
比如常见的写法是这样:
## Steps1. 分析文件2. 总结结果3. 提出建议
这几步当然没错,但问题在于,几乎没有任何约束力。
“分析文件”到底先分析什么?先检查字段,还是先下结论?先看缺失值,还是先解释业务波动?这些关键顺序,全部都没有落下来。
而真实工作里,顺序恰恰特别重要。
拿数据分析场景来说,更稳的流程通常应该写成这样:
## Steps1. 先检查字段、缺失值、重复值和数据类型2. 再判断是否存在明显的数据质量风险3. 然后做描述统计和分布检查4. 识别异常值及可能原因5. 输出适合业务阅读的结构化结论6. 必要时补充下一步分析建议
这样改的重点,不是“写得更详细”,而是“写得更像真实工作的顺序”。
因为很多时候,不是不会分析,而是顺序一乱,后面全乱。
字段都没看明白,就开始给结论。数据质量风险还没确认,就急着解释异常。用户明明是想拿给老板看,结果最后输出成了一份技术笔记。
所以流程这层的优化,本质上是在把自己的工作方法写实。写得越接近真实工作,Skills 的稳定性通常就越高。
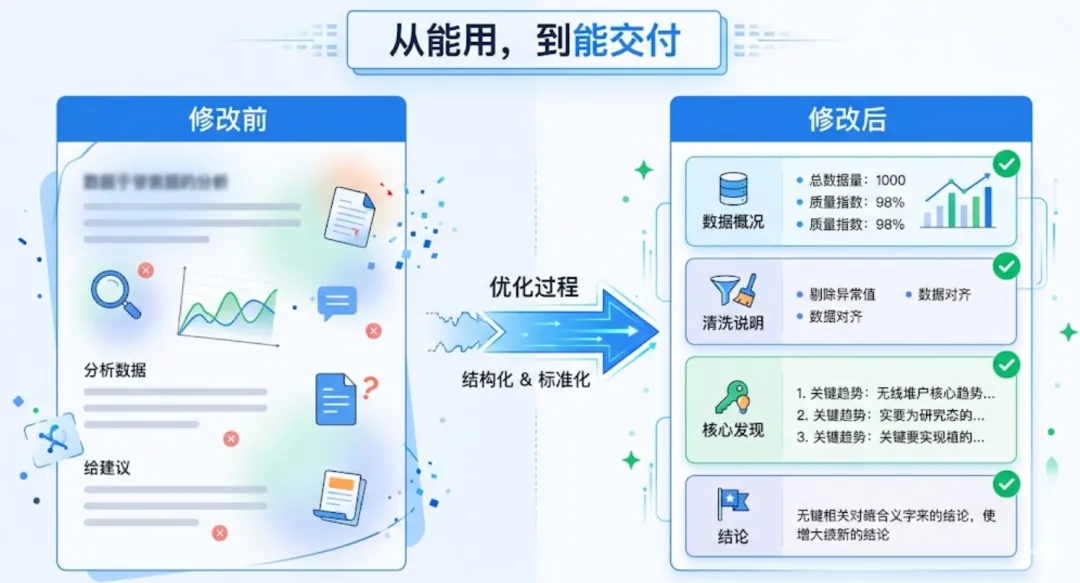
第三层:不只是会做,还要把交付标准写出来
很多 Skills 还有一个常见问题:它看起来已经完成了,但其实不够交付。
原因往往出在 Output 写得太空。
比如这样:
这类写法的问题是,模型很容易觉得自己已经交卷了。但从实际使用角度看,这种输出没有验收标准。
“分析结果”到底包括什么?“建议”是业务建议,还是下一步分析建议?没有写清楚,最终结果就很容易忽多忽少、忽深忽浅。
更稳的写法通常是这样:
## Output输出内容至少包括:- 数据概况- 清洗说明- 核心发现- 异常说明- 图表建议- 业务结论- 下一步建议(如适用)
一旦把输出结构写成这样,Skills 的表现通常会明显稳定很多。因为它不再只是“回答一下”,而是开始按交付标准来完成任务。
这一点很关键。
工作里真正让人放心的,不是一个同事“会做”,而是他知道最后该交什么。Skills 也是一样。
第四层:真正拉开差距的,是补经验沉淀
前面三层,解决的主要还是“它能不能稳定干活”。
再往后,真正拉开 Skills 差距的,往往就不是继续加几句提示词,而是把自己的经验沉淀进去。
因为真正的工作差距,很多时候不在流程本身,而在那些“做久了才会顺手补上的判断”。
比如:
- 缺失值超过一定比例时,结论不能写得太满,要先提示风险
这些内容,不一定适合一直塞在 SKILL.md 里,更好的方式是拆到单独的文件里。
例如,放进 references/:
references/anomaly_rules.md
内容可以写成这样:
# 常见异常判断规则1. 单个指标突然升高时,先检查统计口径是否发生变化2. 缺失值超过 20% 时,结论中必须提示数据风险3. 字段命名混乱时,先统一字段,再做汇总分析4. 面向管理层输出时,优先写业务含义,再写技术过程
再比如,把固定输出风格放进 assets/:
assets/report_template.md
内容可以写成这样:
# 数据分析简报## 一、这份数据先看什么一句话交代数据范围、时间、字段情况## 二、这次最值得关注的发现最多写 3 条,每条都要带业务解释## 三、哪些结论要谨慎提示缺失值、异常口径、样本偏差## 四、下一步建议按“能立刻做”和“后续再看”分开写
走到这一步,Skills 就不再只是“照步骤走”。它会越来越像一个熟悉你工作方式的数字同事。
更稳的改法:一次只改一个关键变量
知道该改哪几层之后,还有一个特别重要的原则:每一轮,只改一个关键变量。
这是很多人最容易忽略,但其实最影响效果的一点。
因为一旦发现 Skills 不够稳,很多人会本能地一起改很多地方:
今天改 description,顺手又把 Steps 重写了,再把 Output 和模板一起换掉。
最后看起来改了很多,但到底是哪一步起了作用,根本说不清。一旦效果变差,也不知道该退回哪一版。
更稳的做法是:
- 如果这轮主要问题是不够交付,就只改
Output 或模板 - 如果这轮主要问题是不够像自己的工作风格,就补
references/ 或 assets/
这样改有三个明显好处:
第一,能看清这次到底改了什么。第二,一旦效果变差,知道该回退到哪里。第三,可以用同一批案例去做前后对比,真正看出优化有没有生效。
一个成熟的 Skills,通常不是靠一次写完,而是靠这种有章法的小步迭代,一点点长出来的。
AI 工具,最适合帮忙做什么
说到这里,很多人会问:Skills 迭代这件事,AI 工具到底能帮上什么忙?
答案其实很直接。
AI 最适合帮忙做三类事:
特别是第一类,价值非常大。
因为一个 Skills 用上一段时间之后,手里往往会积累十几条、几十条真实案例。人工一条条看,不是不行,但很容易越看越乱,最后只记住印象最深的那几次。
这时候,把案例整理成统一格式,再交给 AI 去做批量归纳,效率会高很多。
例如,可以先整理成这样:
[案例 01]用户请求:帮我做一个 Excel 销售数据分析报告是否触发:是结果评价:部分正确问题备注:输出太偏技术,不适合直接发给老板[案例 02]用户请求:帮我写一段 VBA 自动筛选代码是否触发:是结果评价:错误问题备注:这本来不该由这个 Skills 处理[案例 03]用户请求:我上传了一个 CSV,想检查缺失值和异常值,并生成简报是否触发:否结果评价:错误问题备注:这本来应该触发,但没有触发
然后,把这些案例交给 AI,不是让它自由发挥“帮忙总结一下”,而是让它按固定框架来判断。
比如,可以直接用下面这段提示词:
你现在是一个 Skills 迭代分析助手。我会给你一批 Skills 的真实使用案例,请你完成下面 4 件事:1. 逐条判断每个案例属于哪一类问题,只能从下面几类中选择:- 误触发- 漏触发- 步骤不完整- 输出结构问题- 业务判断问题- 风格模板问题2. 对每个案例,判断最可能需要修改的文件位置,只能从下面几类中选择:- SKILL.md 的 description- SKILL.md 的 When to use / When not to use- SKILL.md 的 Steps- SKILL.md 的 Output- references/*- assets/*- scripts/*3. 统计本批案例中出现最多的前 3 类问题,并说明哪一类最值得优先修改。4. 最后只给出一轮迭代建议,要求这一轮只允许修改一个关键变量,并按下面格式输出:- 本轮优先修改什么- 为什么先改这里- 修改前是什么样- 修改后改成什么样- 预期会改善什么- 暂时不会改善什么输出格式固定为:A. 案例逐条诊断B. 问题统计汇总C. 本轮迭代建议D. 修改前后对比
这类用法真正有价值的地方在于:
AI 不是在替你“随便总结”,而是在按你定义好的评审框架,做一次结构化复盘。
跑几轮之后,Skills 的迭代就会变得非常清晰:
这轮修触发,下一轮修流程,再下一轮修交付,最后再把自己的经验慢慢补进去。
这样改出来的 Skills,通常会比“凭感觉来回重写”稳得多。
写在最后
很多人第一次接触 Skills,会觉得它最重要的价值在于“创建出来”。
但真正用久了就会发现,创建只是把一个框架搭起来。真正有壁垒的,是后面的迭代。
因为一个成熟的 Skills,最后拼的从来不是写了多少字、堆了多少功能,而是有没有把这些关键东西一点点沉淀下来:
走到这一步,Skills 才不再只是一个“会响应的工具”,而更像一个越来越懂你、越来越像你的数字同事。
而这,才是一个 Skills 真正开始能干活的时刻。

