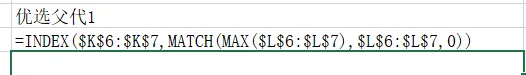1 现实痛点
在实际工程场景中,优化问题无处不在,但多数工程人都面临以下痛点,传统方法难以破解,有没有一种方法,能更快找到一个“足够好的解”。:
无明确数学模型,传统方法无从下手:多数工程问题(如零件加工质量优化、设备调度)受多因素影响,存在高维度(变量多)、非线性(关系复杂)、多峰(多个局部最优),无法推导精准的目标函数,经典的梯度下降、线性规划等方法难以不适用,只能凭经验试错。比如穷举法:计算量大(如100维问题,1秒算1亿次需3×10^84年),梯度下降:依赖导数,易陷入局部最优。
多约束、非线性,试错成本极高:以工艺参数优化为例,往往涉及3-5个变量,每个变量有不同取值范围,两两组合后候选解数量呈指数增长,人工试错不仅耗时久(可能需数天反复实验),还容易错过最优解,造成材料、工时浪费。而遗传算法,无需导数、全局搜索,是仿生智能优化的典型代表,能够极大提交计算效率。
编程门槛高,算法落地难:虽然Python、Matlab可实现遗传算法,但多数工程技术人员缺乏编程基础,面对代码调试、参数适配无从下手,导致“懂算法原理,却无法落地到实际工作”。
需快速试算,拒绝复杂工具:工程中常需快速验证优化思路、初筛参数,而专业算法软件(如Matlab)操作繁琐、启动慢,无法满足“即时试算、灵活调整”的需求。
而Excel版遗传算法恰好精准破解以上痛点——无需编程、无需复杂模型、操作可视化、调整灵活,既能快速验证优化思路,又能直接落地解决低维度工程优化问题,成为工程人高效工作的“轻量工具”。
另外,Excel能够更好地呈现计算的过程,从而帮助我们更好理解算法的原理和计算过程,从而实现对算法结果的诊断,而非简单的复制和粘贴代码,而且懂了原理后,在这个基础上,我们也可以继续进行组合优化和算法改进的工作。
2 概念和原理
遗传算法(GA)是一种模拟达尔文生物进化论的随机搜索优化算法,是一种启发式优化方法,核心是通过“选择、交叉、变异”三个操作,让随机的初始解不断进化,最终逼近问题的最优解(全局最优/近似最优),无需提前知道问题的数学模型(非常关键),特别适合工程中“多约束、非线性、无解析解”的优化问题(如工艺参数优化、资源分配、路径规划等)。
(1)遗传算法与生物进化的对应关系
把算法中的“解”比作生物的“个体”,所有解的集合是“种群”,解的优劣是“适应度”,解的参数是“基因”,算法的寻优过程就是种群的进化过程:
| 生物进化概念 | 遗传算法概念 | 核心作用 |
|---|
| 个体 | 问题的一个可行解 | 算法的基本操作单元一个潜在解,如染色体=二进制串11010 |
| 种群 | 可行解的集合 | 进化的载体,包含多个候选解多个个体的集合(如50个随机生成的二进制串) |
| 基因 | 解的参数/变量 | 决定个体的“性状”(解的优劣) |
| 适应度 | 解的评价指标 | 判断个体是否“优秀”,适应度越高越易保留评价解的质量(如Fitness=1/(目标函数值+ε)) |
| 选择 | 优胜劣汰 | 保留适应度高的个体,淘汰劣质个体,保证进化方向 |
| 交叉 | 基因重组 | 优秀个体交换基因,产生更优的子代,实现解的“改良” |
| 变异 | 基因随机突变 | 随机改变个别基因,避免种群陷入“局部最优”,保证搜索的全面性 |
通过种群,遗传算法就保留多方案并行比较的逻辑。
适应度(Fitness)用于评价一个方案的优劣,适应度高,并不等于“完美解”,而是“相对更优的解”。
选择使得好的方案更容易被保留,交叉使得优秀方案的特征重新组合,变异实现小概率随机变化,避免陷入局部最优。
(2)遗传算法的核心特点
随机搜索但不盲目:以适应度为导向,始终向更优解的方向进化;
全局寻优能力强:变异操作避免“死磕局部最优”,适合工程复杂问题;
无需数学模型:只需定义“解的形式”和“优劣评价标准”,无需推导目标函数的导数/梯度;
操作简单易实现:核心仅3个操作,可通过Excel、编程等多种方式落地。
(3)遗传算法的通用求解步骤
编码:将工程问题的“实际解”转化为算法可处理的“基因编码”(如数字、二进制串),是算法落地的第一步;
初始化种群:随机生成一定数量的初始解,组成初代种群(数量不宜过少,否则搜索范围窄);
计算适应度:按工程问题的“评价标准”,计算每个个体的适应度(如“成本最低”则成本越小适应度越高);
选择操作:按适应度高低筛选个体,适应度越高被选中的概率越大;
交叉操作:让选中的优秀个体随机配对,交换部分基因,生成子代个体;
变异操作:以极低的概率随机改变子代个体的部分基因,引入新的解;
终止判断:若达到进化次数/适应度不再提升,输出最优个体(最优解);否则将子代作为新种群,返回步骤3继续进化。
遗传算法就是“随机生一批解→挑好的→好的互相结合生更好的→偶尔变个异防僵化→反复迭代直到找到最优解”。
具体算法流程如下:
基因编码设计:
| 编码类型 | 适用场景 | 示例 |
|---|
| 二进制 | 离散决策(是否采购) | 1101表示选A/B/C设备 |
| 实数 | 连续参数(混凝土配比) | [0.5, 2.3, 40] |
| 排列 | 顺序敏感问题(施工工序) | [3,1,4,2] |
算法关键参数默认值:
交叉概率:60%~90%
变异概率:1%~10%
最大迭代次数:100~1000次
终止条件:
适应度函数设计:
目标转换规则:最大化问题:直接使用原函数(如利润);最小化问题:取倒数(如工期:Fitness = 1/(工期+1))
多目标处理方法:加权求和:Fitness = 0.7×利润 + 0.3×质量评分;帕累托排序(NSGA-II算法)
约束处理技巧:罚函数法:Fitness = 目标值 - 1000×超预算金额;修复法:强制修改不可行解为可行(如随机删除超预算设备)
选择操作策略:
轮盘赌选择:
锦标赛选择:
精英保留:
强制保留当代最优个体到下一代
保留比例:通常1%~5%
交叉操作策略
单点交叉(二进制):
算术交叉(实数编码):
公式:子代 = α×父代1 + (1-α)×父代2(α∈[0,1])
示例:父代[5,8],α=0.3 → 子代[5×0.3+8×0.7=7.1]
顺序交叉(OX,排列编码):
步骤:保留父代A的片段 → 按父代B顺序填充剩余位置
示例:父代A[1,2|3,4|5,6],父代B[6,3,5,2,4,1] → 子代[3,4,5,2,1,6]
变异操作策略
位翻转(二进制):
高斯变异(实数编码):
交换变异(排列编码):
步骤:随机选两个位置交换(如[1,2,3,4] → [1,4,3,2])
在变异中,精英保留,确保历史最优解不丢失
为了防止种群陷入局部最优,需设置变异概率,如变异率=0.01~0.1
通过学习遗传算法,可以改变了我们看待复杂问题的方式:
不再执着于一次求最优
接受不确定性与试错
用“进化”应对复杂现实
3 Excel实操
项目问题
某工厂项目存在多种配置方案,不同方案在技术选择、设备等级、人员规模等方面存在差异,如何在满足工期约束的前提下,使项目总成本最小。
基因编码
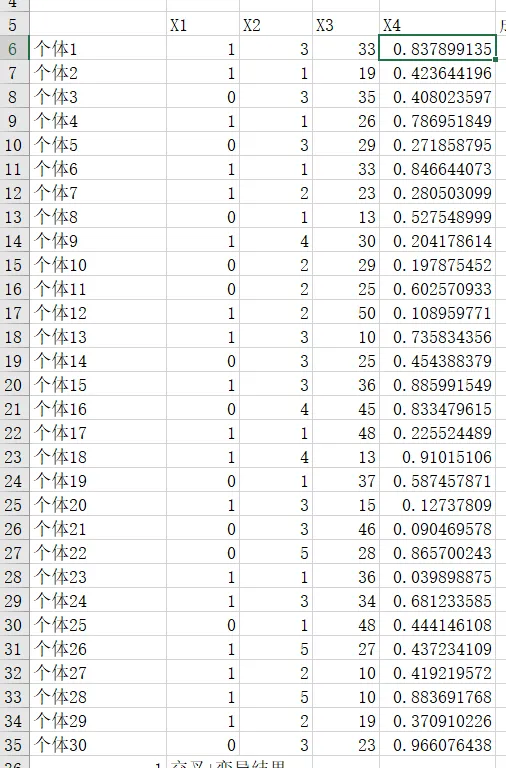
我们定义 4 个决定工期和成本的决策变量:
| 变量 | 含义 | 取值范围 |
|---|
| X1 | 是否采用新技术 | 0 / 1 |
| X2 | 设备等级 | 1–5 |
| X3 | 人员配置规模 | 10–50 |
| X4 | 外包比例 | 0–1 |
基因编码设计
一个染色体 = 一个完整方案
每个基因 = 一个决策变量
也就是说:
[X1, X2, X3, X4]
就是一条染色体。
在 Excel 中:
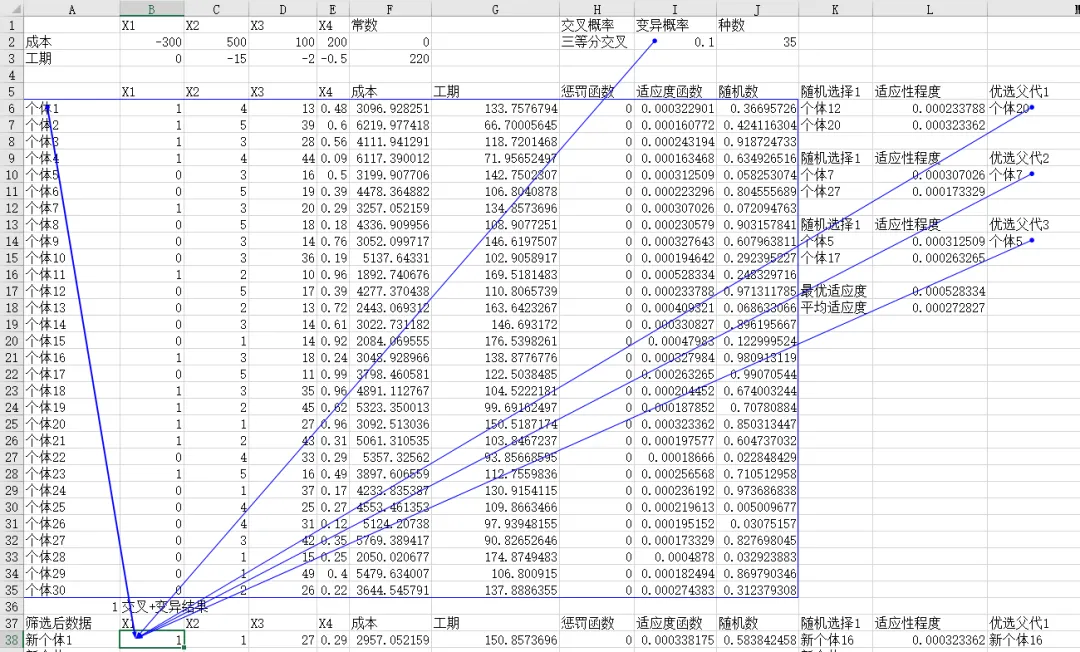
个体和初始种群生成
在 Excel 中,直接使用随机函数即可:
=RANDBETWEEN(0,1)=RANDBETWEEN(1,5)=RANDBETWEEN(10,50)=RAND()
向下填充 20–50 行,就得到了第一代“随机方案”。
📌 这一步相当于“拍脑袋先想一堆方案”,但数量多、覆盖面广。
生成函数的Excel设置如下:
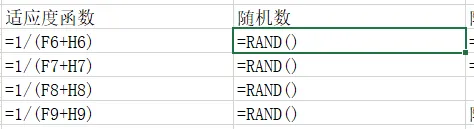
构造适应度函数(核心中的核心)
遗传算法本身并不知道什么是“好方案”,你必须用适应度函数告诉它。
一个简单但合理的工程假设
人员越多,成本越高
设备等级越高,成本越高
新技术可以降低部分成本
超出目标工期要受到惩罚
在这里假设,成本函数构成如下,可以通过多元回归方式或者进行获得Cost = - 300X1+ 500X2 +100X3 + 200X4
工期函数Time = 220 - 15X1 - 2X_2 - 0.5X_3
设目标工期为 180 天。
惩罚函数(关键工程思想)
=IF(Time>180,1000*(Time-180),0)
📌 注意:遗传算法通常不“硬性剔除”不可行解,而是通过惩罚,让它们自然被淘汰。
5️⃣最终适应度函数
=1/(Cost+Penalty)
适应度越大,方案越好。
我们首先在Excel中设置参数如下:
接下来,我们在通过Excel的Sumproduct和IF函数进行设定。核心就是将生成的方案计算出其相应的成本和工期进行结合。接下来是设置适应度函数,适应度函数为成本和惩罚函数的反函数,也就是工期和成本越大,适应性越小。选择操作:让好方案“活下来”
我们采用锦标赛选择法(非常适合 Excel)。
步骤很简单:
随机抽取两个方案
比较它们的适应度
选择适应度更高的方案作为父代
👉 含义:不是“绝对最优才活”,而是“相对更好的更容易留下”。
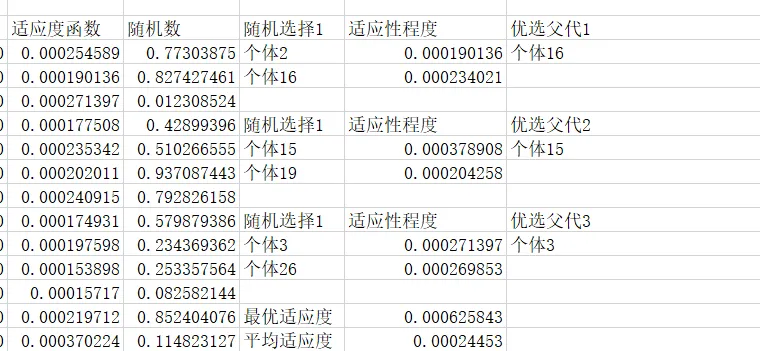
在Excel中是如何操作呢,为了让大家更好地掌握原理,我们选择随机选择3次。每次选择2个个体,然后挑选其中更优秀的个体,为后面的交叉操作做好准备。
第二步是随机选择两组的个体,其Excel设置函数为=INDEX(A6:A35,RANDBETWEEN(1,COUNTA(A6:A35))),其大一为在个体列中,根据随机数抽取一个结果出来。第三步是将随机选择的适应性函数匹配出来,在这里选择=VLOOKUP(K6,$A$6:$I$35,9,FALSE)即可。第四步是优选出更优秀的个体,我们根据适应性结果,去匹配合适的个体,在这里选择=INDEX($K$6:$K$7,MATCH(MAX($L$6:$L$7),$L$6:$L$7,0))进行提取。在这里我们选择了3个个体作为后面杂交的基础,我试了2个个体,发现容易钝化,所以用3个个体比较合适。
交叉操作:方案的“重组”
交叉的本质是:把两个方案的优点组合在一起。
在 Excel 中可以这样做:
=IF(RAND()<0.5, 父代1基因, 父代2基因)
对每一个变量都做一次随机继承,你就得到了一个新方案。
交叉操作是非常关键的,也是遗传算法的核心,我们是如何实现交叉的呢?
其函数设置为:SWITCH(RANDBETWEEN(1,3),1,INDEX(A6:J35,MATCH(M6,A6:A35,0),COLUMN()),2,INDEX(A6:J35,MATCH(M10,A6:A35,0),COLUMN()),3,INDEX(A6:J35,MATCH(M14,A6:A35,0),COLUMN()))。其中column的作用是对应位置的列,目的是为了后续迭代的方便,本质是对应第几列。
变异操作:防止“思路僵化”
如果所有方案都越来越相似,算法就容易“陷入局部最优”。
所以需要小概率变异:
=IF(RAND()<0.1,重新生成方案值,优选方案的值)
📌 工程直觉:偶尔“跳出常规方案”,反而可能带来更优解。
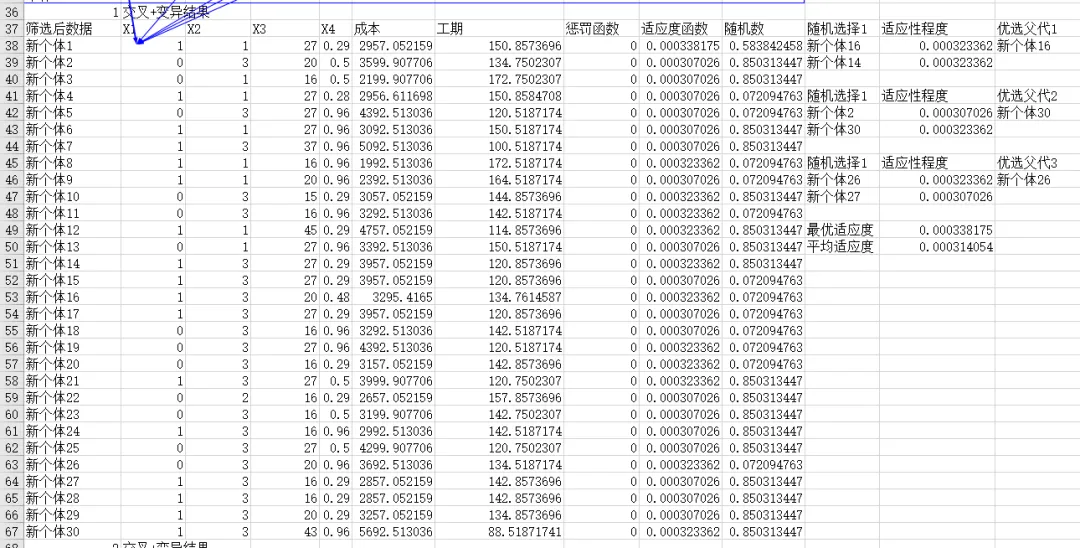
为了方便,在这里我们将交叉和变异组合在一起设置公式。
=IF(RAND()<$I$2,RANDBETWEEN(0,1),SWITCH(RANDBETWEEN(1,3),1,INDEX(A6:J35,MATCH(M6,A6:A35,0),COLUMN()),2,INDEX(A6:J35,MATCH(M10,A6:A35,0),COLUMN()),3,INDEX(A6:J35,MATCH(M14,A6:A35,0),COLUMN())))
其Excel设置效果如下:
迭代:让方案一代代进化
需要完成以下步骤:
生成新一代方案
重新计算适应度
记录每一代最优解
不断重复,直到得到满意解。
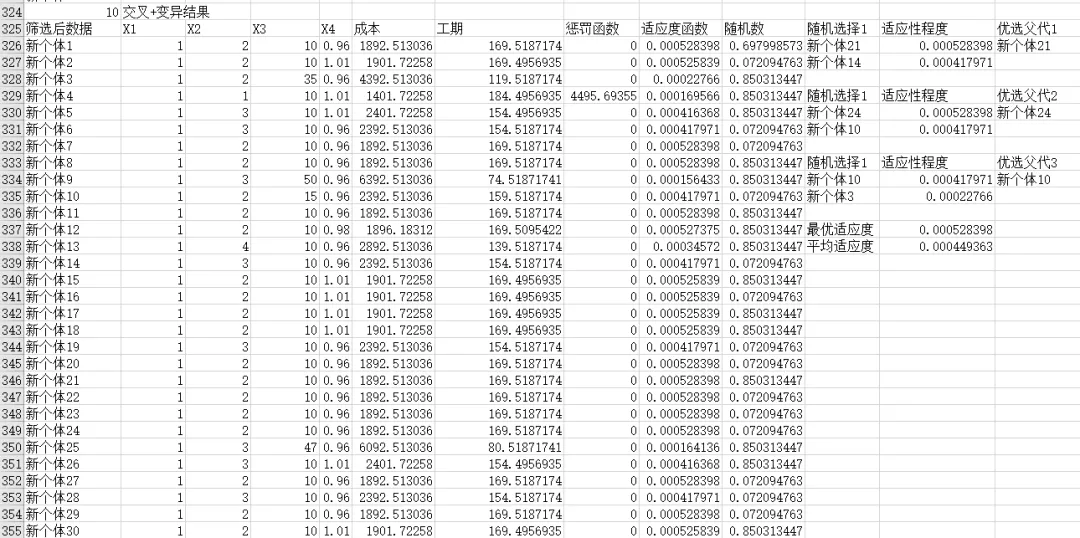
我们在Excel中如何进行重复呢?
首先根据交叉和变异结果生成新方案,然后计算成本和工期,接下来计算适应度函数,优选个体,我们将其公式自动化,就可以通过反复粘贴是实现迭代啦。左上角的1是第一次。
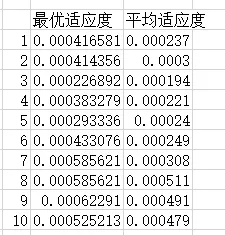
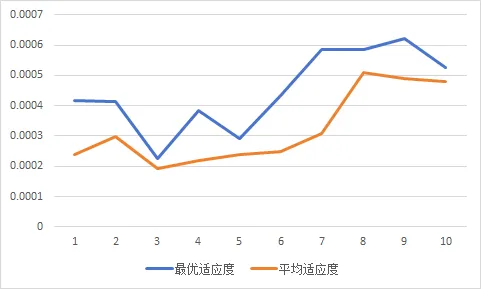
效果展示
我们将每一代的最优适应度和平均适应度提取出来,组成一个表。其中适应度函数采用max实现,平均适应度采用average实现。
从图中你会看到:
用 Excel 折线图画出来,“进化过程”会非常直观。
我们进行了10次迭代,如果你愿意复制的话,可以不断迭代。如果你有兴趣的话,可以关注公众号下载这个文档,反复迭代试试看,不过对于学习和小型工程,这个文档应该是够用了的。
知识点分析
学习视频
资源下载
课程文档下载,请关注公众号,菜单栏点击获取。
总结
本文应该是全网首个纯公式的Excel遗传网络算法版本,相比一些VBA版本,能够更好地展现进化的过程。通过基于Excel的遗传算法原理与工程应用,你会理解到遗传算法并不神秘,它本质是一套工程决策逻辑,无需编程,采用Excel公式足以承载完整算法流程,通过掌握建模思路,你以后进行应用就简单啦。用Excel进行遗传算法分析,非常酷。我是兔子家的萝卜头,请问你学会了吗?相关推文
版权所有,商业转载请联系本人。
长按关注本公众号,

问卷调查,调研您关注或感兴趣的问题,方便请填写调查问卷(长按二维码识别):