帮写PPT、核对发票、搞科研,港大/理大InfiAgent V3开源:靠“外置记忆”实现长跑,比对话框更务实的“全流程数字员工”.
- 2026-04-07 00:05:30
请在微信客户端打开
▋ 推荐阅读:
设计行业的天又要变了,美团/港科大开源 PosterOmni:为解决“品牌ID走样”与“排版乱码”而生的通用海报设计Infra
不仅是视频换脸,更是全模态一致性:字节开源 DreamID 系列,在对称式 DiT 架构下实现从视频换脸专项到音视频统一生成
42k小时数据+零样本!SoulX-Singer开源:中英粤三语自由切换,歌词随意改,音色随便换,AI歌声合成’准’到离谱”
撕掉 Pony Alpha 的假面!匿名霸榜 OpenRouter,智谱 GLM-5 炸场发布:744B 开源巨兽,代码能力硬刚 Claude 4.5!
字节年前输出拉满,Seedance2.0 后 ALIVE 炸穿音视频天花板
OpenClaw 部署太麻烦?AionUi 把 OpenClaw、Gemini CLI、Claude Code 集成一个界面,无需配置,下载即用!
“极限蒸馏”!400M 参数硬刚 7B?英伟达开源C-RADIOv4,把三个“宗师”塞进 400M躯壳
9B小钢炮!面壁MiniCPM-o 4.5焕新升级:能在Mac上跑的全模态AI,边看视频边聊天,还能克隆声音
单卡3090可跑!清华WideSeek-R1全量开源:首创MARL“宽度缩放”,让4B 小模型靠“组织架构”,在广度搜索任务上逼近 671B
能“主动记忆”“自我复盘”的智能体:MemSkill 框架开源,以“自主进化”提升 AI 长任务表现
百度开源“PaddleOCR-VL-1.5”刷新SOTA,不到 1B 参数超越 200B 大模型,文档理解打到 94.5%,手机拍歪、页面弯曲、屏幕反光精准识别

资源导航
项目主页(GitHub): https://github.com/polyuiislab/infiAgent
论文直达: https://arxiv.org/html/2601.03204v1
发布机构: 香港大学、香港理工大学 镜像拉取(Docker):docker pull chenglinhku/mlav3:latest
发布动态:2026 年 1 月正式发布论文,近期(2月)发布了支持 Skills 扩展的 V3 版本及桌面端。
开源协议: GPL-3.0 License
大家新年好!我是一只阔乐菌。
爆竹声中一岁除,在这个合家团圆、围炉守岁的时刻,于此对所有春节还在坚守岗位的你们说声:
新年快乐,你们辛苦了!万家灯火因为你们的坚守得以长明,愿你们回家依然有灯、有热腾腾的年夜饭和守候你们的人。也愿此刻的每一个人,都能在新的一年里财源滚滚,平安喜乐。
发这篇文章时,春晚刚刚拉上序幕,估计不少人正一边盯着春晚,一边刷着 AI的最新趋势。
如果你关注了 Anthropic 的 Claude Code,或者正在研究那个作者 (Peter Steinberger)刚加入 OpenAI 且依然保持独立开源的 OpenClaw,你一定会发现,2026 年初的 Agent 圈子正在发生一场质变:
大家不再满足于让 AI 帮我们回个邮件,而是希望它能真正像个“数字员工”一样,干那种需要持续几天、阅读成千上万页资料、反复修改代码并最终出具专业报告的重体力活。
这种活,传统的 Agent 架构基本跑不到一半就“降智”或者溢出了。 而由香港大学与香港理工大学团队研发的 InfiAgent(多层级智能体 MLA V3),正在尝试从 Infra 层给 Agent 换上一套“无限续航”的肺。
InfiAgent 将大模型从“聊天对话框”彻底转变为能干重活的“全流程数字员工”。它能帮人一键生成 54 页行业深度研报(含 PESTEL、波特五力等专业框架)、自主撰写达到 EI/IEEE 会议录取水准的 LaTeX 学术论文(涵盖文献调研到代码仿真全闭环)、自动化处理80 篇以上海量文献综述,甚至能像电脑助理一样自动整理杂乱文件夹、制作 PPT 及核对报销发票。它通过外置“磁盘记忆”解决了 Agent 运行久了就忘记目标的顽疾,真正实现了数以天计、上百步操作的重载办公与科研自动化。
在 InfiAgent 官方发布的几个视频里,我看到的不是一个对话框,而是一条“自动化知识生产线”。 为了讲清楚它的能力,我把视频里的三个地狱级任务拆开了讲,这部分内容可能会比较长,建议大家结合论文里的 $S_t = F_t$ 公式(即状态 St 等于文件系统 Ft)来理解。
1. 场景一:54页深度行业报告的“工业化生长”
视频展示了一个任务代号为 assignment_test.pdf 的生成全过程。 用户给出的指令很简单:“调研中国电动汽车(EV)行业战略。” (PS:这种任务如果交给传统的 RAG Agent,大概率会因为搜到的资料太多,把上下文塞爆,最后给你出一个 500 字的口水话摘要。)
但是在 InfiAgent 的视频里,我们可以看到一个极其有序的过程:
• 大纲初始化(Thinking 阶段)
视频中,Alpha Agent(顶层编排者) 启动后,右侧的文件浏览器里迅速出现了一个 report_1/ 文件夹。紧接着,一个名为 outline.md 的文件被创建。 你可以清晰地看到大纲的逻辑:它并没有急着去写第一章,而是利用一个专门的 Creative Director Prompt,把任务拆成了 PESTEL 分析、波特五力模型、SWOT 态势分析等专业框架。这种“先筑基、后填肉”的做法,是它能写出 50 页以上内容的前提。
• 海量资料的“外部索引”
视频展示了 Data Collection Agent 在后台的操作。你可以看到 papers/ 目录下文件数量激增,几十份各家车企的年报、产业白皮书被自动下载。 这里最硬核的技术点在于:模型并没有把这些 PDF 全都 load 进 Prompt。视频中展示了模型调用了 answer_from_pdf 工具。 这就像是它派出了几十个“小秘书”,每个小秘书负责读一张纸,然后把关键数据(如比亚迪 2024 年的毛利、工信部的最新补贴标准)汇总到一个 market_data.csv 里。
• 自动化的图表生产线
视频中有一段非常精彩的“自愈”过程。 Coder Agent 写了一段绘图代码,但在第一次运行时,因为本地 Docker 环境缺少某个字体库导致报错(Validation Failure)。 以往的 Agent 可能会卡在“对不起,我遇到了错误”的套娃里。但视频显示,InfiAgent 去读取了磁盘上的 validation_logs,识别出是环境问题,于是它自动修改了绘图代码的依赖逻辑,避开了那个报错点。 最终,你在 PDF 里看到了精美的折线对比图。
• LaTeX 级长文档排版
最终的 54 页 PDF。它包含了完整的目录跳转、严谨的引用列表(引用的文献都在磁盘里的 references.bib 有对应)。 (这种把“记忆”下放到“文件系统”而不是“大脑窗口”的做法,让它在处理长篇大论时展现出了极高的稳定性。)
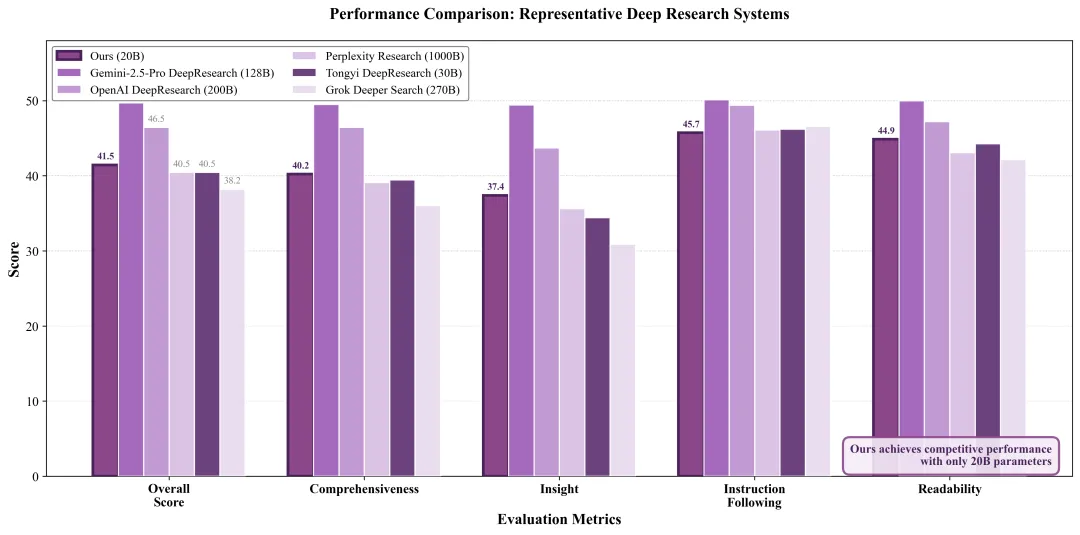

(图:对应论文 Figure 2。这种 54 页报告的高分产出,正是基于它在理解力、指令遵循和可读性维度上的高分表现。)
2. 场景二:算法研究员的“自愈”仿真实验
在另一个 Demo 视频中,InfiAgent 挑战了一个更硬核的活:对比 A* 算法与 Dijkstra 算法在不同复杂网格环境下的表现。文件名为 mia_test.pdf。
这个任务需要 Agent 具备真正的闭环科研能力:
• 写代码:写出寻路算法的模拟脚本。 • 跑仿真:在本地环境运行,得出耗时、路径长度、节点访问数等原始数据。 • 分析并回溯:如果数据不合理,需要重新调参。
视频里展示了一个细节:当 Agent 发现网格密度设为 1000 时,代码运行直接崩溃(Memory Overflow)。 此时,终端显示模型进入了 Thinking 模块的 10 步策略检查:它对比了“当前文件系统状态”与“上一步动作”。它意识到是因为内存溢出。 于是,它在磁盘上直接编辑了 experiment_plan.md,将网格密度下调至合适的量程,重新运行。
最终生成的这篇 LaTeX 论文,盲测质量达到了能参加 EI/IEEE 会议的水平。 这对于算法研究员来说,这种能帮你跑实验、改 Bug、出图、写论文的“外骨骼”,简直是降本增效的神器。
3. 场景三:80 篇顶刊论文的“地狱级”文献综述
这是论文里最核心的实验,也是视频里展示得最淡定的能力。 面对 80 篇 PDF 论文,一般的 Agent 看到第 5 篇就该“Lost in the Middle”(中间迷失)了。
底层逻辑拆解: InfiAgent 启动了 External Attention Pipeline(外部注意力流水线)。 在视频里,你能看到主 Agent(Alpha 层)完全不碰 PDF。它只是发号施令:“查一下这篇论文对 Transformer 效率的改进。” 具体的 PDF 读取是由底层的 Atomic Agent 在隔离的子进程里完成的。
这种“大脑只管逻辑决策,硬盘和工具管原始记忆”的做法,让它的任务覆盖率(Coverage)保持了恐怖的稳定性。论文 Table 1 的数据显示,开启文件中心化状态后,平均覆盖率从 Baseline 的 3.2% 提升到了 67.1%。
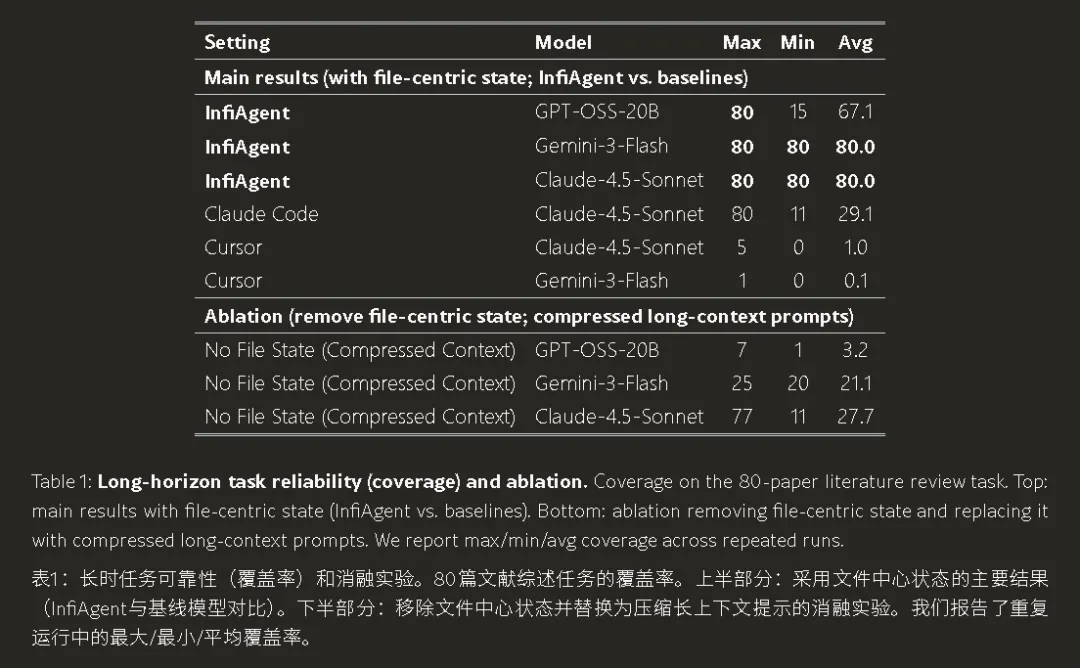
(图:论文 Table 1。展示了 InfiAgent 在长程任务中的碾压级可靠性。)
二、 论文底层架构分析:为什么它“不会累”?
如果你想在新春佳节期间研究下这套 Infra,咱们得跳出视频,深入 Section 3 和 Section 4 那些硬核的架构逻辑里。
1. 数学底座:$S_t = F_t$(文件即状态)
这是论文里最清醒的一个洞察:LLM Agent 的状态不应该是 Prompt 里的对话记录。 传统 Agent 把对话历史、中间计划、工具输出全塞在 Prompt 里。 这就好比你做数学题,不买草稿纸,全靠脑子记。题一难,脑子就烧了。
InfiAgent 的方案是: 它将状态显式定义为文件系统 $F_t$。
• 计划在 plan.md。• 对话记录在 conversations/下的 JSONL。• 代码在 script.py。
每走一步决策,模型执行一次 Workspace State Snapshot(快照),它只读最新的状态概览。 这种 Zero Context Compression(零上下文压缩) 策略,确保了推理上下文始终是 Bounded(有界的)。 (这种 $O(1)$ 复杂度的 bounded context,才是让智能体走向“工业化生产”的正确 Infra。)
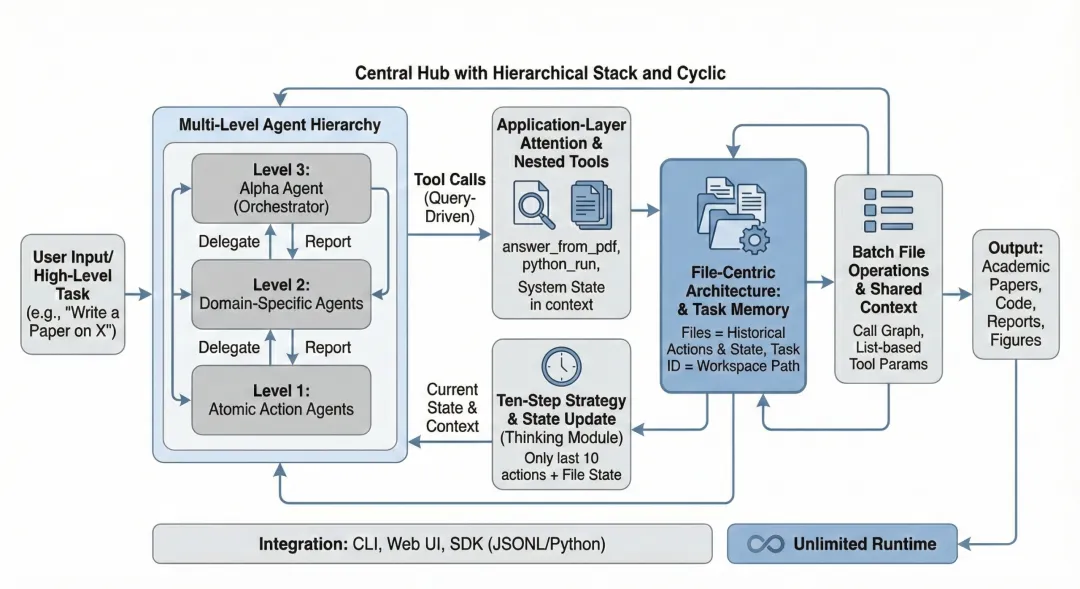
 (图:论文 Figure 1。展示了文件中心化架构的拓扑。左侧是多级智能体,右侧是与其平行的文件系统层。)
(图:论文 Figure 1。展示了文件中心化架构的拓扑。左侧是多级智能体,右侧是与其平行的文件系统层。)
2. MLA 层级体系:Agent-as-a-Tool
InfiAgent 建立了一套严密的递归 DAG(有向无环图)层级:
• Level 3 (Alpha Agent):大脑。负责大目标的拆解。它只负责指挥。 • Level 2 (Domain Agents):专家团。负责具体的 Workflow(如 Coder、Data Collector)。 • Level 1 (Atomic Agents):双手。只负责执行原子化操作(如搜索、读写文件、运行 Python)。
上级把下级当成“工具”来调用。 这种设计理念有效防止了工具调用的“混沌熵增”。如果底层报错了,错误信息会被隔离在子分支的文件里,不会像平铺架构那样干扰到 Alpha Agent 的全局逻辑判断。
3. 10步 Thinking 策略
这是一个非常务实的设计。 框架内置了一个独立的 Thinking 模块。 每走 10 步,它会自动更新一次“文件空间状态”。 它会问自己:这 10 步我干了啥?目标达成了多少?下一步的核心矛盾在哪? 这种周期性的“自我对账”,极大地缓解了模型在长程任务中的迷失感。
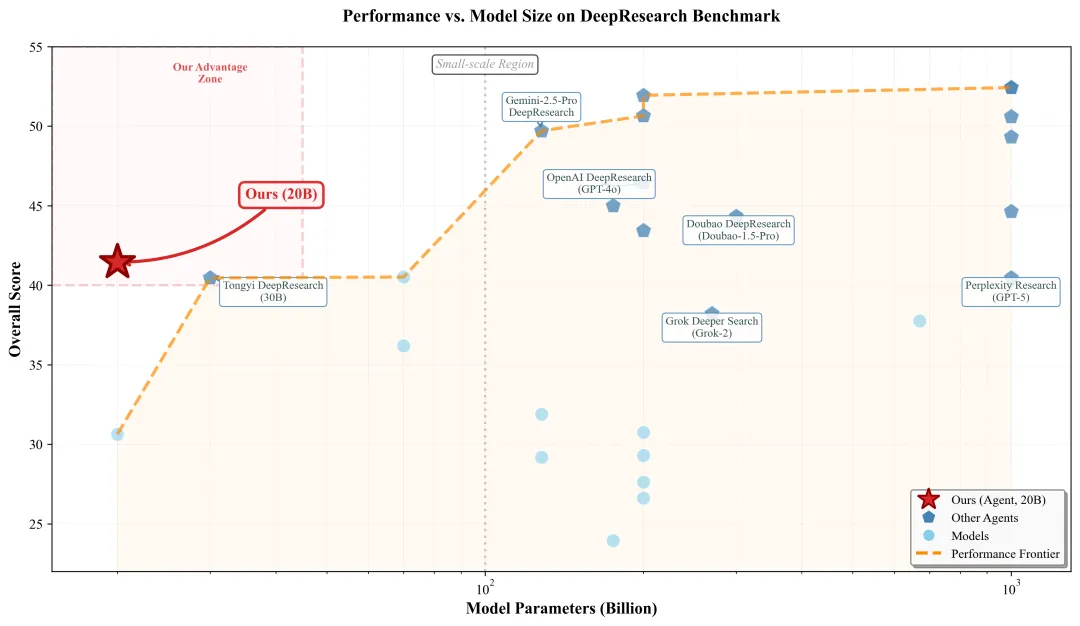

(图:论文 Figure 3。展示了 20B 规模的开源模型在 InfiAgent 架构下,如何在效率/性能前沿线上超越了部分千亿级商业 Baseline。)
我们要聊 Agent,如果不提当下最火的 Claude Code 或者正在尝试 Computer Use 闭环的 OpenClaw(其作者最近加入 OpenAI 并表示将持续维护开源版本),那消息就太闭塞了。
2026 年初,Agent 的竞争已经从“看谁模型大”变成了“看谁架构稳”。
1. 全自动投研分身:从“速读”到“重写”
目前的金融/法律 Agent 只能帮你查查条文。 有了 InfiAgent,投研经理只需要扔给它一个 Task ID:“调研固态电池行业的全球竞争格局,搜集 50 家车企及电池厂的资料,最后出一份 100 页的内部研报。” 它会在你的工作目录下建立 50 个文件夹,持续追踪每一家的财报。 这种长达数周、上千个执行步骤的任务,在 InfiAgent 的 bounded context 架构下是零压力运行。
2. 科研全生命周期管理
目前的“AI 科学家”大多停留在写摘要阶段。 InfiAgent 的 MLA 架构真正具备了从“提出假设 -> 文献调研 -> 仿真实验 -> 纠错优化 -> 文档排版”的全链闭环潜力。 就像视频里生成的那个 mia_test.pdf 一样,这预示着未来可能会出现真正的“数字算法工程师”。
3. 超大规模代码库的“持续自愈系统”
面对含有几千个文件、逻辑错综复杂的 Legacy Code。 InfiAgent 利用文件中心化的记忆,可以持续工作数周,分析每一个模块的定义,并在磁盘记录中保持长期的状态一致性。这完美解决了大 Repo 维护中“按下葫芦浮起瓢”的痛点。
咱们来一波务实的对比:
• 对比堆窗口长度的方案(如 1M+ Context 系列)
有些模型支持 100 万 Token 上下文。但是,处理一次 100 万 Token 的 API 成本极高,且随着窗口填满,模型推理速度会变慢 5-10 倍。 InfiAgent: 每次推理只处理几百 Token。API 成本节省了 90% 以上,响应速度始终保持在毫秒级。
• 对比纯 RAG 方案
RAG 虽然能读很多东西,但缺乏“持久状态”。它很难处理“根据第一页的逻辑去修改第十页的代码”这种强耦合的任务。 InfiAgent: 状态落地成文件。它能在文件系统里进行真正的迭代和回溯。
• 对比 OpenClaw / Claude Code
OpenClaw 强在对屏幕的实时操作感,而 InfiAgent 强在对文件系统的深度经营和长时稳定性。对于需要后台静默运行长任务的用户,InfiAgent 的 Infra 选型更具韧性。
在这个除夕之夜,InfiAgent 给了我们一种不一样的思路。 我们不需要一味追求把模型的大脑容量做得无限大, 我们要学会给 AI 递一张纸、一支笔(文件系统),以及一套科学的管理流程(MLA 架构)。
InfiAgent V3 的开源,不仅仅是放出了一个工具,更是放出了一套“长程智能体”的工业化标准。
(我个人非常看好它的 Skills 扩展 设计。这种基于 Agent Skills 开放标准的加载模式,意味着未来我们可以像安装插件一样给 Agent 安装“会计技能”、“编程技能”、“法务技能”。)
除夕夜,大家如果春晚看累了,不妨去 GitHub 点个 Star,拉个镜像跑跑看。
你会让 InfiAgent 帮你写明年的行业预测,还是帮你梳理电脑里那一堆乱糟糟的 PDF? 欢迎在评论区留言吐槽/交流。
最后, 再次祝各位:
新春大吉,万事顺意!
愿你代码无 Bug!
愿你内存显存无限
愿你积分额度不减
愿你硬件寿命长久
愿你内测资格爆满
愿你 Token 永远够用
愿你 Agent 状态恒定,长跑不掉队!
声明:本文数据、图片及视频演示 Case 均严格引述自 InfiAgent 官方公开论文及项目主页。不代表任何商业承诺,仅作技术拆解。
请在微信客户端打开

