Python数据合并:超越Excel的VLOOKUP,这才是数据对齐艺术!
- 2026-07-20 09:04:10
Python数据合并:超越Excel的VLOOKUP,这才是数据对齐艺术!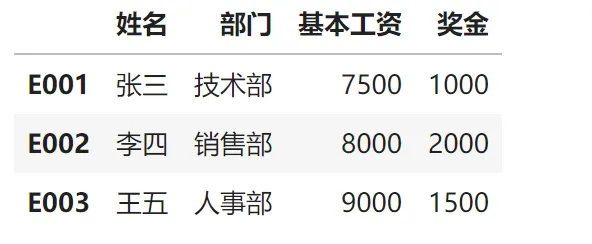

后台回复:【数据分析】,获取Python数据分析资料
引言:从Excel到Python的进化
❝如果你是数据分析师,肯定对Excel的VLOOKUP函数又爱又恨。爱它的便捷,恨它的局限——只能从左向右查找、必须精确匹配、效率低下......
今天,我要告诉你一个好消息:在Python的pandas世界里,数据匹配不仅更强大,而且更智能! 让我们一起来探索这个神奇的功能。
一、索引对齐:Python数据合并的"智能大脑"
什么是索引对齐?
想象一下,你有两个Excel表格,一个记录员工基本信息,一个记录工资信息。在Python中,当你想合并这两个表格时,pandas会自动根据索引(Index)进行智能匹配。
import pandas as pd# 员工基本信息表df1 = pd.DataFrame({'姓名': ['张三', '李四', '王五'],'部门': ['技术部', '销售部', '人事部']}, index=['E001', 'E002', 'E003']) # 索引:员工编号# 员工工资表df2 = pd.DataFrame({'基本工资': [8000, 9000, 7500],'奖金': [2000, 1500, 1000]}, index=['E002', 'E003', 'E001']) # 注意:顺序不同!# 神奇的事情发生了:自动按索引对齐!data = df1.join(df2)data输出结果
看到了吗?即使顺序不同,Python也能智能匹配! 这就是索引对齐的魅力。
三种匹配模式,满足所有需求
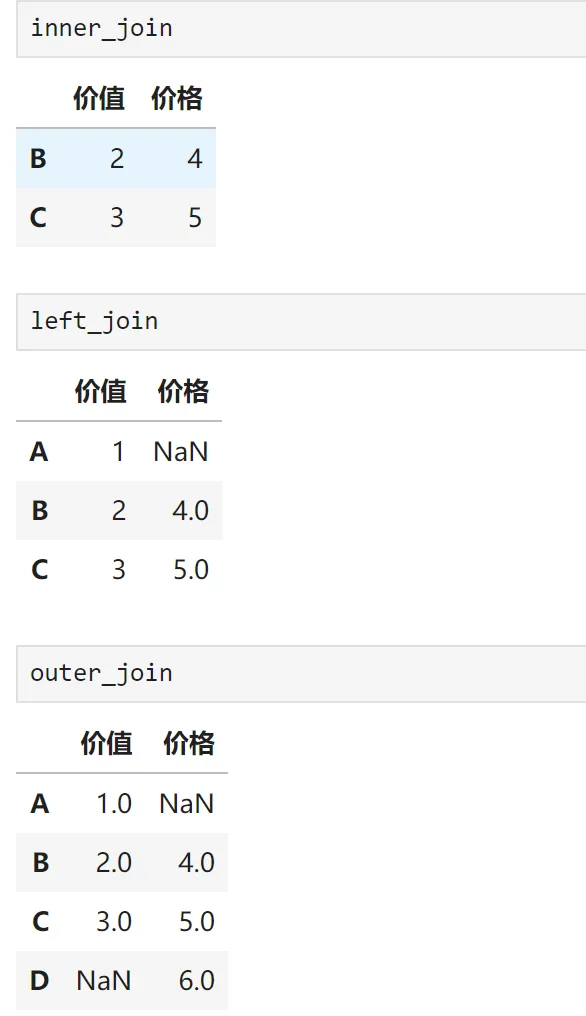
Python提供了三种匹配方式,比VLOOKUP灵活多了:
# 创建示例数据df1 = pd.DataFrame({'价值': [1, 2, 3]}, index=['A', 'B', 'C'])df2 = pd.DataFrame({'价格': [4, 5, 6]}, index=['B', 'C', 'D'])# 模式1:内连接(只保留两者都有的)inner_join = df1.join(df2, how='inner') # 只保留B、C# 模式2:左连接(以左边为主)left_join = df1.join(df2, how='left') # 保留A、B、C,D没有# 模式3:外连接(全部保留)outer_join = df1.join(df2, how='outer') # A、B、C、D都保留输出结果
总结
二、按列匹配:VLOOKUP的超级增强版
基本用法:告别VLOOKUP的限制
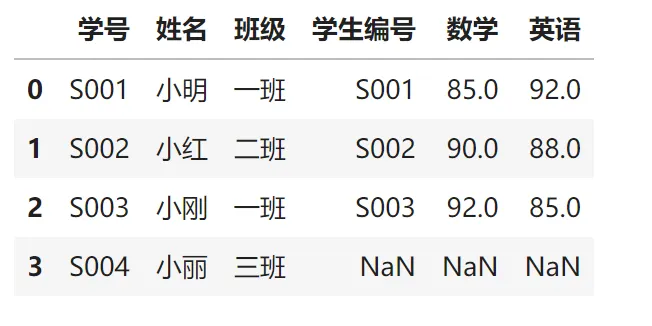
Excel的VLOOKUP只能从左往右查,Python的merge函数可以任意方向匹配:
# 模拟Excel常见场景:学生成绩合并students_data = pd.DataFrame({'学号': ['S001', 'S002', 'S003', 'S004'],'姓名': ['小明', '小红', '小刚', '小丽'],'班级': ['一班', '二班', '一班', '三班']})score_data = pd.DataFrame({'学生编号': ['S002', 'S001', 'S003', 'S005'],'数学': [90, 85, 92, 88],'英语': [88, 92, 85, 90]})# Python版"VLOOKUP"result = pd.merge(students_data, score_data, left_on='学号', # 左表的匹配列 right_on='学生编号', # 右表的匹配列 how='left') # 左连接模式result合并结果
关键优势
可以任意指定匹配列 支持左、右、内、外四种连接 一次可以匹配多个条件 处理百万级数据依然快速
索引和列值的匹配
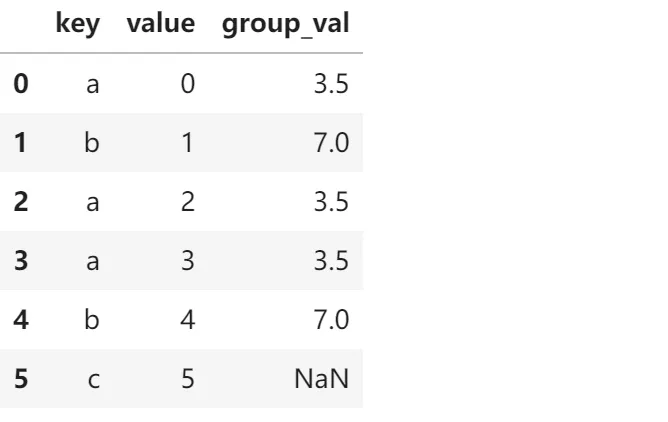
在某些情况下,DataFrame中的连接键位于其索引(行标签)中。在这种情况下,可以 传入left_index=True 或 right_index=True(也可以两个都传)以说明将索引用作连接键:
# 构建数据left1 = pd.DataFrame({'key':['a','b','a','a','b','c'],'value':pd.Series(range(6),dtype='Int64')})right1 = pd.DataFrame({'group_val':[3.5,7,9]}, index=['a','b','d'])# 合并表格,左表的key和右表的主键进行匹配merge_data = pd.merge(left1,right1,left_on='key',right_index=True,how='left')merge_data输出结果
高级技巧:多条件匹配
Excel要实现多条件匹配需要辅助列,Python一行代码搞定:
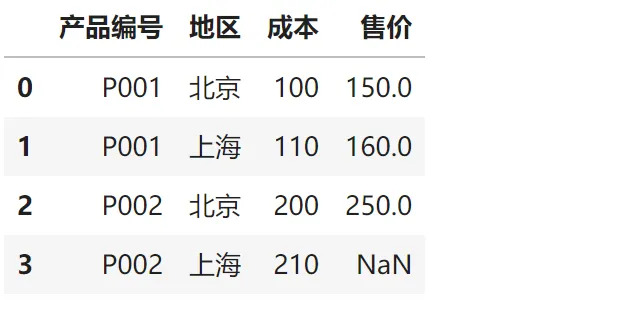
# 复杂场景:同一产品在不同地区的价格product_data = pd.DataFrame({'产品编号': ['P001', 'P001', 'P002', 'P002'],'地区': ['北京', '上海', '北京', '上海'],'成本': [100, 110, 200, 210]})price_data = pd.DataFrame({'产品ID': ['P001', 'P001', 'P002', 'P002'],'区域': ['北京', '上海', '北京', '广州'], # 注意:广州没有成本数据'售价': [150, 160, 250, 260]})# 双条件匹配:产品编号 + 地区result = pd.merge(product_data, price_data, left_on=['产品编号', '地区'], right_on=['产品ID', '区域'], how='left')result[['产品编号', '地区', '成本', '售价']]输出结果
三、匹配时的"坑"与解决方案
陷阱一:数据类型不匹配
常见问题: 一个表中的ID是字符串,另一个是数字
# 错误示例df1 = pd.DataFrame({'ID': ['001', '002', '003'], '数据': [1, 2, 3]})df2 = pd.DataFrame({'ID': [1, 2, 4], '价格': [10, 20, 30]})# 直接合并会失败!'001' ≠ 1# result = pd.merge(df1, df2, on='ID') # 错误!# 解决方案:统一数据类型df1['ID'] = df1['ID'].astype(int) # 转换为整数# 或者df2['ID'] = df2['ID'].astype(str) # 转换为字符串陷阱二:重复值导致数据膨胀
警告: 如果匹配列有重复值,结果可能会让你大吃一惊!
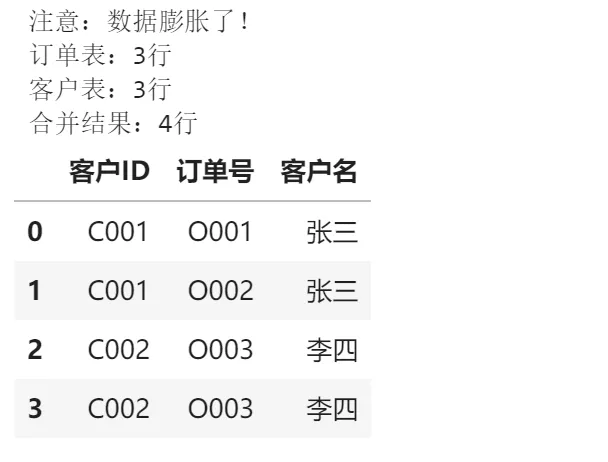
# 危险示例order_table = pd.DataFrame({'客户ID': ['C001', 'C001', 'C002'], # C001有两条记录!'订单号': ['O001', 'O002', 'O003']})customer_table = pd.DataFrame({'客户ID': ['C001', 'C002', 'C002'], # C002有两条记录!'客户名': ['张三', '李四', '李四']})result = pd.merge(order_table, customer_table, on='客户ID')print("注意:数据膨胀了!")print(f"订单表:{len(订单表)}行")print(f"客户表:{len(客户表)}行") print(f"合并结果:{len(result)}行")result输出结果
解决方案:合并前先检查重复值
# 检查重复print("订单表客户ID重复情况:")print(order_table['客户ID'].value_counts())print("\n客户表客户ID重复情况:")print(customer_table['客户ID'].value_counts())陷阱三:列名冲突
当两个表有相同列名但不是匹配列时:
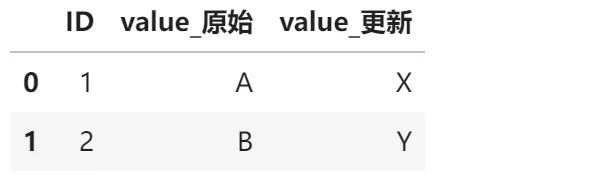
# 列名冲突示例df1 = pd.DataFrame({'ID': [1, 2], 'value': ['A', 'B']})df2 = pd.DataFrame({'ID': [1, 2], 'value': ['X', 'Y']}) # 相同列名!# 使用suffixes参数区分result = pd.merge(df1, df2, on='ID', suffixes=('_原始', '_更新')) # 自动添加后缀区分result输出结果
四、性能优化:大数据匹配的技巧
选择合适的匹配方法
import timeimport pandas as pd# 创建大数据集big_data = pd.DataFrame({'ID': range(1000000), '数据': range(1000000)})small_data = pd.DataFrame({'ID': range(0, 1000000, 2), '价格': range(0, 1000000, 2)})# 方法1:mergestart = time.time()result1 = pd.merge(big_data, small_data, on='ID', how='left')print(f"merge方法耗时:{time.time() - start:.2f}秒")# 方法2:mapstart = time.time()price_dic = small_data.set_index('ID')['价格']big_data['价格'] = big_data['ID'].map(price_dic)print(f"map方法耗时:{time.time() - start:.2f}秒")# 方法3:join start = time.time()big_data = big_data.set_index('ID')[['数据']] #以防上一步已经增加了价格字段small_data = small_data.set_index('ID')result3 = big_data.join(small_data, how='left')print(f"join方法耗时:{time.time() - start:.2f}秒")内存优化技巧
# 技巧1:只选择需要的列result = pd.merge( big_data[['ID', '姓名']], # 只选择必要的列 small_data[['ID', '工资']], # 只选择必要的列 on='ID')# 技巧2:使用合适的数据类型big_data['ID'] = big_data['ID'].astype('int32') # 减少内存使用big_data['姓名'] = big_data['姓名'].astype('category') # 分类数据优化五、总结:Python vs Excel
结语
从Excel到Python,不仅是工具的升级,更是思维方式的转变。掌握了Python的数据匹配技巧,你就能:
处理更复杂的数据场景
应对更大规模的数据量
实现完全自动化的数据处理流程
大大提升工作效率和准确性
不要再被VLOOKUP限制了想象力,拥抱Python,开启高效数据分析的新篇章!
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

